비즈니스 활용 사례로 배우는 데이터 분석:R을 파이썬으로 재 코딩하면서 공부하려고 시작!!
데이터 수집
어떤 게임이 이번달에 매상이 줄어들었다. 그 문제에 대해서 원인을 밝혀서 대책을 세우는 것이 이번 문제이다.
import pandas as pd
import numpy as np
dau = pd.read_csv("C:/Users/HwanSeob/Desktop/R/DataAnalysis_src/R/section3-dau.csv")
dpu = pd.read_csv("C:/Users/HwanSeob/Desktop/R/DataAnalysis_src/R/section3-dpu.csv")
install = pd.read_csv("C:/Users/HwanSeob/Desktop/R/DataAnalysis_src/R/section3-install.csv")이번 데이터 분석에 필요한 데이터프레임은 총 세가지이다.
dau: 하루에 한 번 이상 게임을 이용한 유저 데이터dpu: 하루에 1원 이상 지불한 유저 데이터install: 유저별로 게임을 설치한 날짜가 기록된 데이터
dau

log_date: 로그인 한 날app_name: 앱 이름user_id: 유저 ID
dpu
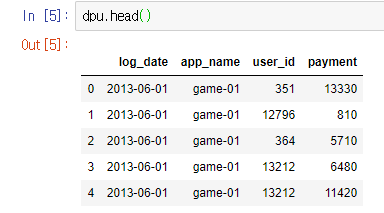
log_date: 로그인 한 날app_name: 앱 이름user_id: 유저 IDpayment: 과금 액수(원)
install
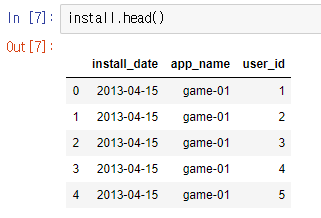
install_date: 설치 한 날app_name: 앱 이름user_id: 유저 ID
데이터 전처리
이번 분석은 매상 감소가 신규 유저의 영향인지 아닌지를 판단하기 위한 분석이다. 신규 유저인지 아닌지를 어떻게 판단할까?
일단 매상은 사람들이 과금을 함으로써 올라간다. 그리고 그 과금을 한 사람이 게임을 설치한 날과 과금을 한 날(월을 기준)이 같으면 신규 유저일 것이고, 아니면 기존 유저일 것이다.
일단 dau 데이터와 install데이터를 병합해서 신규유저와 기존 유저를 구분해보자. 그리고
병합한 데이터와 dpu 데이터를 병합함으로써 날짜를 기준으로 과금을 한 사람과 안 한 사람을 확인해볼 수 있다.
dau_install = pd.merge(dau, install, how = "inner", on = ['app_name', 'user_id'])
dau_install.head()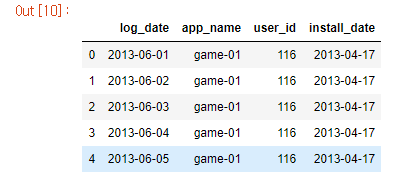
dau데이터와 install데이터를 병합!!
데이터 프레임을 병합할 때 merge 함수를 사용한다. 이 merge 함수에는 여러가지 방법이 존재한다. 맨 처음에는 how = 'left'로 하여 install을 기준으로 dau를 병합하려고 했었다.
dau_install_2 = pd.merge(install, dau, how = "left", on = ['app_name', 'user_id'])
left는 왼쪽의 데이터프레임이 기준이 되어 오른쪽 데이터 프레임이 동일한 키값을 가질 때마다, 병합이 된다. 즉 여기서는 install_date는 한번 뿐이니까 install_date를 기준으로 log_date를 붙여나가는 형식이다.
그런데 문제가 생긴 것이 설치를 하고 게임을 하지 않은 유저가 존재했다는 점이다.
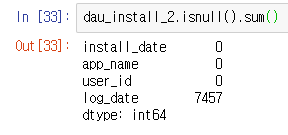
isnull()함수를 활용하여 확인한 결과 log_date에 결측치가 7457개나 존재했다. 그래서 방법을 inner 형식으로 변경했다. 이 방식은 공통된 값이 없으면 생략이 된다. left는 없는 값이 결측치로 추가가 됬지만 여기선 log_date가 없는 경우 생략이 된다.
나중에 생각난건데...
left를 한 후 결측치를 제거하면inner방식과 똑같아진다. ㅇㅅㅇdau_install_2 = dau_install_2.dropna(axis=0)전체 행의 개수를 비교해보니까 똑같았다.
그 다음에 과금액을 병합해주기로 했다. 여기서도 merge함수를 쓰는데 outer방식을 써도 되고 left방식을 써도 된다. 일단 과금을 했다는것은 게임에 로그인을 했다는 의미로 dau_install 데이터에 결측치가 생길리가 없다. 대신 과금액에서 결측치가 생길 텐데, 이 결측치는 없애면 안된다. 이 결측치의 의미는 과금을 하지 않았다는 의미니까 0으로 대체를 해주면 된다.
dau_install_payment = pd.merge(dau_install, dpu, how = "outer", on = ['log_date', 'app_name', 'user_id'])
이 다음에 결측치를 0으로 대체하기 위해 fillna()함수를 이용.
dau_install_payment = dau_install_payment.fillna(0)
그러면 보다시피 NaN 결측치가 0으로 바뀐것을 알 수 있다.
이제 그럼 신규유저와 기존유저를 구별해보기 위한 전처리를 해보자.
이번 데이터를 보면 log_date와 install_date 모두 %Y-%m-%d 의 형태를 가진다.

이 데이터 타입은 모두 object로 문자열을 의미한다. 그러면 유저타입을 월 단위로 신규와 기존을 구별하자고 가정하자. 그럼 일단위는 필요가 없다. 따라서 월단위까지만 남겨두는 전처리를 해보자.
df.dtypes으로도 데이터 타입을 확인할 수 있다.
dau_install_payment['log_month'] = dau_install_payment["log_date"].str[:7]
dau_install_payment["install_month"] = dau_install_payment.install_date.str[:7]
간단하게 str()함수로 문자열을 인덱싱해줬다.
여기서 바로 신규 및 기존 유저를 구분하는 열을 만들어도 되지만, 이번 데이터 분석을 위해서는 id별 총 과금액을 구해야한다. 총 과금액을 구하면 전체 데이터 프레임 크기도 줄어들것이라고 판단되어 먼저 총 과금액을 구하고 난 후 유저타입을 구별하려고 한다.
mau_payment_2 = dau_install_payment.groupby(['log_month', 'user_id', 'install_month'], as_index = False)['payment'].sum()
group함수를 사용하여 log_month, user_id, install_month을 기준으로 하여 payment의 합을 구한다.
groupby를 사용할 시 주의할 점은 as_index = False로 설정해야 하는 점이다. 이를 설정하지 않으면 Pandas 복합 인덱스로 올라가서 변환되거나 사용되기 어려워진다.
이제는 유저타입을 결정해주자. 먼저 함수를 하나 만들어줬다.
def user_type(log, install):
if (log == install):
return "install"
else:
return "existing"log와 install이 같으면 install(신규), 다르면 existing(기존)으로 구별해준다.
그 다음에는 apply함수를 사용하여 각 행마다 이 함수를 적용해준다.
mau_payment['user.type'] = mau_payment.apply(lambda x: user_type(x['log_month'], x['install_month']), axis=1)lambda는 사용자정의 함수를 문법에 맞추어 작성하는 것보다 훨씬 간단하게 한줄 정도로 해결할 수 있는 함수이다. 여기서 x는 mau_payment를 입력변수로 받는다.

마지막으로 신규유저와 기존유저중 어떤 유저타입의 매상이 줄어들었는지 확인해야 한다. 그래서 log_month와 user_type로 groupby시켜줬다.
mau_payment_summary = mau_payment.groupby(['log_month', 'user.type'], as_index = False)['payment'].sum()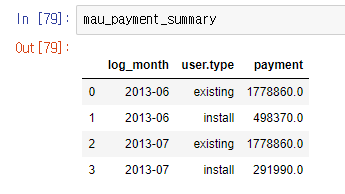
그러면 보다시피 6월, 7월에 신규와 기존 유저의 총 과금액이 나온다. 이 데이터에서는 기존 유저의 과금액에서는 변화가 없었으나 신규 유저의 과금액이 급격히 떨어진 것을 알 수 있다.
따라서 신규 유저를 불러들어올 수 있는 광고를 늘린다던지 하는 방법을 써서 신규 유저 포섭에 힘을 써야한다.
Visualization
우선 mau_payment_summary 데이터를 가지고 기존 유저와 신규 유저의 과금액을 시각화했다.
fig = px.bar(mau_payment_summary, x='log_month', y='payment', color='user.type',
barmode='group',
title='Total Sales of new and existing users')
fig.show()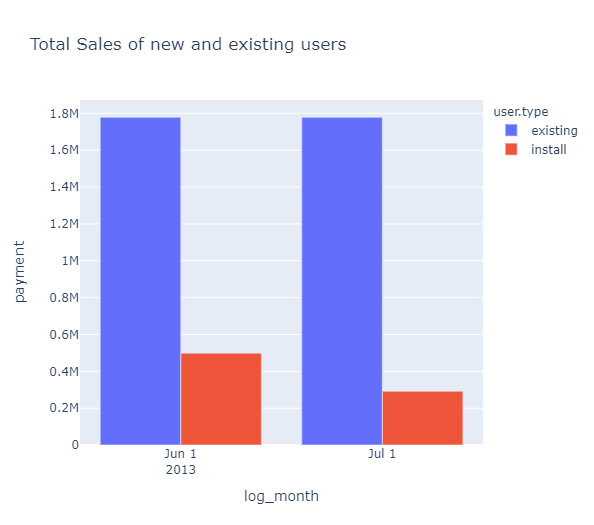
막대 그래프로 표현하기 위해서 px.bar()를 사용. x축은 log_month, y축은 payment, 그리고 user.type로 색깔을 구분지어줬다. barmode는 'group'으로 설정하여 보기좋게 막대그래프가 user.type별 나눠서 보여주게 했다.
그리고 신규 유저의 과금액 분포도를 표현하려고 히스토그램을 가지고 시각화를 하려고 했는데
fig = px.histogram(mau_payment[mau_payment['user.type']=='install'], x='payment', color='log_month', nbins=20,
title='Billed amount of New Users')
fig.show().png)
과금액이 0인 유저가 많다보니 나머지 부분은 눈에 식별이 되지 않는 문제 발생
처음엔 histnorm이라는 파라미터가 있어서 한번 여러가지 변수를 넣고 적용해보았더니 그래도 좋아지지가 않아서 생각해본게 log스케일이었다. 전에 특강에서 log스케일은 큰 값을 작게 작은 값을 크게 해줄 수 있다고 배웠어서 히스토그램에서 log스케일을 어떻게 적용해야 하는지 찾아보았다.fig = px.histogram(mau_payment[mau_payment['user.type']=='install'], x='payment', color='log_month', nbins=20, barmode='group', log_y=True, title='Billed amount of New Users') fig.show()log_y라는 파라미터를 적용하여 y값을 log스케일로 변환해줬다.
.png)
