정렬
Numpy에서 정렬을 위해서 np.sort(), ndarray.sort()을 사용했었다. DataFrame와 Series을 정렬하기 위해서는 sort_values()라는 메서드를 사용한다.
DataFrame.sort_values(by, ascending, inplace)by: 특정 칼럼을 입력 하면 해당 컬럼에 대해서 정렬을 수행한다.ascending: default값은 True이다. True는 오름차순, False는 내림차순으로 정렬한다.inplace: default값은 False이다. True이면 원본 DataFrame를 가지고 정렬이 적용이 되고, False이면 원본 DataFrame은 놔두고 새 DataFrame이 반환된다.
타이타닉 데이터를 Name로 정렬을 해보자
titanic_sort = titanic_df.sort_values(by=['Name'])
titanic_sort.head()
여러개의 칼럼을 가지고 정렬을 하려면 by 파라미터에 리스트로 정리를 해주면 된다. 근데 여기서 주의할 점이 있다.
titanic_sort = titanic_df.sort_values(by=['Pclass', 'Name'])
titanic_sort.head()
titanic_sort = titanic_df.sort_values(by=['Name' , 'Pclass'])
titanic_sort.head()이 두 코딩의 결과물은 같을까?? 위에것은 Pclass, Name순으로, 아래는 Name, Pclass순으로 뒀다.
결과물을 한번 비교해보자


결과물이 명백히 다르다. 이 차이점은 순서에서 온다. by 파라미터에 리스트로 여러개의 칼럼을 지정해줄 때, 앞에 있는 칼럼명부터 우선적으로 정렬을 해준다.
즉,
Pclass->Name은Pclass먼저 오름차순으로 정렬하고,Name을 정렬해준다.
Pclass가 1인 데이터 안에서Name을 알파벳 순으로 오름차순 정렬Pclass->Name은Name먼저 오름차순으로 정렬하고,Pclass을 정렬해준다.
Name을 알파벳 순으로 정렬하고, 해당 이름별Pclass를 오름차순 정렬. 하지만 이름이 중복되지 않으니Pcalss의 정렬은 사실상 무의미하다.
Aggregation 함수
Count(), min(), sum()등의 함수를 Aggregation 함수라고 한다. DataFrame에서 이러한 Aggregation 함수를 적용할 수 있다.
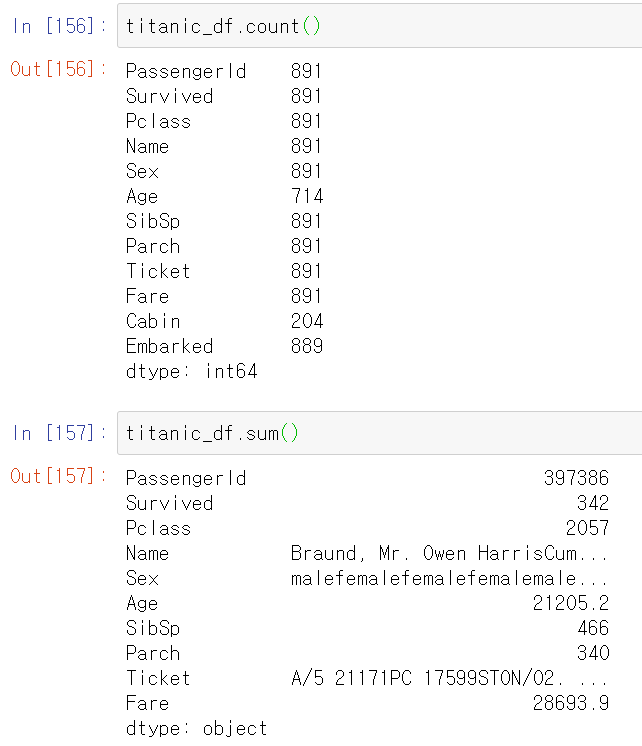
단, DataFrame에서 바로 사용하면 모든 칼럼에 대해서 실행이 된다. 따라서 특정 칼럼에서 사용하고 싶으면 해당 칼럼만 추출해서 적용해야 한다.
titanic_df.Survived.sum()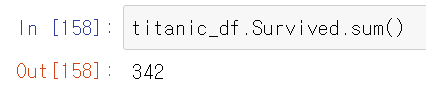
Survived 칼럼에는 결측치가 없는데 sum()을 통해 342가 나온 것을 보면 전체 인원 중 342명만 생존해 있다는 것을 알 수 있다.
여러개의 칼럼도 당연히 가능하다.

groupby()
Pandas에서 groupby()는 분석 작업에서 자주 사용된다. by파라미터에서 해당 칼럼을 넣어주면 대상 칼럼으로 groupby()가 이루어진다. 이 때 by는 생략 가능
titanic_groupby = titanic_df.groupby(by='Pclass')
print(type(titanic_groupby))
print(titanic_groupby)
titanic_groupby = titanic_df.groupby('Pclass')
print(type(titanic_groupby))
print(titanic_groupby)
type을 살펴보면 DataFrameGroupBy라는 또 다른 형태의 DataFrame을 반환한다. titanic_groupby를 print해도 DataFrame이 출력되지 않고 이상한 글만 출력이 된다.
여기서 groupby() 함수에 Aggregation 함수를 호출하면 groupby() 대상 칼럼을 제외한 모든 칼럼에 해당 함수를 적용한다.
titanic_groupby = titanic_df.groupby('Pclass').count()
print(type(titanic_groupby))
titanic_groupby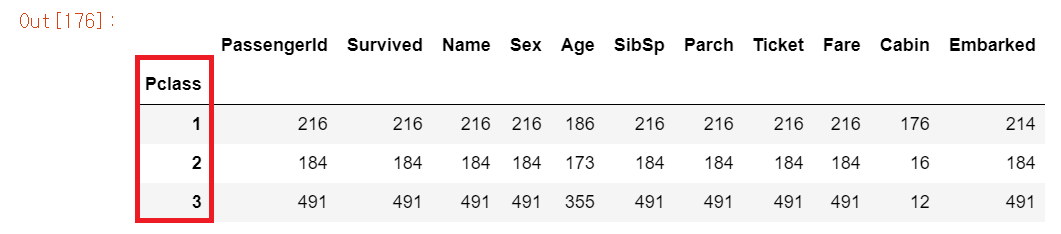
전에 Pclass의 unique() 또는 value_counts()했을 때 값이 1,2,3 이었다.
즉 이 칼럼에는 해당하는 값이 1,2,3뿐이라는 것인데, 이 칼럼을 가지고 groupby()하면 해당 값들끼리 그룹화 하여 해당 데이터의 개수를 count한다. Non-Null 데이터를 가지고 확인해보면
Pclass 1: 216개Pclass 2: 184개Pclass 3: 491개
라는 것을 알 수 있다.
근데 이상한 점이 index부분은 없고 Pcalss가 그 자리를 대신한다. 그래서 as_index라는 파라미터를 사용한다.
titanic_groupby = titanic_df.groupby('Pclass', as_index=False).count()
print(type(titanic_groupby))
titanic_groupby
as_index를 False로 설정하면 index가 생긴다. 이 이유는 groupby()함수를 그냥 실행하면 그룹 대상 칼럼이 index화 된다. 근데 as_index를 False로 설정하면 적용 대상 칼럼이 index화 되지 않는다.
Pclass 칼럼으로 그룹화 했는데 count()함수를 실행해서 해당 Pclass마다 데이터 수를 셀 수 있다. Age칼럼을 보면 어떤 Pclass에서 결측치가 얼마나 되는지 알 수 있다.
특정 칼럼에만 groupby() 적용
모든 칼럼이 아닌 특정 칼럼에만 groupby()를 적용할 수 있다.
groupby()를 실행하고 반환된 DataFrameGroupBy에 적용할 칼럼을 따로 필터링하면 된다.
titanic_df.groupby('Pclass', as_index=False)[['Name', 'Age']].count()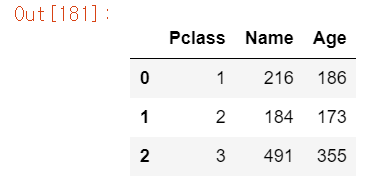
Pcalss별로 그룹화 하고 Name와 Age 칼럼에만 count()를 적용했다.
여러 칼럼 기준 groupby() 적용
groupby() 메서드에서 by파라미터로 여러개의 칼럼도 설정이 가능하다. 물론 복수의 칼럼은 리스트로 묶어줘야 한다.
titanic_df.groupby(['Pclass', 'Sex'], as_index=False)[['Name', 'Age']].count()
titanic_df.groupby(['Sex', 'Pclass'], as_index=False)[['Name', 'Age']].count()이것도 sort_valeus()처럼 왼쪽먼저 기준을 잡는다.
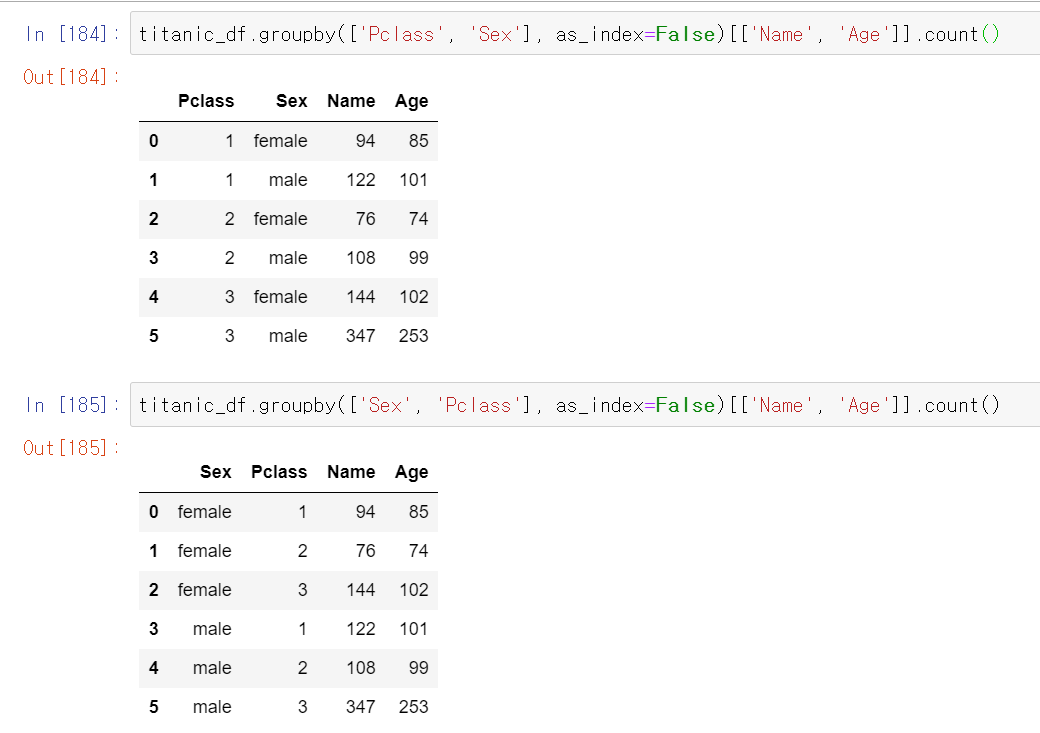
Pcalss->Sex: 우선Pclass별로 그룹화하고 오름차순으로 정렬하여 해당Pclass별Sex로 그룹화Sex->Pcalss: 우선Sex별로 그룹화하고 오름차순으로 정렬하여 해당Sex별Pclass로 그룹화
근데 결과 값은 같다. 표시 방법만 다를 뿐
여러개의 Aggregation 함수 적용
groupby()에서 여러개의 Aggregation함수를 적용하려면 agg() 내에 인자로 해당 함수들을 입력해준다.
titanic_df.groupby(['Sex', 'Survived'], as_index=False)['Age'].agg([max, min])
물론 적용 칼럼도 복수가 가능하다.
titanic_df.groupby(['Sex', 'Survived'], as_index=False)[['Age', 'Fare']].agg([max, min])
만약 각 칼럼에 서로 다른 Aggregation 함수를 지정하려면 딕셔너리 형태로 각각 지정해줘야 한다.
agg_form = {'Age':'max', 'SibSp':'sum', 'Fare':'mean'}
titanic_df.groupby('Pclass', as_index=False).agg(agg_form)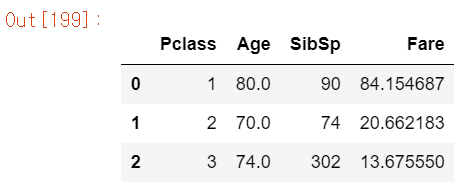
딕셔너리로 Age에는 max, SibSp에는 sum, Fare에는 mean 함수를 적용했다.
결측치 처리
결측치란 해당 칼럼에서 값이 없는 데이터를 의미하며(NULL 값), Numpy에서 NaN으로 표현된다. 머신러닝 알고리즘은 이 결측치를 따로 처리해주지 않기 때문에 전처리단계에서 직접 다른 값으로 대체해야 한다. 그리고 결측치는 평균, 총합 등 함수 연산에서 제외된다.
결측치 데이터 여부 확인
isna() 메서드는 결손 데이터의 여부를 알려준다. DataFrame에서 isna()를 수행하면 모든 칼럼의 값이 NaN의 여부를 boolean으로 알려준다.
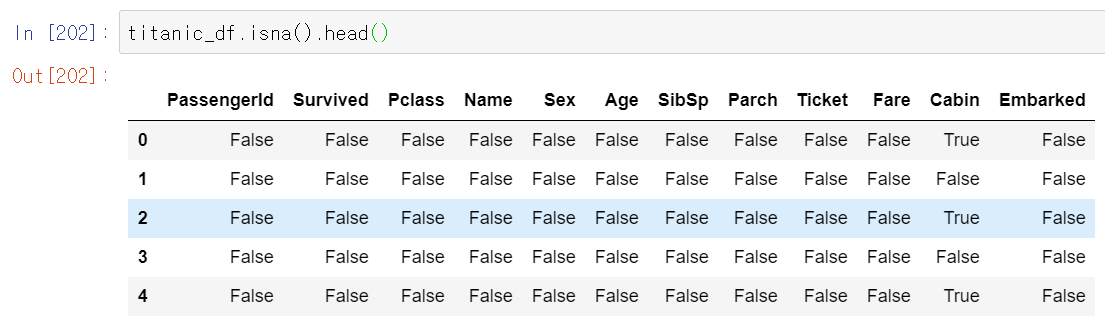
헌데 이렇게 봐서는 각 칼럼에서 결측치가 몇개인지 알 수 없다. 그래서 sum()함수를 이용하여 결손 데이터의 개수를 알 수 있다.
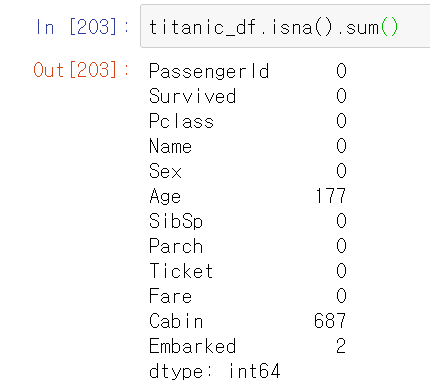
Age칼럼에는 결측치가 177개Cabin칼럼에는 결측치가 687개Embarked칼럼에는 결측치가 2개
결손 데이터 대체
fillna() 메서드를 사용 시 결측치 데이터를 다른 값으로 대체할 수 있다. 결손 데이터를 대체값으로 대체하는 방법에는 여러가지가 있다.
단순 대치법
단순 대치법에는 결측값이 존재하는 레코드를 모두 삭제하는 방법, 평균 대치법과 단순확률 대치법이 존재한다.
평균 대치법에는 두가지 방법이 있다.
- 비조건부 평균 대치법 : 관측데이터의 평균으로 대체
- 조건부 평균 대치법 : 회귀분석을 이용한 대치법(결측치를 포함한 칼럼과 상관관계가 있거나, 통계량이 유효한 칼럼끼리 회귀분석 하여 결측치를 대체)
단순확률 대치법은 평균 대치법에서 추정량 표준 오차의 과소 추정문제를 보완하고자 고완된 방법이다.
- Hot-deck 방법 : 최빈값을 채워 놓는다.
- nearest neighbor 방법 : 결측치 포함 칼럼을 제외한 나머지 칼럼들에서 거리가 가장 가까운 칼럼을 채워놓는다.
.jpg)
위 데이터를 예로 들면 결측치를 포함한 레코드에서 Y1, Y2칼럼을 비교하면 2번째 레코드와 비슷함을 알 수 있다. 그래서 결측치를 C라고 예측 대입하는 것이다.
다중 대치법
단순대치법을 한번 하지 않고 n번 실행하여 n개의 가상의 완전 자료를 만드는 것이다.
- 1단계 : 대치
- 2단계 : 분석
- 3단계 : 결합
fillna()
titanic_df['Cabin'] = titanic_df['Cabin'].fillna('C000')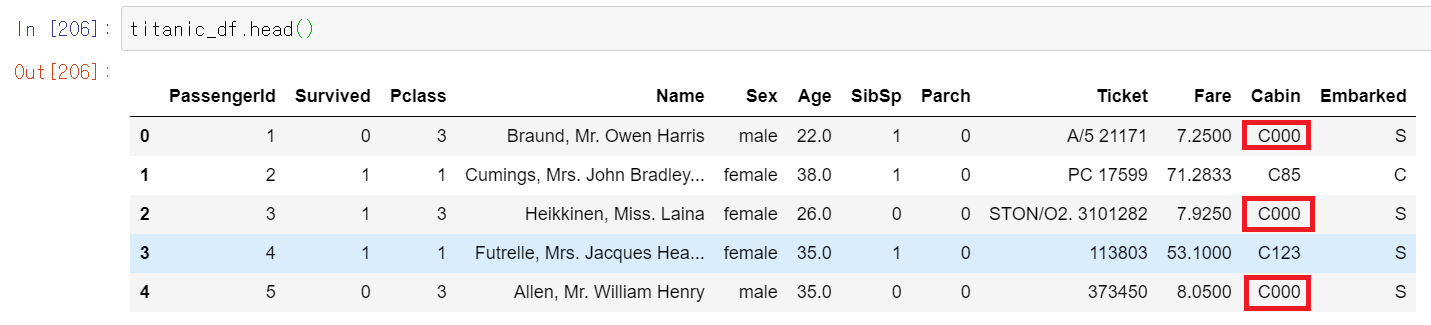
fillna()함수로 Cabin 칼럼에서 결측치를 'C000'으로 채웠다. fillna()메서드를 사용시 주의할 점은 반환값을 다시 받거나 파라미터중 inplace를 True로 설정하여 원본 데이터를 변경해야 하는 것이다.
titanic_df['Cabin'] = titanic_df['Cabin'].fillna('C000')
titanic_df['Cabin'].fillna('C000', inplace=True)이번엔 Age를 평균값으로, Embarked를 'S'로 대체해보려고 한다.
titanic_df['Age'].fillna(titanic_df['Age'].mean(), inplace=True)
titanic_df['Embarked'].fillna('S', inplace=True)
titanic_df.isna().sum()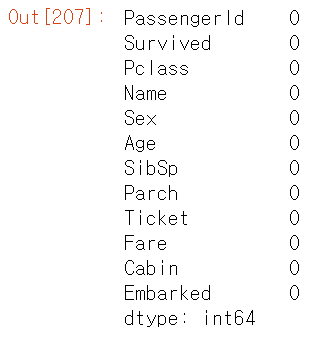
데이터 가공
Pandas에서 apply 메서드에 lambda 식을 결합하여 DataFrame이나 Series의 레코드별로 데이터 가공을 한다.
lambda
파이썬에서 lambda는 함수 선언과 처리 내용을 한줄의 식으로 변환하는 식이다.
def ft_square(n):
return n**2
print(ft_square(3))
lambda_square = lambda x: x**2
print(lambda_square(3))위 두 식의 결과는 똑같이 9이다. lambda 식에서 :을 기준으로 입력 인자와 계산식을 분리하여 적는다.
lambda 식으로 여러개의 값을 입력인자로 받을 때는 map() 함수를 결합한다.
a = [1,2,3]
square = map(lambda x : x**2, a)
print(type(square))
list(square)
map()함수를 통해 반환된 결과값은 map이라는 타입을 가진다. 그리고 결과값을 list로 변환하면 각 리스트 인자마다 lambda 식이 적용이 된 것을 알 수 있다.
apply
판다스의 lambda는 파이썬의 기능과 똑같다. 여기서 apply() 함수를 적용하여 데이터를 가공해보자.
titanic_df['Name_len'] = titanic_df['Name'].apply(lambda x: len(x))
titanic_df[['Name', 'Name_len']].head()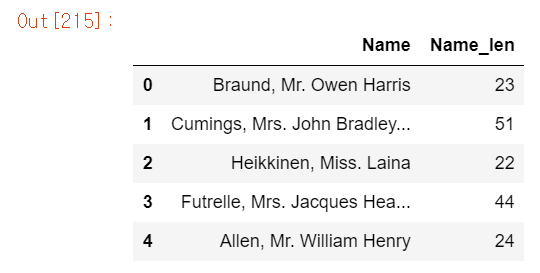
titanic_df의 Name 칼럼에서 문자열 길이를 계산하여 Name_len이라는 새로운 칼럼을 만들어 값을 넣어줬다.
이 lambda에는 조건문도 가능하다.
titanic_df['Child_Adult'] = titanic_df['Age'].apply(lambda x: 'Child' if x <= 15 else 'Adult')
titanic_df[['Age', 'Child_Adult']].head()
이 때 조건문을 좀 특이하게 사용한다.
.jpg)
lambda는 if, else만 지원한다. if, else if, else와 같이 else if는 지원하지 않는다. else if를 사용하려면 else 절을 ()로 묶고 내부에서 다시 if else를 사용해야 한다.
titanic_df['Age_cat'] = titanic_df['Age'].apply(lambda x: 'Child' if x <= 15 else ('Adult' if x <= 60 else 'Elderly'))
titanic_df['Age_cat'].value_counts()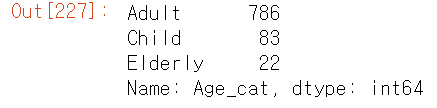
하지만 이렇게 lambda 식안에 여러개의 if, else 절을 쓰기는 부담스럽고 가독성이 떨어진다. 그래서 따로 함수를만들어서 적용하는 것이 좋다.
# 나이별로 세분화 함수
def get_category(age):
cat = ''
if age <= 5: cat = 'Baby'
elif age <= 12: cat = 'Child'
elif age <= 18: cat = 'Teenager'
elif age <= 25: cat = 'Student'
elif age <= 35: cat = 'Young Adult'
elif age <= 60: cat = 'Adult'
else: cat = 'Elderly'
return cat
# 함수 적용
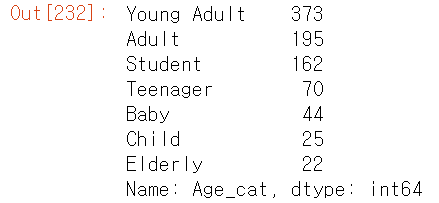
titanic_df['Age_cat'] = titanic_df['Age'].apply(lambda x: get_category(x))
titanic_df['Age_cat'].value_counts()