간단하게 배운 DecisionTreeClassifier 머신러닝 알고리즘으로 타이타닉 데이터를 분석해보았다.
복습차원에서 공부한것이라 큰 의미는 없는 분석이다.
모듈
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
from sklearn.preprocessing import LabelEncodersklern 패키지에서 의사결정나무 모듈은 import하고 titanic 데이터에서 성별과 같은 데이터를 인코더하기 위해 LabelEncoder을 import했다.
데이터
test_df = pd.read_csv("itanic/test.csv")
train_df = pd.read_csv("titanic/train.csv")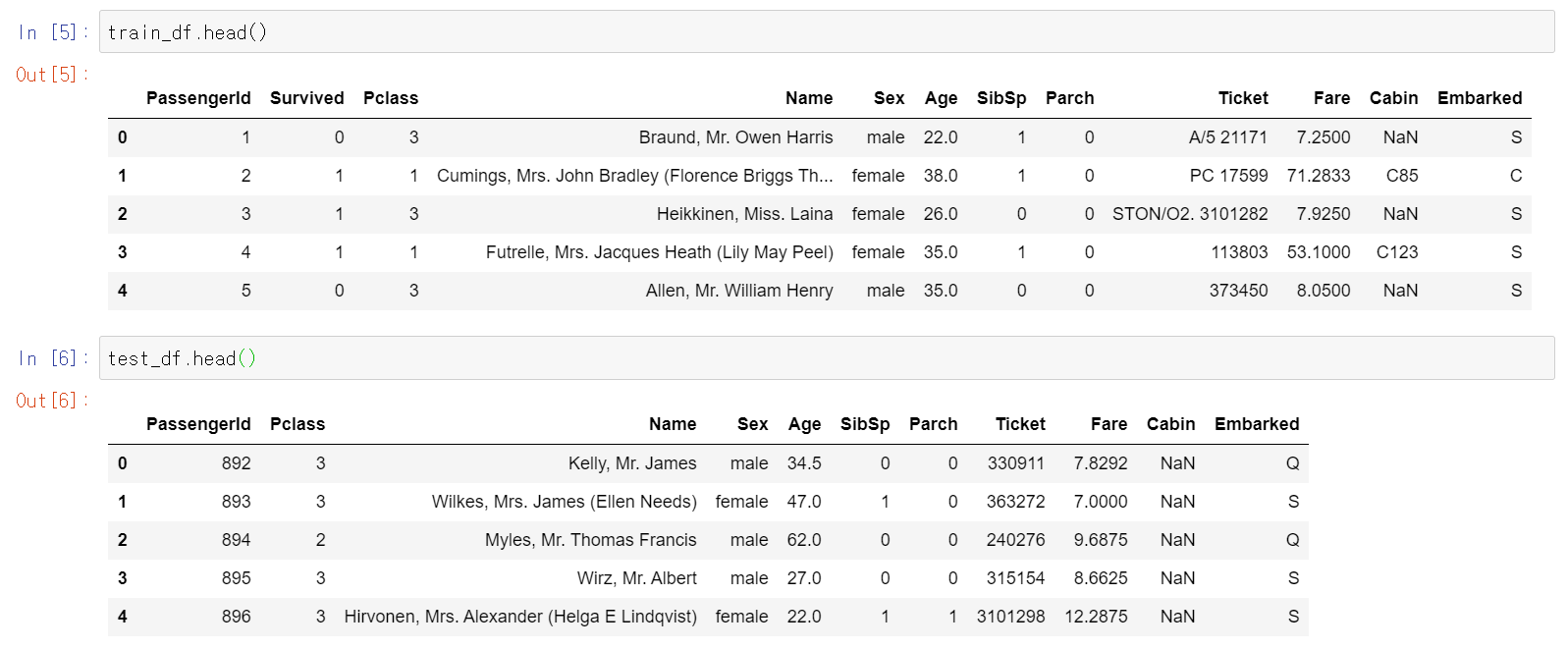
우선 이번 분석의 목표는 feature 데이터를 가지고 Survived Label 데이터를 예측하는 것이다.
전처리
개인적으로 Survived 데이터를 예측하는데 필요한 데이터는 Pclass, Sex, Age라고 판단했다. 나머지 데이터는 삭제하고 이 세 데이터를 가지고 분석을 해보려고 한다.
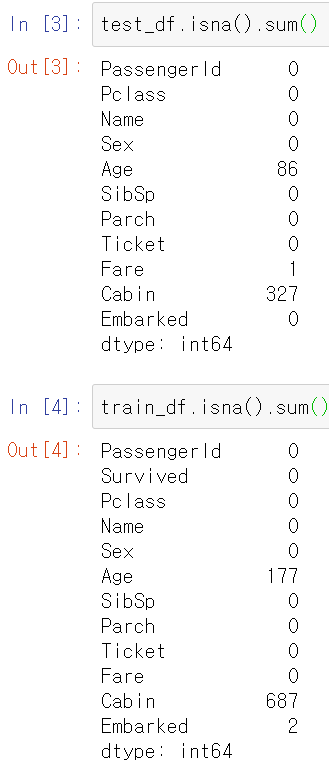
우선 ML 알고리즘을 실행하기 전에 데이터셋을 확인한 결과 Age데이터에 결측치가 존재했다. 아직 결측치 대체 방법에 많이 알지 못해서 이들을 평균값으로 대체했다.
train_df['Age'] = train_df['Age'].fillna(train_df['Age'].mean())
test_df['Age'] = test_df['Age'].fillna(test_df['Age'].mean())Sex데이터는 문자열로 된 데이터이다. 이는 ML 알고리즘에 적용하기 쉽지 않으므로 LabelEncoder을 통해 숫자형 데이터로 변환했다.
label = LabelEncoder()
label.fit(train_df['Sex'])
train_df['Sex'] = label.transform(train_df['Sex'])
test_df['Sex'] = label.transform(test_df['Sex'])그리고 필요없는 데이터는 삭제한다.
train_df.drop(['PassengerId', 'Name', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin' ,'Embarked'], axis=1, inplace=True)
test_df.drop(['PassengerId', 'Name', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin' ,'Embarked'], axis=1, inplace=True)이번엔 train 데이터셋을 feature 데이터셋과 label 데이터셋으로 구분지어줬다.
train_label = train_df['Survived'].values
train_feature = train_df[['Sex','Age','Pclass']].values의사결정나무 적용
dt_clf = DecisionTreeClassifier(random_state=11)
dt_clf.fit(train_feature, train_label)
pred = dt_clf.predict(test_df.values)
의사결정나무 객체를 생성하고 train_feature, train_label을 fit()메서드로 적용하여 test_df.values(ndarray로 변환)을 가지고 예측한 결과다.
성능
성능이 얼마나 좋은지 궁금해서 train 데이터를 학습용, 테스트 데이터로 구분하여 비교해봤다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import pandas as pd
from sklearn.preprocessing import LabelEncoder
train_df = pd.read_csv("titanic/train.csv")
train_df['Age'] = train_df['Age'].fillna(train_df['Age'].mean())
label = LabelEncoder()
label.fit(train_df['Sex'])
train_df['Sex'] = label.transform(train_df['Sex'])
train_df.drop(['PassengerId', 'Name', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], axis=1, inplace=True)
train_feature = train_df[['Sex', 'Pclass', 'Age']].values
train_label = train_df['Survived'].values
x_train, x_test, y_train, y_test = train_test_split(train_feature, train_label, test_size=0.3, random_state=11)
dt_clf = DecisionTreeClassifier(random_state=11)
dt_clf.fit(x_train,y_train)
pred = dt_clf.predict(x_test)
print('예측 정확도 : {0:.4f}'.format(accuracy_score(y_test, pred)))예측 정확도 : 0.8321
예측 정확도는 0.8321로... 망했다 ㅇㅅㅇ
