데이터 마트란?
.jpg)
데이터의 흐름은 다음과 같다.
Legacy에서 Staging을 거쳐 ODS에서 데이터 전처리를 거친다음 DW에 저장을 한다. 그 후 특정 주제, 부서에 맞게 데이터를 다시 저장
즉, 작은 범위의 데이터 웨어하우스라고 할 수 있다.
데이터 마트의 데이터는 대부분 DW에서 가져오기도 하지만 자체적으로도 수집이 가능하다. 그리고 RDB나 다차원 데이터 베이스를 이용하여 구축한다.
데이터 마트의 중요성
근래의 데이터 분석 기법은 어느정도 발전이 되어있다. 그래서 숙련된 분석가가 같은 데이터 셋을 가지고 분석을 할 경우 결과물의 차이가 크게 나지 않을 것이다.
그래서 데이터 마트를 어떻게 구축하느냐에 따라 분석효과의 차이가 나기 때문에 데이터 마트는 분석시에 중요하다.
변수
데이터 마트를 구축시에는 보통 데이터 웨어하우스에서 데이터들을 가져온다. 그리고 이 데이터를 분석에 사용될 수 있게 처리과정을 거쳐야 한다. 이 과정을 거치면 변수들은 요약변수와 파생변수로 나눠진다.
요약변수
요약변수는 우리가 쉽게 생각할 수 있는 변수이다. 요약변수에 어떤 것들이 있나 확인해보면 구매 금액, 구매 횟수, 구매 여부 등이 있다. 이와 같은 예시를 보면 단순 데이터들을 종합한 변수라고 생각할 수 있다. 즉, 요약변수는 데이터 웨어하우스에서 받아온 데이터를 특정 분석 목적에 적합하게 종합한 변수이다.
- 장점
요약변수는재활용성이 높다. 다른 많은 모델을 공통으로 사용될 수 있다. - 단점
얼마 이상이면 구매하더라도 기준값의 의미 해석이 애매해진다.
-> 연속형 변수를 그룹핑해 사용하는 것이 좋다.
심화 예시
| 요약변수 | 의미 |
|---|---|
| 위클리 쇼퍼 | 구매 시기를 통해 고객의 특성을 추정하는데 활용이 가능하다. |
| 상품별 구매 순서 | 고객에 대한 이해와 해석력을 높일 수 있다. |
| 초기 행동변수 | 고객 가입 또는 첫 거래 초기 1개월간 거래 패턴에 대한 변수로 1년 후에 어떤 행동을 보일지를 평가하는 지표 |
| 연속형 변수의 구간화 | 분석 후 적용단계를 고려한 데이터 분석을 위해 연속형 변수를 구간화 해야한다. 1, 10, 100 등 의미없이 아무렇게 구간화하지 말고 의미있는 구간으로 구간화한다. |
파생변수
파생변수는 분석가가 특정 조건을 만족하거나 함수에 의해 값을 만들어서 의미를 부여한 변수이다. 분석가가 개인의 의견이 들어가서 주관적일 수 있으므로 논리적 타당성을 갖추어 개발해야 한다. 세분화, 고객행동 예측, 캠페인 반응 예측 등에 활용된다.
- 주의 : 상황에 따라 특정 상황에만 유의미하지 않게 대표성을 띄어야 한다.
심화 예시
| 파생변수 | 의미 |
|---|---|
| 근무시간 구매지수 | 근무시간대에 거래가 발생하는 비율을 산출하여 활용 |
| 주 구매 매장 변수 | 고객의 주 거래 매장을 예측하여 적절한 분석에 활용 |
| 라이프스타일 변수 | 고객의 라이프스타일을 보고 상품구매를 유도하는데 활용 |
| 주 구매상품 변수 | 상품을 추천하는데 활용 |
데이터 마트 개발
reshape
데이터 마트를 개발하는데 R에서 reshape라는 패키지를 활용한다. reshape에는 melt와 cast라는 함수가 있다. 주조할때 사용하는 그 melt와 cast 맞다.
melt(): 원 데이터 형태로 만든다.cast(): 요약 형태로 만든다.
변수를 조합하여 새로운 변수명을 만들고 변수들을 시간, 상품 등의 차원에 결합하여 다양한 요약 및 파생변수를 쉽게 생성하여 데이터 마트를 구성할 수 있게 한다.
install.packages("reshape")
library(reshape)
data(iris)
melt(iris, id = c("Petal.Length", "Petal.Width","Sepal.Length", "Sepal.Width"), na.rm = T)iris데이터를 가지고 reshape를 활용해봤다. 결측값을 제거해주는 것이 좋기때문에 na.rm = T을 통해 결측값 제거를 실행해줬다.

Sepal의 길이, 넓이와 Petal 길이, 넓이에 따라 종류가 어떻게 변화되는지 확인해보고 싶어 위와 같은 코드를 짜보았다. 물론 전체 데이터는 위 사진보다 훨씬 많지만 일정 부분만 따로 잘라내어 가져와봤다.
cast는 airquality라는 데이터를 가지고 실행해봤다.
cast(aqm, Day ~ Month ~ variable)aqm은 airquality 데이터를 'Month'와 'Day'를 가지고 melt시킨 데이터이다.
결과물은
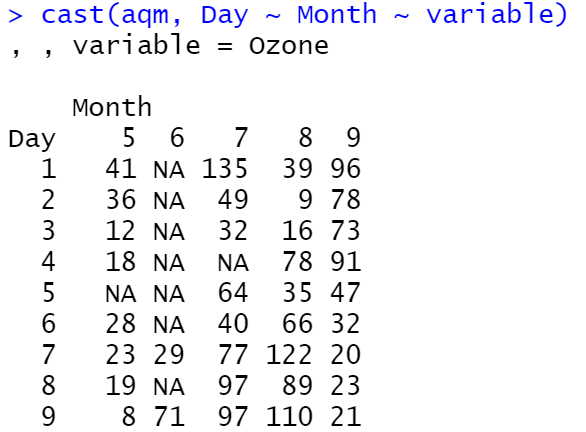
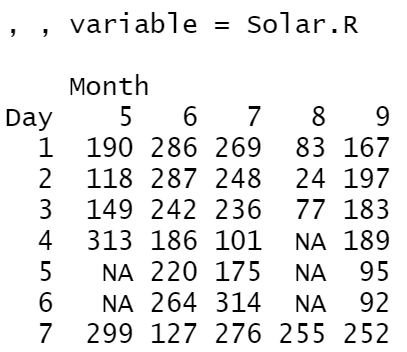
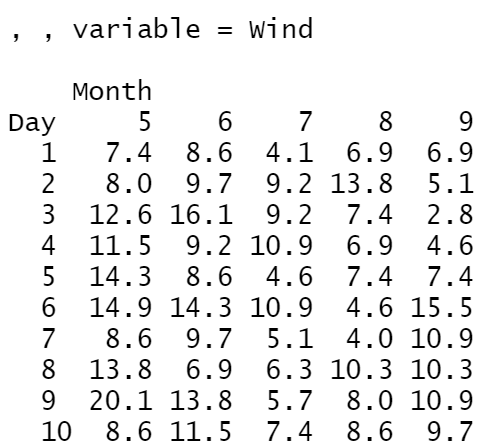
cast할 시에 3차원 구조로 해주었기 때문에 variable가 각각
1. Ozone
2. Solar.R
3. Wind
일 때 cast가 된 데이터 구조가 나온다.
