
K-nearest neighbors는 지도학습 분류 기술이다.
K-nearest neighbors는 알려진 데이터 포인트에 대한 근접성을 기반으로 새로운 알려지지 않은 데이터 포인트를 분류한다.
이 분류 과정은 대상 데이터 포인트에 가장 가까운 데이터 포인트의 "k"개를 설정하여 결정된다.
데이터 양이 적은 경우만 추천한다.
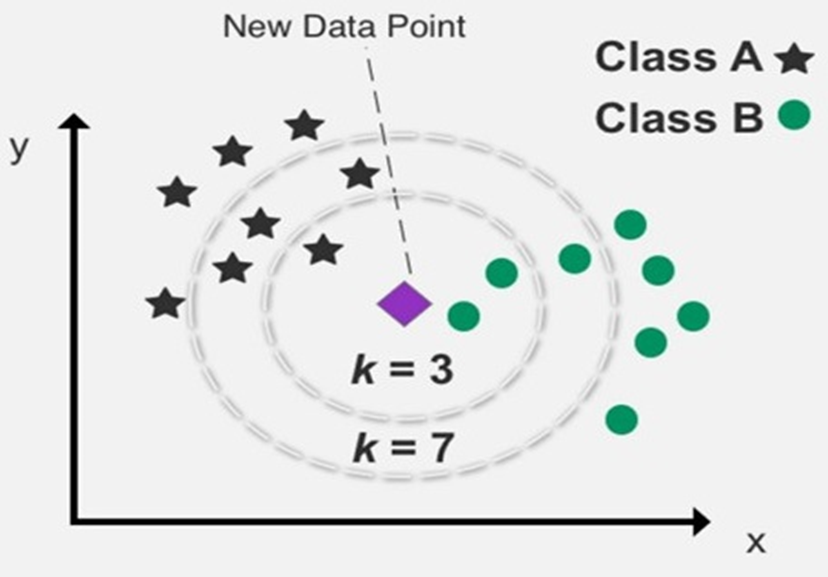
K=3이면 ㅁ에서 가장 가까운 3개의 data를 찾는다.
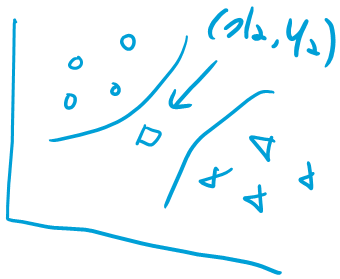

위쪽의 유클리디안 공식에서 X1와 Y1은 3개의 데이터에 각각 해당되어 총 3번 d값을 계산하게 된다.

k-nearest neighbors 기법은 예측이 이루어질 때마다 전체 학습 데이터가 사용되기 때문에 "메모리 기반 절차"라고도 한다. 이러한 이유로 k-NN은 일반적으로 큰 데이터 세트를 분석하고 고차원 데이터에서 여러 거리를 측정하는 데 권장되지 않는다.
Principal dimension algorithm(PCA) 또는 변수 병합과 같은 내림차순 차원 알고리즘은 k-NN 분석을 위한 데이터 세트를 단순화하고 준비하는 일반적인 전략이다. Dimension을 줄이면 dataset도 줄어든다.
discrete 변수를 제거.
K-NN은 age나 area income과 같은 연속적인 변수에 효과적이다.
한계가 있으면 discrete. 예시로 gender, 원 핫 인코딩에서 성별을 남자는 1, 여자는 0 이런 식으로 표현 가능.
나이는 continuous, 한계가 없다.
K-nearest는 continuous일 때 결과값이 좋음. Dimension reduction해서 dataset 사이즈를 줄여줘야 하기 때문에 보통 discrete한 data는 제거한다.
독립 변수의 분산을 표준화하기 위해 Scikit-learn의 StandardScaler()를 사용한다(종속 변수는 삭제함).
이 변환은 모델의 focus를 부당하게 끌어당기는 높은 범위의 하나 이상의 변수를 피하는 데 도움이 된다. K를 홀수로 설정하면 바이너리 예측의 경우 예측 교착 상태의 가능성을 제거하는데 도움이 된다.
model = KNeighborsClassifier(n_neighbors=5)
model.fit(X_train, y_train)
이런 식으로 알고리즘을 세팅한다. 그리고 정확하지 않은 예측값들을 제거한다.
scaled_features 데이터 프레임의 처음 10개 행에 모델(n_neighbors=3)을 배포하여 가능한 결과를 예측할 수 있다.
model.predict(scaled_features)[0:10]
학습에 사용된 데이터와 결과를 비교하면 모델의 예측이 정확하다.
