
8.1 시각화와 두 가지 목적
시각화가 중요한 이유
- 분석에 도움을 준다
- 이상점을 찾을 수 있다
8.2 선 그래프
대박 재밌당 ㅎㅎ
선그래프를 불러오기 위한 명령어로 우리는 %matplotlib inline을 쓴다
내 생각엔 %matplotlib이 그래프 명령어 이고 선그래프여서 inline을 붙인 듯
%matplotlib inline
import pandas as pd그리고 csv 파일을 불러온다
df=pd.read_csv('drive/MyDrive/dataScience/data/broadcast.csv',index_col=0)
dfoutput
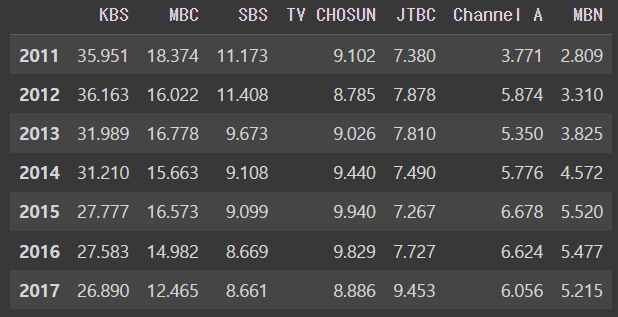
그래프로 바꿀 때 사용하는 명령어는 .plot()이다
df.plot(kind = 'line')output
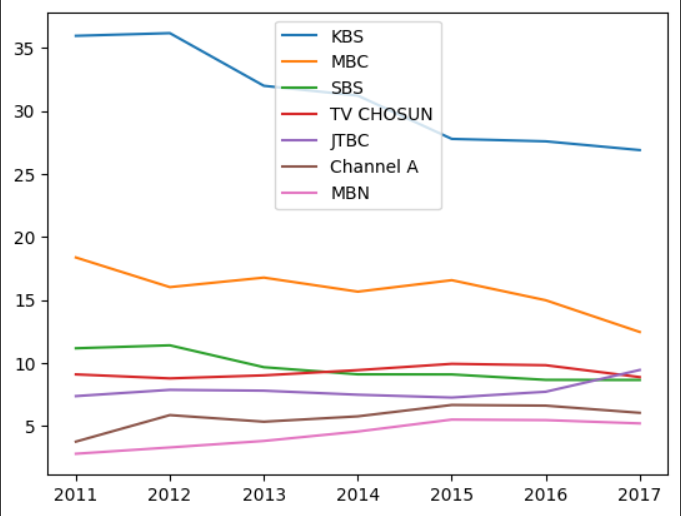
그래프의 기본형은 선그래프여서 원래는 plot()을 쓸 때 매개변수로 kind를 써야하지만 선 그래프일 때는 생략도 가능하다
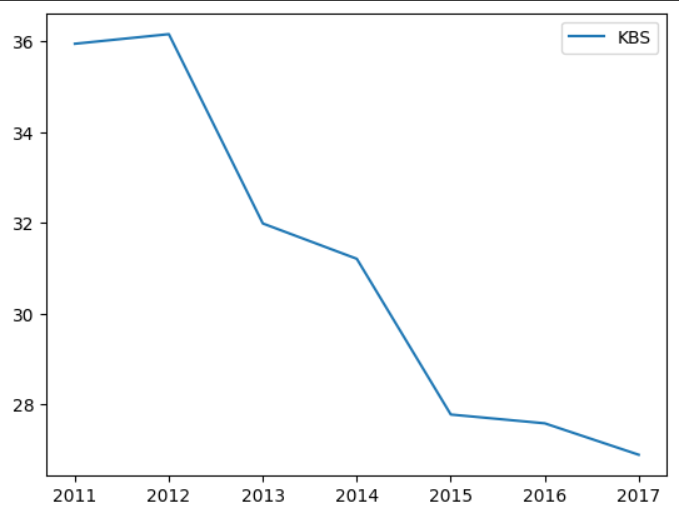
KBS 데이터만 그래프화 하려면
df.plot(y='KBS')output
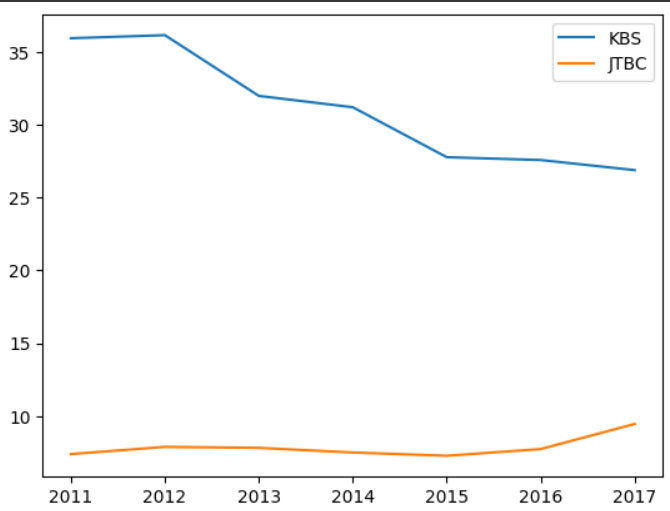
여러개를 하고 싶다면 리스트를 쓰자
df.plot(y=['KBS','JTBC'])output
슬라이싱한 데이터 프레임을 먼저 불러오고
df[['KBS','JTBC']]output
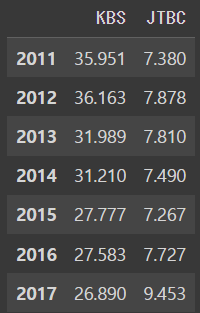
그 후에 그래프화 시키는 것도 가능하다
df[['KBS','JTBC']].plot()output
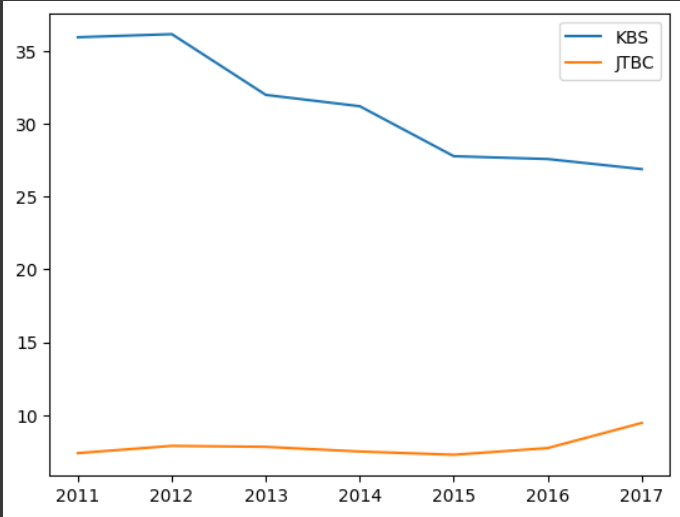
Series 역시 가능하다 !
df['KBS']output
2011 35.951
2012 36.163
2013 31.989
2014 31.210
2015 27.777
2016 27.583
2017 26.890
Name: KBS, dtype: float64.plot()만 입력하자
df['KBS'].plot()output
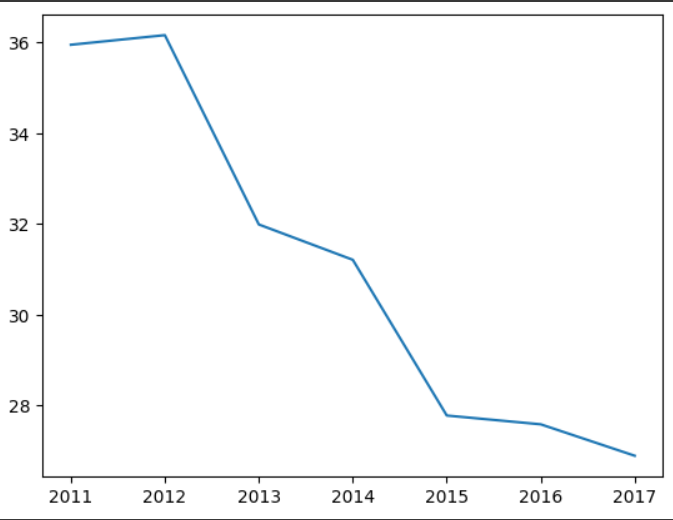
유의할 점 !
= 선 그래프는 문자로 되어있는 데이터프레임을 그래프로 만들 때에는 오류가 발생하기 때문에 주의하자
8.3 (실습) 국가별 경제 성장
주어진 데이터를 이용해서 한국(Korea_Rep), 미국(United_States), 영국(United_Kingdom), 독일(Germany), 중국(China), 일본(Japan)의 GDP 그래프를 그려 보세요.
code
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/gdp.csv', index_col=0)
df.plot(y=["Korea_Rep", "United_States", "United_Kingdom", "Germany", "China", "Japan"])8.4 (실습) 국가별 경제 성장 분석
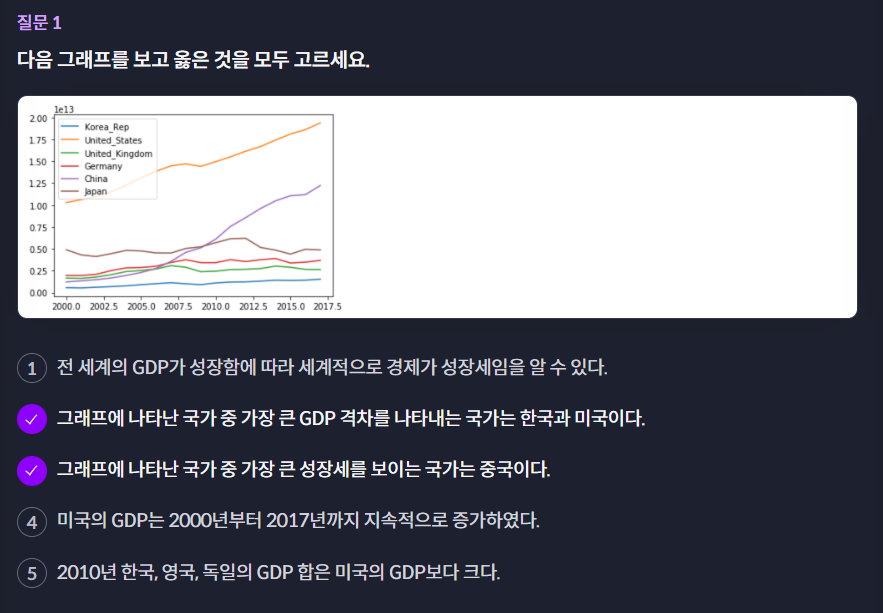
퀴즈 해설
위 그래프로는 전 세계의 GDP 추이를 알 수 없습니다.
미국의 GDP는 2007년도에 감소합니다.
2010년도에 한국, 영국, 독일의 GDP 합은 0.5 정도로 미국(1.35)보다 작습니다.
정답: 2, 3
8.5 막대 그래프
- 카테고리를 비교하기 위해 사용
%matplotlib inline
import pandas as pd
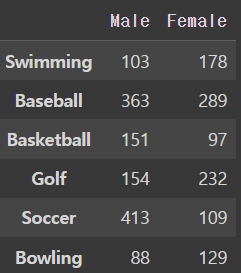
df = pd.read_csv('drive/MyDrive/dataScience/data/sports.csv',index_col=0)
dfoutput
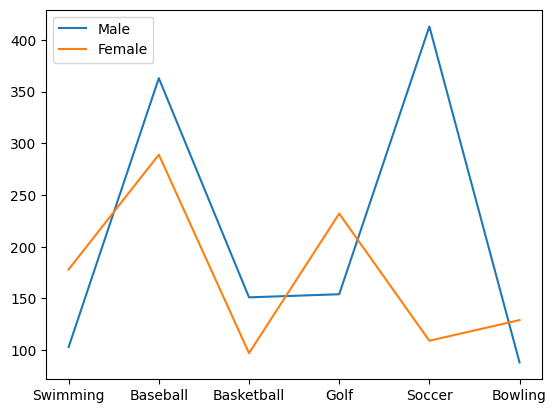
전 처럼 선그래프로 나타내면
df.plot()output
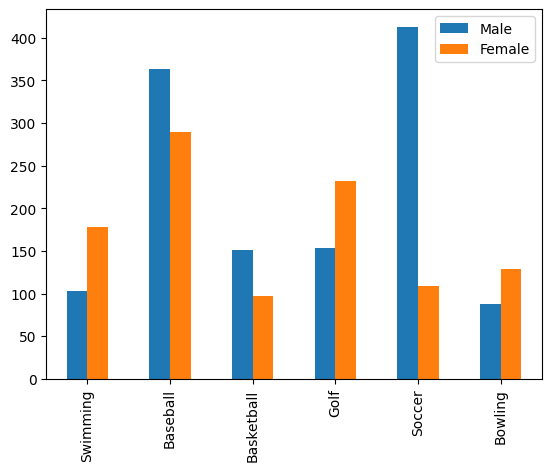
선그래프로 만들어주려면 .plot(kind = 'bar') 을 사용하면 된다
df.plot(kind = 'bar')output
막대를 눕히고 싶다면 (kind = 'barh')를 쓰면 된다
df.plot(kind ='barh')output
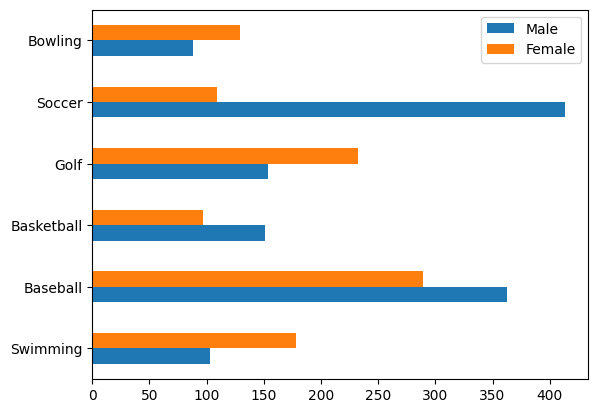
막대를 누적으로 쓰고싶다면 (kind = 'bar',stacked = True)를 쓰자
df.plot(kind = 'bar',stacked = True)output
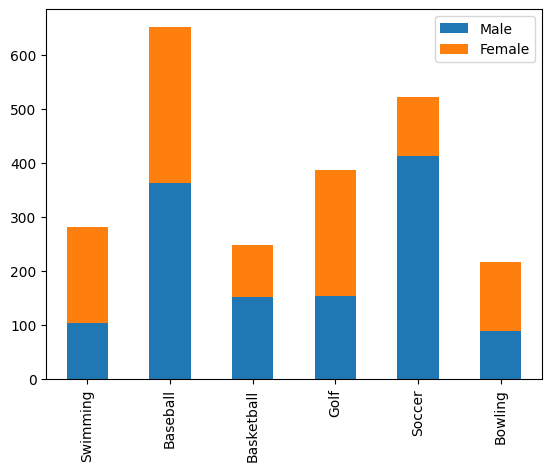
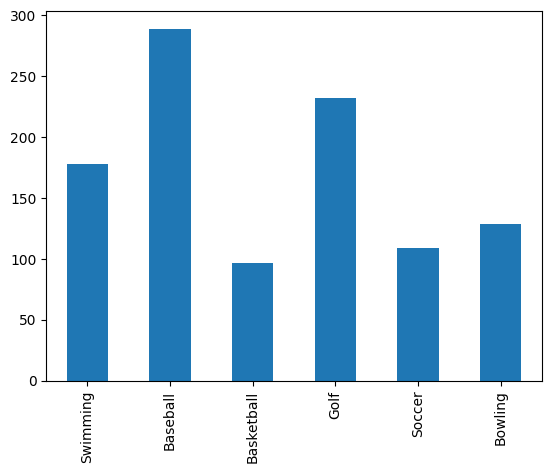
하나의 항목만 뽑아서 막대 그래프로 추출하고 싶다면
데이터를 뽑고
df['Female']output
Swimming 178
Baseball 289
Basketball 97
Golf 232
Soccer 109
Bowling 129
Name: Female, dtype: int64그래프화 시키면 된다
df['Female'].plot(kind = 'bar')output
8.6 (실습) 실리콘 밸리에는 누가 일할까 ? I
실리콘 밸리에서 일하는 사람들의 정보가 있습니다.
직업 종류, 인종, 성별 등이 포함되어 있는데요.
실리콘 밸리에서 일하는 남자 관리자 (Managers)에 대한 인종 분포를 막대 그래프로 다음과 같이 그려보세요.
code
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/silicon_valley_summary.csv')
boolean_male = df['gender']=='Male'
boolean_manager = df['job_category'] == 'Managers'
boolean_not_all = df['race_ethnicity'] != 'All'
df[boolean_male & boolean_manager & boolean_not_all].plot(kind = 'bar', x = 'race_ethnicity', y = 'count')8.7 파이 그래프
- 절대적인 수치보다 비율을 표현하기에 좋음
파일을 불러와준다
df = pd.read_csv('drive/MyDrive/dataScience/data/broadcast.csv',index_col=0)
dfoutput

2017년도 데이터를 뽑아준다
df.loc[2017]output
KBS 26.890
MBC 12.465
SBS 8.661
TV CHOSUN 8.886
JTBC 9.453
Channel A 6.056
MBN 5.215
Name: 2017, dtype: float64파이 그래프를 만들 때는 kind = 'pie'를 쓰면 됨
df.loc[2017].plot(kind='pie')output
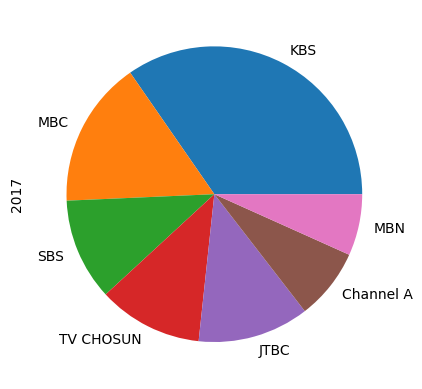
8.8 (실습) 실리콘 밸리에는 누가 일할까? II
이번에는 어도비 (Adobe)의 직원 분포를 한번 살펴봅시다.
어도비 전체 직원들의 직군 분포를 파이 그래프로 그려보세요.
(인원이 0인 직군은 그래프에 표시되지 않아야 합니다.)
%matplotlib inline
import pandas as pd
df = pd.read_csv("data/silicon_valley_details.csv")
boolean_adobe = df['company'] == 'Adobe' #회사가 adobe 이고
boolean_all_races = df['race'] == 'Overall_totals' # 인종이 Overall_totals만 고르고
boolean_count = df['count'] != 0 # count가 0인 것들 제외
boolean_job_category = (df['job_category'] != 'Totals') & (df['job_category'] != 'Previous_totals') # Previous_totals 와 Totals 도 제외
df_adobe = df[boolean_adobe & boolean_all_races & boolean_count & boolean_job_category]
df_adobe.set_index('job_category', inplace=True) # 파이 그래프는 index 기준으로 이름표를 붙여주게 돼서 직업 카테고리로 이름표 바꿔주기
df_adobe.plot(kind='pie', y= 'count')8.9 히스토그램
key들을 각각의 항목이 아니라 범위로 묶어서 보는 그래프
csv파일을 불러와줌
import pandas as pd
df = pd.read_csv('drive/MyDrive/dataScience/data/body.csv',index_col=0)
df.head(10)output
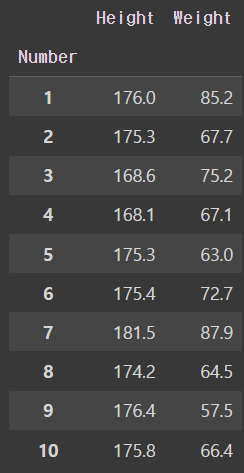
히스토그램을 만들 때는 kind = 'hist'라고 하면 된다
df.plot(kind = 'hist',y = 'Height')output
상세히 나누고자 범위의 개수를 정하고 싶다면
df.plot(kind = 'hist',y = 'Height',bins = 15)output
하지만 너무 상세히 나누어도 좋을 것은 없다
df.plot(kind = 'hist',y = 'Height',bins = 200)output
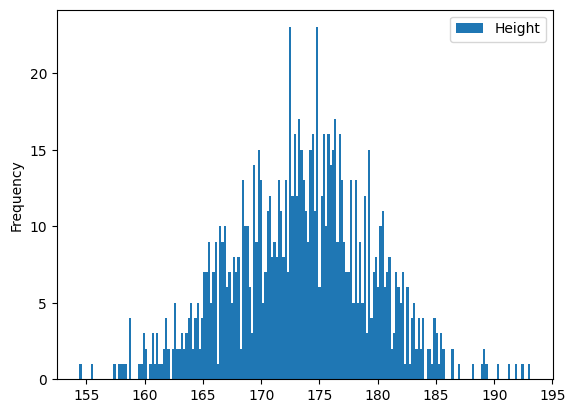
8.10 (실습) 스타벅스 음료의 칼로리는 ?
스타벅스 음료의 칼로리 및 영양소 정보가 있습니다.
스타벅스 음료의 칼로리 분포는 어떻게 되는지, 히스토그램을 그려서 확인해 봅시다.
원하는 결과가 나오도록 df.plot() 메소드의 괄호를 채워 보세요!
code
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/starbucks_drinks.csv')
df.plot(kind = 'hist',y='Calories', bins = 20) # 괄호안에 코드를 작성하세요8.11 박스 플롯
- 어떤 데이터셋에 대한 통계 정보를 시각적으로 보여주기 위해 사용됨
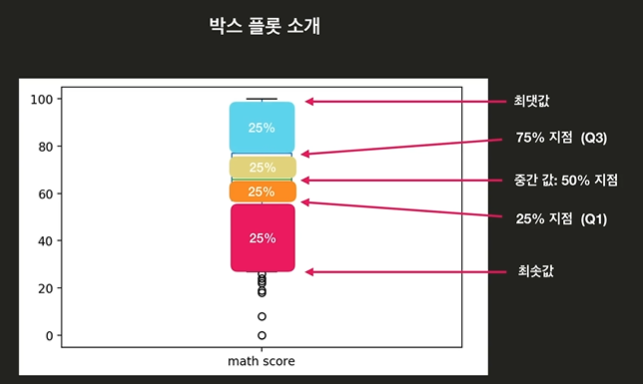
파일 불러오기
%matplotlib inline
import pandas as pd
df = pd.read_csv('drive/MyDrive/dataScience/data/exam.csv')
df.head()output
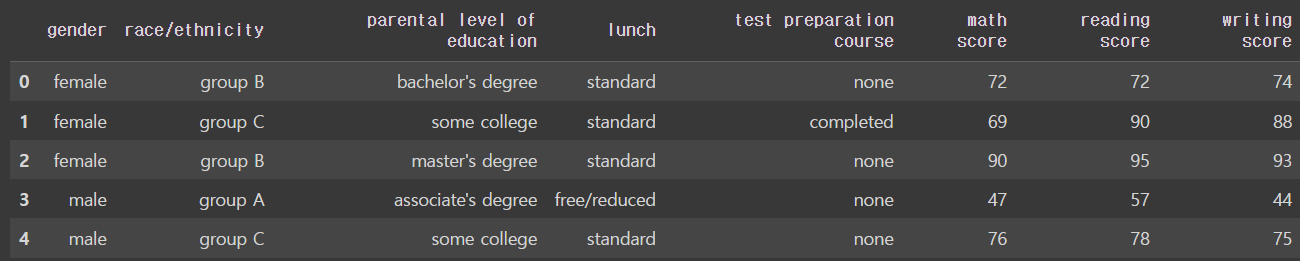
math score만 얻고 싶다면
df['math score'].describe()output
count 1000.00000
mean 66.08900
std 15.16308
min 0.00000
25% 57.00000
50% 66.00000
75% 77.00000
max 100.00000
Name: math score, dtype: float64박스 플롯을 만들고 싶으면 kind = 'box'로 해주면 된다
df.plot(kind = 'box',y = 'math score')output
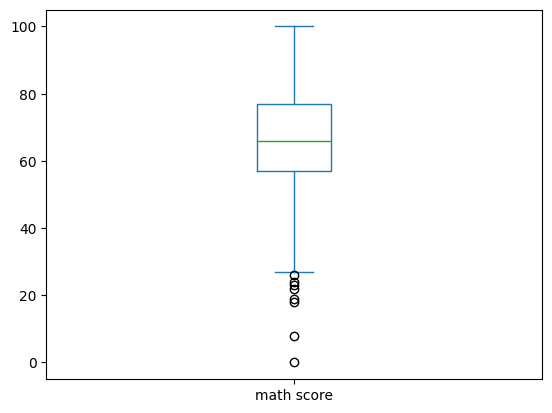
여러가지 항목을 박스플롯으로 만들고 싶을 땐 리스트를 쓰자
df.plot(kind = 'box',y = ['math score','reading score','writing score'])output
8.12 (실습) 스타벅스 음료의 칼로리는? II
이번엔 스타벅스 음료의 칼로리를 박스 플롯으로 그려봅시다.
code
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/starbucks_drinks.csv')
df.plot(kind = 'box', y = 'Calories')이렇게도 가능 !!
%matplotlib inline
import pandas as pd
df = pd.read_csv("data/starbucks_drinks.csv")
df['Calories'].plot(kind='box')8.13 산점도
- 상관관계를 보여주기 적합한 그래프
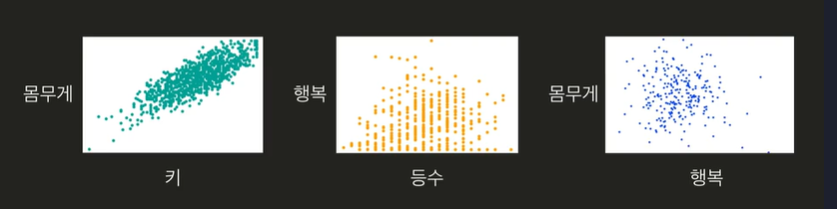
파일 불러오기
%matplotlib inline
import pandas as pd
df = pd.read_csv('drive/MyDrive/dataScience/data/exam.csv')
df.head()output
산점도를 나타내려면 kind = 'scatter'을 쓰자
그리고 x와 y축을 지정해줘야 함
df.plot(kind = 'scatter', x = 'math score', y = 'reading score')output
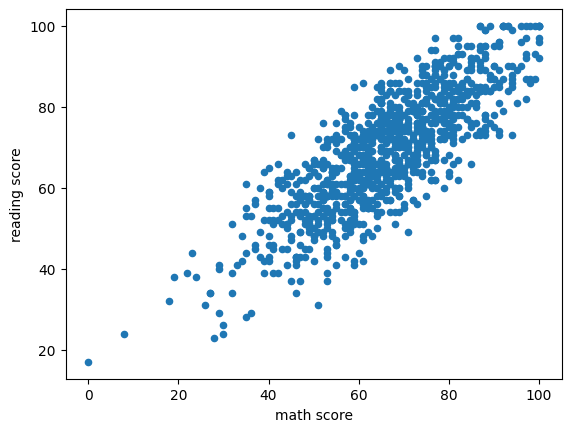
이런식으로 하면 된다 !!
df.plot(kind = 'scatter', x = 'reading score', y = 'writing score')output
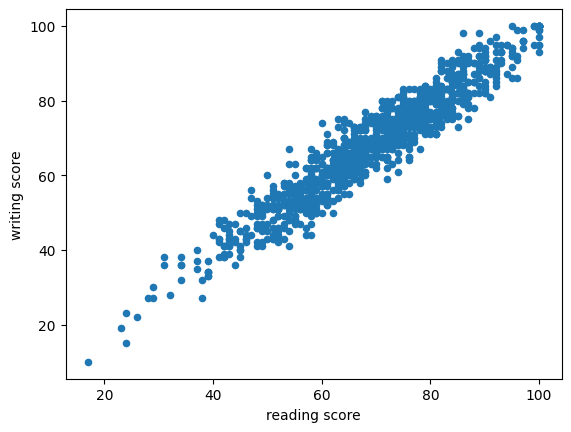
8.14 (실습) 국가 지표 분석하기
아래 데이터를 직접 다운로드 받은 후, 본인의 Jupyter notebook에서 실행하여 분석하고 결과를 적어주시면 됩니다.
주어진 데이터에는 여러 가지 지표가 column에 포함되어 있습니다.
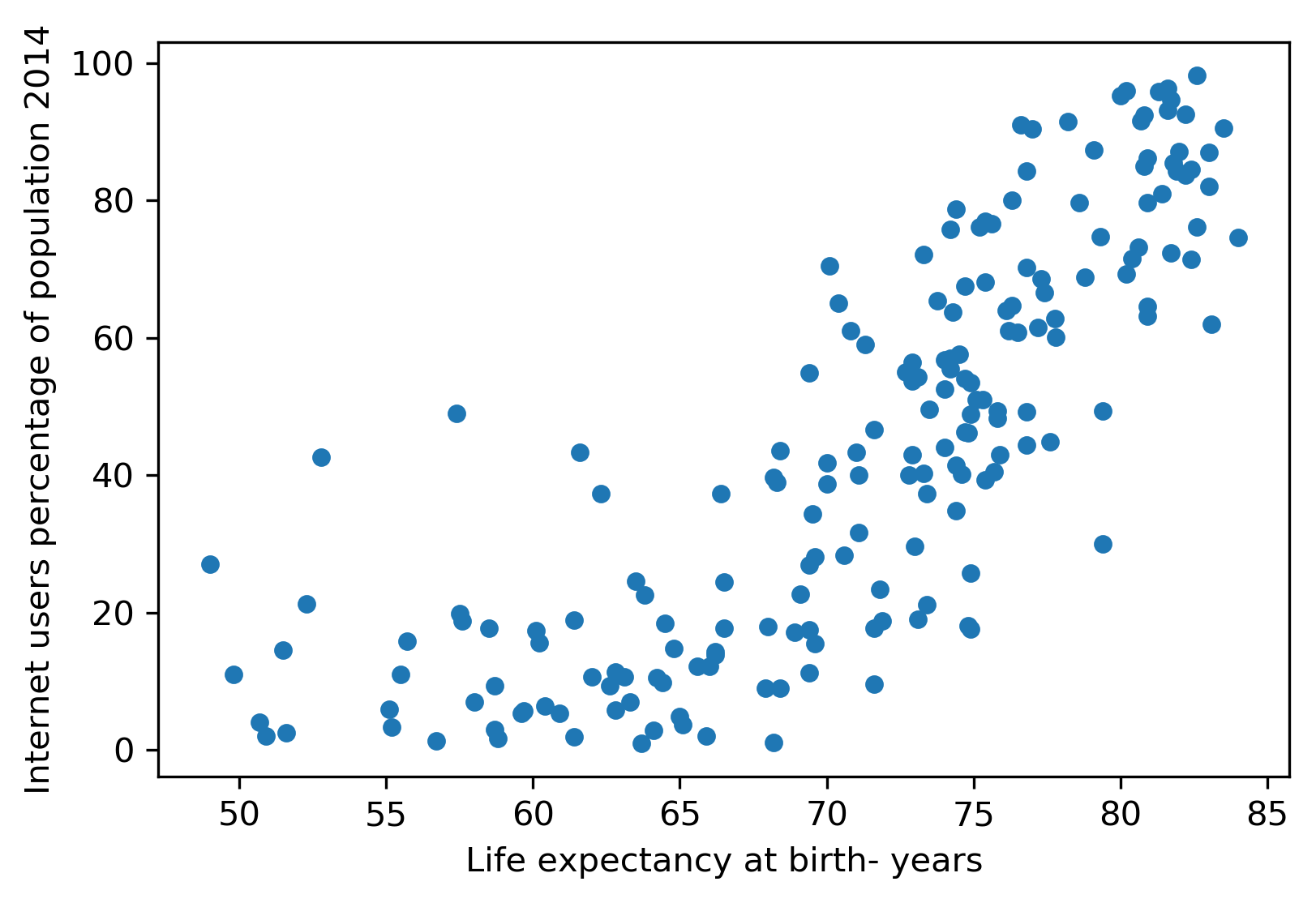
- 기대 수명: 'Life expectancy at birth- years'
- 인터넷 사용자 비율: 'Internet users percentage of population 2014'
- 숲 면적 비율: 'Forest area percentage of total land area 2012'
- 탄소 배출 증가율: 'Carbon dioxide emissionsAverage annual growth'
다음 중 가장 연관성이 깊은 지표를 찾아보세요.

정답의 산점도
8.15 (실습) 어느 그래프가 어울릴까?
-
냥냥동물병원에 고양이 20,000 마리의 몸무게 데이터가 있습니다. 고양이들의 몸무게가 어떻게 분포하고 있는지 몸무게의 범위를 나눠서 알아보려고 합니다. 어떤 시각화 방법을 사용하면 의미 있는 결과를 얻을 수 있을까요?
ㄴ 히스토그램을 그리면 고양이들의 몸무게 분포를 범위별로 파악할 수 있기 때문 -
하루 평균 습도와 그 날의 화재 발생 횟수에 대한 10년치 데이터가 있습니다. 소방서에서는 습도와 화재 발생 횟수 사이에 어떤 상관 관계가 있는지 파악해보려고 합니다. 어떤 그래프를 이용하는 것이 좋을지 골라보세요.

ㄴ 산점도를 활용하면 두 변수 사이의 상관 관계를 파악할 수 있습니다.
하루 평균 습도를 x축으로, 화재 발생 횟수를 y축으로 두고, 각 데이터를 점으로 표현하면 습도와 화재 발생 횟수 사이의 관계를 시각화할 수 있습니다. -
코드잇에서 신규 과목 5개를 출시하였습니다. 이 5개 과목에서 1년 동안 발생한 매출의 비율을 비교해보려고 합니다. 가장 적합하다고 생각하는 그래프를 골라주세요.
ㄴ 파이 그래프를 사용하면 5개 과목에서 1년 동안 발생한 전체 매출을 원 전체로 보고, 그 안에서 각 과목이 차지하는 비율을 확인할 수 있습니다.

좋은 정보 얻어갑니다, 감사합니다.