
9.1 Seaborn 소개
= Statistical Data Visualization
다양한 그래프를 사용할 수 있음 !
pandas 보다 더 근사한 그래프를 그릴 수 있다
9.2 확률 밀도 함수 (PDF)
PDF = Probability Density Function
- 확률밀도함수 = 데이터셋의 분포를 나타낸다
- 특정 구간의 확률은 그래프 아래 그 구간의 면적과 동일하다
- 모든 구간의 확률을 다 더하면
1이다
9.3 확률 밀도 함수 개념 확인
- 다음 중 PDF에 대한 설명으로 옳지 않은 것은?

퀴즈 해설
(1) PDF 아래의 면적은 확률을 의미합니다. 모든 확률을 합하면 100%이기 때문에 PDF 아래의 면적은 1입니다.
(2) PDF의 정의입니다.
(3) PDF에서 특정 값이 일어날 확률은 0%입니다. 특정 범위에 대해서만 0이 넘는 확률을 가질 수 있습니다.
(4) 시계 한 바퀴는 12시간이며 1시부터 3시까지는 2시간입니다. 1시부터 3시까지 시계 바늘이 위치할 확률은 2/12, 약분하면 1/6 입니다.
- 2080년… 드디어 화성을 향한 우주선이 출발합니다. 하지만 안정성 문제로 키가 160cm~180cm인 사람들만 탑승할 수 있는데요. PDF의 그래프가 아래와 같다면, 어떤 사람이 우주선을 탑승할 수 있을 확률(%)은 얼마일까요?
답 : 65
퀴즈 해설
PDF 아래의 넓이를 계산하면 확률을 알 수 있습니다. 키가 160cm 이하일 확률은 8%이고 키가 180cm 이상일 확률은 27%이기 때문에, 어떤 사람이 우주선을 탈 수 있을 확률은 160cm와 180cm 사이인 65%입니다.
9.4 KDE Plot
구글 코랩에 Seaborn 까는 명령어는
pip install seaborn이다 !
파일 불러오기
import pandas as pd
import seaborn as sns
body_df = pd.read_csv('drive/MyDrive/dataScience/data/body.csv',index_col=0)
body_df.head()output
Height 만 불러와서 그래프를 만들고자 하기 때문에
body_df['Height']output
Number
1 176.0
2 175.3
3 168.6
4 168.1
5 175.3
...
996 171.8
997 171.5
998 177.9
999 174.4
1000 173.5
Name: Height, Length: 1000, dtype: float64몇번 나오는지 세기
body_df['Height'].value_counts()output
174.9 13
172.5 13
173.2 12
175.3 12
175.2 12
..
160.2 1
188.2 1
162.0 1
185.1 1
184.4 1
Name: Height, Length: 262, dtype: int64.sort_index()를 사용하면 얼마나 count됐는지가 순서대로 나열돼서 나온당
body_df['Height'].value_counts().sort_index()output
154.4 1
155.5 1
157.4 1
157.8 1
158.0 1
..
190.3 1
191.2 1
191.8 1
192.4 1
193.1 1
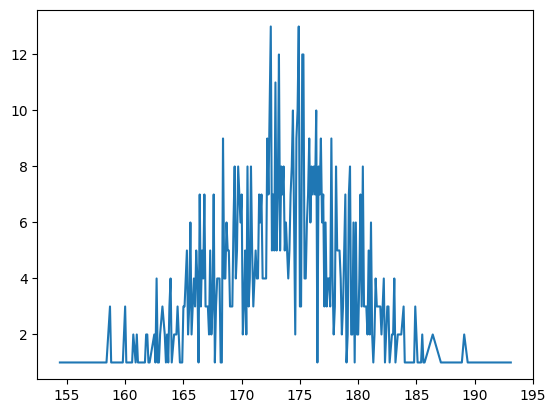
Name: Height, Length: 262, dtype: int64그 다음에 이제 .plot()을 이용해서 그래프를 그리면 !!
body_df['Height'].value_counts().sort_index().plot()output
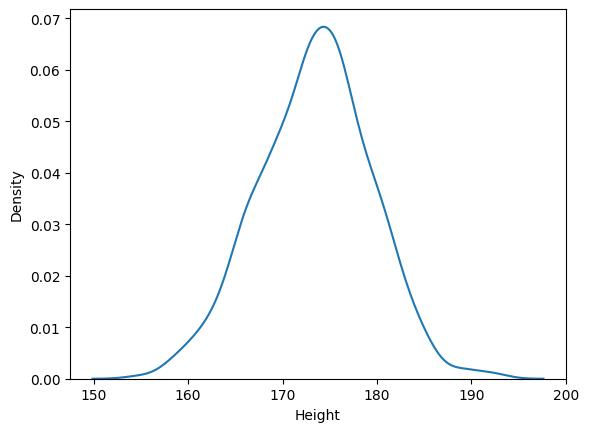
이거를 확률밀도함수로 표현하고자 sns.kdeplot()을 써서 불러오면
sns.kdeplot(body_df['Height'])output
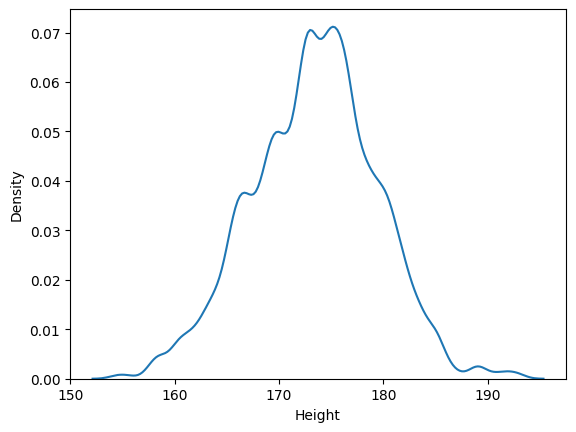
구간을 나누고자 한다면 bw_adjust = 을 사용하자
sns.kdeplot(body_df['Height'],bw_adjust=0.5)output
9.5 (실습) 서울 지하철 승차인원
서울 지하철 역에 대한 승차인원 및 하차인원 정보가 주어져 있습니다.
승차인원에 대한 KDE Plot을 그려 보세요.
code
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/subway.csv')
sns.kdeplot(df['in'])9.6 KDE 활용 예시
KDE가 히스토그램에 활용되는 예시
우선 히스토그램을 그려보자
body_df.plot(kind = 'hist', y='Height',bins = 15)output
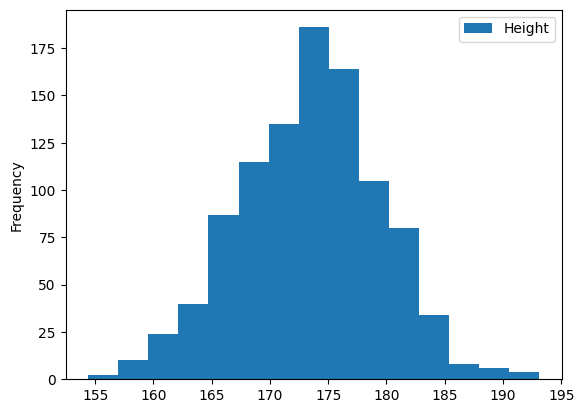
KDE를 히스토그램 위에 얹고자 한다면 앞에 sns.displot()을 써주면 된당
근에 신기한거는 kind = 'hist'를 쓰지 않아도 알아서 히스토그램으로 된다 왜지 ㅋㅋ
sns.displot(body_df['Height'],bins = 15)output
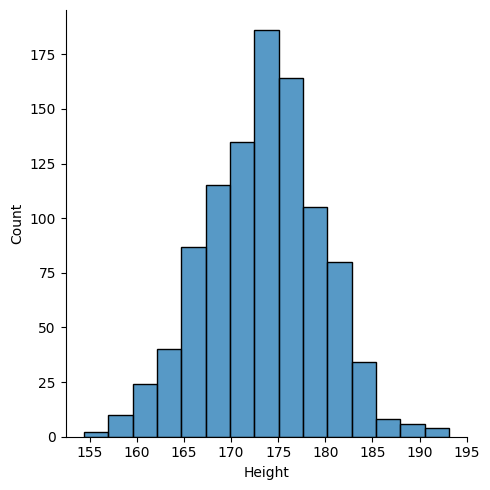
구글코랩에서는 근데 지원해주지는 않는듯 하다 원래 선이 따라가야되는데 ㅠ
KDE가 박스플롯에 사용되는 예시
박스플롯을 먼저 그려보면
body_df.plot(kind = 'box',y = 'Height')output

KDE를 넣을 때는 sns.violinplot을 써보자
sns.violinplot(y=body_df['Height'])output
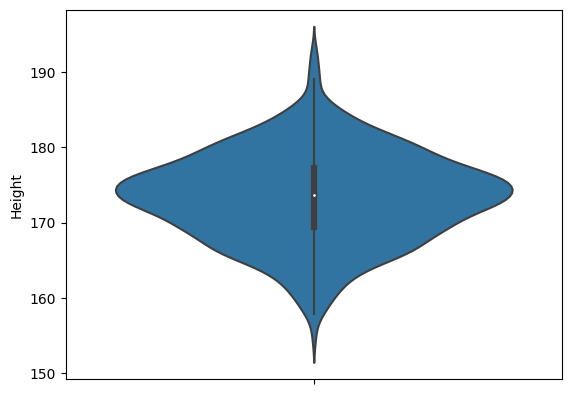
KDE가 산점도에 활용되는 예시
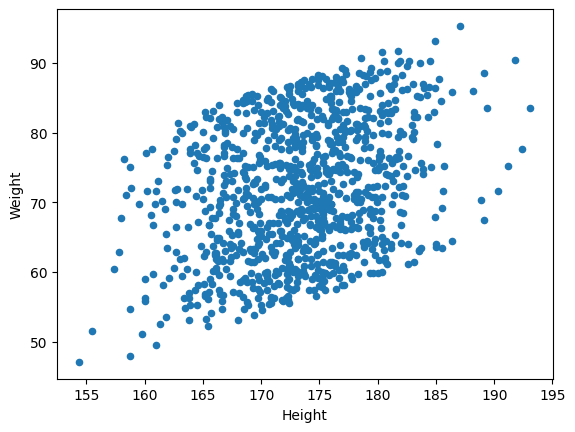
산점도를 먼저 그려보자
body_df.plot(kind = 'scatter', x= 'Height', y = 'Weight')output
등고선을 그리기 위해서 매개변수를 두개를 넣어보았는데
sns.kdeplot(body_df['Height'], body_df['Weight'])output
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-27-0b815c6a296e> in <cell line: 3>()
1 x= 'Height'
2 y='Weight'
----> 3 sns.kdeplot(body_df[x], body_df[y])
TypeError: kdeplot() takes from 0 to 1 positional arguments but 2 were given이런 에러가 떴다.. 아무래도 구글 코랩에서는 안되는 듯 하다 ㅠ
9.7 (실습) 교수님의 연봉은?
교수가 꿈인 지훈이는 교수들의 급여 분포를 알아보려고 합니다.
인터넷에서 어느 학교 교수의 급여 데이터를 발견했네요!
급여 ('salary')에 대한 Violin Plot을 그려 보세요.
code
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/salaries.csv')
sns.violinplot(x=df['salary'])x=는 붙이지 않아도 되는 것 같다
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/salaries.csv')
sns.violinplot(df['salary'])9.8 LM Plot
lmplot을 사용하는 것은 간단하다. 하던대로 sns.lmplot()을 사용하면 됨 !
data에는 원하는 파일, 가로축에 오고자하는 건 x에, 세로축엔 y에 넣으면 된다 ~~
sns.lmplot(data=body_df,x='Height',y='Weight')output
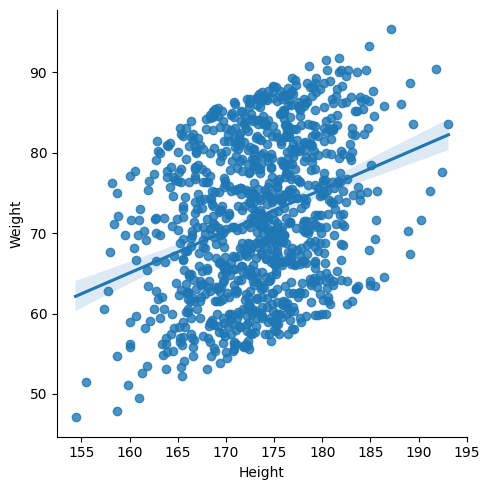
lmplot을 쓰면 회귀선이 나온다! 이 회귀선은 흩어져 있는 점들을 최대한 하나의 선으로 만들고자 한 선인데 x와 y의 연관성이 높을 수록 이 회귀선의 예측도가 올라간다
9.9 카테고리별 시각화
먼저 파일을 불러와줍니당
import pandas as pd
import seaborn as sns
laptops_df = pd.read_csv('drive/MyDrive/dataScience/data/laptops.csv')
laptops_df.head()os 항목을 보고자 하기 때문에 이렇게 치고 데이터를 분석하장
laptops_df['os'].unique()output
array(['linux', 'mac', 'windows'], dtype=object)이제 그래프를 그려줄 건데 우리는 카테고리별로 그릴것이기 때문에
sns.catplot()을 사용하면 된다!
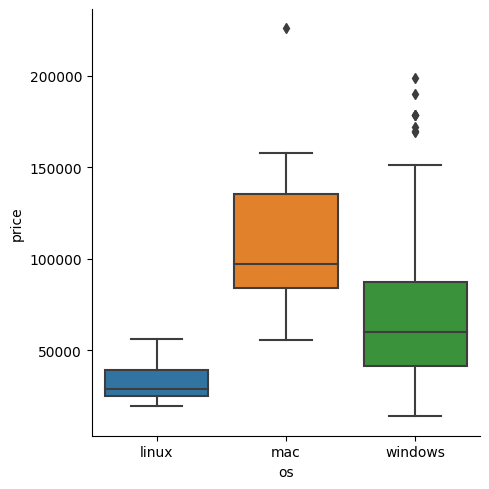
sns.catplot(data = laptops_df, x = 'os', y = 'price', kind = 'box')ㄴ 박스플롯으로 할 거여서 kind = 'box'써줌
output
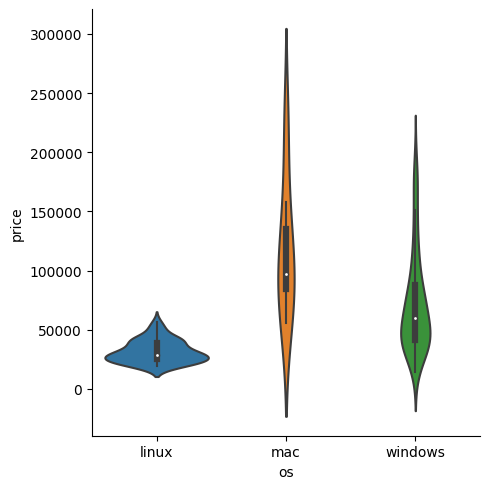
violin 형태로 보고자 하면 역시 kind = 'violin'을 써주면 된다
sns.catplot(data = laptops_df, x = 'os', y = 'price', kind = 'violin')output
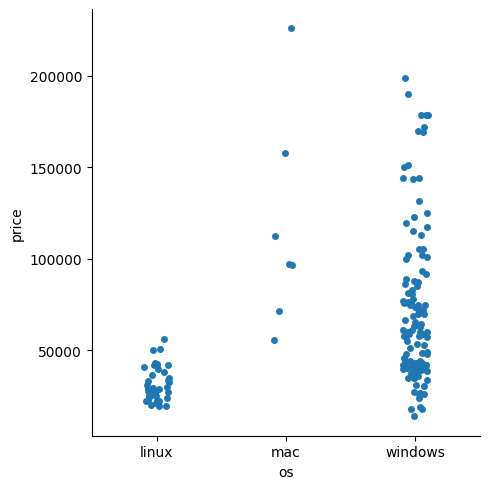
하지만 여기서 단점이 있는데, 각 os에 데이터가 몇개씩 있는지 모르니까 이 plot들을 얼마나 믿을 수 있는지 모른다는 것이다. 이럴 때에는 strip plot을 쓰자
kind = 'strip'으로 입력
sns.catplot(data = laptops_df, x = 'os', y = 'price', kind = 'strip')output
processotr brand항목도 보고자 한다
laptops_df['processor_brand'].unique()output
array(['intel', 'amd'], dtype=object)색을 나타내기 위해 hue = 를 쓰면 되고 우리는 아까 processor brand를 보고자 했기 때문에 hue = 'processor_brand'를 적으면 된다 !
sns.catplot(data = laptops_df, x = 'os', y = 'price', kind = 'strip', hue = 'processor_brand')output
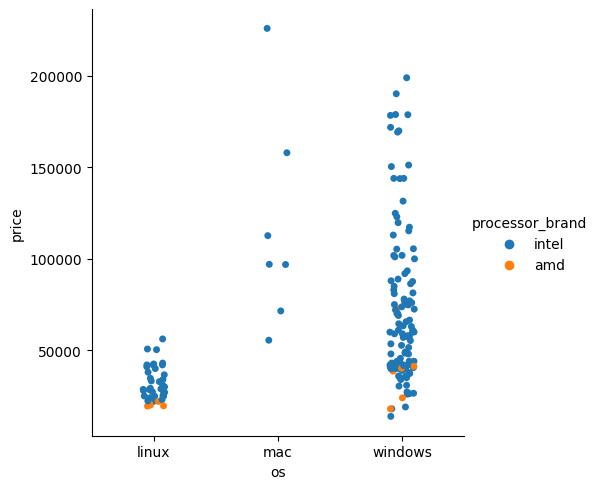
그러면 이렇게 색이 나누어서 보여진다
데이터 하나하나 살펴볼 수 있지만 점들이 많이 모여있는 부분들은 보기가 불편하기 때매 swarm을 사용하자
sns.catplot(data = laptops_df, x = 'os', y = 'price', kind = 'swarm', hue = 'processor_brand')output
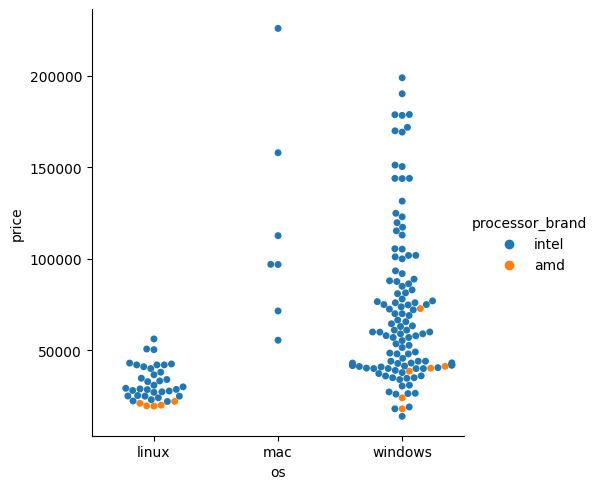
9.10 보험금 분석하기
보험 회사에서 보험금이 어떻게 지출되었는지 분석하려고 합니다.
다음과 같이 흡연 여부 카테고리에 따라 보험금을 살펴볼 수 있는 그래프를 그려보세요.
code
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/insurance.csv')
sns.catplot(data = df, x = 'smoker', y = 'charges', kind = 'violin')