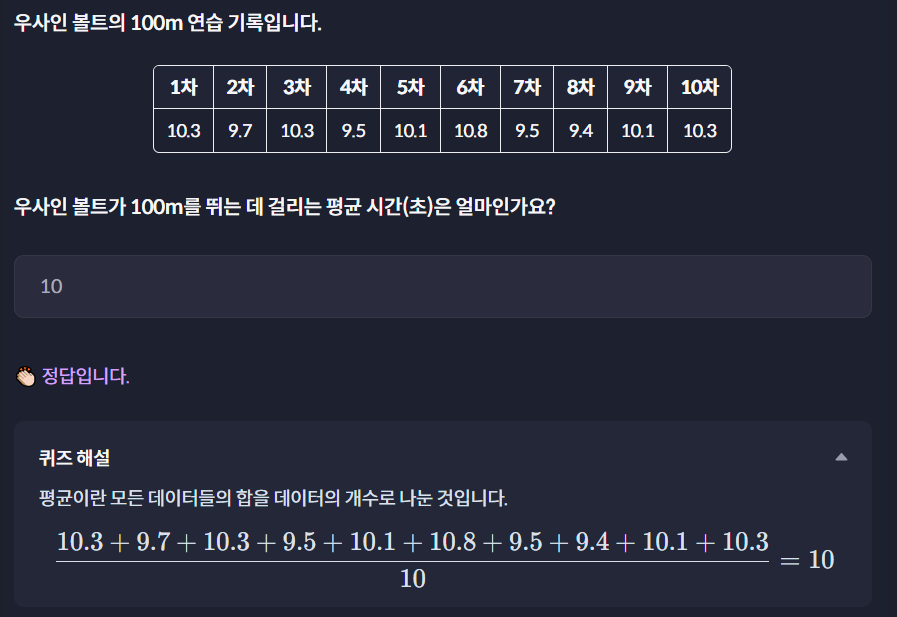
10.1 평균값
평균 = 데이터들의 합 / 데이터들의 개수
데이터가 다 정수값들이어도 평균은 정수값이 안 올 수 있다
10.2 평균값 계산하기

10.3 중간값
중간값 (Median) = 데이터셋에서 딱 중간에 있는 값
데이터 개수가 홀수일 때 )
32 48 56 78 86 96 100
ㄴ 여기서는 78이 중간값
데이터 개수가 짝수일 때)
7 11 12 15 16 21 24 29
ㄴ 여기서는 15랑 16이 중간이라 볼 수 있는데 이 둘의 중간이 15.5이므로 중간값은 15.5 !
10.4 평균값 vs 중간값
평균값은 잘못된 데이터 한두개로 값이 이상해질 수 있지만 중간값은 크게 영향을 받지 않아서 더 유리한 경우가 있다 !
ex)
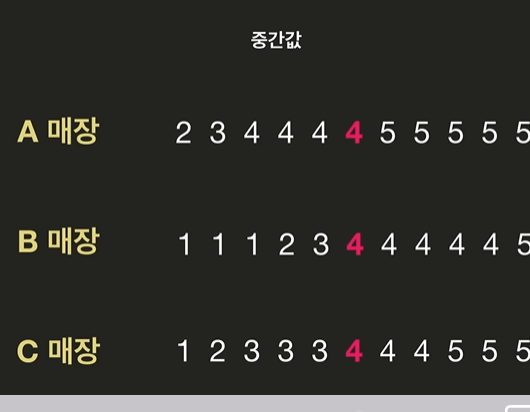

ㄴ 평균값이 더 유용한 사례
10.5 중간값 계산하기

ㄴ 정렬을 해야한다 !! (처음엔 몰라서 틀림 흑)
판다스로 중간값을 계산도 해보아씀 ㅎㅎ
import pandas as pd
mlist = {'name':[44,42,43,28,46,33,42,37,29]}
df = pd.DataFrame(mlist)
median_value = df['name'].median()
print(median_value)output
42.0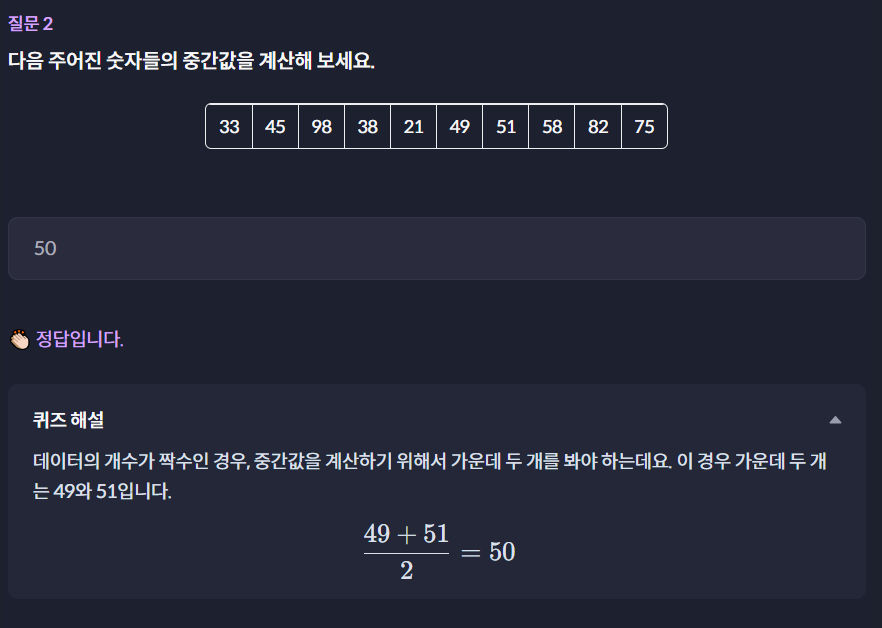
이것두 판다스로 해봤음 ㅎㅎ
mlist = {'name': [33,45,98,38,21,49,51,58,82,75]}
df = pd.DataFrame(mlist)
median = df['name'].median()
print(median)output
50.010.6 Q1, Q3와 이상값
Q1, Q3 구하기
Q1 = 데이터의 25% 지점
Q3 = 데이터의 75% 지점
여기서 중간값은 86이다 !
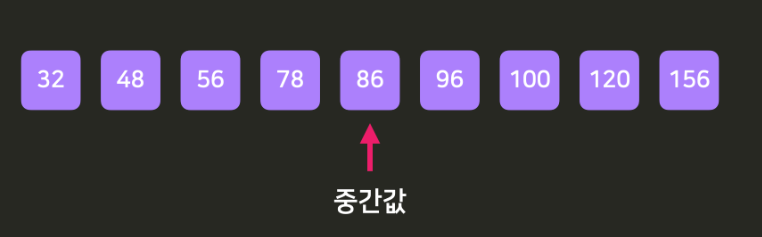
중간을 기준으로 첫 번째 값 ~ 중간값 = Q1, 중간값 ~ 가장 마지막 값 = Q3
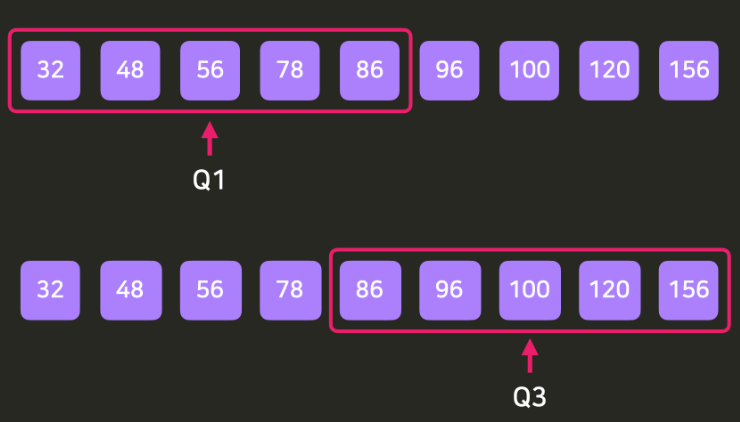
하지만 아래와 같이 Q1, Q2, Q3의 위치를 딱 정할 수 없는 경우도 있음 -> 데이터 개수가 짝수일 때 !
중간값은 아래와 같다
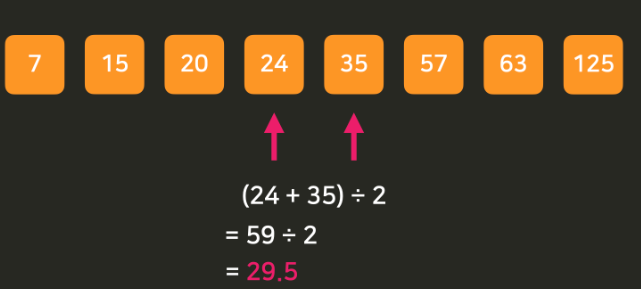
Q1을 구해보자면
우선 Q1이 몇 번 인덱스에 있는 값인지 구해야함
데이터에서 특정 퍼센트 지점의 인덱스 구하는 법 : (데이터 개수-1) * 원하는 숫자
여기서는 데이터의 개수가 총 8개 이므로 (8-1) * 0.25 = 1.75이다
근데 0번, 2번, 4번 ... 과 같은 정수 값이 아니라 1.75번 인덱스에 있는 숫자를 어떻게 구해야 할까?
우선 1.75 는 1과 2 사이에 있기 때문에 1번 인덱스인 15와 2번 인덱스인 20 사이에 존재 !
이제 0.75라는 소수를 고려해보자
0.75 는 15와 20사이에서 4분의 3 지점 !
값을 구하려면 15 * (1 - 0.75) + 20 * 0.75를 계산하면 된다 = Q1 은 18.75

Q3을 계산하자면 Q3의 인덱스는 (8 - 1) * 0.75를 해서 5.25가 된다 !
즉 5번 인덱스인 57과 6번 인덱스인 63 사이에 1/4 지점이라고 할 수 있음
57 * (1 - 0.25) + 63 * 0.25를 계산해서 Q3은 58.5가 된다 !!
이상값 구하기
이상점 = 박스플롯에서 박스와 위스커 바깥에 있는 점들
이상점을 구분하기 위한 명확한 기준 중 Q1와 Q3 값 활용하기 가 있음
Q1과 Q3의 거리를 알아야하는데 이거는 Q3에서 Q1을 빼면 된다 (이 값을 IQR이라 함)
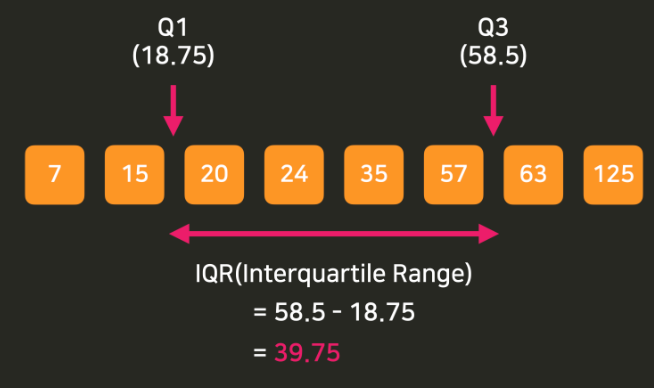
보통 Q1지점에서 아래로 1.5 IQR 더 떨어져 있거나 Q3 지점에서 위로 1.5 IQR 더 떨어져 있는 값을 이상점이라고 판단 함

10.7 상관 계수
상관 계수 = 연관성을 표현하는 수치
피어슨 상관계수 : -1부터 1까지 값을 가질 수 있음
0이면 x와 y는 연관이 아예 없다
0보다 크면 1에 가까울 수록 연관성이 높다 (x가 커질 수록 Y가 커진다는 뜻)
1이면 연관이 확실하다는 뜻
0보다 작으면 -1에 가까워질 수록 연관성이 크다는 뜻
-1이면 x와 y는 확실한 반대 관계
10.8 상관 계수 퀴즈

퀴즈 해설
1번: 상관 계수는 데이터에서 두 변수가 얼마나 연관성이 있는지 보여주는 값입니다.
2번: 두 변수의 연관성이 전혀 없다면 상관계수는 0입니다. 상관 계수가 -1이라면 음의 상관 관계가 있다는 의미입니다.
3번: 상관 계수는 두 변수가 얼마나 연관성이 있는지 나타내기 때문에 데이터가 많다고 상관계수가 높아지는 것은 아닙니다.
4번: 산점도 그래프가 촘촘하게 그려진다고 해서 상관 관계가 항상 높은 것은 아닙니다. 예를 들어, 산점도 그래프가 원 모양으로 촘촘하게 그려지면 상관 관계가 높지 않은 것입니다. 촘촘하면서 대각선 형태를 보여야 높은 상관 관계를 보인다고 할 수 있습니다.
5번: 게임을 많이 할수록 성적이 떨어진다면, 게임을 하는데 쓰는 시간과 성적은 음의 상관관계가 있다고 할 수 있습니다.
10.9 상관 계수 시각화
데이터 사이의 상관계수를 알아보자 !
DataFrame의 corr()메소드를 사용하면 숫자 데이터 사이의 상관 계수를 볼 수 이씀
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/exam.csv')
df.corr()output
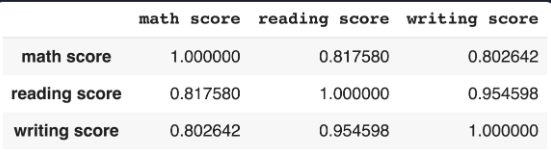
상관 계수도 DataFrame 형태로 출력됨. 하지만 숫자가 많아서 한눈에 안들어온다? 그럼 히트맵을 사용해보자
히트맵 = 상관 계수를 시각화 하는 대표적인 방법 (Seaborn을 이용해서 그릴 수 이씀)
코드는 sns.heatmap()을 사용함. 상관계수의 결과를 Seaborn의 heatmap 메소드에 넘겨주면 된다
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/exam.csv')
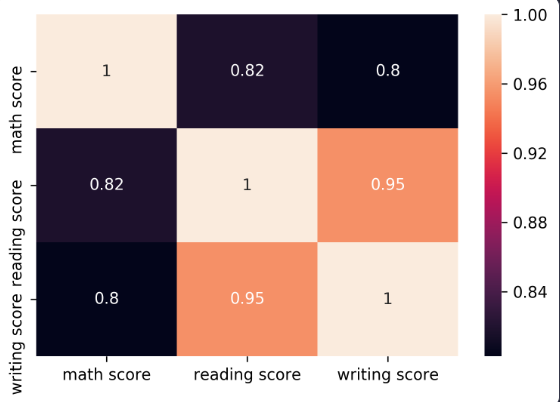
sns.heatmap(df.corr())output

ㄴ 색이 밝을 수록 상관 계수가 더 높다는 뜻 !
여기선 reading score와 writing score 사이의 상관 관계가 가장 강하다는 것을 알 수 있다
annot = True 옵션을 추가하면 숫자도 함께 보여진다
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/exam.csv')
sns.heatmap(df.corr(), annot=True)output