개요
어플의 매출을 증가하기 위해 광고를 이용하려고 한다. 크게 인터넷 광고와 미디어 광고가 있는데, 이 중에서 미디어 광고에 집중을 한다.
이용하려는 미디어 광고의 종류는 TV광고와 잡지 광고가 있다. 이들을 이용하여 신규 유저수를 증가시키기 위해 광고비 비율을 정하려고 한다.
이용 데이터는 과거의 TV 및 잡지 광고비 대비 신규 유저수이다. 이 과거 데이터를 가지고 미래 데이터를 예측해야 하기 때문에 회귀분석을 이용하려고 한다.
ad_data = pd.read_csv("C:/Users/HwanSeob/Desktop/R/DataAnalysis_src/R/ad_result.csv")
이 데이터를 시각적으로 이해하기 위해 scatter 그래프를 사용해봤다.
px.scatter(ad_data, x='tvcm', y='magazine', size='install', color = 'install').png)
대체적으로 tv와 잡지 광고비가 클수록 신규 유저의 수도 증가함을 알 수 있다.
선형회귀
단순 선형
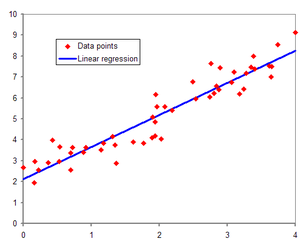
단순 선형 회귀는 설명 변수 x에 대해서 종속 변수 y의 선형 상관 관계를 모델링하는 회귀분석 방법이다. 이는 식 y = ax + b인 일차방정식으로 표현이 가능하다.
선형회귀를 사용하면 설명변수 x에 대해서 y를 예측이 가능하다. 물론 정확한 값은 아니다. 예측은 말 그대로 근사치의 값을 나타낸다는 것이다.
다중 선형
그러면 다중 선형은 무엇인가? 단순 선형은 설명변수가 x, 딱 하나만 존재할 경우 사용이 가능하다. 그런데 설명 변수 하나가지고는 예측하기가 어려운 것이 현실이다. 어떤 사건에 대해 상관 관계를 설명할 수 있는 변수는 여러가지이기 때문이다. 그러기 때문에 설명변수가 여러개인 다중 선형 회귀식을 사용한다. 이는 식
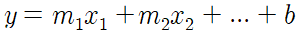
로 표현이 가능하다.
그러나 인간은 시각적으로 3차원까지밖에 이해하지 못한다. 그 이상의 차원은 그래프로 그려낼 수가 없다.
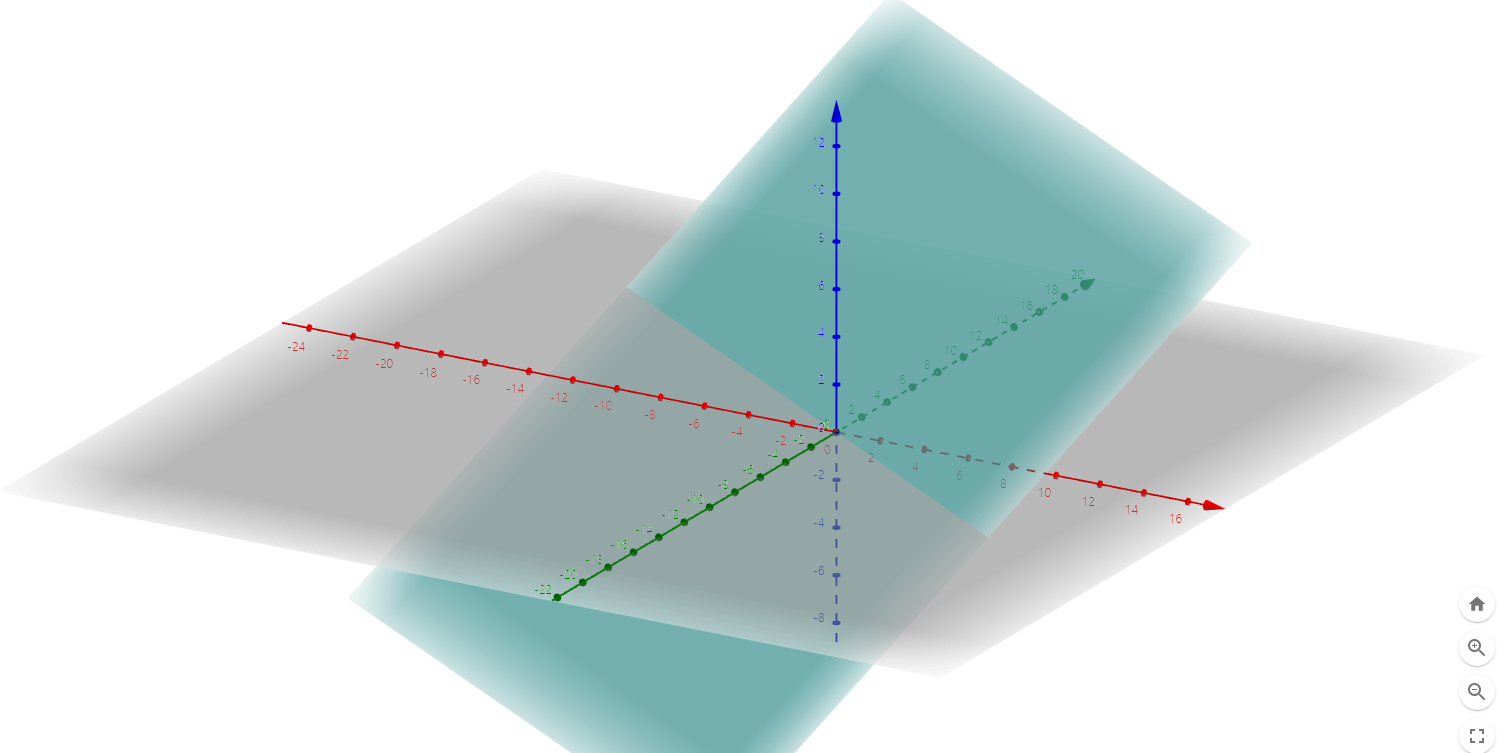
그래서 머신러닝 기법으로 식을 구해서 값을 계산해야 한다.
코드
from sklearn.linear_model import LinearRegression
x = ad_data[['tvcm', 'magazine']]
y = ad_data['install']
mlr = LinearRegression()
mlr.fit(x, y)선형 회귀는 sklearn 모듈에 있다. 그래서 sklearn 모듈에서 LinearRegression 패키지를 임포트 해준다.
다중 선형회귀 학습을 위해 설명 변수(x)와 목표 변수(y)를 구분지어 준다.
그리고 LinearRegression()을 호출해 준 후, 설명, 목표 변수에 fit시킨다. 이제 다중 선형회귀식을 불러올 수 있다.
선형회귀 함수에 대입할 때 주의할점은 2차원 배열을 파라미터로 넣어줘야 한다는 점이다.
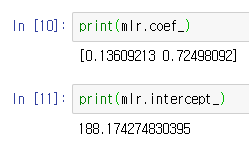
위에서 다중 선형회귀식의 구성에 대해서 알아 봤었다. 이 문제에서는 설명 변수가 두개이므로 계수가 두개와 절편 하나가 도출될 것이다.
coef_: 설명변수의 계수intercept_: 회귀식의 절편
따라서 이 선형회귀 문제의 식은 다음과 같다.

식을 세워봤으니 한번 예측을 해보자.- tvcm = 55000
- magazine = 62000
일 때 신규 유저의 수는 몇명일까?
test = [[55000, 62000]]
y_predict = mlr.predict(test)
print(y_predict)[52622.05817173]
신규 유저는 대략 52622명임을 알아냈다.
회귀분석모델의 상세 검토
다중 선형회귀식의 정확도를 검토할 때에는 잔차분석을 통해 알아볼 수 있다. 잔차란 실제 목표변수 값과 예측 목표변수의 차이이다.
잔차의 분포도를 확인해보면
y_predict = mlr.predict(x)
res = y - y_predict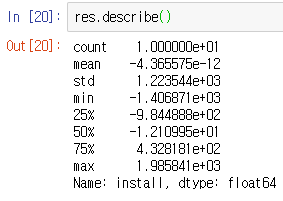
boxplot으로 분포도를 시각화하면
.png)
이번엔 p_value와 R2 결정계수를 확인해보자
import statsmodels.api as sm
from statsmodels.formula.api import ols
result = ols('install ~ tvcm + magazine', data=ad_data).fit()
result.summary()statsmodels라는 모듈에서 다시 선형회귀식을 짰는데, 코딩이 왠지 R이랑 비슷하다.
ols를 통해 다중 선형회귀식을 짜는데 변수들을 넣을 때 목표변수 ~ 설명변수1 + 설명변수2와 같이 파라미터를 대입한다. fit()을 통해 선형회귀식을 만들었으면 이제는 summary()을 통해 확인해보자

tvcm의 p_value는 0.034, magazine의 p_value는 0.004로 0.05 이하이므로 유의미한 계수이다. 결정계수는 0.938, Adj.결정계수는 0.920으로 1에 가까우므로 모델이 주어진 데이터에 적합함을 의미한다.
F-Statistic도 5.97e-05로 0.05이하이므로 모형이 유의미하다.
추가내용

회귀분석에서 result.summary()에서 아래에 Warning이 있는데, 여기서 [2]에 대한 내용이 다중공산성 또는 다른 numerical 문제가 발생했다는 것이다.
잔차도로 확인
import matplotlib.pyplot as plt
result.resid.plot(label = "ad")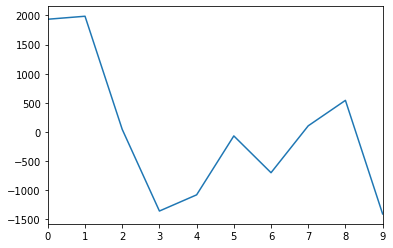
잔차의 분포를 확인해본 결과 정규성, 등분산성을 따르지 않는것으로 확인되었다.
상관계수
import seaborn as sns
x.corr()
cmap = sns.light_palette("darkgray", as_cmap = True)
sns.heatmap(x.corr(), annot = True, cmap=cmap)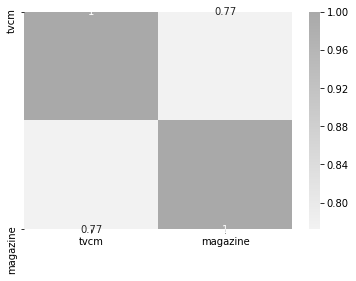
설명변수간에 상관계수를 구해보면 tvcm과 magazine의 상관계수는 0.77로 0.5를 넘기는데 이는 다중공산성을 충분히 발생시킬 수 있다.
pairplot로 확인해본 결과

보다시피 양의 상관관계를 이루는것을 알 수 있다.
VIF
VIF는 variance Inflation Fator으로 다중공산성을 확인할 때 쓰는 지표이다. 한글로는 분산팽창요인이라고도 한다. 보통 VIF가 10보다 큰 경우 다중공산성이 있다고 본다.
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(x.values, i) for i in range(x.shape[1])]
vif['feature'] = x.columns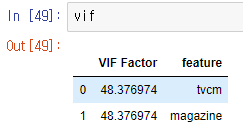
tvcm과 magazine의 VIF 계수가 10을 넘겨 크다는 것을 알 수 있다. 이는 서로 의존적이라는 뜻이므로, 원래대로라면 둘 중 하나를 제거하는게 맞다. 만약 변수가 다양하다면 가장 큰 VIF를 갖는 계수부터 지워보자.
