🤗 소개
Denoising Diffusion Probabilistic Models(DDPM) (Sohl-Dickstein et al., 2015; Ho et al., 2020) 은 diffusion 모델링의 핵심을 이루는 기초적 모델이다. 개념적으로 DDPM은 VAE, HVAE와 마찬가지로 변분적(variational) 틀 안에서 작동한다. 그러나 DDPM은 이전 모델들이 직면했던 여러 어려움을 해결하는 영리한 변형을 도입한다.
이번 글에서는 VAE 이후로 generative modeling에 큰 발자취를 남긴 DDPM 에 대해 자세히 알아보고자 한다.
🌷 DDPM 파헤치기
DDPM의 핵심에는 두 개의 구분되는 확률적 과정 이 존재한다.
▶️ Forward Pass (고정된 인코더)
이 과정은 전이 커널(transition kernel) p ( x i ∣ x i − 1 ) p(\mathbf{x}_i\mid\mathbf{x}_{i-1}) p ( x i ∣ x i − 1 )
데이터는 결국 등방성(isotropic) Gaussian 분포 로 수혐하며 사실상 순수한 노이즈 N ( 0 , 1 ) \mathcal{N}(\mathbf{0},\mathbf{1}) N ( 0 , 1 ) 학습되지 않는다 .
◀️ Reverse Denoising Process (학습 가능한 디코더)
여기서는 신경망이 parameterized된 분포 p ϕ ( x i − 1 ∣ x i ) p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i) p ϕ ( x i − 1 ∣ x i ) 역으로 되돌리는 법 을 학습한다. 순수한 노이즈에서 시작해 이 과정을 반복하면 현실적인 샘플을 생성할 수 있다.
중요한 점은, 각 개별 복원 단계는 VAE처럼 전체 샘플을 한 번에 생성하는 것보다 훨씬 다루기 쉬운 문제라는 것이다.
인코더를 고정하고 점진적인 생성 경로에 학습을 집중함으로써, DDPM은 놀라울 정도의 안정성과 표현력 을 달성한다.
1️⃣ Forward 과정 – 고정된 인코더
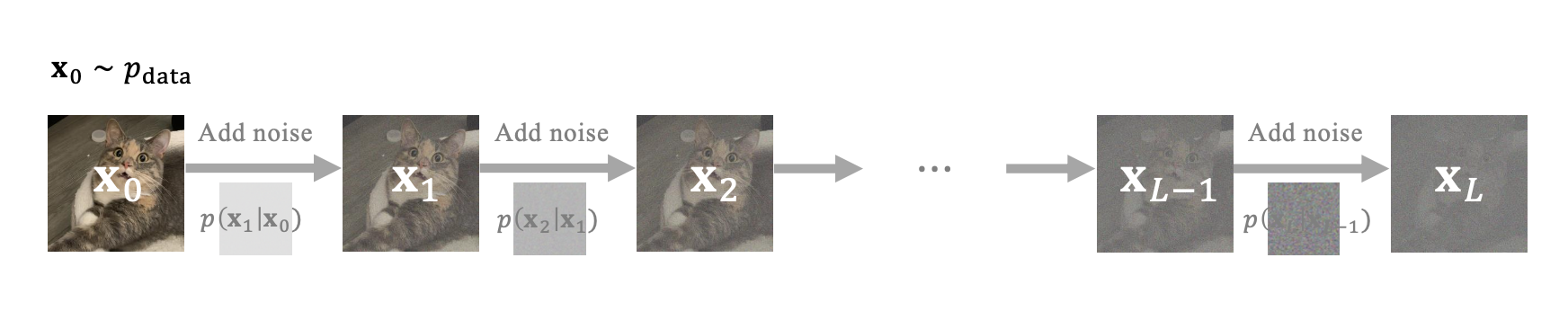
DDPM에서 forward 과정은 학습되지 않는 고정된 연산 으로, 인코더(encoder) 역할을 수행한다. 이 과정은 여러 단계에 걸쳐 원본 데이터에 노이즈를 점진적으로 추가하여, 최종적으로 단순한 prior 분포 p prior : = N ( 0 , 1 ) p_\text{prior}:=\mathcal{N}(\mathbf{0},\mathbf{1}) p prior : = N ( 0 , 1 )
이 과정은 밑의 그림에 시각적으로 잘 나타나있다.
이제부터 이러한 단계별 열화(degradation) 과정을 형식적으로 기술해보자.
🛠️ Fixed Gaussian Transitions
Forward 과정의 각 단계는 다음과 같은 고정된 Gaussian transition kernel 에 의해 정의된다.
p ( x i ∣ x i − 1 ) : = N ( x i ; 1 − β i 2 x i − 1 , β i 2 I ) p(\mathbf{x}_i\mid\mathbf{x}_{i-1}):=\mathcal{N}(\mathbf{x}_i;\sqrt{1-\beta_i^2}\mathbf{x}_{i-1},\beta_i^2\mathbf{I}) p ( x i ∣ x i − 1 ) : = N ( x i ; 1 − β i 2 x i − 1 , β i 2 I ) 이때 과정은 x 0 \mathbf{x}_0 x 0 x 0 \mathbf{x}_0 x 0 p data p_\text{data} p data
노이즈 스케쥴(noise schedule) { β i } i = 1 L \{\beta_i\}_{i=1}^L { β i } i = 1 L 단조 증가(monotonic increase) 하는 스케쥴이며, 각 β i ∈ ( 0 , 1 ) \beta_i\in(0,1) β i ∈ ( 0 , 1 ) i i i
편의상 α i : = 1 − β i 2 \alpha_i:=\sqrt{1-\beta_i^2} α i : = 1 − β i 2 x i \mathbf{x}_i x i
x i = α i x i − 1 + β i ϵ i , ϵ i ∼ N ( 0 , 1 ) \mathbf{x}_i=\alpha_i\mathbf{x}_{i-1}+\beta_i\epsilon_i,\quad\epsilon_i\sim\mathcal{N}(\mathbf{0},\mathbf{1}) x i = α i x i − 1 + β i ϵ i , ϵ i ∼ N ( 0 , 1 ) 즉, 각 단계 i i i x i − 1 \mathbf{x}_{i-1} x i − 1 α i \alpha_i α i β i \beta_i β i
Perturbation Kernel & Prior Distribution
위 transition kernel을 반복적으로 적용하면, 원본 데이터 x 0 \mathbf{x}_0 x 0 i i i x i \mathbf{x}_i x i closed-form의 분포 를 갖는다.
p i ( x i ∣ x 0 ) = N ( x i ; α ˉ i x 0 , ( 1 − α ˉ i 2 ) I ) p_i(\mathbf{x}_i\mid\mathbf{x}_0)=\mathcal{N}\left(\mathbf{x}_i;\bar{\alpha}_i\mathbf{x}_0,(1-\bar{\alpha}_i^2)\mathbf{I}\right) p i ( x i ∣ x 0 ) = N ( x i ; α ˉ i x 0 , ( 1 − α ˉ i 2 ) I ) 여기서 α ˉ i : = ∏ k = 1 i α k \bar{\alpha}_i:=\prod_{k=1}^i\alpha_k α ˉ i : = ∏ k = 1 i α k
혹은 이 분포는 다음의 단 한 번의 샘플링 공식 으로부터도 동일하게 얻을 수 있다.
x i = α ˉ i x 0 + 1 − α ˉ i 2 ϵ , ϵ ∼ N ( 0 , 1 ) \mathbf{x}_i=\bar{\alpha}_i\mathbf{x}_0+\sqrt{1-\bar{\alpha}_i^2}\epsilon,\quad\epsilon\sim\mathcal{N}(\mathbf{0},\mathbf{1}) x i = α ˉ i x 0 + 1 − α ˉ i 2 ϵ , ϵ ∼ N ( 0 , 1 ) 이 표현은 DDPM의 forward noising이 누적된(scale-composed) 선형 변환 + + + 형태로 매우 단순하게 정리됨을 보여준다.
추가적으로, 위에서 언급했던 것 처럼 증가하는 노이즈 스케쥴(noise schedule) { β i } i = 1 L \{\beta_i\}_{i=1}^L { β i } i = 1 L 주변 분포(marginal distribution) 는 다음과 같이 수렴하게 된다.
p L ( x L ∣ x 0 ) → N ( 0 , I ) , as L → ∞ p_L(\mathbf{x}_L\mid\mathbf{x}_0)\rightarrow\mathcal{N}(\mathbf{0},\mathbf{I}),\quad\text{as}~L\rightarrow\infty p L ( x L ∣ x 0 ) → N ( 0 , I ) , as L → ∞ 이 사실은 prior 분포를 p prior : = N ( 0 , I ) p_\text{prior}:=\mathcal{N}(\mathbf{0},\mathbf{I}) p prior : = N ( 0 , I ) x 0 \mathbf{x}_0 x 0
2️⃣ 역방향 Denoising 과정 – 학습 가능한 디코더
DDPM의 핵심은 forward diffusion 과정이 만들어낸 통제된 degradation 과정을 역으로 되돌릴 수 있는 능력 에 있다. 구조가 없는 순수한 노이즈 x L ∼ p prior \mathbf{x}_L\sim p_\text{prior} x L ∼ p prior 점진적으로 denoise 하여 단계적으로 정돈된(coherent) 의미 있는 데이터 샘플을 만들어내는 것이다.
이러한 reverse 생성 과정은 아래 그림에서도 보이듯 Markov 연쇄를 따라 진행된다.
이로부터 비롯되는 DDPM을 발전시키는 데 있어 근본적인 핵심 질문 은 다음과 같다.
x i ∼ p i ( x i ) \mathbf{x}_i\sim p_i(\mathbf{x}_i) x i ∼ p i ( x i ) p ( x i − 1 ∣ x i ) p(\mathbf{x}_{i-1}\mid\mathbf{x}_i) p ( x i − 1 ∣ x i )
이 질문을 품은 채 이제 본격적으로 DDPM에 대해 깊게 파고들 예정인데, 원래 DDPM 논문처럼 바로 복잡한 ELBO의 수학적 유도부터 들어가진 않을 것이다. 대신 조건부 확률 을 활용해 tractable한 형태로 만드는 직관적인 관점에서 학습의 목적 함수를 살펴보고자 한다.
🎯 모델링과 학습 목표
생성 과정을 가능하게 하려면 알 수 없는 실제 reverse-transition kernel p ( x i − 1 ∣ x i ) p(\mathbf{x}_{i-1}\mid\mathbf{x}_i) p ( x i − 1 ∣ x i )
이를 위해 학습 가능한 매개변수 모델 p ϕ ( x i − 1 ∣ x i ) p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i) p ϕ ( x i − 1 ∣ x i ) 기댓값 KL 발산 을 최소화하도록 학습시킨다.
E p i ( x i ) [ D KL ( p ( x i − 1 ∣ x i ) ∣ ∣ p ϕ ( x i − 1 ∣ x i ) ) ] \mathbb{E}_{p_i(\mathbf{x}_i)}\left[\mathcal{D}_\text{KL}\left(p(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\mid\mid p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\right)\right] E p i ( x i ) [ D KL ( p ( x i − 1 ∣ x i ) ∣ ∣ p ϕ ( x i − 1 ∣ x i ) ) ] 하지만 목표 분포 p ( x i − 1 ∣ x i ) p(\mathbf{x}_{i-1}\mid\mathbf{x}_i) p ( x i − 1 ∣ x i ) 매우 어렵다 .
Bayes' Theorem에 따르면 다음을 대신 계산해야 한다.
p ( x i − 1 ∣ x i ) = p ( x i ∣ x i − 1 ) p i − 1 ( x i − 1 ) p i ( x i ) ⏟ intractable p(\mathbf{x}_{i-1}\mid\mathbf{x}_i)=p(\mathbf{x}_i\mid\mathbf{x}_{i-1})\underbrace{\frac{p_{i-1}(\mathbf{x}_{i-1})}{p_i(\mathbf{x}_i)}}_\text{intractable} p ( x i − 1 ∣ x i ) = p ( x i ∣ x i − 1 ) intractable p i ( x i ) p i − 1 ( x i − 1 ) 주변 분포 p i − 1 ( x i − 1 ) p_{i-1}(\mathbf{x}_{i-1}) p i − 1 ( x i − 1 ) p i ( x i ) p_i(\mathbf{x}_i) p i ( x i ) p data ( x ) p_\text{data}(\mathbf{x}) p data ( x ) p i − 1 p_{i-1} p i − 1
p i ( x i ) = ∫ p i ( x i ∣ x 0 ) p data ( x 0 ) d x 0 p_i(\mathbf{x}_i)=\int p_i(\mathbf{x}_i\mid\mathbf{x}_0)p_\text{data}(\mathbf{x}_0)d\mathbf{x}_0 p i ( x i ) = ∫ p i ( x i ∣ x 0 ) p data ( x 0 ) d x 0 그러나 p data p_\text{data} p data 해석적인(closed-form) 해가 존재하지 않는다 . 최대한 샘플을 통해 근사할 수는 있지만, 정확한 density는 실제로 계산할 수 없다.
📐 조건부 확률을 통한 Intractability 극복
DDPM의 핵심 통찰 중 하나는, 이 난해한 역전이 커널을 깨끗한 데이터 샘플 x \mathbf{x} x 조건부(conditional) 바꿈으로써 해결할 수 있다는 점이다. 이 미묘하지만 강력한 조작을 통해 본래 intractable 하던 커널을 수학적으로 다룰 수 있는 형태 로 바꿀 수 있다.
p ( x i − 1 ∣ x i , x ) = p ( x ∣ x i − 1 ) p ( x i − 1 ∣ x ) p ( x i ∣ x ) p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x})=p(\mathbf{x}\mid\mathbf{x}_{i-1})\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x})}{p(\mathbf{x}_i\mid\mathbf{x})} p ( x i − 1 ∣ x i , x ) = p ( x ∣ x i − 1 ) p ( x i ∣ x ) p ( x i − 1 ∣ x ) 이 식이 tractable해지는 이유는 다음 두 가지 forward 과정의 핵심 성질 덕분이다.
마르코프 성질 (Markov Property)
p ( x i ∣ x i − 1 , x ) = p ( x i ∣ x i − 1 ) p(\mathbf{x}_i\mid\mathbf{x}_{i-1},\mathbf{x})=p(\mathbf{x}_i\mid\mathbf{x}_{i-1}) p ( x i ∣ x i − 1 , x ) = p ( x i ∣ x i − 1 ) 가 성립한다. 즉, 깨끗한 데이터 x \mathbf{x} x 변하지 않는다 .
모든 분포가 Gaussian p ( x i − 1 ∣ x i , x ) p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}) p ( x i − 1 ∣ x i , x ) Gaussian 형태를 유지 하며, closed-form인 해를 갖는다.
이러한 조건부 트릭 덕분에 원래는 풀 수 없던 marginal KL 발산을 피하고, 동일한 목적을 달성하면서도 tractable한 학습 목표로 변환할 수 있다.
정리 2.2.1 – Marginal KL 최소화와 조건부 KL 최소화의 동치
E p i ( x i ) [ D KL ( p ( x i − 1 ∣ x i ) ∥ p ϕ ( x i − 1 ∣ x i ) ) ] = E p data ( x ) E p ( x i ∣ x ) [ D KL ( p ( x i − 1 ∣ x i , x ) ∥ p ϕ ( x i − 1 ∣ x i ) ) ] + C \begin{aligned} &\mathbb{E}_{p_i(\mathbf{x}_i)}\left[\mathcal{D}_\text{KL}\left(p(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\|p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\right)\right] \\ =&\mathbb{E}_{p_\text{data}(\mathbf{x})}\mathbb{E}_{p(\mathbf{x}_i\mid\mathbf{x})}\left[\mathcal{D}_\text{KL}\left(p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x})\|p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\right)\right]+C \\ \end{aligned} = E p i ( x i ) [ D KL ( p ( x i − 1 ∣ x i ) ∥ p ϕ ( x i − 1 ∣ x i ) ) ] E p data ( x ) E p ( x i ∣ x ) [ D KL ( p ( x i − 1 ∣ x i , x ) ∥ p ϕ ( x i − 1 ∣ x i ) ) ] + C 여기서 C C C ϕ \phi ϕ
p ∗ ( x i − 1 ∣ x ) = E p ( x ∣ x i ) [ p ( x i − 1 ∣ x i , x ) ] = p ( x i − 1 ∣ x ) , x i ∼ p i p^\ast(\mathbf{x}_{i-1}\mid\mathbf{x})=\mathbb{E}_{p(\mathbf{x}\mid\mathbf{x}_i)}\left[p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x})\right]=p(\mathbf{x}_{i-1}\mid\mathbf{x}),\quad\mathbf{x}_i\sim p_i p ∗ ( x i − 1 ∣ x ) = E p ( x ∣ x i ) [ p ( x i − 1 ∣ x i , x ) ] = p ( x i − 1 ∣ x ) , x i ∼ p i
📝 정리 2.2.1의 증명
위의 동치를 수학적으로 차근차근 증명해보자. 우선 위 등식의 좌변에 있는 기댓값에 x 0 \mathbf{x}_0 x 0
E p ( x 0 , x i ) [ D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ϕ ( x i − 1 ∣ x i ) ) ] = ∬ p ( x 0 , x i ) D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ϕ ( x i − 1 ∣ x i ) ) d x 0 d x i \begin{aligned} &\mathbb{E}_{p(\mathbf{x}_0,\mathbf{x}_i)}\left[\mathcal{D}_\text{KL}\left(p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)\|p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\right)\right] \\ =&\iint p(\mathbf{x}_0,\mathbf{x}_i)\mathcal{D}_\text{KL}\left(p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)\|p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\right)d\mathbf{x}_0d\mathbf{x}_i \\ \end{aligned} = E p ( x 0 , x i ) [ D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ϕ ( x i − 1 ∣ x i ) ) ] ∬ p ( x 0 , x i ) D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ϕ ( x i − 1 ∣ x i ) ) d x 0 d x i KL 발산의 정의에 의해,
D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ϕ ( x i − 1 ∣ x i ) ) = ∫ p ( x i − 1 ∣ x i , x 0 ) log p ( x i − 1 ∣ x i , x 0 ) p ϕ ( x i − 1 ∣ x i ) d x i − 1 \mathcal{D}_\text{KL}\left(p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)\|p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\right)=\int p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)\log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)}{p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}d\mathbf{x}_{i-1} D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ϕ ( x i − 1 ∣ x i ) ) = ∫ p ( x i − 1 ∣ x i , x 0 ) log p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i , x 0 ) d x i − 1 이를 위 기댓값 전개식에 대입하면 다음을 얻을 수 있다.
∭ p ( x 0 , x i ) p ( x i − 1 ∣ x i , x 0 ) log p ( x i − 1 ∣ x i , x 0 ) p ϕ ( x i − 1 ∣ x i ) d x i − 1 d x 0 d x i \iiint p(\mathbf{x}_0,\mathbf{x}_i)p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)\log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)}{p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}d\mathbf{x}_{i-1}d\mathbf{x}_0d\mathbf{x}_i ∭ p ( x 0 , x i ) p ( x i − 1 ∣ x i , x 0 ) log p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i , x 0 ) d x i − 1 d x 0 d x i 확률의 연쇄법칙 p ( x 0 , x i ) = p ( x i ) p ( x 0 ∣ x i ) p(\mathbf{x}_0,\mathbf{x}_i)=p(\mathbf{x}_i)p(\mathbf{x}_0\mid\mathbf{x}_i) p ( x 0 , x i ) = p ( x i ) p ( x 0 ∣ x i )
∫ p ( x i ) ∫ p ( x 0 ∣ x i ) ∫ p ( x i − 1 ∣ x i , x 0 ) log p ( x i − 1 ∣ x i , x 0 ) p ϕ ( x i − 1 ∣ x i ) d x i − 1 d x 0 d x i \int p(\mathbf{x}_i)\int p(\mathbf{x}_0\mid\mathbf{x}_i)\int p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)\log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)}{p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}d\mathbf{x}_{i-1}d\mathbf{x}_0d\mathbf{x}_i ∫ p ( x i ) ∫ p ( x 0 ∣ x i ) ∫ p ( x i − 1 ∣ x i , x 0 ) log p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i , x 0 ) d x i − 1 d x 0 d x i 즉, 아래와 같이 중첩(nested) 기댓값 으로 정리할 수 있다.
E p ( x i ) [ E p ( x 0 ∣ x i ) [ E p ( x i − 1 ∣ x i , x 0 ) [ log p ( x i − 1 ∣ x i , x 0 ) p ϕ ( x i − 1 ∣ x i ) ] ] ] \mathbb{E}_{p(\mathbf{x}_i)}\left[\mathbb{E}_{p(\mathbf{x}_0\mid\mathbf{x}_i)}\left[\mathbb{E}_{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)}\left[\log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)}{p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}\right]\right]\right] E p ( x i ) [ E p ( x 0 ∣ x i ) [ E p ( x i − 1 ∣ x i , x 0 ) [ log p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i , x 0 ) ] ] ] 그 다음으로, 로그의 성질을 이용해 로그항을 다음과 같이 조작해보자.
log p ( x i − 1 ∣ x i , x 0 ) p ϕ ( x i − 1 ∣ x i ) = log p ( x i − 1 ∣ x i , x 0 ) p ( x i − 1 ∣ x i ) + log p ( x i − 1 ∣ x i ) p ϕ ( x i − 1 ∣ x i ) \log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)}{p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}=\log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)}{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}+\log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}{p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)} log p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i , x 0 ) = log p ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i , x 0 ) + log p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i ) 여기서 p ( x i − 1 ∣ x i ) p(\mathbf{x}_{i-1}\mid\mathbf{x}_i) p ( x i − 1 ∣ x i )
이를 위의 중첩 기댓값에 적용하면,
E p ( x i ) [ E p ( x 0 ∣ x i ) [ E p ( x i − 1 ∣ x i , x 0 ) [ log p ( x i − 1 ∣ x i , x 0 ) p ( x i − 1 ∣ x i ) ] ] ] + E p ( x i ) [ E p ( x 0 ∣ x i ) [ E p ( x i − 1 ∣ x i , x 0 ) [ log p ( x i − 1 ∣ x i ) p ϕ ( x i − 1 ∣ x i ) ] ] ] \begin{aligned} &\mathbb{E}_{p(\mathbf{x}_i)}\left[\mathbb{E}_{p(\mathbf{x}_0\mid\mathbf{x}_i)}\left[\mathbb{E}_{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)}\left[\log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)}{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}\right]\right]\right] \\ &+\mathbb{E}_{p(\mathbf{x}_i)}\left[\mathbb{E}_{p(\mathbf{x}_0\mid\mathbf{x}_i)}\left[\mathbb{E}_{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)}\left[\log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}{p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}\right]\right]\right] \\ \end{aligned} E p ( x i ) [ E p ( x 0 ∣ x i ) [ E p ( x i − 1 ∣ x i , x 0 ) [ log p ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i , x 0 ) ] ] ] + E p ( x i ) [ E p ( x 0 ∣ x i ) [ E p ( x i − 1 ∣ x i , x 0 ) [ log p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i ) ] ] ] 여기서 두 번째 항은 x 0 \mathbf{x}_0 x 0 전체 확률의 법칙(law of total probability) 에 의해 다음과 같이 정리된다.
E p ( x 0 ∣ x i ) [ E p ( x i − 1 ∣ x i , x 0 ) [ log p ( x i − 1 ∣ x i ) p ϕ ( x i − 1 ∣ x i ) ] ] = E p ( x i − 1 ∣ x i ) [ log p ( x i − 1 ∣ x i ) p ϕ ( x i − 1 ∣ x i ) ] \mathbb{E}_{p(\mathbf{x}_0\mid\mathbf{x}_i)}\left[\mathbb{E}_{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)}\left[\log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}{p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}\right]\right]=\mathbb{E}_{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}\left[\log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}{p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}\right] E p ( x 0 ∣ x i ) [ E p ( x i − 1 ∣ x i , x 0 ) [ log p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i ) ] ] = E p ( x i − 1 ∣ x i ) [ log p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i ) ] 마찬가지로, 중첩 기댓값의 첫 번째 항은 KL 발산에 대한 기댓값으로 정리할 수 있다.
E p ( x 0 ∣ x i ) [ D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ( x i − 1 ∣ x i ) ) ] \mathbb{E}_{p(\mathbf{x}_0\mid\mathbf{x}_i)}\left[\mathcal{D}_\text{KL}\left(p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)\|p(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\right)\right] E p ( x 0 ∣ x i ) [ D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ( x i − 1 ∣ x i ) ) ] 이를 종합하면 정리 2.2.1 의 최종적인 등식을 얻을 수 있다.
E p ( x 0 , x i ) [ D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ϕ ( x i − 1 ∣ x i ) ) ] = E p ( x i ) [ E p ( x 0 ∣ x i ) [ D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ( x i − 1 ∣ x i ) ) ] ] + E p ( x i ) [ D KL ( p ( x i − 1 ∣ x i ) ∥ p ϕ ( x i − 1 ∣ x i ) ) ] − − − − − − − − − − − − − − − − − − − − − ■ \begin{aligned} &\mathbb{E}_{p(\mathbf{x}_0,\mathbf{x}_i)}\left[\mathcal{D}_\text{KL}\left(p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)\|p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\right)\right] \\ =&\mathbb{E}_{p(\mathbf{x}_i)}\left[\mathbb{E}_{p(\mathbf{x}_0\mid\mathbf{x}_i)}\left[\mathcal{D}_\text{KL}\left(p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)\|p(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\right)\right]\right] \\ \quad&+\mathbb{E}_{p(\mathbf{x}_i)}\left[\mathcal{D}_\text{KL}\left(p(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\|p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\right)\right] \\ &\phantom{---------------------}\blacksquare \end{aligned} = E p ( x 0 , x i ) [ D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ϕ ( x i − 1 ∣ x i ) ) ] E p ( x i ) [ E p ( x 0 ∣ x i ) [ D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ( x i − 1 ∣ x i ) ) ] ] + E p ( x i ) [ D KL ( p ( x i − 1 ∣ x i ) ∥ p ϕ ( x i − 1 ∣ x i ) ) ] − − − − − − − − − − − − − − − − − − − − − ■ 이로써 Marginal KL과 조건부 KL이 사실상 같음을 증명하였다.
이러한 조건부화(conditioning) 를 통해 tractable한 목적 함수를 얻는 대안적 방식은 DDPM의 기초를 이루며, 이후 다루게 될 다른 강력한 diffusion 모델들과의 깊은 공통점을 드러낸다.
이 관점은 중요한 사실을 하나 알려준다. 주변(marginal) 분포들 사이의 KL 발산을 최소화하는 문제는 특정 조건부 분포들 사이의 KL 발산을 최소화하는 문제와 수학적으로 완전히 동일 하다.
특히 후자의 조건부 형태는 매우 유용한데, 그 이유는 핵심이 되는 조건부 분포 p ( x i − 1 ∣ x i , x ) p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}) p ( x i − 1 ∣ x i , x ) 간단한 closed-form 표현을 가지기 때문이다.
보조정리 2.2.2 – 역방향 조건부 전이 커널 (Reverse Conditional Transition Kernel) p ( x i − 1 ∣ x i , x ) p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}) p ( x i − 1 ∣ x i , x )
p ( x i − 1 ∣ x i , x ) = N ( x i − 1 ; μ ( x i , x , i ) , σ 2 ( i ) I ) p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x})=\mathcal{N}\left(\mathbf{x}_{i-1};\mu(\mathbf{x}_i,\mathbf{x},i),\sigma^2(i)\mathbf{I}\right) p ( x i − 1 ∣ x i , x ) = N ( x i − 1 ; μ ( x i , x , i ) , σ 2 ( i ) I ) 여기서
μ ( x i , x , i ) : = α ˉ i − 1 β i 2 1 − α ˉ i 2 x + ( 1 − α ˉ i − 1 2 ) α i 1 − α ˉ i 2 x i , σ 2 ( i ) : = 1 − α ˉ i − 1 2 1 − α ˉ i 2 β i 2 \mu(\mathbf{x}_i,\mathbf{x},i):=\frac{\bar{\alpha}_{i-1}\beta^2_i}{1-\bar{\alpha}_i^2}\mathbf{x}+\frac{(1-\bar{\alpha}^2_{i-1})\alpha_i}{1-\bar{\alpha}^2_i}\mathbf{x}_i,\quad\sigma^2(i):=\frac{1-\bar{\alpha}^2_{i-1}}{1-\bar{\alpha}^2_i}\beta^2_i μ ( x i , x , i ) : = 1 − α ˉ i 2 α ˉ i − 1 β i 2 x + 1 − α ˉ i 2 ( 1 − α ˉ i − 1 2 ) α i x i , σ 2 ( i ) : = 1 − α ˉ i 2 1 − α ˉ i − 1 2 β i 2
3️⃣ 역방향 전이 커널의 모델링
정리 2.2.1 의 gradient-level 등가성과 보조정리 2.2.2 에서 제시된 역방향 조건부 분포 p ( x i − 1 ∣ x i , x ) p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}) p ( x i − 1 ∣ x i , x ) p ϕ ( x i − 1 ∣ x i ) p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i) p ϕ ( x i − 1 ∣ x i ) Gaussian이라고 가정 하고 다음과 같이 parameterize 한다.
p ϕ ( x i − 1 ∣ x ) : = N ( x i − 1 ; μ ϕ ( x i , i ) , σ 2 ( i ) I ) p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}):=\mathcal{N}\left(\mathbf{x}_{i-1};\mu_\phi(\mathbf{x}_i,i),\sigma^2(i)\mathbf{I}\right) p ϕ ( x i − 1 ∣ x ) : = N ( x i − 1 ; μ ϕ ( x i , i ) , σ 2 ( i ) I ) 여기서 μ ϕ ( ⋅ , i ) : R D → R D \mu_\phi(\cdot,i):\mathbb{R}^D\rightarrow\mathbb{R}^D μ ϕ ( ⋅ , i ) : R D → R D learnable한 mean function 이며, σ 2 ( i ) > 0 \sigma^2(i)>0 σ 2 ( i ) > 0 보조정리 2.2.2 에서 정의된 고정된 분산 이다.
추가적으로, 모든 레이어의 분포를 일치 시키기 위해 시간 단계 i i i x 0 ∼ p data \mathbf{x}_0\sim p_\text{data} x 0 ∼ p data
L diffusion ( x 0 ; ϕ ) : = ∑ i = 1 L E p ( x i ∣ x 0 ) [ D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ϕ ( x i − 1 ∣ x i ) ) ] \mathcal{L}_\text{diffusion}(\mathbf{x}_0;\phi):=\sum_{i=1}^L\mathbb{E}_{p(\mathbf{x}_i\mid\mathbf{x}_0)}\left[\mathcal{D}_\text{KL}\left(p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)\|p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\right)\right] L diffusion ( x 0 ; ϕ ) : = i = 1 ∑ L E p ( x i ∣ x 0 ) [ D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ϕ ( x i − 1 ∣ x i ) ) ] Gaussian 형태의 두 분포와 위의 parameterization을 이용하면 이 목적함수는 closed-form의 형태 를 가지며 다음과 같이 단순화된다.
L diffusion ( x 0 ; ϕ ) = ∑ i = 1 L 1 2 σ 2 ( i ) ∥ μ ϕ ( x i , i ) − μ ( x i , x 0 , i ) ∥ 2 2 + C \mathcal{L}_\text{diffusion}(\mathbf{x}_0;\phi)=\sum_{i=1}^L\frac{1}{2\sigma^2(i)}\|\mu_\phi(\mathbf{x}_i,i)-\mu(\mathbf{x}_i,\mathbf{x}_0,i)\|^2_2+C L diffusion ( x 0 ; ϕ ) = i = 1 ∑ L 2 σ 2 ( i ) 1 ∥ μ ϕ ( x i , i ) − μ ( x i , x 0 , i ) ∥ 2 2 + C 이후, 데이터 분포에 대해 평균을 취하고, 최적화에 영향을 주지 않는 상수 C C C 최종 DDPM의 학습 목표 는 다음과 같다.
L DDPM ( ϕ ) : = ∑ i = 1 L 1 2 σ 2 ( i ) E x 0 E p ( x i ∣ x 0 ) [ ∥ μ ϕ ( x i , i ) − μ ( x i , x 0 , i ) ∥ 2 2 ] \mathcal{L}_\text{DDPM}(\phi):=\sum_{i=1}^L\frac{1}{2\sigma^2(i)}\mathbb{E}_{\mathbf{x}_0}\mathbb{E}_{p(\mathbf{x}_ i\mid\mathbf{x}_0)}\left[\|\mu_\phi(\mathbf{x}_i,i)-\mu(\mathbf{x}_i,\mathbf{x}_0,i)\|^2_2\right] L DDPM ( ϕ ) : = i = 1 ∑ L 2 σ 2 ( i ) 1 E x 0 E p ( x i ∣ x 0 ) [ ∥ μ ϕ ( x i , i ) − μ ( x i , x 0 , i ) ∥ 2 2 ] 여기서 x 0 ∼ p data \mathbf{x}_0\sim p_\text{data} x 0 ∼ p data
4️⃣ 예측과 손실 계산의 실용적인 접근
🫧 ϵ \epsilon ϵ
일반적인 DDPM 구현에서는 위의 mean prediction parameterization을 기반으로 한 원래 손실을 직접 학습하지 않는다 . 대신 동등한 재파라미터화(reparameterization)인, 흔히 ϵ \epsilon ϵ
DDPM의 정방향 과정에서, 노이즈 레벨 i i i x i ∼ p ( x i ∣ x ) \mathbf{x}_i\sim p(\mathbf{x}_i\mid\mathbf{x}) x i ∼ p ( x i ∣ x )
x i = α ˉ i x 0 + 1 − α ˉ i 2 ϵ , x 0 ∼ p data , ϵ ∼ N ( 0 , I ) \mathbf{x}_i=\bar{\alpha}_i\mathbf{x}_0+\sqrt{1-\bar{\alpha}^2_i}\epsilon,\quad\mathbf{x}_0\sim p_\text{data},\quad\epsilon\sim\mathcal{N}(\mathbf{0},\mathbf{I}) x i = α ˉ i x 0 + 1 − α ˉ i 2 ϵ , x 0 ∼ p data , ϵ ∼ N ( 0 , I ) 이 표현을 살용하면, 앞서 등장했던 역전이 평균 μ ( x i , x 0 , i ) \mu(\mathbf{x}_i,\mathbf{x}_0,i) μ ( x i , x 0 , i )
μ ( x i , x 0 , i ) = 1 α i ( x i − 1 − α i 2 1 − α ˉ i 2 ϵ ) \mu(\mathbf{x}_i,\mathbf{x}_0,i)=\frac{1}{\alpha_i}\left(\mathbf{x}_i-\frac{1-\alpha_i^2}{\sqrt{1-\bar{\alpha}_i^2}}\epsilon\right) μ ( x i , x 0 , i ) = α i 1 ( x i − 1 − α ˉ i 2 1 − α i 2 ϵ ) 이 식은 모델의 평균 μ ϕ \mu_\phi μ ϕ 노이즈를 직접 예측하는 신경망 ϵ ϕ ( x i , i ) \epsilon_\phi(\mathbf{x}_i,i) ϵ ϕ ( x i , i )
μ ( x i , x 0 , i ) = 1 α i ( x i − 1 − α i 2 1 − α ˉ i 2 ϵ ϕ ( x i , i ) ⏟ ϵ -prediction ) \mu(\mathbf{x}_i,\mathbf{x}_0,i)=\frac{1}{\alpha_i}\left(\mathbf{x}_i-\frac{1-\alpha_i^2}{\sqrt{1-\bar{\alpha}_i^2}}\underbrace{\epsilon_\phi(\mathbf{x}_i,i)}_{\epsilon\text{-prediction}}\right) μ ( x i , x 0 , i ) = α i 1 ⎝ ⎜ ⎜ ⎛ x i − 1 − α ˉ i 2 1 − α i 2 ϵ -prediction ϵ ϕ ( x i , i ) ⎠ ⎟ ⎟ ⎞ 이 표현을 원래 손실에 대입하면, 결과적으로 예측된 노이즈와 실제 노이즈 간의 ℓ 2 \ell_2 ℓ 2
∥ μ ϕ ( x i , i ) − μ ( x i , x 0 , i ) ∥ 2 2 ∝ ∥ ϵ ϕ ( x i , i ) − ϵ ∥ 2 2 \|\mu_\phi(\mathbf{x}_i,i)-\mu(\mathbf{x}_i,\mathbf{x}_0,i)\|_2^2\propto\|\epsilon_\phi(\mathbf{x}_i,i)-\epsilon\|_2^2 ∥ μ ϕ ( x i , i ) − μ ( x i , x 0 , i ) ∥ 2 2 ∝ ∥ ϵ ϕ ( x i , i ) − ϵ ∥ 2 2 단, 비례 상수는 timestep i i i
직관적으로, 모델은 각 정방향 단계에서 추가된 랜덤 노이즈를 추적하는 '노이즈 탐지기(noise detective)' 역할을 한다. 오염된 샘플에서 이 노이즈를 빼면 깨끗한 데이터를 향해 한 걸음 이동하게 되며, 이를 반복하면 데이터가 순차적으로 복원 된다.
이를 통해 손실 함수를 더 단순화시킬 수 있다. Timestep에 따라 달라지는 가중치를 제거하여, 널리 사용되는 DDPM 기본 학습 손실 함수를 다음과 같이 얻을 수 있다.
L simple ( ϕ ) : = E i E x ∼ p data E ϵ ∼ N ( 0 , I ) [ ∥ ϵ ϕ ( x i , i ) − ϵ ∥ 2 2 ] \mathcal{L}_\text{simple}(\phi):=\mathbb{E}_i\mathbb{E}_{\mathbf{x}\sim p_\text{data}}\mathbb{E}_{\epsilon\sim\mathcal{N}(\mathbf{0},\mathbf{I})}\left[\|\epsilon_\phi(\mathbf{x}_i,i)-\epsilon\|_2^2\right] L simple ( ϕ ) : = E i E x ∼ p data E ϵ ∼ N ( 0 , I ) [ ∥ ϵ ϕ ( x i , i ) − ϵ ∥ 2 2 ] Timestep t t t 항상 단위 분산(unit variance) 이므로, 위의 ℓ 2 \ell_2 ℓ 2 t t t 동일한 스케일 을 유지한다.
이는 target이 exploding 또는 vanishing 되는 문제를 방지하며, 별도의 손실 가중치가 필요 없게 된다.
추가적으로, L DDPM \mathcal{L}_\text{DDPM} L DDPM L simple \mathcal{L}_\text{simple} L simple ϵ ∗ \epsilon^\ast ϵ ∗ least-squares 문제 로 귀결되기 때문이다.
ϵ ∗ ( x i , i ) = E [ ϵ ∣ x i ] , x i ∼ p i \epsilon^\ast(\mathbf{x}_i,i)=\mathbb{E}[\epsilon\mid\mathbf{x}_i],\quad\mathbf{x}_i\sim p_i ϵ ∗ ( x i , i ) = E [ ϵ ∣ x i ] , x i ∼ p i 🏞️ x \mathbf{x} x
또 다른 동등한 parameterization인 x \mathbf{x} x 클린 예측 이라고도 하며, 신경망 x ϕ ( x i , i ) \mathbf{x}_\phi(\mathbf{x}_i,i) x ϕ ( x i , i ) i i i x i ∼ p i ( x i ) \mathbf{x}_i\sim p_i(\mathbf{x}_i) x i ∼ p i ( x i ) 깨끗한(denoised) 샘플 을 예측하도록 훈련된다.
역전이 평균(reverse mean) 표현식에서, ground-truth 클린 샘플 x \mathbf{x} x x ϕ ( x i , i ) \mathbf{x}_\phi(\mathbf{x}_i,i) x ϕ ( x i , i )
μ ϕ ( x i , i ) = α ˉ i − 1 β i 2 1 − α ˉ i 2 x ϕ ( x i , i ) + ( 1 − α ˉ i − 1 2 ) α i 1 − α ˉ i 2 x i \mu_\phi(\mathbf{x}_i,i)=\frac{\bar{\alpha}_{i-1}\beta_i^2}{1-\bar{\alpha}_i^2}\mathbf{x}_\phi(\mathbf{x}_i,i)+\frac{(1-\bar{\alpha}_{i-1}^2)\alpha_i}{1-\bar{\alpha}_i^2}\mathbf{x}_i μ ϕ ( x i , i ) = 1 − α ˉ i 2 α ˉ i − 1 β i 2 x ϕ ( x i , i ) + 1 − α ˉ i 2 ( 1 − α ˉ i − 1 2 ) α i x i ϵ \epsilon ϵ
∥ μ ϕ ( x i , i ) − μ ( x i , x 0 , i ) ∥ 2 2 ∝ ∥ x ϕ ( x i , i ) − x 0 ∥ 2 2 , x 0 ∼ p data \|\mu_\phi(\mathbf{x}_i,i)-\mu(\mathbf{x}_i,\mathbf{x}_0,i)\|_2^2\propto\|\mathbf{x}_\phi(\mathbf{x}_i,i)-\mathbf{x}_0\|_2^2,\quad\mathbf{x}_0\sim p_\text{data} ∥ μ ϕ ( x i , i ) − μ ( x i , x 0 , i ) ∥ 2 2 ∝ ∥ x ϕ ( x i , i ) − x 0 ∥ 2 2 , x 0 ∼ p data 즉, 모델은 noisy 버전 x i \mathbf{x}_i x i 원본 데이터 샘플 x 0 \mathbf{x}_0 x 0
E i E x 0 ∼ p data E ϵ ∼ N ( 0 , I ) [ ω i ∥ x ϕ ( x i , i ) − x 0 ∥ 2 2 ] \mathbb{E}_i\mathbb{E}_{\mathbf{x}_0\sim p_\text{data}}\mathbb{E}_{\epsilon\sim\mathcal{N}(\mathbf{0},\mathbf{I})}\left[\omega_i\|\mathbf{x}_\phi(\mathbf{x}_i,i)-\mathbf{x}_0\|_2^2\right] E i E x 0 ∼ p data E ϵ ∼ N ( 0 , I ) [ ω i ∥ x ϕ ( x i , i ) − x 0 ∥ 2 2 ] 여기서 ω i \omega_i ω i i i i
이 손실은 최소제곱 문제 이므로, 최적해는 다음과 같다.
x ∗ ( x i , i ) = E [ x 0 ∣ x i ] , x i ∼ p i \mathbf{x}^\ast(\mathbf{x}_i,i)=\mathbb{E}[\mathbf{x}_0\mid\mathbf{x}_i],\quad\mathbf{x}_i\sim p_i x ∗ ( x i , i ) = E [ x 0 ∣ x i ] , x i ∼ p i 즉, 모델은 timestep i i i x i \mathbf{x}_i x i 기댓값 형태의 깨끗한 데이터 를 예측해야 한다는 의미이다.
x \mathbf{x} x ϵ \epsilon ϵ 동등하며 , 정방향 과정으로 다음과 같이 연결된다.
x i = α ˉ i x ϕ ( x i , i ) + 1 − α ˉ i 2 ϵ ϕ ( x i , i ) \mathbf{x}_i=\bar{\alpha}_i\mathbf{x}_\phi(\mathbf{x}_i,i)+\sqrt{1-\bar{\alpha}_i^2}\epsilon_\phi(\mathbf{x}_i,i) x i = α ˉ i x ϕ ( x i , i ) + 1 − α ˉ i 2 ϵ ϕ ( x i , i ) 즉, 모델이 클린 샘플 x ϕ ( x i , i ) \mathbf{x}_\phi(\mathbf{x}_i,i) x ϕ ( x i , i ) ϵ ϕ ( x i , i ) \epsilon_\phi(\mathbf{x}_i,i) ϵ ϕ ( x i , i ) x i \mathbf{x}_i x i
5️⃣ DDPM의 ELBO
DDPM의 ELBO를 바로 알아보기 전에 우선 DDPM의 joint generative distribution 을 알아보자.
p ϕ ( x 0 , x 1 : L ) : = p ϕ ( x 0 ∣ x 1 ) p ϕ ( x 1 ∣ x 2 ) ⋯ p ϕ ( x L − 1 ∣ x L ) p prior ( x L ) p_\phi(\mathbf{x}_0,\mathbf{x}_{1:L}):=p_\phi(\mathbf{x}_0\mid\mathbf{x}_1)p_\phi(\mathbf{x}_1\mid\mathbf{x}_2)\cdots p_\phi(\mathbf{x}_{L-1}\mid\mathbf{x}_L)p_\text{prior}(\mathbf{x}_L) p ϕ ( x 0 , x 1 : L ) : = p ϕ ( x 0 ∣ x 1 ) p ϕ ( x 1 ∣ x 2 ) ⋯ p ϕ ( x L − 1 ∣ x L ) p prior ( x L ) 그리고 데이터에 대한 주변 생성 모델(marginal generative model) 은 다음과 같다.
p ϕ ( x 0 ) : = ∫ p ϕ ( x 0 , x 1 : L ) d x 1 : L p_\phi(\mathbf{x}_0):=\int p_\phi(\mathbf{x}_0,\mathbf{x}_{1:L})d\mathbf{x}_{1:L} p ϕ ( x 0 ) : = ∫ p ϕ ( x 0 , x 1 : L ) d x 1 : L 사실 L diffusion \mathcal{L}_\text{diffusion} L diffusion VAE ⋅ \cdot ⋅ 를 가지며, 이는 로그 가능도의 lower bound로 작동한다.
정리 2.2.3 – DDPM의 ELBO
− log p ϕ ( x 0 ) ≤ − L ELBO ( x 0 ; ϕ ) : = L prior ( x 0 ) + L recon. ( x 0 ; ϕ ) + L diffusion ( x 0 ; ϕ ) \begin{aligned} -\log p_\phi(\mathbf{x}_0)&\le-\mathcal{L}_\text{ELBO}(\mathbf{x}_0;\phi) \\ &:=\mathcal{L}_\text{prior}(\mathbf{x}_0)+\mathcal{L}_\text{recon.}(\mathbf{x}_0;\phi)+\mathcal{L}_\text{diffusion}(\mathbf{x}_0;\phi) \\ \end{aligned} − log p ϕ ( x 0 ) ≤ − L ELBO ( x 0 ; ϕ ) : = L prior ( x 0 ) + L recon. ( x 0 ; ϕ ) + L diffusion ( x 0 ; ϕ ) 여기서 각 항은 다음과 같이 정의된다.
L prior ( x 0 ) : = D KL ( p ( x L ∣ x 0 ) ∥ p prior ( x L ) ) L recon. ( x 0 ; ϕ ) : = E p ( x 1 ∣ x 0 ) [ − log p ϕ ( x 0 ∣ x 1 ) ] L diffusion ( x 0 ; ϕ ) : = ∑ i = 1 L E p ( x i ∣ x 0 ) [ D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ϕ ( x i − 1 ∣ x i ) ) ] \begin{aligned} \mathcal{L}_\text{prior}(\mathbf{x}_0)&:=\mathcal{D}_\text{KL}\left(p(\mathbf{x}_L\mid\mathbf{x}_0)\|p_\text{prior}(\mathbf{x}_L)\right) \\ \mathcal{L}_\text{recon.}(\mathbf{x}_0;\phi)&:=\mathbb{E}_{p(\mathbf{x}_1\mid\mathbf{x}_0)}\left[-\log p_\phi(\mathbf{x}_0\mid\mathbf{x}_1)\right] \\ \mathcal{L}_\text{diffusion}(\mathbf{x}_0;\phi)&:=\sum_{i=1}^L\mathbb{E}_{p(\mathbf{x}_i\mid\mathbf{x}_0)}\left[\mathcal{D}_\text{KL}\left(p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}_0)\|p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\right)\right] \end{aligned} L prior ( x 0 ) L recon. ( x 0 ; ϕ ) L diffusion ( x 0 ; ϕ ) : = D KL ( p ( x L ∣ x 0 ) ∥ p prior ( x L ) ) : = E p ( x 1 ∣ x 0 ) [ − log p ϕ ( x 0 ∣ x 1 ) ] : = i = 1 ∑ L E p ( x i ∣ x 0 ) [ D KL ( p ( x i − 1 ∣ x i , x 0 ) ∥ p ϕ ( x i − 1 ∣ x i ) ) ]
📝 정리 2.2.3의 증명
우선 marginal log-likelihood를 먼저 구해보자.
log p ϕ ( x ) = log ∫ ⋯ ∫ p ϕ ( x , x 0 : L ) d x 0 ⋯ d x L \log p_\phi(\mathbf{x})=\log\int\cdots\int p_\phi(\mathbf{x},\mathbf{x}_{0:L})d\mathbf{x}_0\cdots d\mathbf{x}_L log p ϕ ( x ) = log ∫ ⋯ ∫ p ϕ ( x , x 0 : L ) d x 0 ⋯ d x L 여기서 등장한 결합 분포는 다음과 같다.
p ϕ ( x , x 0 : L ) = p prior ( x L ) ∏ i = 1 L p ϕ ( x i − 1 ∣ x i ) ⋅ p ϕ ( x ∣ x 0 ) p_\phi(\mathbf{x},\mathbf{x}_{0:L})=p_\text{prior}(\mathbf{x}_L)\prod_{i=1}^L p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)\cdot p_\phi(\mathbf{x}\mid\mathbf{x}_0) p ϕ ( x , x 0 : L ) = p prior ( x L ) i = 1 ∏ L p ϕ ( x i − 1 ∣ x i ) ⋅ p ϕ ( x ∣ x 0 ) 이제 변분 분포(variational distribution) p ( x 0 : L ∣ x ) p(\mathbf{x}_{0:L}\mid\mathbf{x}) p ( x 0 : L ∣ x ) log p ϕ ( x ) \log p_\phi(\mathbf{x}) log p ϕ ( x )
log p ϕ ( x ) = log ∫ ⋯ ∫ p ( x 0 : L ∣ x ) p ϕ ( x , x 0 : L ) p ( x 0 : L ∣ x ) d x 0 ⋯ d x L = log E p ( x 0 : L ∣ x ) [ p ϕ ( x , x 0 : L ) p ( x 0 : L ∣ x ) ] \begin{aligned} \log p_\phi(\mathbf{x})&=\log\int\cdots\int p(\mathbf{x}_{0:L}\mid\mathbf{x})\frac{p_\phi(\mathbf{x},\mathbf{x}_{0:L})}{p(\mathbf{x}_{0:L}\mid\mathbf{x})}d\mathbf{x}_0\cdots d\mathbf{x}_L \\ &=\log\mathbb{E}_{p(\mathbf{x}_{0:L}\mid\mathbf{x})}\left[\frac{p_\phi(\mathbf{x},\mathbf{x}_{0:L})}{p(\mathbf{x}_{0:L}\mid\mathbf{x})}\right] \\ \end{aligned} log p ϕ ( x ) = log ∫ ⋯ ∫ p ( x 0 : L ∣ x ) p ( x 0 : L ∣ x ) p ϕ ( x , x 0 : L ) d x 0 ⋯ d x L = log E p ( x 0 : L ∣ x ) [ p ( x 0 : L ∣ x ) p ϕ ( x , x 0 : L ) ] 여기에 얀센 부등식 (log E [ Z ] ≥ E [ log Z ] \log\mathbb{E}[Z]\ge\mathbb{E}[\log Z] log E [ Z ] ≥ E [ log Z ]
log p ϕ ( x ) ≥ E p ( x 0 : L ∣ x ) [ log p ϕ ( x , x 0 : L ) p ( x 0 : L ∣ x ) ] = : L ELBO \log p_\phi(\mathbf{x})\ge\mathbb{E}_{p(\mathbf{x}_{0:L}\mid\mathbf{x})}\left[\log\frac{p_\phi(\mathbf{x},\mathbf{x}_{0:L})}{p(\mathbf{x}_{0:L}\mid\mathbf{x})}\right]=:\mathcal{L}_\text{ELBO} log p ϕ ( x ) ≥ E p ( x 0 : L ∣ x ) [ log p ( x 0 : L ∣ x ) p ϕ ( x , x 0 : L ) ] = : L ELBO 그러므로 즉, − log p ϕ ( x ) ≤ − L ELBO -\log p_\phi(\mathbf{x})\le-\mathcal{L}_\text{ELBO} − log p ϕ ( x ) ≤ − L ELBO
다음으로 변분 분포 p ( x 0 : L ∣ x ) p(\mathbf{x}_{0:L}\mid\mathbf{x}) p ( x 0 : L ∣ x )
p ( x 0 : L ∣ x ) = p ( x L ∣ x ) ∏ i = 1 L p ( x i − 1 ∣ x i , x ) p(\mathbf{x}_{0:L}\mid\mathbf{x})=p(\mathbf{x}_L\mid\mathbf{x})\prod_{i=1}^Lp(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}) p ( x 0 : L ∣ x ) = p ( x L ∣ x ) i = 1 ∏ L p ( x i − 1 ∣ x i , x ) 이제 결합 분포와 변분 분포의 전개식을 ELBO 식에 대입하면 다음과 같다.
L ELBO = E p ( x 0 : L ∣ x ) [ log p prior ( x L ) + ∑ i = 1 L log p ϕ ( x i − 1 ∣ x i ) + log p ϕ ( x ∣ x 0 ) − log p ( x L ∣ x ) − ∑ i = 1 L log p ( x i − 1 ∣ x i , x ) ] \begin{aligned} \mathcal{L}_\text{ELBO}=\mathbb{E}_{p(\mathbf{x}_{0:L}\mid\mathbf{x})}[&\log p_\text{prior}(\mathbf{x}_L)+\sum_{i=1}^L\log p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)+\log p_\phi(\mathbf{x}\mid\mathbf{x}_0) \\ &-\log p(\mathbf{x}_L\mid\mathbf{x})-\sum_{i=1}^L\log p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x})] \\ \end{aligned} L ELBO = E p ( x 0 : L ∣ x ) [ log p prior ( x L ) + i = 1 ∑ L log p ϕ ( x i − 1 ∣ x i ) + log p ϕ ( x ∣ x 0 ) − log p ( x L ∣ x ) − i = 1 ∑ L log p ( x i − 1 ∣ x i , x ) ] 여기서 음의 ELBO를 구할 예정인데, 위의 각 항들을 항들의 dependency와 적절한 marginalization 적용을 통해 그룹화하여 식을 정리하면 구할 수 있다.
− L ELBO = E p ( x 0 ∣ x ) [ − log p ϕ ( x ∣ x 0 ) ] + E p ( x L ∣ x ) [ log p ( x L ∣ x ) p prior ( x L ) ] + ∑ i = 1 L E p ( x i ∣ x ) [ E p ( x i − 1 ∣ x i , x ) [ log p ( x i − 1 ∣ x i , x ) p ϕ ( x i − 1 ∣ x i ) ] ] \begin{aligned} -\mathcal{L}_\text{ELBO}=&\mathbb{E}_{p(\mathbf{x}_0\mid\mathbf{x})}[-\log p_\phi(\mathbf{x}\mid\mathbf{x}_0)]+\mathbb{E}_{p(\mathbf{x}_L\mid\mathbf{x})}\left[\log\frac{p(\mathbf{x}_L\mid\mathbf{x})}{p_\text{prior}(\mathbf{x}_L)}\right] \\ &+\sum_{i=1}^L\mathbb{E}_{p(\mathbf{x}_i\mid\mathbf{x})}\left[\mathbb{E}_{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x})}\left[\log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x})}{p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}\right]\right] \\ \end{aligned} − L ELBO = E p ( x 0 ∣ x ) [ − log p ϕ ( x ∣ x 0 ) ] + E p ( x L ∣ x ) [ log p prior ( x L ) p ( x L ∣ x ) ] + i = 1 ∑ L E p ( x i ∣ x ) [ E p ( x i − 1 ∣ x i , x ) [ log p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i , x ) ] ] 마지막 항은 다음의 분해(factorization)를 통해 유도하였다.
p ( x i , x i − 1 ∣ x ) = p ( x i ∣ x ) p ( x i − 1 ∣ x i , x ) p(\mathbf{x}_i,\mathbf{x}_{i-1}\mid\mathbf{x})=p(\mathbf{x}_i\mid\mathbf{x})p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x}) p ( x i , x i − 1 ∣ x ) = p ( x i ∣ x ) p ( x i − 1 ∣ x i , x ) 그리고 이 분해를 기댓값 항에 적용하여 위 음의 ELBO 식의 마지막 항을 얻었다.
E p ( x 0 : L ∣ x ) [ log p ( x i − 1 ∣ x i , x ) p ϕ ( x i − 1 ∣ x i ) ] = ∫ p ( x i ∣ x ) [ ∫ p ( x i − 1 ∣ x i , x ) log p ( x i − 1 ∣ x i , x ) p ϕ ( x i − 1 ∣ x i ) d x i − 1 ] d x i = E p ( x i ∣ x ) [ E p ( x i − 1 ∣ x i , x ) [ log p ( x i − 1 ∣ x i , x ) p ϕ ( x i − 1 ∣ x i ) ] ] \begin{aligned} &\mathbb{E}_{p(\mathbf{x}_{0:L}\mid\mathbf{x})}\left[\log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x})}{p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}\right] \\ &=\int p(\mathbf{x}_i\mid\mathbf{x})\left[\int p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x})\log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x})}{p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}d\mathbf{x}_{i-1}\right]d\mathbf{x}_i \\ &=\mathbb{E}_{p(\mathbf{x}_i\mid\mathbf{x})}\left[\mathbb{E}_{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x})}\left[\log\frac{p(\mathbf{x}_{i-1}\mid\mathbf{x}_i,\mathbf{x})}{p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)}\right]\right] \\ \end{aligned} E p ( x 0 : L ∣ x ) [ log p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i , x ) ] = ∫ p ( x i ∣ x ) [ ∫ p ( x i − 1 ∣ x i , x ) log p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i , x ) d x i − 1 ] d x i = E p ( x i ∣ x ) [ E p ( x i − 1 ∣ x i , x ) [ log p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i , x ) ] ] − L ELBO -\mathcal{L}_\text{ELBO} − L ELBO L recon. \mathcal{L}_\text{recon.} L recon. L prior \mathcal{L}_\text{prior} L prior L diffusion \mathcal{L}_\text{diffusion} L diffusion 정리 2.2.3 에서의 ELBO 식 유도가 마무리된다. ■ \blacksquare ■
DDPM의 ELBO는 다음과 같은 세 가지 구성 요소 를 가진다.
L prior \mathcal{L}_\text{prior} L prior β i {\beta_i} β i p ( ⋅ ∣ x 0 ) p(\cdot\mid\mathbf{x}_0) p ( ⋅ ∣ x 0 ) p prior p_\text{prior} p prior 사실상 무시 할 수 있을 정도로 작아진다.
L recon. \mathcal{L}_\text{recon.} L recon. Monte Carlo 추정 으로 근사하여 실용적으로 최적화할 수 있다.
L diffusion \mathcal{L}_\text{diffusion} L diffusion i i i p ϕ ( x i − 1 ∣ x i ) p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i) p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i ) p(\mathbf{x}_{i-1}\mid\mathbf{x}_i) p ( x i − 1 ∣ x i ) 맞추는 역할 을 한다.
Diffusion 모델의 변분적 시각은 HVAE 구조와 놀라울 정도로 잘 들어맞는다.
Encoder는 학습되지 않는 고정된 forward noising process 이다.
잠재변수 x 1 : T \mathbf{x}_{1:T} x 1 : T 동일한 차원 을 가진다.
학습은 동일한 ELBO를 최대화 하는 방식으로 진행된다.
VAE와 달리 학습된 encoder도 없고, 레벨별 KL 항도 없다.
대신, 학습 과정이 큰 노이즈 → \rightarrow → 일련의 denoising 문제 로 자연스럽게 분해된다.
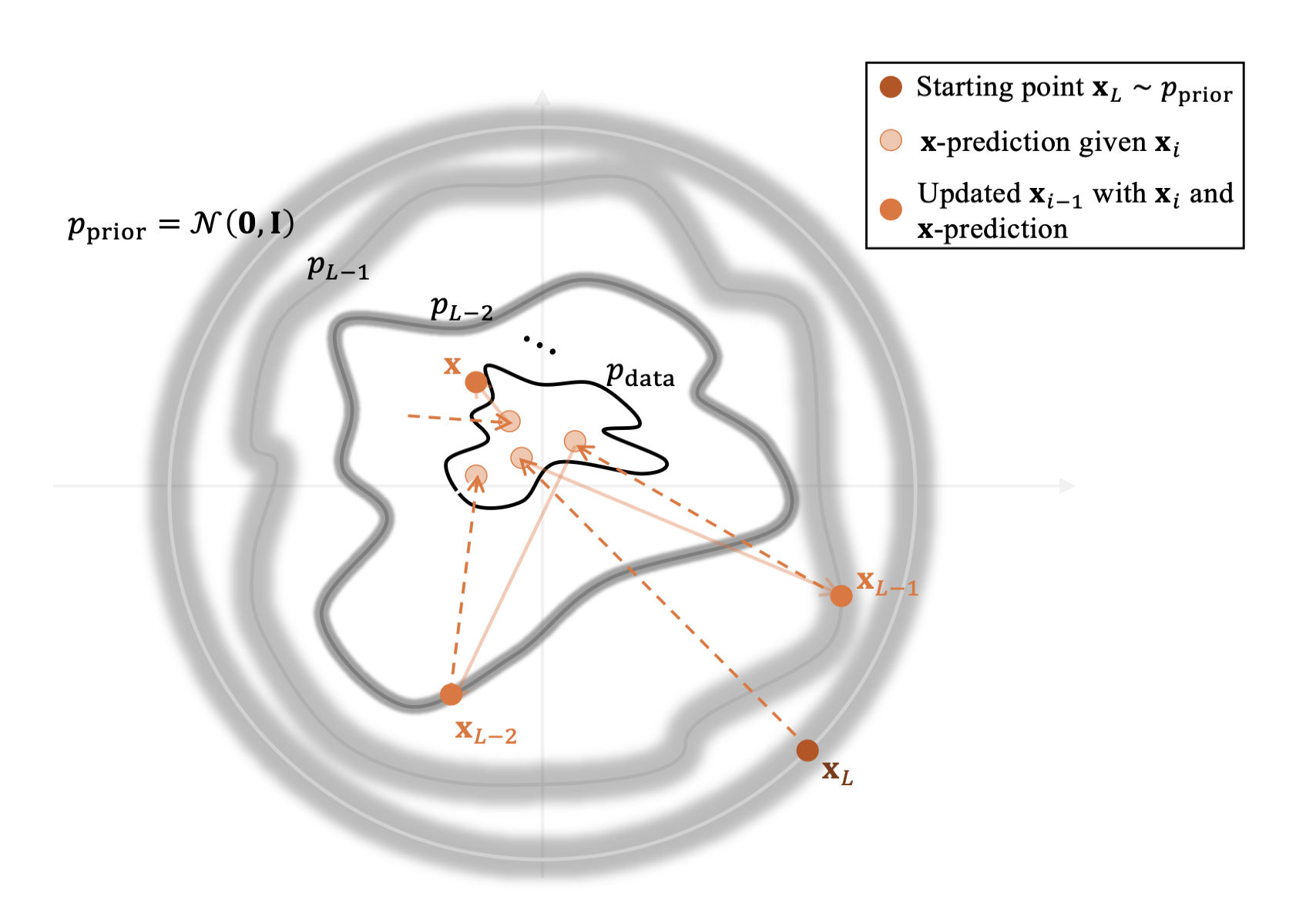
6️⃣ 샘플링
ϵ \epsilon ϵ ϵ ϕ × ( x i , i ) \epsilon_{\phi^\times}(\mathbf{x}_i,i) ϵ ϕ × ( x i , i ) 순차적으로(sequentially) 진행되며, 이제 실제 역전이 커널 대신 학습된 파라미터화된 전이분포 p ϕ × ( x i − 1 ∣ x i ) p_{\phi^\times}(\mathbf{x}_{i-1}\mid\mathbf{x}_i) p ϕ × ( x i − 1 ∣ x i ) × \times × frozen 된 상태임을 나타낸다.
좀 더 구체적으로는, 무작위 초기값 x L ∼ p prior = N ( 0 , 1 ) \mathbf{x}_L\sim p_\text{prior}=\mathcal{N}(\mathbf{0},\mathbf{1}) x L ∼ p prior = N ( 0 , 1 ) i = L , L − 1 , … , 1 i=L,L-1,\ldots,1 i = L , L − 1 , … , 1
x i − 1 ← 1 α i ( x i − 1 − α i 2 1 − α ˉ i 2 ϵ ϕ × ( x i , i ) ) ⏟ μ ϕ × ( x i , i ) + σ ( i ) ϵ i , ϵ i ∼ N ( 0 , I ) \mathbf{x}_{i-1}\leftarrow\underbrace{\frac{1}{\alpha_i}\left(\mathbf{x}_i-\frac{1-\alpha_i^2}{\sqrt{1-\bar{\alpha}_i^2}}\epsilon_{\phi^\times}(\mathbf{x}_i,i)\right)}_{\mu_{\phi^\times}(\mathbf{x}_i,i)}+\sigma(i)\epsilon_i,\quad\epsilon_i\sim\mathcal{N}(\mathbf{0},\mathbf{I}) x i − 1 ← μ ϕ × ( x i , i ) α i 1 ( x i − 1 − α ˉ i 2 1 − α i 2 ϵ ϕ × ( x i , i ) ) + σ ( i ) ϵ i , ϵ i ∼ N ( 0 , I ) 이 denoising(복원) 과정은 x 0 \mathbf{x}_0 x 0 x 0 \mathbf{x}_0 x 0 새로운 클린 생성 샘플(clean generated sample) 이 된다.
📒 DDPM 샘플링에 대한 또 다른 해석
위에서 언급된 x i = α ˉ i x ϕ ( x i , i ) + 1 − α ˉ i 2 ϵ ϕ ( x i , i ) \mathbf{x}_i=\bar{\alpha}_i\mathbf{x}_\phi(\mathbf{x}_i,i)+\sqrt{1-\bar{\alpha}_i^2}\epsilon_\phi(\mathbf{x}_i,i) x i = α ˉ i x ϕ ( x i , i ) + 1 − α ˉ i 2 ϵ ϕ ( x i , i ) ϵ ϕ × ( x i , i ) \epsilon_{\phi^\times}(\mathbf{x}_i,i) ϵ ϕ × ( x i , i )
x ϕ × ( x i , i ) = x i − 1 − α ˉ i 2 α ˉ i ϵ ϕ × ( x i , i ) \mathbf{x}_{\phi^\times}(\mathbf{x}_i,i)=\mathbf{x}_i-\frac{\sqrt{1-\bar{\alpha}_i^2}}{\bar{\alpha}_i}\epsilon_{\phi^\times}(\mathbf{x}_i,i) x ϕ × ( x i , i ) = x i − α ˉ i 1 − α ˉ i 2 ϵ ϕ × ( x i , i ) 이 표현을 위의 샘플링 규칙에 대입하면 다음과 같은 동등한 형태의 업데이트 식이 만들어진다.
x i ← ( interpolation between x i and x ϕ × ) + σ ( i ) ϵ i \mathbf{x}_i\leftarrow(\text{interpolation between }\mathbf{x}_i\text{ and }\mathbf{x}_{\phi^\times})+\sigma(i)\epsilon_i x i ← ( interpolation between x i and x ϕ × ) + σ ( i ) ϵ i 이는 각 단계의 중심 이 클린 예측 x ϕ × \mathbf{x}_{\phi^\times} x ϕ × σ ( i ) \sigma(i) σ ( i )
이 관점에서 DDPM 샘플링은 다음 두 과정을 번갈아 수행하는 반복적 복원 과정(iterative denoising process) 으로 볼 수 있다.
현재 noisy 입력 x i \mathbf{x}_i x i 클린 데이터 추정치 x ϕ × ( x i , i ) \mathbf{x}_{\phi^\times}(\mathbf{x}_i,i) x ϕ × ( x i , i )
그 추정치를 사용해 더 적은 노이즈를 가진 x i − 1 \mathbf{x}_{i-1} x i − 1
이 과정을 계속 반복하면, 초기 무작위 노이즈 x L \mathbf{x}_L x L x 0 \mathbf{x}_0 x 0
그러나 x ϕ × \mathbf{x}_{\phi^\times} x ϕ × 최적의 디노이저(optimal denoiser) 로 학습되었다 하더라도, 이는 어디까지나 주어진 noisy 입력 x i \mathbf{x}_i x i 평균적인 샘플 만을 예측할 수 있을 뿐이다.
이 때문에 특히 노이즈가 매우 큰 초기 단계에서는 심하게 훼손된 입력으로부터 세부 구조를 복원하기가 어려워 예측된 클린 샘플이 흐릿해지는(blurry) 문제가 발생한다.
이 관점에서 보면, diffusion 모델의 샘플링 과정은 높은 노이즈 → \rightarrow → 점진적으로 이동 하며 클린 신호의 추정치를 점점 더 정교하게 다듬어가는 과정이라 할 수 있다.
초기 단계에서는 전체적이고 거친(global & coarse) 구조가 형성되고,
후반 단계로 갈수록 세밀한 디테일(finer details) 이 추가된다.
이러한 점진적 복원 덕분에 노이즈가 제거될수록 샘플은 점점 더 현실적인 형태를 띄게 된다.
🐌 DDPM의 느린 샘플링 속도
DDPM의 샘플링은 태생적으로 느릴 수밖에 없다 . 그 이유는 역전이 과정이 완전히 sequential 하고, 매 단계가 다음 단계에 직접적으로 의존 하기 때문이다.
조금 더 구체적으로는 다음과 같은 제약이 존재한다.
이론적으로는 역전이 분포를 정확히 모델링할 수 있다. p ϕ ( x i − 1 ∣ x i ) p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i) p ϕ ( x i − 1 ∣ x i ) p ( x i − 1 ∣ x i ) p(\mathbf{x}_{i-1}\mid\mathbf{x}_i) p ( x i − 1 ∣ x i ) 정확하게 모사 할 수 있다.
하지만 실제 구현에서는 단일 Gaussian 근사에 의존한다. p ϕ ( x i − 1 ∣ x i ) = N ( μ ϕ ( x i , i ) , σ 2 ( i ) I ) p_\phi(\mathbf{x}_{i-1}\mid\mathbf{x}_i)=\mathcal{N}(\mu_\phi(\mathbf{x}_i,i),\sigma^2(i)\mathbf{I}) p ϕ ( x i − 1 ∣ x i ) = N ( μ ϕ ( x i , i ) , σ 2 ( i ) I )
이 단일 Gaussian 가정은 구현과 학습을 단순하게 만들지만, 표현력을 크게 제한 하는 요소가 된다.
작은 β \beta β β \beta β β i \beta_i β i
그러나 β i \beta_i β i 표현할 수 없다 .
그래서 β \beta β β i \beta_i β i 매우 작게 설정해야 한다. 그러면 각 단계의 변화폭이 너무 작아지므로 전체 과정은 수백~수천 단계로 매우 촘촘하게 쪼개진다.
즉, DDPM 샘플링이 느린 이유는 모든 스텝이 이전 스텝을 반드시 기다려야 하는 완전 순차적 구조 와 그리고 정확도를 유지하기 위해 요구되는 작은 β \beta β 많은 timestep 때문이다.
✅ 요약
DDPM 은 데이터를 점진적으로 노이즈화하는 고정된 정방향 과정과, 이를 거꾸로 복원하는 학습 가능한 역방향 과정으로 구성된 변분적 생성 모델 이다.
직접 계산이 불가능한 역전이 분포 p ( x i − 1 ∣ x i ) p(\mathbf{x}_{i-1}\mid\mathbf{x}_i) p ( x i − 1 ∣ x i ) x 0 \mathbf{x}_0 x 0 조건부화 하여 역전이 조건부 p ( x i − 1 ∣ x i , x 0 ) p(\mathbf{x}_{i-1}\mid \mathbf{x}_i,\mathbf{x}_0) p ( x i − 1 ∣ x i , x 0 ) 닫힌형 Gaussian 이 된다는 성질을 활용한다.
이를 통해 학습 목표는 각 단계의 조건부 분포를 KL 관점에서 맞추는 단순한 회귀 문제로 정리되며, 실용적으로는 노이즈 자체를 예측 하는 ϵ \epsilon ϵ x \mathbf{x} x "각 timestep에서 노이즈를 정확히 제거하는 법" 을 학습하는 과정이 된다.
샘플 생성 시에는 표준 정규분포 에서 시작하여 학습된 평균 ⋅ \cdot ⋅ 순차적으로 노이즈를 제거 하며 x 0 \mathbf{x}_0 x 0 샘플링 속도가 느리다는 근본적 한계 를 가진다.
이러한 제약은 이후 DDIM, ODE 기반 샘플러 등 고속 생성 기법으로 발전하는 동기를 제공한다.
📄 출처
[1] Lai, Chieh-Hsin, et al. The Principles of Diffusion Models. arXiv, 24 Oct. 2025, arXiv:2510.21890.