
1.1 머신 러닝 더 빠르고 정확하게 토픽
scikit-learn도 아무렇게나 사용하면 성능이 떨어질 수 있다 !
이번 토픽에선
- 머신 러닝 알고리즘의 속도와 정확도를 높이는 법
- 이 이론들을 scikit-learn과 pandas 라이브러리에서 적용하는 법
을 배우고자 한다 !!
이는 앞으로 배울 수많은 머신 알고리즘에도 적용이 가능하다 !!
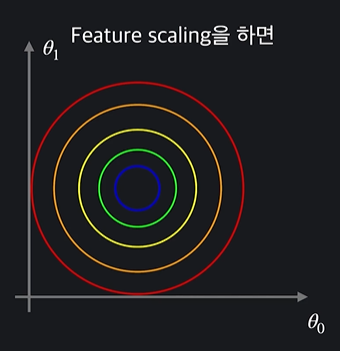
1.2 Feature Scaling : Normalization
데이터 전처리 : 데이터를 그대로 사용하지 않고, 가공해서 모델을 학습시키는데 좀 더 좋은 형식으로 만들어주는 것
Feature Scaling = 머신 러닝 모델에 사용할 입력 변수들의 크기를 조정해서 일정 범위 내에 떨어지도록 바꾸는 것
ex) 연봉과 나이라는 입력변수가 있다고 가정
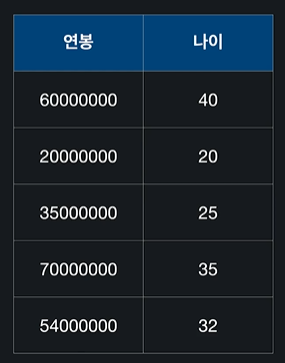
이 변수의 두 규모 단위의 차가 커서 머신러닝에 방해가 될 수도 있다
-> feature scaling을 해서 일정 범위 내에 들어오도록 바꿔줌
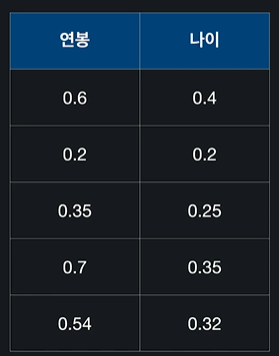
Feature Scaling을 하는 이유
- 경사 하강법을 좀 더 빨리할 수 있게 도와준다
min-max normalization
: 최솟값, 최댓값을 이용해서 데이터의 크기를0과1사이로 바꿔준다 ex) 키를 입력변수
여기서 가장 큰 값과 가장 작은 값을 찾아내서 차이를 구함
= 210-140=70
그 다음에는 모든 데이터에(데이터 - 최솟값) / (최댓값 - 최솟값)을 해준다
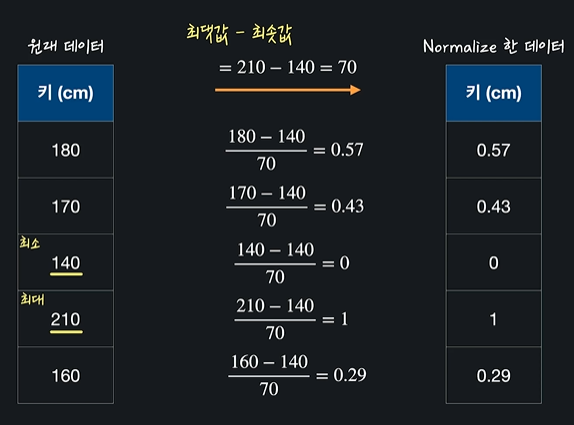
이렇게 feature scaling을 해주면 항상 0과 1사이가 나온다 = 모든 데이터 값이 140과 210 사이에 있다는 뜻
min-max normalization 일반화

ㄴ 0과 1사이의 숫자로 바꿈
1.3 scikit-learn으로 Normalization 해보기
이번에는 sklearn에서 새로운 모듈인 preprocessing을 불러와보았당
import pandas as pd
import numpy as np
from sklearn import preprocessing파일경로를 NBA_FILE_PATH에 지정하고
이걸 읽어서 또 변수에 지정했다
NBA_FILE_PATH = 'drive/MyDrive/dataScience/data/NBA_player_of_the_week.csv'
nba_player_of_the_week_df = pd.read_csv(NBA_FILE_PATH)변수에 데이터프레임으로 잘 들어갔나 보면
nba_player_of_the_week_df.head()output
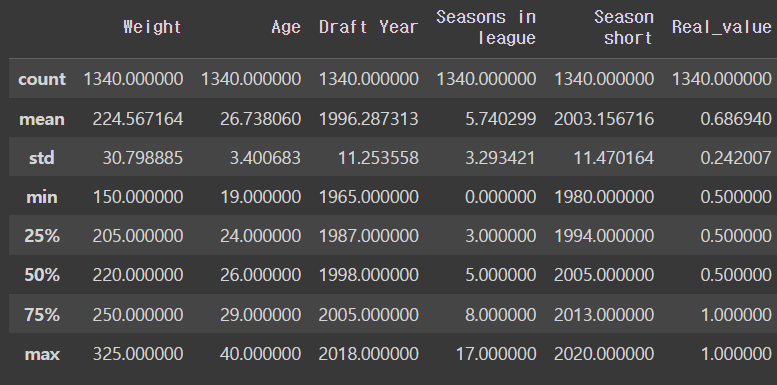
describe()는 각 열에 있는 데이터들에 대한 통계를 간단히 확인할 수 있당
nba_player_of_the_week_df.describe()output
원하는 입력변수만 선택해서 다시 데이터프레임을 생성한다
height_weight_age_df = nba_player_of_the_week_df[['Height CM','Weight KG','Age']]
height_weight_age_df.head()output
min-max scaler함수를 불러와서 변수에 넣고 .fit_transform()을 써서 주어진 데이터를 학습하고 변환시켜준다
scaler = preprocessing.MinMaxScaler()
normalized_data = scaler.fit_transform(height_weight_age_df)
normalized_dataoutput
array([[0.51851852, 0.32911392, 0.0952381 ],
[0.7037037 , 0.56962025, 0.28571429],
[0.48148148, 0.39240506, 0.19047619],
...,
[0.48148148, 0.37974684, 0.23809524],
[0.38888889, 0.21518987, 0.23809524],
[0.42592593, 0.27848101, 0.52380952]])ㄴ 보면 다 0과 1 사이의 값들임 !!
그 후에 이걸 데이터프레임에 넣는다
normalized_df = pd.DataFrame(normalized_data,columns = ['Height','Weight','Age'])describe()를 사용해서 보면
normalized_df.describe()output
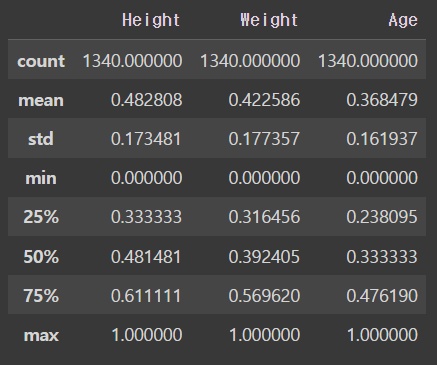
잘 들어가진 것을 볼 수 잇다
1.4 Feature Scaling과 경사 하강법
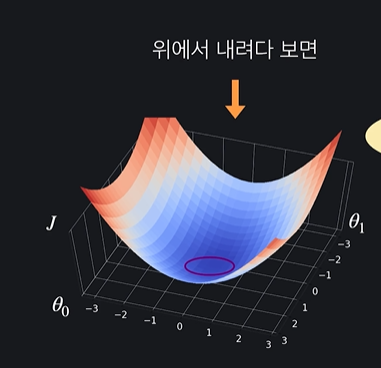
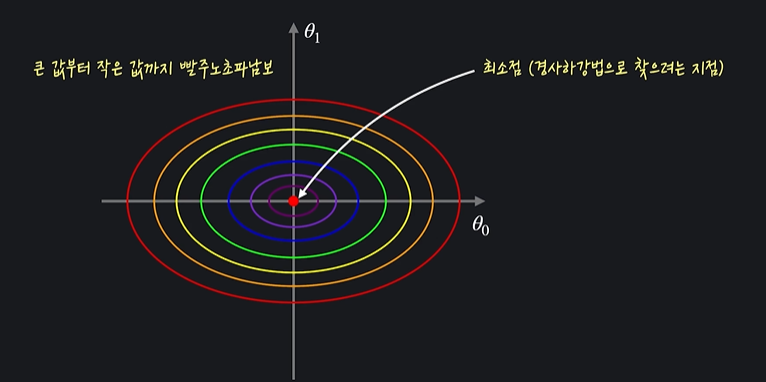
그래프를 이렇게 2차원으로 나타내면 좋은점이 가장 가파른 방향이 등고선과 수직인 방향이라는 것이다 !!
ex) 선형 회귀를 이용해서 사람들의 연봉을 가지고 나이를 예측하기
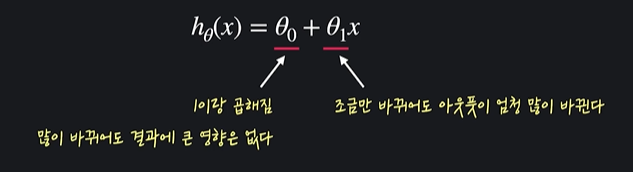
아웃풋이 많이 바뀐다는 것 = 손실 함수에도 큰 영향을 준다는 것
그래프로 나타내기
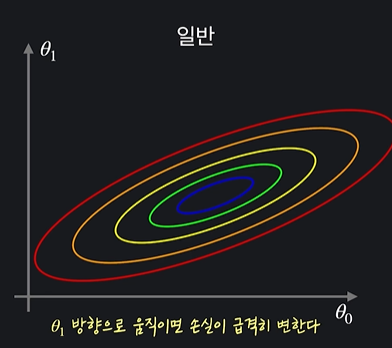
feature scaling을 해서 0과 1사이의 값으로 바꿨다고 하면
첫번째 그래프에서 경사 하강을 한다고 하면
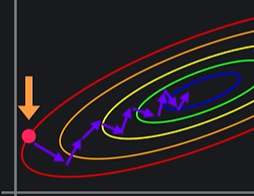
이렇게 지그재그 형태가 됨
두번째 그래프에서 경사 하강을 한다고 함녀
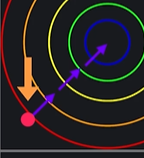
featuer scaling을 해줘서 훨씬 더 빨리 최소점을 찾을 수 있다
1.5 Feature Scaling : 표준화(Standardization) 노트
표준화를 알기 위해서는 조금의 통계 지식이 필요하다
평균(mean)과 표준 편차(standard deviation)
데이터의 평균은
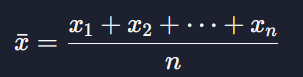
이렇게 모든 x값들을 더해주고 데이터의 개수 n으로 나눠주는 것이다
표준편차는
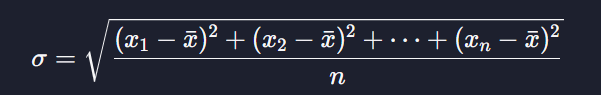
데이터와 평균에 대한 평균 제곱 오차를 구한 후 루트를 씌워서 구할 수 있다
ex)

10명의 키가 있다고 할 때
평균은

표준편차는

여기에 제곱근을 구하면
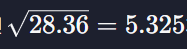
라는 값이 나온다
표준화 (standardization)
표준화 공식은
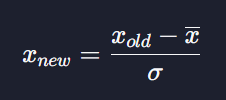
여기서 Xnew 는 표준화 한 데이터, Xold는 표준화하기 전 데이터 x-는 평균 O-는 표준편차이다
모든 데이터에서 평균값을 빼주고 이걸 표준편차로 나눠주면
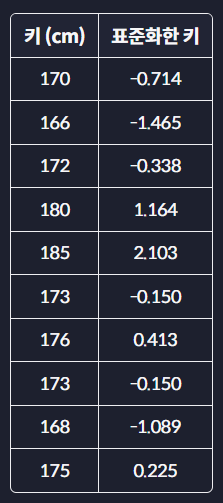
이렇게 바뀐다
표준화를 하면 항상 새로운 데이터의 평균은 0, 표준 편차는 1이 된다
scikit-learn으로 standardization 하기
from sklearn import preprocessing
import pandas as pd
import numpy as np
NBA_FILE_PATH = '../datasets/NBA_player_of_the_week.csv'
# 소수점 5번째 자리까지만 출력되도록 설정
pd.set_option('display.float_format', lambda x: '%.5f' % x)
nba_player_of_the_week_df = pd.read_csv(NBA_FILE_PATH)
# 데이터를 standardize 함
scaler = preprocessing.StandardScaler()
standardized_data = scaler.fit_transform(height_weight_age_df)
standardized_df = pd.DataFrame(standardized_data, columns=['Height', 'Weight', 'Age'])
standardized_df.describe()output
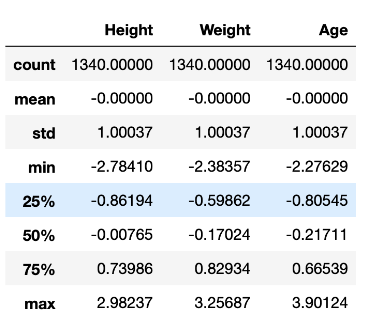
모든 열이 평균은 0, 그리고 표준 편차는 1을 갖도록 제대로 Standardize 된 것을 확인가능 !!
1.6 (실습) Feature Scaling 퀴즈


1.7 (실습) Normalization 직접 해보기
이번 챕터에서는 데이터를 Feature Scaling 하는 두 가지 방법, Normalization, Standardization에 대해서 배웠어요. sklearn 라이브러리를 사용해서 데이터에 Normalization 하는 방법도 봤습니다.
이번 과제에서는 배운 내용을 바탕으로 직접 데이터 Normalization을 구현해 보겠습니다.
필요한 도구 import
from sklearn import preprocessing
import pandas as pd데이터 파일 경로 정의 & 출력 옵션 설정
PATIENT_FILE_PATH = './datasets/liver_patient_data.csv'
pd.set_option('display.float_format', lambda x: '%.5f' % x)데이터가 저장돼 있는 파일 경로를 변수에 저장하고, 소수점 몇 자리까지 출력할 건지 설정할게요. (내용을 소수점 5자리까지 출력합니다.)
# 데이터 DataFrame으로 받아오기
liver_patients_df = pd.read_csv(PATIENT_FILE_PATH)pandas 라이브러리의 read_csv() 메소드를 사용해서 데이터를 pandas dataframe으로 받아 옵니다.
이 데이터 셋에 어떤 내용이 있는지 열 정보를 통해서 살펴볼게요.
lliver_patients_df.columns
저희가 사용하는 데이터는 간 질환 환자 데이터입니다. 살펴보면 'Dataset' 열은 환자가 간 질환이 있는지 없는지를 나타내는 목표 변수고요, 나머지 열들은 입력 변수들입니다. 나이, 성별, 그리고 다양한 건강 관련 수치 데이터가 있습니다.
이번 과제에서는 preprocessing 모듈의 MinMaxScaler을 사용해서 아래 열들을 Normalize해 보겠습니다.
- 'Total_Bilirubin'
- 'Direct_Bilirubin'
- 'Alkaline_Phosphotase'
- 'Alamine_Aminotransferase’
결괏값을 변수normalized_df에 새로운 pandas DataFrame으로 저장해 주세요.
code
# 필요한 도구 import
from sklearn import preprocessing
import pandas as pd
PATIENT_FILE_PATH = './datasets/liver_patient_data.csv'
pd.set_option('display.float_format', lambda x: '%.5f' % x)
# 데이터 파일을 pandas dataframe으로 가지고 온다
liver_patients_df = pd.read_csv(PATIENT_FILE_PATH)
# Normalization할 열 이름들
features_to_normalize = ['Total_Bilirubin','Direct_Bilirubin', 'Alkaline_Phosphotase', 'Alamine_Aminotransferase']
df = liver_patients_df[features_to_normalize]
# scaler 사용해서 원하는 데이터를 normalize한다
scaler = preprocessing.MinMaxScaler()
normalized_data = scaler.fit_transform(df)
# normalize한 데이터와 열 이름 리스트를 사용해서 새 dataframe 하나 만들기
normalized_df = pd.DataFrame(normalized_data, columns = features_to_normalize)
# 테스트 코드
normalized_df.describe()1.8 One-hot Encoding
머신 러닝에서 사용하는 데이터는 수치형 데이터와 범주형 데이터로 나눠진다
보통 입력변수가 수치형 데이터여야함. 근데 범주형 데이터라면?
-> 수치형 데이터로 바꿔야한다 !!
ex)
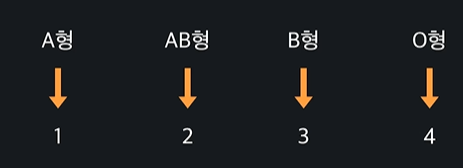
이렇게 되면 혈액형이 숫자로 변하기 때문에 수치형 데이터가 되는데 하지만 이 예시는 혈액형에 원하지 않는 크고 작다라는 개념이 생겨서 좋지 않다 !
범주형 데이터를 수치형 데이터로 바꿀 때 One-hot Encoding을 사용한당
ㄴ 이거는 각 카테고리를 새로운 열로 바꿔주는 방법이다
ex)
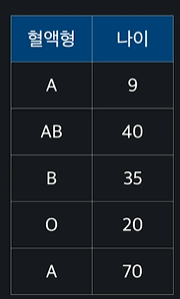
이 네 카테고리(A,B,O,AB)를 열로 설정해준다
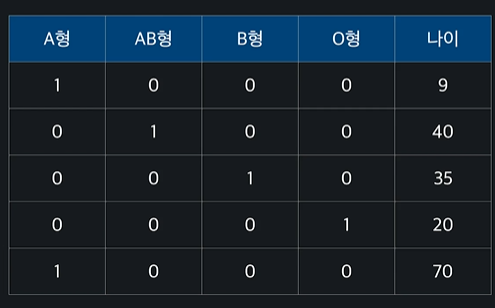
이렇게 ~~
=> 범주형 데이터에 엉뚱한 관계를 만들지 않으면서 수치형 데이터로 바꿔줄 수 있는 방법이다 ~~
1.9 Pandas로 One-hot Encoding 해보기
pandas로 해보자 !!
pandas 임포트 하고 파일 경로를 변수에 넣어준다
import pandas as pd
TITANIC_FILE_PATH = 'drive/MyDrive/dataScience/data/titanic.csv'csv파일을 읽어주자
titanic_df = pd.read_csv(TITANIC_FILE_PATH)
titanic_dfoutput
one-hot encoding을 하고자 하는 열만 변수에 담아준다
titanic_sex_embarked = titanic_df[['Sex','Embarked']]확인하기
titanic_sex_embarked.head()output
pandas에서 one-hot encoding 하는 방법 !!
바로바로 pd.get_dummies()를 쓰면 된당 ~~
one_hot_encoded_df = pd.get_dummies(titanic_sex_embarked)확인해보면
one_hot_encoded_df.head()output
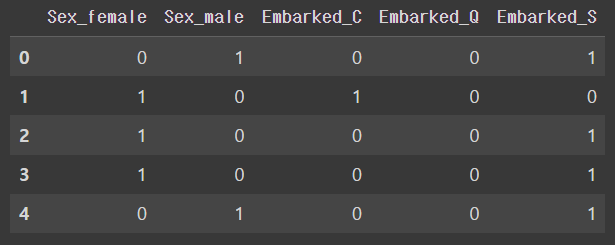
이렇게 잘 변환 되어있는 것을 볼 수 있다 ~~
이렇게 원하는 열을 변수 지정해서 이러쿵저러쿵 하는거 말고
전체 데이터들에서 원하는 열들만 one-hot encoding 하는 방법도 있다
ㄴ pd.get_dummies(data = ~~, columns = [~~]) 하는 방법이다
one_hot_encoded_df = pd.get_dummies(data = titanic_df, columns = ['Sex','Embarked'])
one_hot_encoded_df.head()output
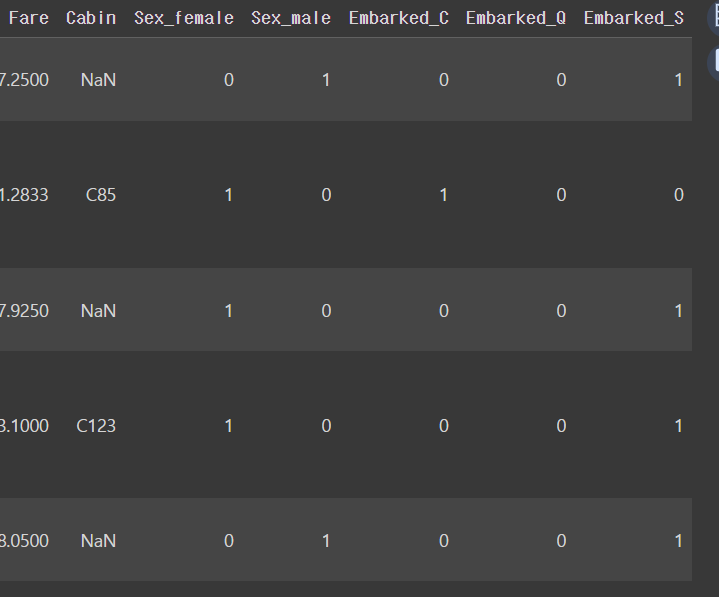
이렇게 손쉽게 변환할 수 있땅
1.10 One-hot Encoding 직접 해보기
이번 과제에서는 성별 데이터를 사용할 건데요. pandas 라이브러리의 read_csv() 메소드를 써서 사용할 데이터를 pandas dataframe으로 받아 옵니다.
데이터를 살펴보면 각 행은 한 명의 사람을 나타냅니다. 'Gender' 열을 살펴보면 성별 데이터가 있고요, 나머지 열들은 각 사람이 가장 좋아하는 색, 음악 장르, 주류, 음료가 저장돼 있습니다. 일단 목표 변수로 사용할 성별 열을 제외한 새로운 dataframe을 만들어 줄게요.
이번 과제에서 저희는 입력 변수 전체를 One-hot Encoding 하고 싶은데요. pandas 라이브러리의 get_dummies() 메소드를 사용해서 주어진 입력 변수 데이터 전체 열을 One-hot Encoding 해 보세요. (One-hot Encoding 한 데이터는 변수 X에 저장하세요!)
code
import pandas as pd
GENDER_FILE_PATH = './datasets/gender.csv'
gender_df = pd.read_csv(GENDER_FILE_PATH)
input_data = gender_df.drop(['Gender'], axis=1)
X = pd.get_dummies(input_data)
# 테스트 코드
X.head()