세번째 타이타닉 분석이다. 이러다 진짜 타이타닉 마스터하겠소...
이번엔 새로운 방식을 사용한 것만 설명하려고 한다.
모듈
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from collections import Counter
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier,\
ExtraTreesClassifier, VotingClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV, cross_val_score, StratifiedKFold, learning_curve
import plotly.express as px
sns.set(style='white', context='notebook', palette='deep')
plt.rcParams['figure.figsize'] = [10, 6]
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import LabelEncoder
from sklearn.impute import KNNImputer데이터
train = pd.read_csv("/kaggle/input/titanic/train.csv")
test = pd.read_csv("/kaggle/input/titanic/test.csv")
IDtest = test['PassengerId']분석
이상치 분석
fig, ax = plt.subplots(2, 2, figsize=(20, 10))
sns.boxplot('Age', data=train, ax=ax[0,0])
ax[0,0].set_title("Outlier of Age")
sns.boxplot(train['Parch'], ax=ax[0,1])
ax[0,1].set_title("Outlier of Parch")
sns.boxplot(train['SibSp'], ax=ax[1,0])
ax[1,0].set_title("Outlier of SibSp")
sns.boxplot(train['Fare'], ax=ax[1,1])
ax[1,1].set_title("Outlier of Fare")
plt.show()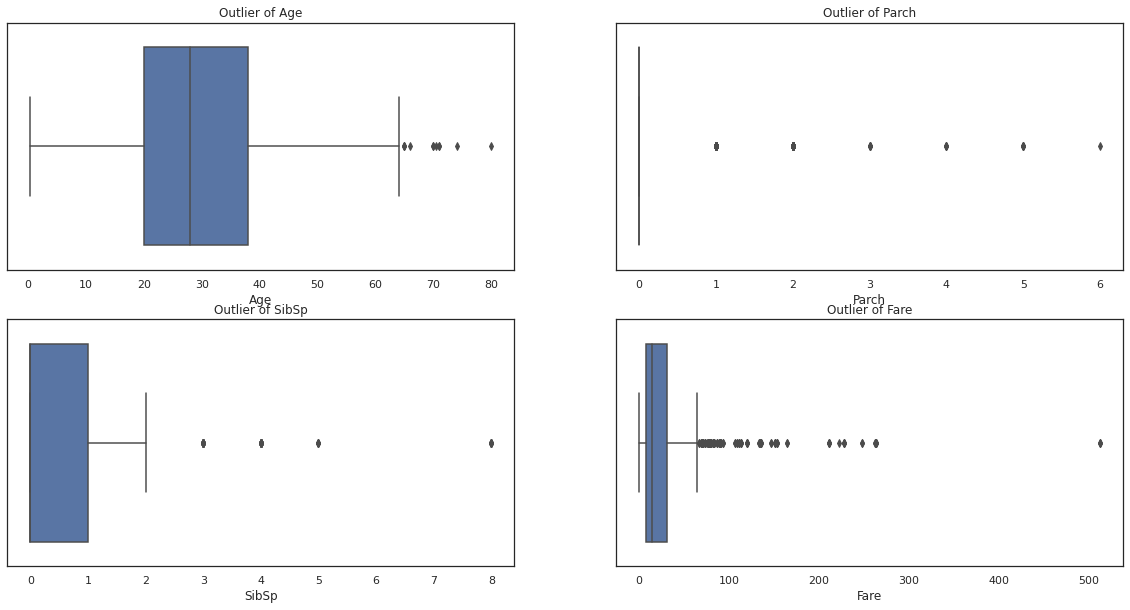
이번엔 이상치를 검색해서 이상치가 2개 이상인 행만 제거하고 분석하려고 한다. 일단 이 boxplot은 이상치 분석을 하기전에 한번 데이터 분포도를 보려고 그려봤다.(필사엔 없는 내용)
또한 이상치를 확인해보기 위해 데이터 프레임을 분석해봐도 된다.
train.describe()
def detect_outlier(df, n, features):
outlier_ind = []
for col in features:
Q1 = np.percentile(df[col], 25)
Q3 = np.percentile(df[col], 75)
IQR = Q3 - Q1
outlier_step = 1.5 * IQR
outlier_list_col = df[(df[col] > Q3 + outlier_step)].index # 그래프로 확인해본 결과
outlier_ind.extend(outlier_list_col)
outlier_ind = Counter(outlier_ind)
multi_outlier = list(k for k, v in outlier_ind.items() if v > n)
return multi_outlier위 함수는 사분위수를 이용해서 이상치를 제거하는 것이다. boxplot의 outer fance밖에 있는 데이터 값 제거
outliers_drop = detect_outlier(train, 2, ['Age', 'SibSp', 'Parch', 'Fare'])
outliers_drop[27, 88, 159, 180, 201, 324, 341, 792, 846, 863]
train = train.drop(outliers_drop, axis=0).reset_index(drop=True) # drop하면 열로 생성한 열을 DF에서 삭제학습 데이터에서 이상치를 가진 행을 삭제해주었다.
시각화
factorplot()
g = sns.factorplot(x="SibSp", y="Survived", data=train, kind='bar', size=6,
palette="muted")
g.despine(left=True)
g = g.set_ylabels("Survival probability")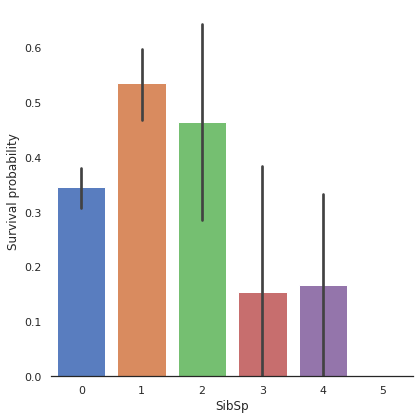
factorplot은 factor형 변수의 시각화를 할 때 유용한 시각화이다. 위 그림은 SibSp별 생존율을 시각화한 그래프이다.
g = sns.factorplot("Pclass", col="Embarked", data=train, kind="count", size=6,
palette="muted")
g.despine(left=True)
g = g.set_ylabels("Count")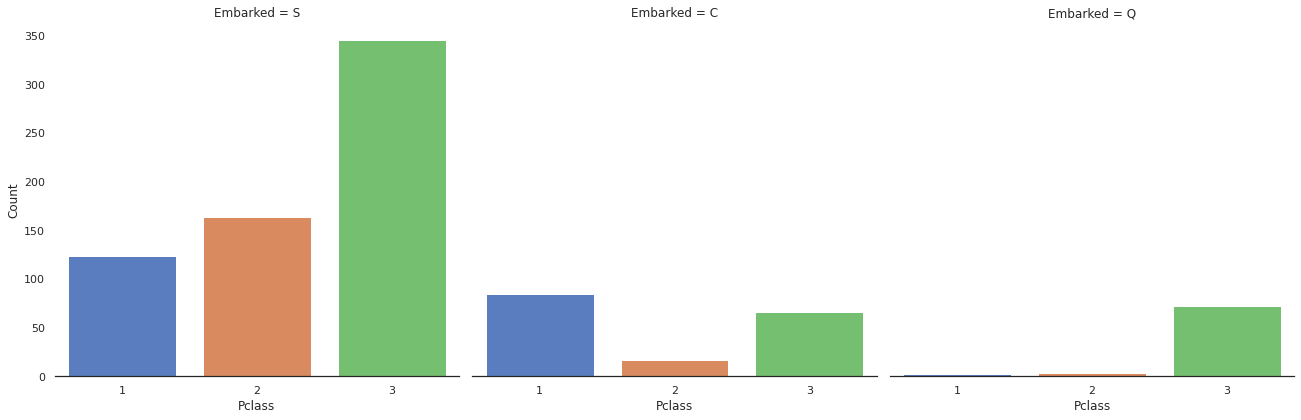
factorplot은 kind에 따라 여러가지 유형으로 나눌 수 있다. count의 방법을 사용하면 각 변수의 개수를 셀 수 있다.
FacetGrid()
g = sns.FacetGrid(train, col="Survived", size = 10)
g = g.map(sns.distplot, "Age")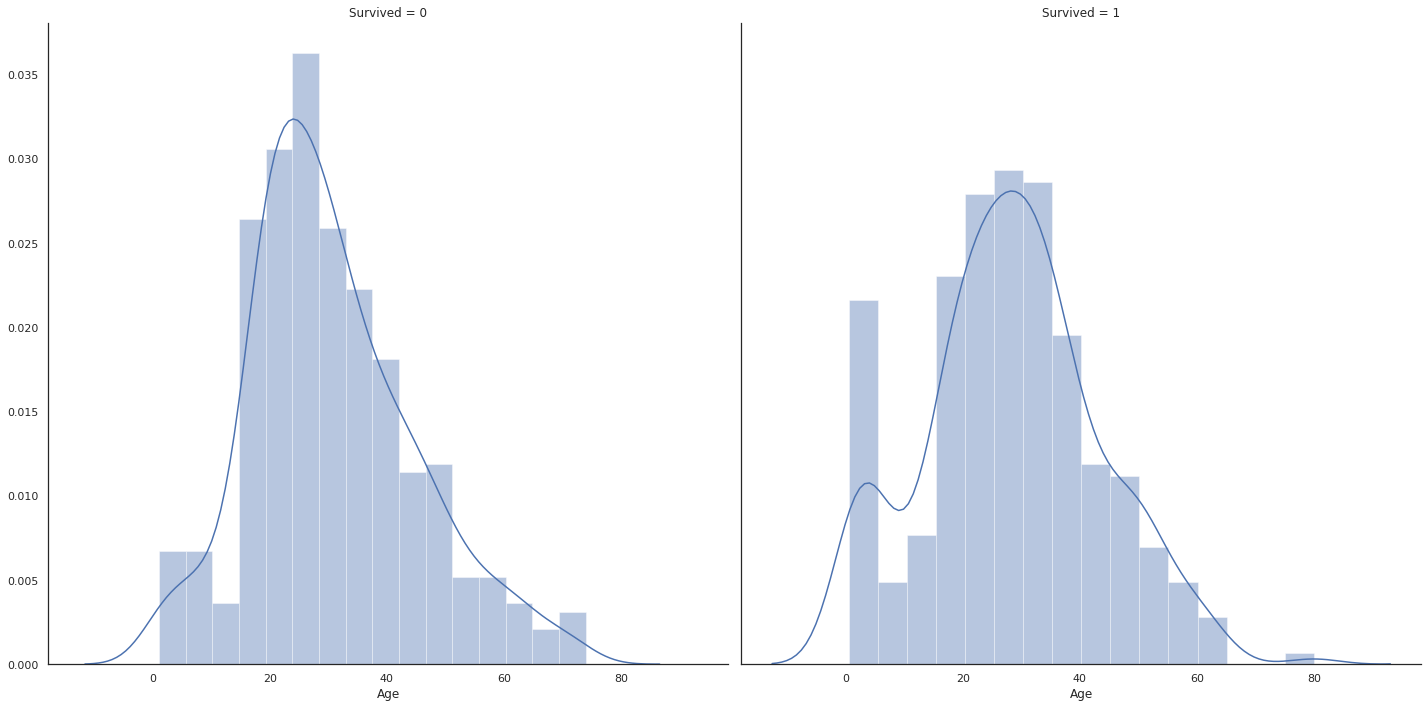
FacetGrid로 생존유무별로 col을 나누고 map함수를 통해 각각의 Grid에 distplot을 삽입한다.
kdeplot()
g = sns.kdeplot(train['Age'][(train['Survived'] == 0) & (train["Age"].notnull())], color='Red',
shade=True)
g = sns.kdeplot(train['Age'][(train["Survived"] == 1) & (train['Age'].notnull())], color='Blue',
shade=True)
g.set_xlabel("Age")
g.set_ylabel("Frequency")
g = g.legend(["Not Survived", "Survived"])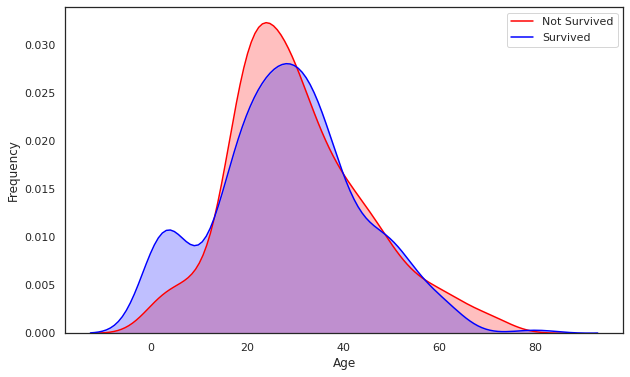
kdeplot은 kernel density estimation의 약자로 확률 밀도를 추정한다. 이 그래프는 이산(discrete) 변수를 연속형으로 만들어준다.
distplot()
g = sns.distplot(dataset['Fare'], color='m', label="Skewness : %.2f"%(dataset['Fare'].skew()))
g.legend(loc='best')
이 distplot은 히스토그램과 위 kdeplot을 같이 시각화해주는 함수이다.
countplot()
g = sns.countplot(x="Title", data=dataset)
g = plt.setp(g.get_xticklabels(), rotation=45)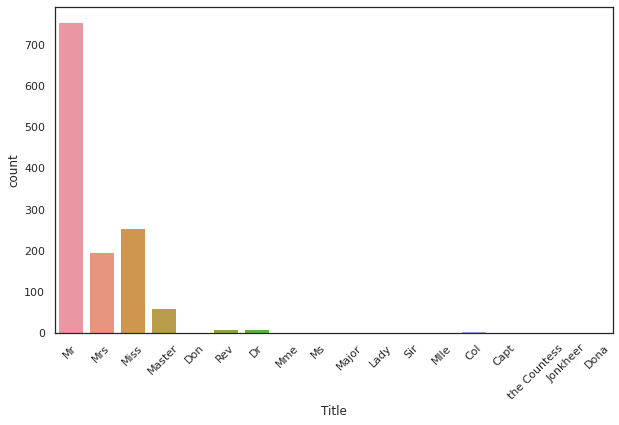
각 명목형 변수에 대해서 count해주는 그래프이다.
setp는 그래프 오브젝트에 대해 특성을 setting해준다. 선의 모양을 변경해줄 수 있고, 위 그래프처럼 범례를 수정해줄 수 있다.
결측치 처리
결측치를 처리하는 방법은 여러가지가 있다. 중간값, 최빈값을 넣어주는 간단한 방법도 있고, 여러 과정을 거쳐 처리하는 방법도 있다.
그 중에 KNN을 이용한 방법으로 결측치를 처리하려고 한다.
우선 KNN을 처리하기 위해선 모든 데이터를 수치화해야 한다.
그래서 Cabin, Name, Ticket을 따로 제외시켜두고 Sex는 LabelEncoder, Embarked은 get_dummies 함수를 이용하여 OneHotEncoder를 대체하려고 한다.
data = dataset[['Cabin', 'Name', 'Ticket']]
dataset.drop(['Cabin', 'Name', 'Ticket'], inplace=True, axis=1)
# LabelEncoder
le = LabelEncoder()
le.fit(dataset['Sex'])
dataset['Sex'] = le.transform(dataset['Sex'])
# get_dummies
dataset = pd.get_dummies(dataset, columns=['Embarked'], prefix="Em")
# KNN
imputer = KNNImputer(n_neighbors=5)
dataset = imputer.fit_transform(dataset)
# KNN을 이용해서 결측치를 처리하면 ndarray로 반환되서 DataFrame으로 변환해줘야 한다.
dataset = pd.DataFrame(dataset, columns=['index', 'PassengerId', 'Survived', 'Pclass',
'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Em1', 'Em2', 'Em3'])필사한 노트북에서는 Parch, SibSp ,Pclass를 이용하여 결측치 처리하였다.
index_NaN_age = list(dataset["Age"][dataset["Age"].isnull()].index)
for i in index_NaN_age :
age_med = dataset["Age"].median()
age_pred = dataset["Age"][((dataset['SibSp'] == dataset.iloc[i]["SibSp"]) & (dataset['Parch'] == dataset.iloc[i]["Parch"]) & (dataset['Pclass'] == dataset.iloc[i]["Pclass"]))].median()
if not np.isnan(age_pred) :
dataset['Age'].iloc[i] = age_pred
else :
dataset['Age'].iloc[i] = age_med결과
이 노트북을 2번 필사했다. 처음엔 그대로 필사했고 두번째부터는 내 개인적인 생각을 첨가해서 두번째 필사때는 다음과 같이 분석을 해보았다. 결측치를 KNN으로 처리하고 Ticket도 추가적으로 삭제하고, Family Size도 4가지에서 3가지로 줄이는 등 여러가지 필요없다고 생각되는 부분을 줄이려고 많이 노력했으나 결과는 참혹...😞😞 슬프긴 하지만 왜 결과가 너무 안좋게 나왔는지 파악을 해보려고 한다.
