앙상블(Ensemble)이란 여러개의 분류기를 생성하고 예측값을 결합해서 보다 정확한 예측값을 도출하는 기법이다. 강한 ML모델 하나보다 약한 ML모델 학습기를 여러개 결합한 것이 더 성능이 좋다는 생각으로 만들어낸 기법이다.
대부분의 정형 데이터 분류할 때, 앙상블이 뛰어난 성능을 보인다.
기본적인 앙상블의 종류는 다음과 같다.
- 보팅(Voting)
- 배깅(Bagging)
- 부스팅(Boosting)
이 외에도 스태깅 등 다양한 앙상블이 있긴 하다.
보팅과 배깅은 여러개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 공통점이 있다. 차이점은 다음과 같다.
보팅은 서로 다른 알고리즘을 가진 분류기를 결합배깅은 같은 알고리즘을 가지고, 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행한다. 대표적인 방식이랜덤 포레스트알고리즘이다.
보팅(Voting)
.jpg)
이 보팅방식은 하나의 데이터에서 Linear Regression, K Nearest Neighbor, SVM으로 학습한뒤 각각의 예측결과를 모아 보팅해서 최종 예측 결과를 도출한다.
Hard Voting
예측한 결과값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결과값으로 선정.
.jpg)
결과값 1, 2중 분류기1과 3는 1을, 분류기2는 2로 예측했으므로 다수결의 원칙에 의하여 1이 최종 도출 됬다.
Soft Voting
분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결과값으로 선정. 일반적으로 소프트 보팅이 보팅 방법으로 적용.
.jpg)
| 분류기 | 1 | 2 |
|---|---|---|
| Classifier1 | 0.7 | 0.3 |
| Classifier2 | 0.4 | 0.6 |
| Classifier3 | 0.9 | 0.1 |
| Voting result | 0.67 | 0.33 |
Soft Voting은 각각의 레이블마다 Confidence Value를 사용한다.
위 그림의 보팅을 보면 분류기 1은 예측값 1 확률이 0.7, 2는 0.3이고 분류기 2는 1은 0.4, 2는 0.6, 분류기 3은 각각 0.9, 0.1이다. 예측값 1, 2에 대해서 분류기들의 Confidence Value를 평균내면 각각 0.67, 0.33에 이르고 예측값 1의 확률이 더 크므로 최종 예측값은 1이된다.
Voting Classifier
Logistic Regression과 KNeighborsClassifier 모델을 가지고 Soft Voting을 해보자.
# create model object
lr_clf = LogisticRegression()
knn_clf = KNeighborsClassifier(n_neighbors=8)
# Soft Voting model
vo_clf = VotingClassifier(estimators=[('LR', lr_clf), ('KNN', knn_clf)], voting='soft')
# data split
x_train, x_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state=156)Logistic과 KNN 객체 생성하고 voting 객체의 estimators에 넣어준다.
# Voting train / predict / scoring
vo_clf.fit(x_train, y_train)
pred = vo_clf.predict(x_test)
print('Voting 분류기 정확도 : {0:.4f}'.format(accuracy_score(pred, y_test)))Voting 분류기 정확도 : 0.9474
두 모델의 Voting하여 예측값의 정확도가 0.9474로 계산되었다. 그럼 이번엔 각각 모델의 정확도를 살펴보자.
classifiers = [lr_clf, knn_clf]
for clf in classifiers:
clf.fit(x_train, y_train)
pred = clf.predict(x_test)
# __class__ : 클래스 이름 참조, 클래스 내부에서 self.__class__.__name__ : 클래스 이름 참조
class_name = clf.__class__.__name__
print('{} 정확도 : {}'.format(class_name, accuracy_score(pred, y_test)))LogisticRegression 정확도 : 0.9385964912280702
KNeighborsClassifier 정확도 : 0.9385964912280702
두 모델의 정확도가 이상하게 똑같이 나왔다;; 그래도 한가지 확실한건 두 모델의 정확도보다 보팅의 정확도가 높다는 것이다. 하지만 무조건 보팅으로 여러개의 분류기를 결합한다고 예측 성능이 향상되지는 않는다.
배깅(Bagging)
.jpg)
배깅은 보다시피 보팅과 비슷하지만 다르다. 개별 분류기에 데이터를 샘플링해서 추출하는 방식을 부트스트래핑(Bootstrapping)분할 방식이라 한다. 개별 분류기가 부트스트래핑으로 샘플링된 데이터 세트에 대해 학습을 통해 개별적인 예측을 수행하고, 이들을 모아 보팅(여기서 보팅은 투표)을 통해 최종 예측 결과를 도출한다.
이 부트스트래핑으로 샘플링된 데이터 세트는 교차검증과 다르게 데이터 세트간에 중복이 허용된다.
이는 만약 10000개의 데이터를 10개의 분류기가 배깅으로 샘플링해도 각 1000개의 데이터 내에는 중복 데이터가 있다.
Random Forest
랜덤 포레스트(Random Forest)는 앙상블 알고리즘 중에 빠른 수행 속도를 가지며, 다양한 영역에서 높은 예측 성능을 보인다.
랜덤 포레스트의 기반 알고리즘은 DecisionTree이다. 이는 곧 결정 트리의 장점인 쉽고 직관적인 특징을 그대로 갖는다. 이 모델은 여러 개의 결정 트리가 전체 데이터에서 부트스트래핑으로 데이터를 샘플링하고 개별적으로 학습한 뒤 최종 예측값을 Soft Voting을 통해 정한다.
부트스트랩을 하여 데이터 샘플링을 하면 다음과 같다.
.jpg)
각 샘플링을 보면 위에도 말했다시피 중복 데이터가 존재한다. 샘플 데이터 크기는 원본 데이터 세트 크기와 같다.
UCI 행동예측 데이터로 랜덤포레스트를 실행해보자.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
rf_clf = RandomForestClassifier(random_state=0)
rf_clf.fit(x_train, y_train)
pred = rf_clf.predict(x_test)
accuracy = accuracy_score(pred, y_test)
print('랜덤 포레스트 정확도 : {:.4f}'.format(accuracy))랜덤 포레스트 정확도 : 0.9253
랜덤 포레스트로 파라미터를 default로 UCI 행동예측 정확도가 92.53%로 나왔다.
하이퍼 파라미터
트리 기반의 앙상블은 하이퍼 파라미터가 상대적으로 많아 튜닝에 대한 시간이 많이 소요된다. 트리 자체의 파라미터 + 배깅,부스팅,학습,정규화 등을 위한 파라미터이다보니 많을 수밖에 없긴 하다.
랜덤포레스트는 그래도 결정 트리에서 사용되는 하이퍼 파라미터가 대부분이다.
- n_estimators : 랜덤포레스트에서 결정 트리 개수 지정. default는 10개. 개수가 늘어날수록 무조건 성능이 향상되는것은 아니고 시간은 오래 걸려진다.
- max_features : 결정 트리와 똑같다. 단지, default값이
None이 아니라auto, 즉sqrt이다.(전체 feature가 16개면 분할을 위해 그 중에서 4개만 참조) - max_depth, min_samples_leaf, ... : 결정 트리에서처럼 과적합을 개선하기 위한 하이퍼 파라미터
하이퍼 파라미터를 이용해 RandomForest를 튜닝한다.
from sklearn.model_selection import GridSearchCV
# param_grid of GridSearchCV
params = {
'n_estimators' : [300],
'max_depth' : [6, 8, 10, 12],
'min_samples_leaf' : [8, 12, 18],
'min_samples_split' : [8, 16, 20]
}
# RandomForest 모델 학습
rf_clf = RandomForestClassifier(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1, scoring='accuracy', verbose=1)
grid_cv.fit(x_train, y_train)
print('최적의 하이퍼 파라미터 : \n', grid_cv.best_params_)
print('최고 예측 정확도 : ', grid_cv.best_score_)최적의 하이퍼 파라미터 :
{'max_depth': 10, 'min_samples_leaf': 8, 'min_samples_split': 8, 'n_estimators': 300}
최고 예측 정확도 : 0.9144450489662677
최종 예측 정확도는 91.44%이다.
Feature Importances
랜덤 포레스트의 features들의 중요도 파악을 구하기 위해 feature_importances를 이용해보자.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# first step is model fitting
rf_clf = RandomForestClassifier(n_estimators=300, max_depth=10, min_samples_split=8, min_samples_leaf=8)
rf_clf.fit(x_train, y_train)
# feature_importances_
rf_importances_values = rf_clf.feature_importances_
#index는 features명이므로 data.columns로 설정
rf_importances = pd.Series(rf_importances_values, index=x_train.columns)
rf_top20 = rf_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8, 6))
plt.title('Feature importances Top 20')
sns.barplot(x=rf_top20, y=rf_top20.index)
plt.show()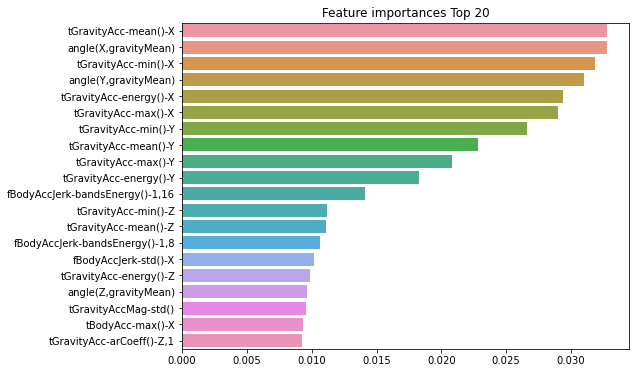
스태킹(Stacking)
스태킹은 여러가지 다른 모델의 예측 결과값을 다시 학습 데이터로 만들어서 다른 모델(메타 모델)로 재학습시켜 결과를 예측한다.
