interview2022
1.[ML/DL] 인터뷰 질문 모음

면접 질문 모음
2.알고 있는 metric에 대해 설명해주세요. (ex. RMSE, MAE, recall, precision ...)
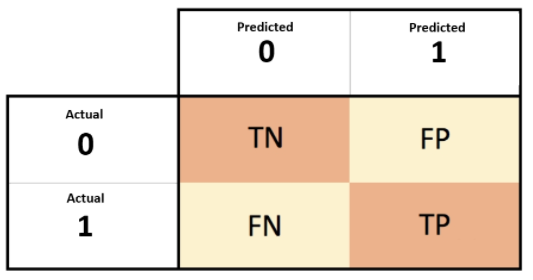
면접 대비 답변 제가 대회에서 활용한 Metric으로는 Accuracy, F1-score, AUPRC, EM, Rouge score등이 있습니다. 우선 관계추론대회의 경우 Micro F1 score를 활용하였으며, 질의응답(ODQA) 대회에서는 EM(Exact Matc
3.정규화를 왜 해야할까요? 정규화의 방법은 무엇이 있나요?
제가 생각하는 데이터를 정규화를 해야하는 이유로는각 feature들 사이에 값의 차이가 큰 경우 정규화를 통해 모든 feature가 같은 정도의 중요도로 반영되게 하기 위합니다.큰 값을 가지는 변수에 편향이 되지 않도록 한다.특정 변수의 단위가 다른 변수들보다 큰 경우
4.Local Minima와 Global Minima에 대해 설명해주세요.
Gradient Descent(경사하강법)을 통해 Cost Function의 최소값을 찾게 되도록 하는데 극소점 즉, Global Minima에 다다르지 않고, 기울기가 0이 되는 다른 지점을 Local Minima라고 합니다. 이렇게 Local Minima로 빠지는
5.회귀 / 분류시 알맞은 metric은 무엇일까?
우선 회귀 문제에서는 실제 데이터와 모델의 예측값 사이의 차이를 기반으로둔 Metric을 활용합니다. MSE(Mean Square Error, 평균제곱오차), RSS(Residual sum of Square, 단순 오차 제곱합), MAE(Mean Absolute Err
6.ROC 커브에 대해 설명해주실 수 있으신가요?
ROC 커브는 정답이 아닌 것을 정답으로 추론하는 확률을 x축으로 두고 이를 0부터 1로 키워가면서 정답을 정답으로 맞추는 확률을 y축으로 하여 나타낸 그래프를 의미합니다. 이 그래프는 y=x를 기준으로 멀리 떨어질 수록 모델의 성능이 좋다고 판단할 수 있으며, ROC
7.L1, L2 정규화에 대해 설명해주세요.
우선 Weight Regularization(정규화)의 경우에는 Overfitting을 방지하기위해 특정 가중치가 과도하게 커지지 않도록 하는 방법으로 말씀주신 L1, L2 정규화 방법이 있습니다.L1 정규화는 Cost Function에 가중치의 절대값을 더해주는 방식
8.Cross Validation은 무엇이고 어떻게 해야하나요?
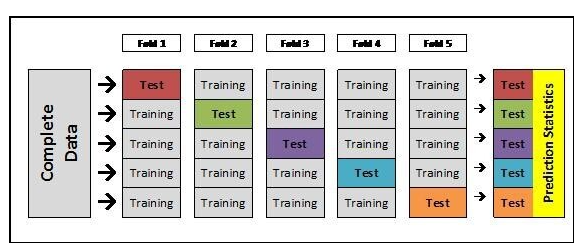
Cross Validation은 주어진 문제에 대하여 Train, Validation Set으로 나누어 모델의 성능을 체크함에 있어 나누어진 집합에 편향성을 가질수 있는 문제를 해결하기 위한 방법입니다. Cross Validation 기법의 가장 대표적인 예로 K-fo
9.앙상블 방법엔 어떤 것들이 있나요?
우선 제가 교육과정을 통해 사용한 앙상블 기법은 하드보팅, 소프트보팅 방법입니다. MRC대회를 진행하면서 앙상블을 통해 약 7점가량의 EM 점수를 향상시킬수 있었습니다. 하드보팅 방법은 다양한 모델과 변수를 주어 추론결과물을 얻어내고 이 결과물의 대표값을 찾는 방식으로
10.딥러닝은 무엇인가요? 딥러닝과 머신러닝의 차이는?
우선 AI 기술안에 머신러닝이 존재하며, 그 안에 딥러닝이 있습니다. 머신러닝이란, 주어진 데이터를 활용하여 알고리즘을 통해 새로운 데이터로부터 추론하는 과정을 의미하며, 딥러닝은 이 과정속에서 뉴런네트웍크를 활용한 기법입니다. 머신러닝의 경우에는 데이터에 주어진 fe
11.Cost Function과 Activation Function은 무엇인가요?
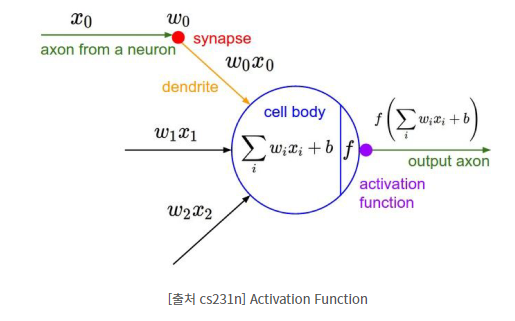
가설함수(Hypothesis Function)은 학습을 통해 최적화를 시키려는 함수로 데이터의 분포를 일반적으로 나타내는 함수가 될 수 있습니다. 이 가설함수를 실제 데이터와 최적화 하기 위한 함수를 cost function 혹은, loss function이라고 합니다
12.Tensorflow, PyTorch 특징과 차이가 뭘까요?
우선 저 같은 경우에는 Tensorflow를 사용해본적은 없습니다. Pytorch가 가지는 장점으로는 debugging 하기가 더 편리하고, 구현함에 있어서 더 직관적이고 학습하기 용이하다는 것으로 알고 있습니다.pythonic code를 작성할 수 있다.GPU와 Go
13.Data Normalization은 무엇이고 왜 필요한가요?
데이터 정규화를 하는 이유는 특정 변수에 대해서 편향성을 가지지 않도록 하기 위함이다. 특정 변수 값이 단위가 10억이고, 다른 변수의 값이 0~10 이라면 학습과정에서 10억단위를 가지는 변수가 더 큰 영향을 가질수 있습니다. 이처럼 모든 변수가 동일한 영향력을 끼칠
14.알고있는 Activation Function에 대해 알려주세요. (Sigmoid, ReLU, LeakyReLU, Tanh 등)
Activation Function은 들어온 값들 중에서 다음 신호에 사용될 값을 추려서 전달하고, 딥러닝에서 뉴런네트워크를 쌓음에 있어서 비선형성을 주어 다양한 정보를 담을 수 있도록 합니다. (선형을 계속 쌓아봤자 선형이기때문에 많은 정보를 담지 못함) Activa
15.오버피팅일 경우 어떻게 대처해야 할까요?
오버피팅은 학습데이터가 과도하게 학습되어서 실제데이터에서는 성능이 떨어지는 현상을 의미합니다. 이런 오버피팅 문제를 해소하기 위한 방법으로는 우선 가장 학습이 잘 되었을때를 찾기 위한 Early stopping 방법이 있으며, 그 외에도 데이터에 노이즈를 추가하는 방식
16.하이퍼 파라미터는 무엇인가요?
하이퍼파라미터는 학습과정에서 임의로 지정하게 되는 변수들을 의미합니다. 예를 들어 학습 epoch수, layer의 갯수, dropout 퍼센티지, batch size, learning rate 등이 있을 수 있으며 이 값에 따라서 학습의 정도나 속도에 영향을 끼치기 때
17.요즘 Sigmoid 보다 ReLU를 많이 쓰는데 그 이유는?
시그모이드 함수를 활성화함수로 사용하게되면, 레이어를 쌓음에 따라 지속적으로 0~1사이의 값이 곱해지게 되고 이는 0에 수렴하게 되는 문제가 발생한다. 이를 보완하기 위해 ReLU Activation Function을 활용하게 되었고, 이는 0보다 작은값은 0, 큰값은
18.Non-Linearity라는 말의 의미와 그 필요성은?
비선형성이란, 1개의 직선으로 표현이 되지 않는 모든 형태를 의미합니다. 실제로 많은 경우가 1개의 직선으로 구분하는 것은 불가능하고, 선형방정식을 쌓게 되어도 결국 또다른 선형 방정식이 나오게 됩니다. 여기서 Activation Function을 통해 비선형성을 부가
19.Gradient Descent에 대해서 쉽게 설명한다면?
볼록한 형태의 그래프에서 최소값을 찾기위한 방법으로 한 점에서의 미분값에 따라 그 기울기가 0이 되는 방향으로 이동하는 방식으로 최소점을 찾아가는 알고리즘이다.선형회귀나 분류 등 우리가 접하게 되는 문제들의 loss(cost) 함수의 경우 아래로 볼록한 형태를 띄기 마
20.[면접후기] 20220210
이력서 기반으로 예비질문까지 만들어서 전달주셔서 면접 준비도 유익했던 시간이 되었다. 전주에 봤던 면접에서는 이력서와 지원 분야와 관계없이.. 스프링과 관련된 질문이 주를 이루어서 아쉬움이 남았는데, 딥러닝과 관련해서 그동안 배운내용을 잘 정리하고, 설명할 수 있었던