1. Abstract
- Goal of the Competition
- 문서 타입 분류를 위한 이미지 분류(17종)
- Timeline
- 2024.04.11 ~ 2024.04.23 19:00
2. Process : Competition Model
-
Environment
Ubuntu 20.04
python
Geforce RTX3090 24GB
wandb -
Requirements
albumentations==1.3.1
ipykernel==6.27.1
ipython==8.15.0
ipywidgets==8.1.1
jupyter==1.0.0
matplotlib-inline==0.1.6
numpy==1.26.0
pandas==2.1.4
Pillow==9.4.0
timm==0.9.12 -
Dataset overview
데이터는 총 17개 종의 문서로 분류되어 있음.
1570장의 학습 이미지를 통해 3140장의 평가 이미지를 예측하게 됨.
현업에서 사용하는 실 데이터를 기반으로 대회를 제작하여 대회와 현업의 갭을 최소화
현업에서 생길 수 있는 여러 문서 상태에 대한 이미지를 구축.
-
agumentation
RandomResizedCrop(height=img_size, width=img_size, scale=(0.8, 1.0), p=0.5)
Resize(height=img_size, width=img_size),
HorizontalFlip(p=0.5),
VerticalFlip(p=0.5),
RandomRotate90(p=0.5),
Rotate(limit=(-35, 35), p=0.5),
GaussianBlur(blur_limit=(3, 7), p=0.5),
GaussNoise(always_apply=False, p=0.5, var_limit=(50.0, 200.0),per_channel=True, mean=0.0),
HueSaturationValue(hue_shift_limit=20, sat_shift_limit=30, val_shift_limit=20, p=0.5),
RandomBrightnessContrast(brightness_limit=0.2, contrast_limit=0.2, p=0.5),
# 클래스 간 차이 부각을 위한 추가 기법
ImageCompression(quality_lower=60, quality_upper=100, p=0.5), # 이미지 압축 및품질 저하
CoarseDropout(max_holes=8, max_height=16, max_width=16, p=0.5), # CoarseDropout 추가
Normalize(mean=[0.57433558, 0.58330406, 0.58818927], std=[0.18964056, 0.18694252, 0.18506919]),
ToTensorV2()
#Normalize의 경우는 train, test 데이터의 평균, 분산을 직접 계산해서 적용
#추가로 mix up을 적용3. Process : Issues
- 어느 정도 이상으로 정확도가 잘 올라가지 않음
- 클래스별 f1score를 찾아보기로 함
3, 7, 14번 클래스의 점수가 낮음

- 클래스별 f1score를 찾아보기로 함
-
형태가 비슷한 문서의 경우 분류가 어려움
- 3, 7, 14번 클래스의 경우 문서의 형태가 비슷해 모델이 이미지를 잘 분류해내지 못함
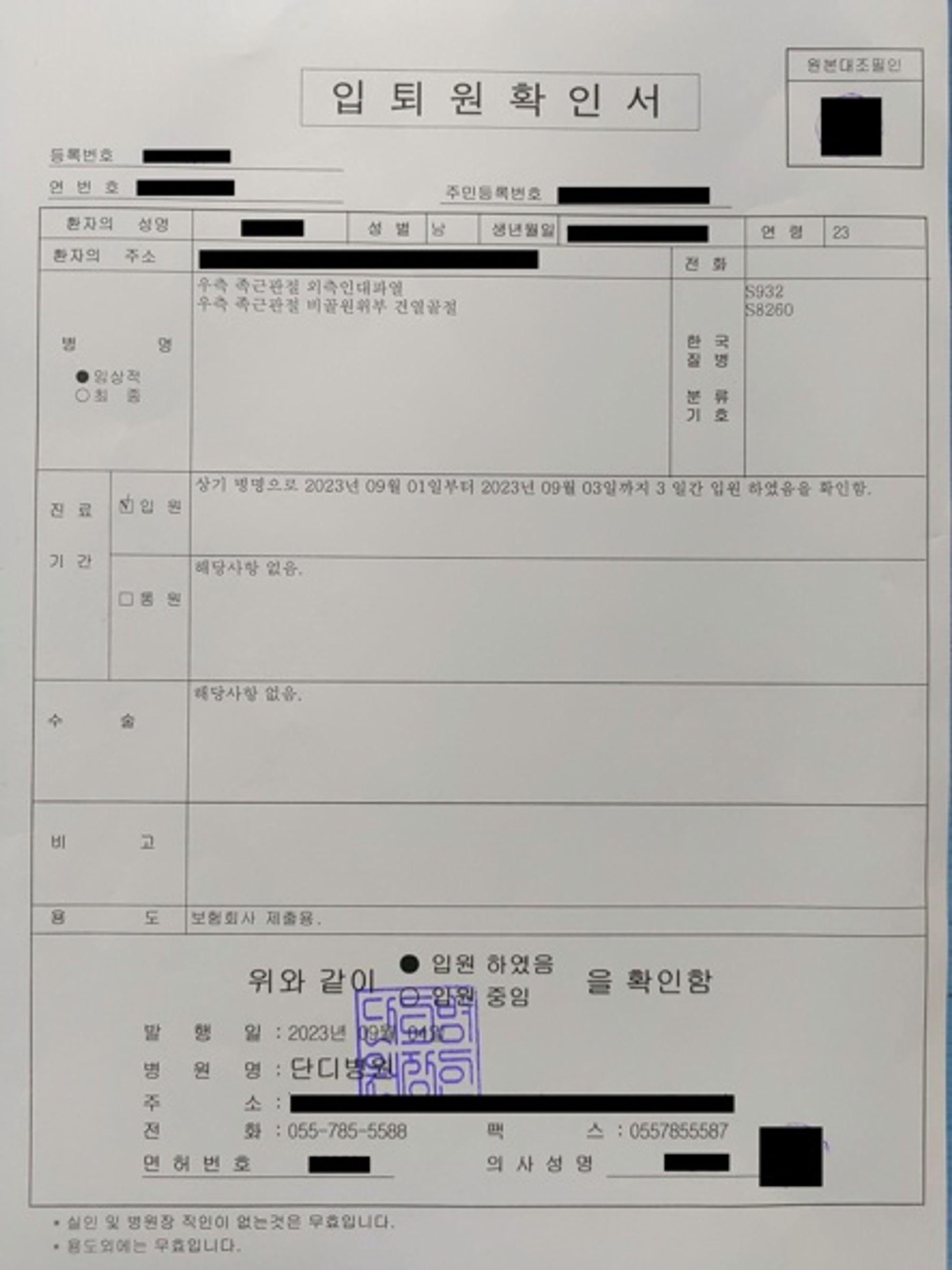
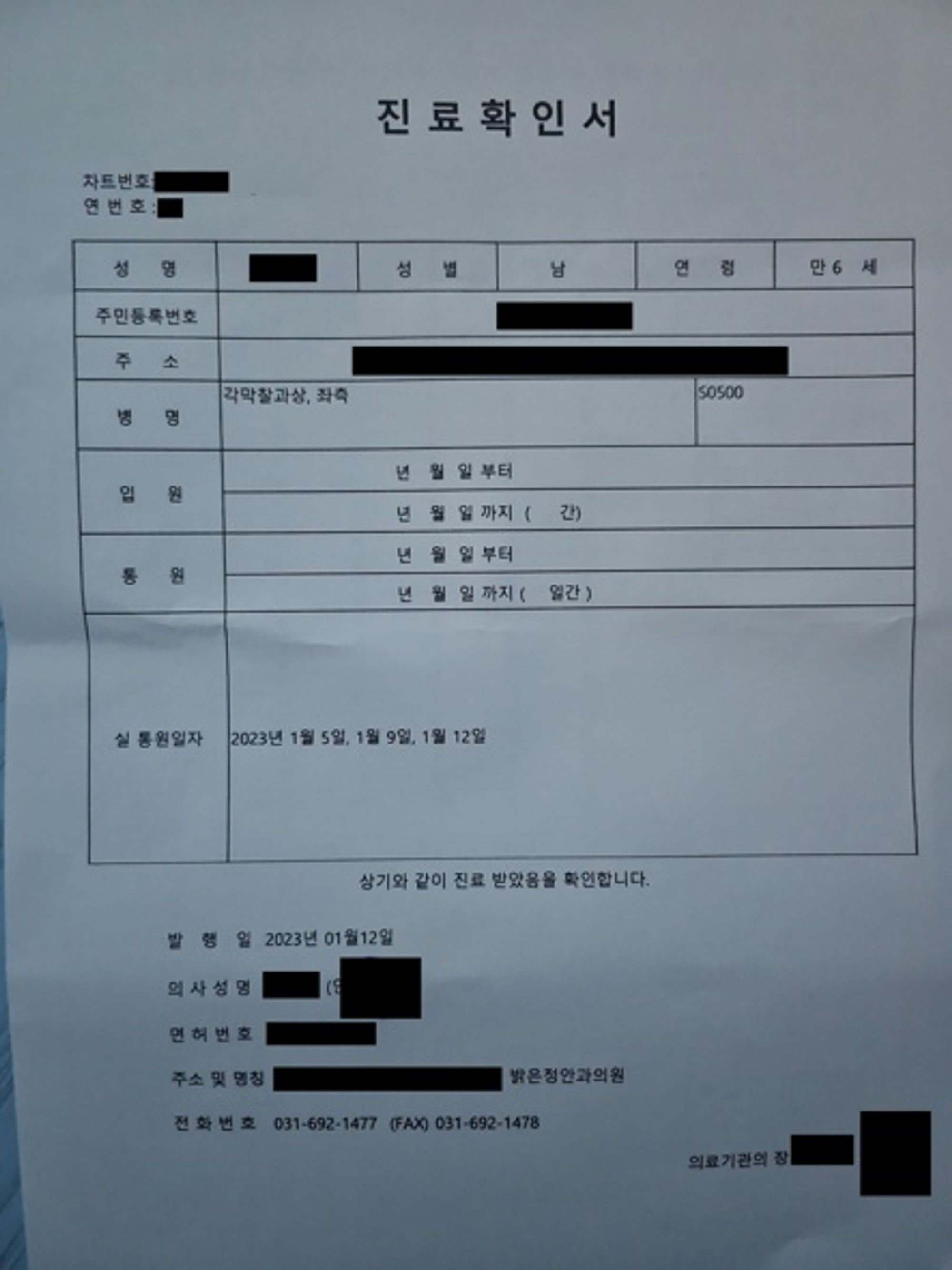

- 3, 7, 14번 클래스의 경우 문서의 형태가 비슷해 모델이 이미지를 잘 분류해내지 못함
-
Describe the possible solution to imporve your project.
- 해당 이미지를 따로 분류하도록 하는 계층적 구조를 도입해볼 수 있겠으나, 시간 부족으로 적용해보지 못하였음
4. Role
- Describe your role with task in your team.
- efficientnet-b4를 사용한 base model 작성
- Describe papers or book chapeters you found relevant to the problem, references to see.
- Explain which are relevant for your Project.
- efficientnet-b4에 imagenet을 사용한 가중치를 사용하고, LRscheduler와 AdamW optimizer를 사용.
- AMP사용으로 OOM 문제 방지
- data에는 각종 agumentation을 사용.
- Stratified K-Fold Cross Validation
5. Results
- 약 0.95정도의 LBscore 달성
- 최종 리더보드 순위 3위

6. Conclusion
- Describe your running code with its own advantages and disadvantages, in relation to other groups in the course.
- augmentation 부분에 있어 좀 더 많은 노력이 필요했던것으로 보임
- Sum up your project and suggest future extensions and improvements.
- 계층적 분류 모델의 도입으로 잘 분류하지 못했던 3개 클래스에 대한 분류 정확도를 올리고 싶음
