sklearn의 model_selection은 데이터셋을 train 및 test 데이터셋으로 분리하거나 교차검증 분할 및 평가, 지도학습 클래스(Estimator)의 하이퍼 파라미터를 튜닝하는 모듈이다.
train_test_split
기본적인 데이터셋을 학습 및 테스트 데이터 셋으로 분리하는 메서드이다.
train_test_split(feature_data, label_data, test_size, train_size, shuffle, random_state)- 첫번째 및 두번째 파라미터는 feature 데이터셋, label 데이터셋을 받는다.
- test_size : 전체 데이터셋에서 테스트 데이터셋의 크기를 정하는 파라미터. default값은 0.25이다.
- train_size : 잘 사용 안한다. 주로 test_size 사용
- shuffle : 데이터셋을 분리하기 전에 데이터들을 미리 섞는지 여부 결정. default 값은 True. 데이터를 분산시켜서 좀 더 효율적인 학습 및 데이터 세트를 만드는데 사용
- random_state : 호출할 때마다 동일한 학습/테스트용 데이터 셋을 생성하게 해주는 난ㄴ수 값
- 반환값은 튜플 형태. 순차적으로 학습용 데이터의 feature 데이터셋, 테스트용 feature 데이터 셋, 학습용 데이터의 label 데이터셋, 테스트용 label의 데이터셋
교차 검증
가장 간단하게 테스트용 데이터로 학습 시 과적합을 일으킬 수 있다. 고정된 테스트 데이터로 평가를 하다보면 테스트 데이터에만 최적화가 되기 때문이다. 이를 개선하기 위해 교차 검증을 이용하여 다양한 학습과 평가를 진행한다.
교차 검증은 데이터 편중을 막기 위해 여러 세트로 구성된 학습 데이터 셋과 검증 데이터 셋에서 학습과 평가를 수행
K Fold 교차 검증
이 방법은 그림을 그려서 설명하는 것이 좋다.
.jpg)
위 그림은 K Fold 교차검증을 5번 실행한 내용이다. 전체 데이터 셋을 5등분으로 나누고 그 분할한 5개중 하나를 검증 데이터로 삼는다. 이를 5번 반복 실행하는 것이 K Fold 교차 검증이다.
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
import numpy as np
import pandas as pd
# 데이터 생성
iris = load_iris()
# feature, label 데이터 생성
features = iris.data
label = iris.target
#의사 결정 나무 객체 생성
dt_clf = DecisionTreeClassifier(random_state=156)
# KFold 객체 생성(n_splits=5), 그리고 정확도를 담을 리스트 생성
kfold = KFold(n_splits=5)
cv_accuracy = []
print('붓꽃 데이터 세트 크기 : ', features.shape[0]) # 150
n_iter = 0
# K Fold 실행
for train_index, test_index in kfold.split(features): # split을 실행하면 인덱스로 반환이 된다.
x_train, x_test = features[train_index], features[test_index]
y_train, y_test = label[train_index], label[test_index]
dt_clf.fit(x_train, y_train)
pred = dt_clf.predict(x_test)
n_iter += 1
accuracy = np.round(accuracy_score(y_test, pred), 4)
train_size = x_train.shape[0]
test_size = x_test.shape[0]
print('\n#{0} 교차 검증 정확도 : {1}, 학습 데이터 크기 : {2}, 검증 데이터 크기 : {3}'.format(n_iter, accuracy, train_size, test_size))
print('#{0} 검증 세트 인덱스 : {1}'.format(n_iter, test_index))
cv_accuracy.append(accuracy)
print('\n 평균 검증 정확도 : ', np.mean(cv_accuracy))
5번의 의사결정나무를 실행한 정확도 값을 평균낸 갑이 0.9이다.(90%의 정확도)
Stratified K Fold
Stratified K Fold는 Label 데이터가 불균형한 분포도를 가지고 있을 때 유용하다. 예를 들어 사기 대출건에 대해서 봐보자.
1억건의 데이터 셋중 사기 대출의 건수는 매우 적을 것이다. 이를 그냥 K Fold하면 어떤 트레이닝 셋에는 정상 대출건만 있을 경우가 높다. 이를 방지해주는 것이 Stratified K Fold 이다.
iris 데이터로 기존 K Fold를 해보고 결과물을 봐보자.
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
iris = load_iris()
iris_df = pd.DataFrame(data=iris.data, columns = iris.feature_names)
iris_df['label'] = iris.target
iris_df['label'].value_counts()
kfold = KFold(n_splits=3)
n_iter = 0
for train_index, test_index in kfold.split(iris_df):
n_iter += 1;
label_train = iris_df['label'].iloc[train_index]
label_test = iris_df['label'].iloc[test_index]
print("## 교차 검증 : {}".format(n_iter))
print("학습 레이블 분포도 : \n", label_train.value_counts())
print("테스트 레이블 분포도 : \n", label_test.value_counts())
print("\n")
첫번째 교차검증만 봐도 value값들이 쏠려있다. 이렇게 되면 학습할 때 효율이 낮아진다.
이를 StratifiedKFold로 다시 교차검증을 해보자
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import accuracy_score
iris = load_iris()
iris_df = pd.DataFrame(data=iris.data, columns = iris.feature_names)
iris_df['label'] = iris.target
iris_df['label'].value_counts()
skf = StratifiedKFold(n_splits=3)
n_iter = 0
for train_index, test_index in skf.split(iris_df, iris_df['label']):
n_iter += 1;
label_train = iris_df['label'].iloc[train_index]
label_test = iris_df['label'].iloc[test_index]
print("## 교차 검증 : {}".format(n_iter))
print("학습 레이블 분포도 : \n", label_train.value_counts())
print("테스트 레이블 분포도 : \n", label_test.value_counts())
print("\n")
확실히 value값들이 골고루 퍼져있다.
이를 DecisionTreeClassifier로 붓꽃 예측을 해보자
dt_clf = DecisionTreeClassifier(random_state=156)
skf = StratifiedKFold(n_splits=3)
n_iter = 0
cv_accuracy = []
for train_index, test_index in skf.split(iris_df, iris.target):
n_iter += 1;
x_test, x_train = iris.data[test_index], iris.data[train_index]
y_test, y_train = iris.target[test_index], iris.target[train_index]
dt_clf.fit(x_train,y_train)
pred = dt_clf.predict(x_test)
accuracy = np.round(accuracy_score(pred, y_test), 4)
train_size = x_train.shape[0]
test_size = x_test.shape[0]
print("\n# {} 교차 검증 정확도 : {}, 학습 데이터 크기 : {}, 검증 데이터 크기 : {}".format(n_iter, accuracy, train_size, test_size))
print("\n# {} 교차 검증 인덱스 : {}".format(n_iter, test_index))
cv_accuracy.append(accuracy)
print("\n 정확도 : ", np.mean(cv_accuracy))
정확도가 일반적인 KFold로 분류한 값보다는 높다. 이러한 StratifiedKFold는 일반적으로 분류에서 사용해야한다. 회귀같은 기법에서는 StratifiedKFold는 사실상 무의미하여 지원되지 않는다.
cross_val_score()
KFold 메커니즘은 다음과 같다.
1. KFold 객체 생성
2. 반복문에서 KFold.split로 학습 및 테스트 데이터 인덱스를 추출
3. 머신러닝 알고리즘으로 학습 후 분류 또는 예측
위 과정을 한번에 해주는 API가 cross_val_scoreㅇ()이다.
cross_val_score(estimator, X, y=None, scoring=None, cv=None,
n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')위 파라미터 중 estimator, X, y, scoring, cv가 중요하다.
- estimator : Classifier 또는 Regressor
- X : 피처 데이터 세트
- y : 레이블 데이터 세트
- scoring : 예측 성능 평가 지표
- cv : 교차 검증 폴드 수
- 반환값 : scoring 파라미터로 지정된 성능 지표 측정값을 배열 형태로 반환
붓꽃 데이터를 crss_cal_score()로 분류해보자
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score, cross_validate
import numpy as np
iris_data = load_iris()
dt_clf = DecisionTreeClassifier(random_state=156)
data = iris_data.data
label = iris_data.target
scores = cross_val_score(dt_clf, data, label, scoring='accuracy', cv=3)
print('교차 검증별 정확도 : ', np.round(scores, 4))
print('평균 검증별 정확도 : ', np.round(np.mean(scores), 4))
cross_val_score()를 사용하면 코드가 간결해진다. cross_val_score() API 하나로 학습(fit), 예측(predict), 평가(evaluation)가 다 가능하다.
정확도도 보면 StratifiedKFold와 비슷하다. 이는 KFold 할 때 StratifiedKFold를 했다는 것을 증명한다.
cross_validate() API는 여러개의 평가 지표를 반환할 수 있다.
GridSearchCV
GridSearchCV로 교차 검증과 최적 하이퍼 파라미터 튜닝을 한번에 적용이 가능하다. 하이퍼 파라미터는 ML 알고리즘을 구성하는 주요 구성 요소이다. 이 값을 조정해서 알고리즘의 예측 성능을 개선시킬 수 있다.
예를 들어 하이퍼 파라미터 2개 a, b가 있다고 하자.
grid_parameters = {'a' : [1, 2, 3],
'b' : [4, 5]
}위 두 하이퍼 파라미터를 각각 지정해주면 gridSearchCV는 다음과 같이 ML 알고리즘에 파라미터를 지정해준다.
| 순번 | a | b |
|---|---|---|
| 1 | 1 | 4 |
| 2 | 1 | 5 |
| 3 | 2 | 4 |
| 4 | 2 | 5 |
| 5 | 3 | 4 |
| 6 | 3 | 5 |
총 6번을 걸쳐 하이퍼 파라미터를 적용해주고 최적의 파라미터를 찾아준다.
GridSearchCV의 파라미터는 다음과 같다.
- estimator : classifier, regressor, pipeline
- param_grid : key + 리스트 값을 가지는 딕셔너리가 주어진다. estimator의 튜닝을 위해 파라미터명과 사용될 여러 파라미터 값을 지정
- scoring : 예측 성능을 측정할 평가 방법 지정.
- cv : 교차 검증 세트의 개수 지정
- refit : default 값은 True. True로 설정 시 가장 최적의 하이퍼 파라미터를 찾은 뒤 입력된 estimator 객체를 해당 하이퍼 파라미터로 재학습
예제
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.datasets import load_iris
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=121, test_size=0.2)
dtree = DecisionTreeClassifier()
# 파라미터 지정
parameters = {'max_depth' : [1,2,3], 'min_samples_split' : [2,3]}
# GridSearchCV 파라미터 지정
grid_dtree = GridSearchCV(dtree, param_grid=parameters, cv=3, refit=True)
# GridSearchCV에 train 데이터 셋 학습
grid_dtree.fit(x_train, y_train)
#결과물 확인
scores_df = pd.DataFrame(grid_dtree.cv_results_)
scores_df[['params', 'mean_test_score', 'rank_test_score',
'split0_test_score', 'split1_test_score', 'split2_test_score']]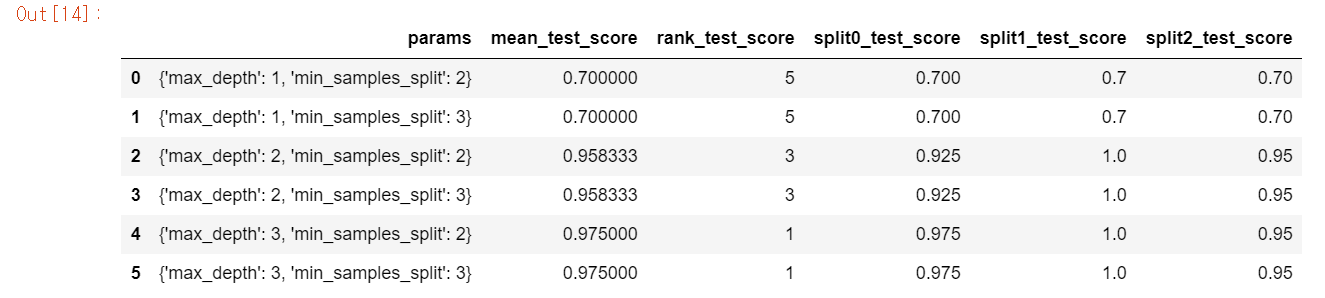
GridSearchCV의 결과는 cv_results_ 딕셔너리에 저장된다.
grid_dtree.cv_results_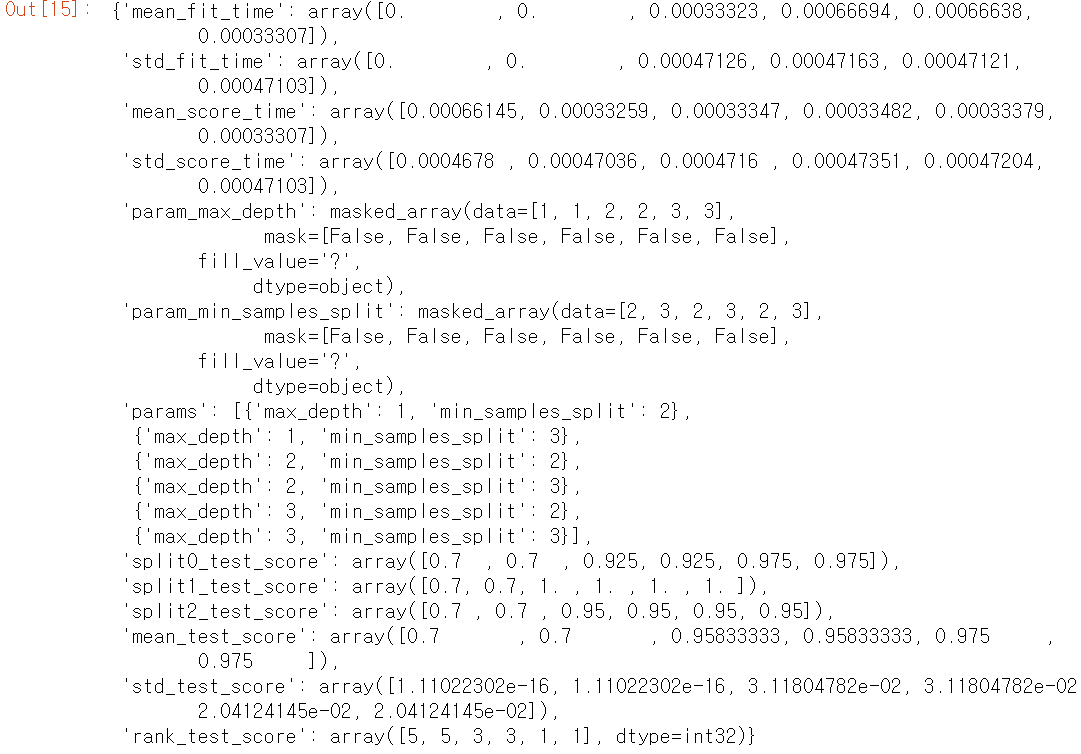
GridSearchCV 객체에 train 데이터 셋을 fit() 시키면 최고 성능을 나타낸 하이퍼 파라미터 값과 그 때의 평가 결과 값이 각각 bestparams, bestscore 속성에 기록된다.
print("최적 파라미터 : ", grid_dtree.best_params_)
print("최고 정확도 : {0:.4f}".format(grid_dtree.best_score_))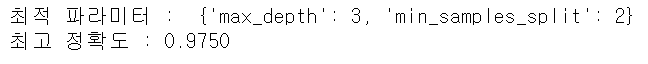
또한 GridSearchCV의 파라미터 중 refit를 True로 설정 시 최적의 파라미터로 Estimator을 학습해 최적화된 Estimator인 bestestimator을 생성.
이 bestestimator로 테스트 데이터셋을 예측해보자.
estimator = grid_dtree.best_estimator_
pred = estimator.predict(x_test) # 바로 predict()로!!
print("테스트 정확도 : {0:.4f}".format(accuracy_score(y_test, pred)))테스트 정확도 : 0.9667
