
6.1 DataFrame에 값 쓰기 I
현재 dataFrame 에서 iphone 8 의 메모리는 2GB인데 2.5GB로 바꾸고 싶다면
iphone_df.loc['iPhone 8','메모리'] = '2.5GB'output

이 처럼 수식을 이용해서 값을 바꿀 수 있다!!
한 열을 통째로 바꾸고 싶다면?
ex) iPhone 8 에 해당하는 열 통째로 바꾸기
iphone_df.loc['iPhone 8']output
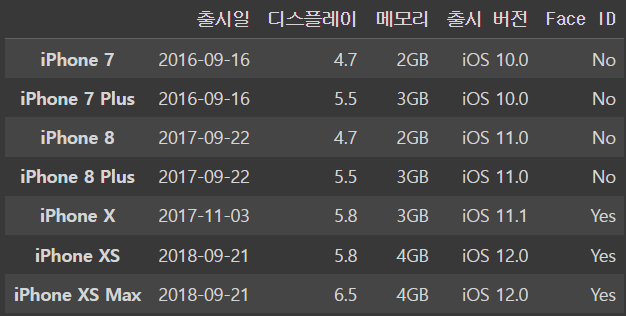
출시일 2017-09-22
디스플레이 4.7
메모리 2.5GB
출시 버전 iOS 10.3
Face ID No
Name: iPhone 8, dtype: object불러와서 값을 확인한 후에
iphone_df.loc['iPhone 8'] ==['2016-09-22','4.7','2GB','iOS 11.0','No']output
출시일 False
디스플레이 False
메모리 False
출시 버전 False
Face ID True
Name: iPhone 8, dtype: bool리스트를 이용하여 바꿔준다 여기서 연산자는 =나 == 를 사용한다
output

열을 바꿔줄 때에도 동일하다
iphone_df['Face ID']output
iPhone 7 No
iPhone 7 Plus No
iPhone 8 No
iPhone 8 Plus No
iPhone X Yes
iPhone XS Yes
iPhone XS Max Yes
Name: Face ID, dtype: object값을 확인해주고
iphone_df['Face ID'] = ['No','No','No','No','No','No','No']
iphone_dfoutput
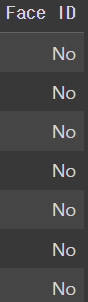
똑같이 리스트를 사용해서 바꿔준다
만약 위 처럼 같은 값이라면 하나만 써줘도 된다
iphone_df['Face ID']='Yes'
iphone_df6.2 DataFrame에 값 쓰기 II
여러 줄을 바꾸고 싶다면
iphone_df[['디스플레이','Face ID']] ='x'
iphone_dfoutput
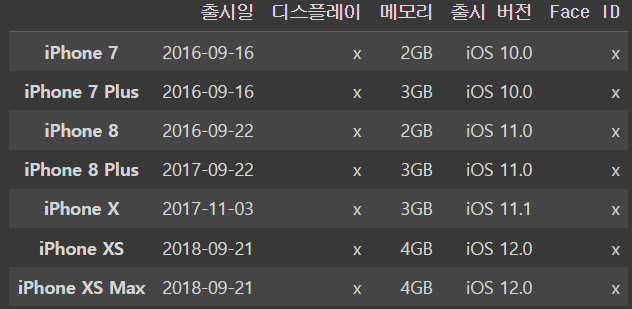
['column1','column2'] = 'x' 와 같은 형식으로 써주면 값이 바뀐다
iphone_df.loc[['iPhone 7','iPhone X']] ='o'
iphone_dfoutput
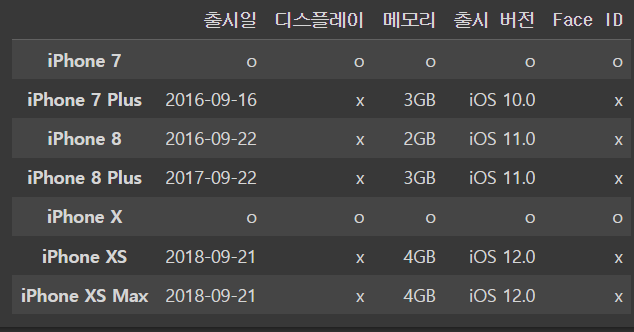
슬라이싱도 가능하당
iphone_df.loc['iPhone 7':'iPhone X']='o'
iphone_dfoutput
조건문을 사용해서 값을 바꿀 수도 있다
iphone_df['디스플레이']>5output
iPhone 7 False
iPhone 7 Plus True
iPhone 8 False
iPhone 8 Plus True
iPhone X True
iPhone XS True
iPhone XS Max True
Name: 디스플레이, dtype: bool디스플레이가 5 이상인 것들의 Series를 불러옴
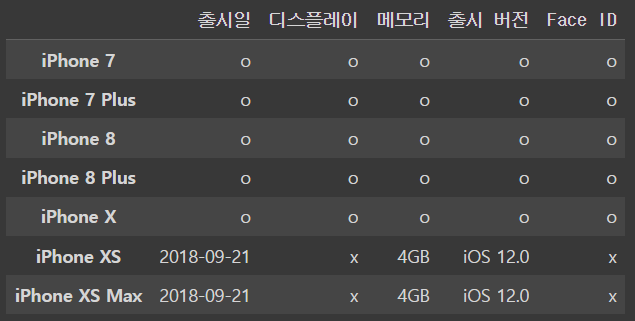
iphone_df.loc[iphone_df['디스플레이']>5]output

이를 DataFrame으로 불로오고
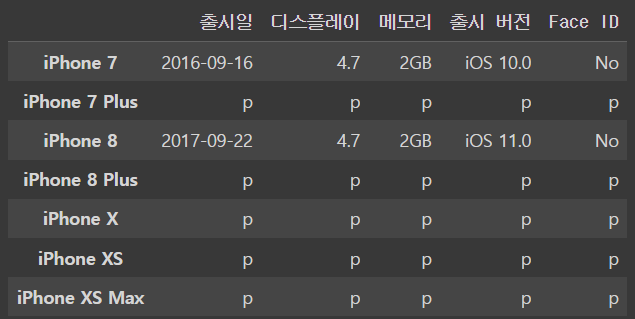
iphone_df.loc[iphone_df['디스플레이']>5] ='p'
iphone_df디스플레이가 5 이상인 요소들을 모아놓은 DataFrame의 값을 p라고 수식으로 정해준다
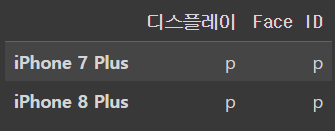
위치로 값을 바꿀 수도 있당
iphone_df.iloc[[1,3],[1,4]]output
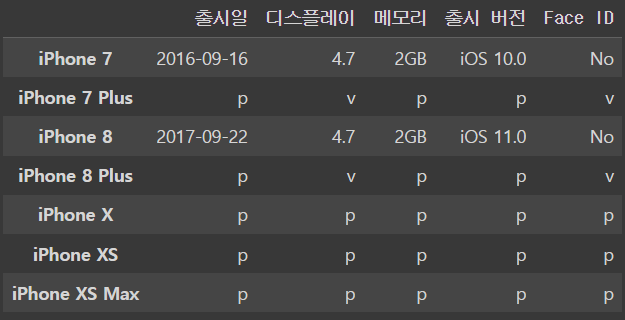
iphone_df.iloc[[1,3],[1,4]] ='v'
iphone_dfoutput
6.3 DataFrame에 값 추가/삭제
추가할 값의 이름을 .loc에 넣고 = 다음에 값을 리스트로 넣어주면 된다!
iphone_df.loc['iPhone XR'] = ['2018-10-26',6.1,'3GB','iOS 12.0.1','Yes']
iphone_dfoutput
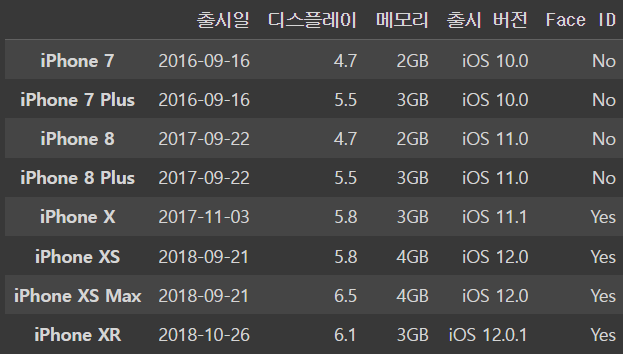
ㄴ iPhone XR이 생긴 것을 볼 수 있다
column을 추가할 때에도 마찬가지이다
iphone_df['제조사']='Apple'
iphone_dfoutput
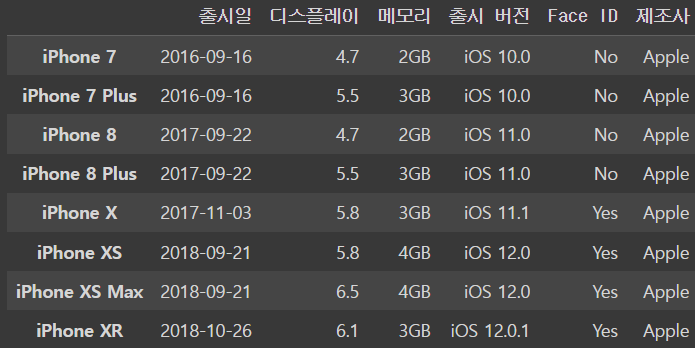
ㄴ 제조사가 추가된 것을 볼 수 있다
삭제하는 방법은 .drop()를 쓰면 된다!
iphone_df.drop('iPhone XR', axis = 'index',inplace=False)ㄴ axis = 'index'의 뜻 = pandas에서 row를 index라고 하기 때문에 지우고 싶은 것이 row라는 것을 알려줌
ㄴ column을 삭제할 때엔 axis = columns를 쓰면 된다 s를 붙이는 것에 유의하자
ㄴ inplace = False는 기존의 데이터를 건들이지 않겠다는 뜻
output
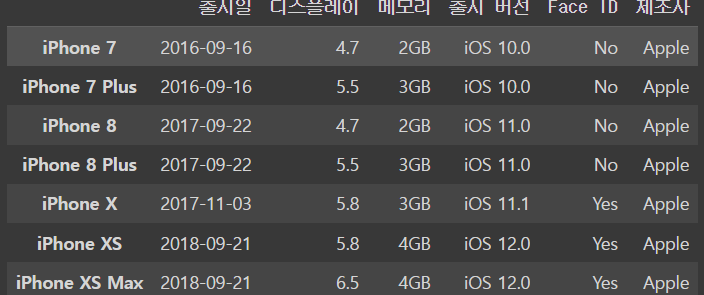
그래서 이렇게 삭제를 하고 iphone_df를 입력을 해도
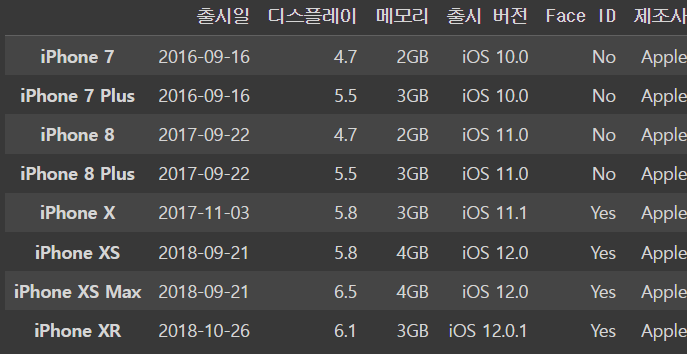
iPhone XR이 삭제 되지 않고 그대로 있는 것을 볼 수 있다
왜냐하면 inplace = False를 썼기 때문이다 !! 완전히 삭제시키고 싶을 때는 inplace = True를 쓰면 된다
iphone_df.drop('제조사',axis = 'columns',inplace=True)
iphone_dfoutput
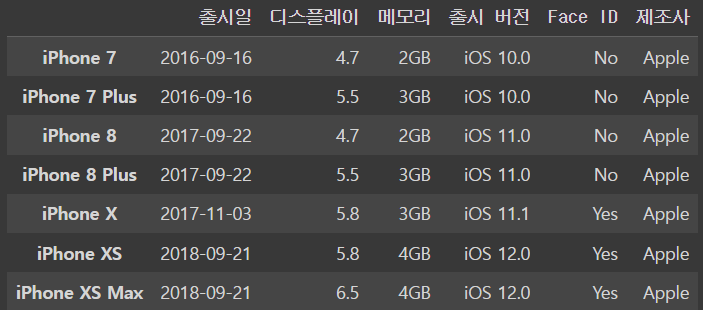
여러 열들을 없애고 싶으면 리스트를 사용해주면 된다
iphone_df.drop(['iPhone 7','iPhone 8','iPhone X'], axis = 'index',inplace=True)
iphone_dfoutput
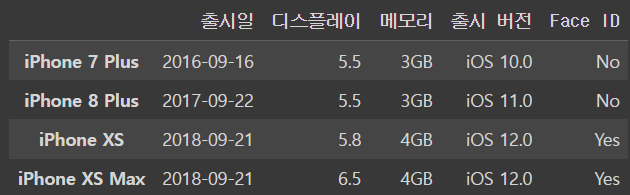
행을 없애는 것도 동일하다
iphone_df.drop(['출시일','디스플레이'], axis = 'columns',inplace=True)
iphone_dfoutput
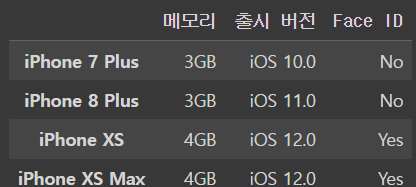
6.4 (실습) 잘못된 DataFrame 고치기 I
키와 몸무게가 담겨 있는 한 DataFrame이 있는데요. 몇 가지 잘못된 사항들이 있습니다. 이번 챕터에서 배운 기법들로 DataFrame을 바로잡아 봅시다.
해야 할 일이 세 가지 있습니다.
ID 1의 무게를 200으로 변경하세요.
ID 21의 row를 삭제하세요.
ID 20의 row를 추가하세요. ID 20의 키는 70, 무게는 200입니다.
딱 3줄의 코드만 추가하시면 됩니다!
code
import pandas as pd
df = pd.read_csv('data/body_imperial1.csv', index_col=0)
df.iloc[1,1]=200
df.drop(21,axis='index',inplace=True)
df.loc['20']=[70,200]
df6.5 (실습) 잘못된 DataFrame 고치기 II
키와 몸무게가 담겨 있는 한 DataFrame이 있는데요. 몇 가지 잘못된 사항들이 있습니다. 이번 챕터에서 배운 기법들로 DataFrame을 바로잡아 봅시다.
해야 할 일이 두 가지 있습니다.
'비만도' column을 추가하고, 모든 ID에 대해 '정상'으로 설정해주세요.
'Gender' column의 값을 ID 0~10까지는 'Male' 11~20까지는 'Female'로 변경하세요.
code
import pandas as pd
df = pd.read_csv('data/body_imperial2.csv', index_col=0)
df['비만도']='정상'
df.iloc[0:11,0]='Male'
df.iloc[11:,0]='Female'
df6.6 index/column 설정하기
기존에 쓰던 iphone.csv 말고 다른 csv 파일을 불러와줍니당
import pandas as pd
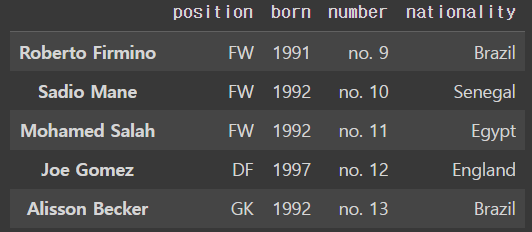
liverpool_df = pd.read_csv('drive/MyDrive/dataScience/data/liverpool.csv',index_col=0)
liverpool_dfoutput
column의 이름을 바꾸고 싶다면 .rename()을 사용하자
liverpool_df.rename(columns = {'position':'Position'})output
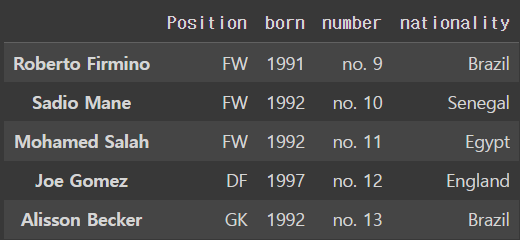
하지만 위와 같이 바꾸고 나서 liverpool_df라고 다시 불러오면
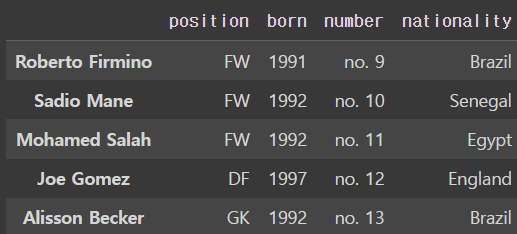
이렇게 수정이 되어있지 않다. 왜냐하면 rename은 기존의 데이터프레임을 건들지는 않기 때문 !!
이럴때는 inplace = True를 함께 써주자
liverpool_df.rename(columns = {'position':'Position'},inplace=True)
liverpool_dfoutput
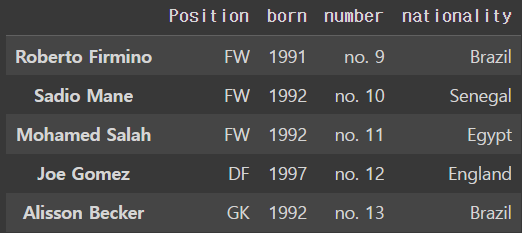
여러개를 한꺼번에 지정해줄 수도 있다
{}안에 많이 넣어주면 됨
liverpool_df.rename(columns = {'position':'Position','born':'Born','number':'Number','nationality':'Nationality'},inplace=True)
liverpool_dfoutput
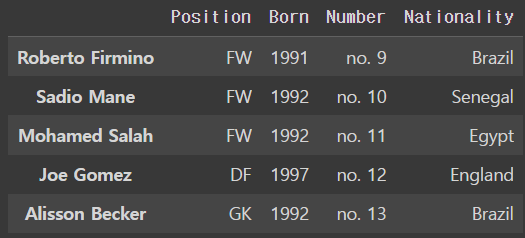
행에다가 이름을 붙이고 싶다면 .index.name = ' '형식으로 쓰면 된다
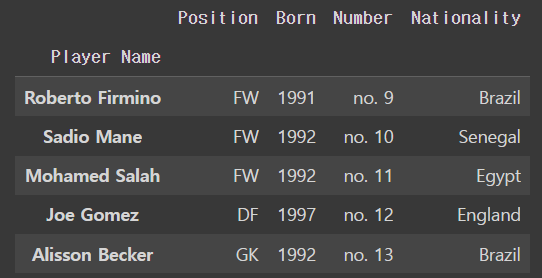
liverpool_df.index.name='Player Name'
liverpool_dfoutput
행의 이름을 바꾸고 싶다면 .set_index()를 쓰면 된다
liverpool_df.set_index('Number')output
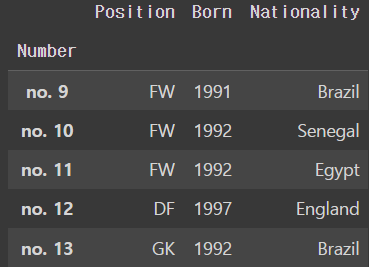
ㄴ 하지만 이렇게 되면 그 전에 행에 있던 선수 이름 데이터들을 열로 옮기고 싶지만 못하게 된다
열에다가 행에 있는 Player Name을 넣어줌
liverpool_df['Player Name']=liverpool_df.index
liverpool_dfoutput
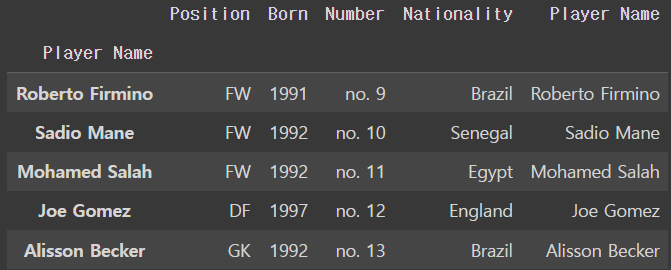
행을 Player Nmae에서 Number로 바꿔줌
liverpool_df.set_index('Number')output
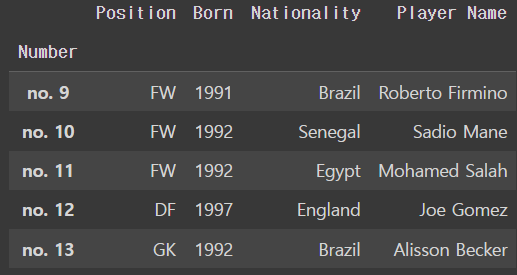
이렇게 해도 다시 선언하면 바뀌지 않았음 !! ㅠㅠ
liverpool_dfoutput
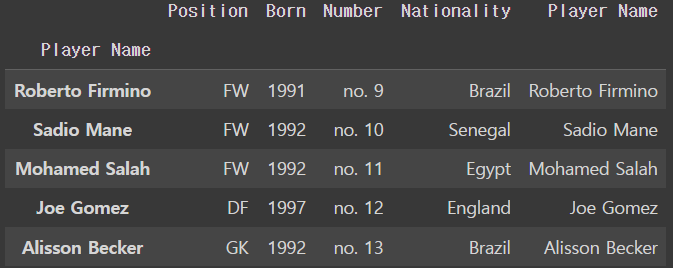
여태까지 해준 것들에다가 inplace = True를 붙여주면 됨
liverpool_df.set_index('Number',inplace=True)
liverpool_dfoutput
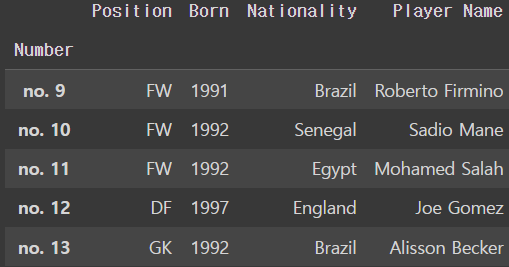
liverpool_df.rename(index = {'Number':'number'},inplace=True)
liverpool_dfoutput
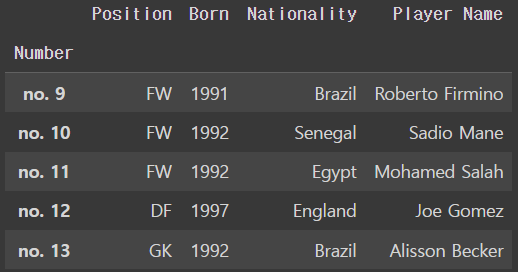
완성 !
6.7 (실습) 서류 전형 합격 여부
토익 시험은 LC(듣기) 파트와 RC(독해) 파트로 이루어져 있습니다. 각 파트가 495점 만점, 총 990점이 만점입니다.
“서울 항공”에 입사하기 위해서는 토익 점수를 제출해야 하는데요. 각 파트가 최소 250점, 총 점수가 최소 600점이 되어야 서류 전형을 합격할 수 있습니다.
기존 DataFrame에 “합격 여부”라는 column을 추가하고, 합격한 지원자는 불린 값 True, 불합격한 지원자는 불린 값 False를 넣어주면 됩니다.
code
import pandas as pd
df = pd.read_csv('data/toeic.csv')
pass_total = df['LC'] + df['RC'] > 600
pass_both = (df['LC'] >= 250) & (df['RC'] >= 250)
df['합격 여부'] = pass_total & pass_both
# 테스트 코드
df6.8 (실습) 퍼즐을 풀어라 !
데이터프레임이 있습니다.
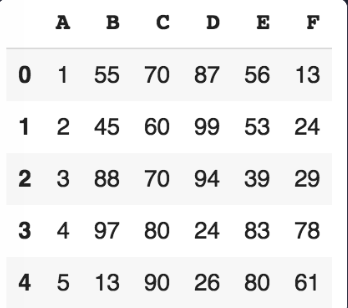
코드를 4줄만 써서, 아래 데이터프레임으로 바꿔보세요.
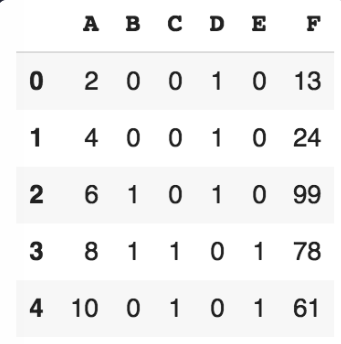
code
import pandas as pd
df = pd.read_csv('data/Puzzle_before.csv')
# 80이 넘으면 1 아니면 0 & A *2
df['A']=df['A']*2
df[['B','C','D','E']]=(df[['B','C','D','E']]>=80)*1
df.iloc[2,5]='99'
# 테스트 코드
df