앞선 글에서는 diffusion 모델이 변분적 관점(variational framework) 에서 어떻게 해석될 수 있는지 살펴보았다. 이제 이번 글에서는 또 다른 하나의 핵심적인 시각인 에너지 기반 모델(Energy-Based Model; EBM) 로 초점을 옮겨보고자 한다.
EBM은 데이터가 놓여 있는 영역에서는 에너지가 낮고, 그 외의 영역에서는 에너지가 높은 형태의 에너지 지형(energy landscape) 으로 확률분포를 표현한다. 샘플링은 보통 랑주뱅 역학(Langevin dynamics) 을 통해 이루어지며, 이는 에너지 지형의 기울기를 따라 확률이 높은 방향으로 이동하도록 한다. 이때 등장하는 것이 바로 점수(score) 로, 각 지점에서 "더 가능성이 높은 방향" 을 가리키는 벡터장이다.
여기서 중요한 사실은 score만 알면 정규화 상수를 계산하지 않고도 생성이 가능하다는 점이다. 즉, 확률분포의 정확한 값을 몰라도 그 gradient field를 따라가면 자연스럽게 데이터 영역으로 이동할 수 있는 것이다. Score-based diffusion models는 바로 이러한 기반 위에서 구축된다.
Diffusion 모델은 깨끗한 데이터 분포만을 다루는 대신, 점점 더 강한 Gaussian 노이즈가 섞인 일련의 분포들을 고려한다. 이러한 분포들은 점수를 근사하기 훨씬 쉽고, 결과적으로 각 단계의 score를 학습하면 전체적인 "되돌아가는 흐름" 이 완성된다. 학습된 score field들은 노이즈 샘플을 단계적으로 정돈된 형태로 바꾸어주며 생성 과정은 점진적 복원(progressive denoising) 과 동일한 절차로 자연스럽게 구현된다.
⚡️ EBM 알아보기
이제 점수(score)의 개념이 어디에서 비롯되는지, 그리고 EBM이 어떻게 확률을 표현하는지 이해하기 위해 에너지 함수 기반의 확률 모델링을 먼저 짚고 넘어가자.
1️⃣ 에너지 함수를 이용한 확률분포 모델링
한 데이터 포인트 x∈RD가 있다고 가정하자. EBM은 파라미터 ϕ를 갖는 에너지 함수Eϕ(x)를 통해 확률 밀도를 정의하며, 이 에너지 함수를 더 가능성이 높은 구성(configuration)일수록 더 낮은 에너지 를 할당한다.
이때 확률분포는 다음과 같이 주어진다.
pϕ(x):=Zϕexp(−Eϕ(x)),Zϕ:=∫RDexp(−Eϕ(x))dx
여기서 Zϕ는 정규화를 보장하는 분배함수(partition function) 로, 다음 조건이 성립하도록 한다.
∫RDpϕ(x)dx=1
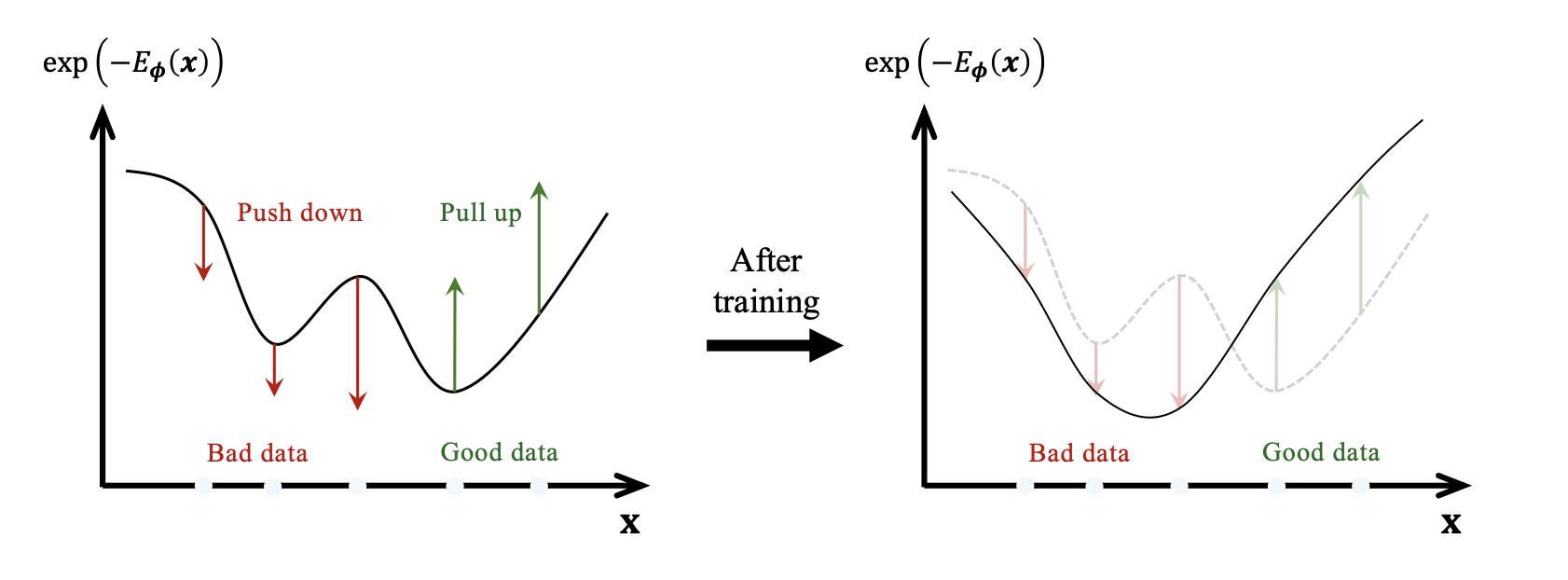
위 그림에서 볼 수 있듯, 낮은 에너지를 가진 지점은 높은 확률을 의미하여, 이는 공이 골짜기로 굴러 떨어지는 상황에 비유할 수 있다. 분배함수 Zϕ는 전체 확률이 1이 되도록 조정하기 때문에 절대적인 에너지 값보다 상대적인 에너지 차이만이 실제 확률비를 결정한다.
예를 들어 모든 에너지에 동일한 상수를 더하더라도,
분자의 exp(−Eϕ(x))는 같은 비율로 곱해지고,
분모 Zϕ역시 같은 비율로 곱해지므로,
결과적으로 확률분포 자체는 변하지 않는다.
또한 Zϕ가 전체 확률 질량을 1로 맞추는 역할을 하기 때문에, 어떤 영역에서 에너지를 낮추어 그 영역의 확률을 높이면, 그에 대한 상보적인(complementary) 영역의 확률은 감소해야 한다.
즉, EBM은 어떤 골짜기를 더 깊게 만들면, 다른 골짜기들은 상대적으로 더 얕아져야만 한다는 일종의 전역(global)적인 trade-off를 따른다.
🚫 EBM의 최대우도 학습이 어려운 이유
원칙적으로, EBM은 다음의 최대우도(maximum likelihood) 목적함수를 통해 학습될 수 있다.
LMLE(ϕ)=Epdata(x)[logZϕexp(−Eϕ(x))]=lowers energy of dataEpdata[Eϕ(x)]−global regularizationlog∫exp(−Eϕ(x))dx
여기서
첫 번째 항: 데이터가 위치한 영역의 에너지를 낮추도록 학습을 유도한다
두 번째 항: 정규화를 위한 Zϕ 계산이 필요한데, 이는 고차원에서 거의 intractable 하다. (해당 계산이 모델 분포 pdata에 대한 기댓값을 필요로 하기 때문)
따라서 EBM은 표면적으로는 간단해 보이지만, 분배함수 Zϕ 때문에 MLE 학습이 실질적으로 매우 어렵다는 근본적 난점을 갖는다.
이 문제는 다음과 같은 대안적 학습 목적들을 고안하도록 동기를 부여하였다.
해당 항을 근사 하려는 접근 – Contrastive Divergence (Hinton, 2002)
혹은 아예 이 항을 완전히 회피 하는 접근 – Score Matching
이 중에서 정규화 항의 계산을 완전히 회피해버리는 Score Matching에 대해 깊게 파고들고자 한다.
2️⃣ Score이란 무엇인가?
어떤 확률밀도 p(x)가 RD위에 정의되어 있다고 하자. Score function(점수 함수) 은 로그 밀도의 기울기(gradient)로 정의된다.
s(x):=∇xlogp(x),s:RD→RD
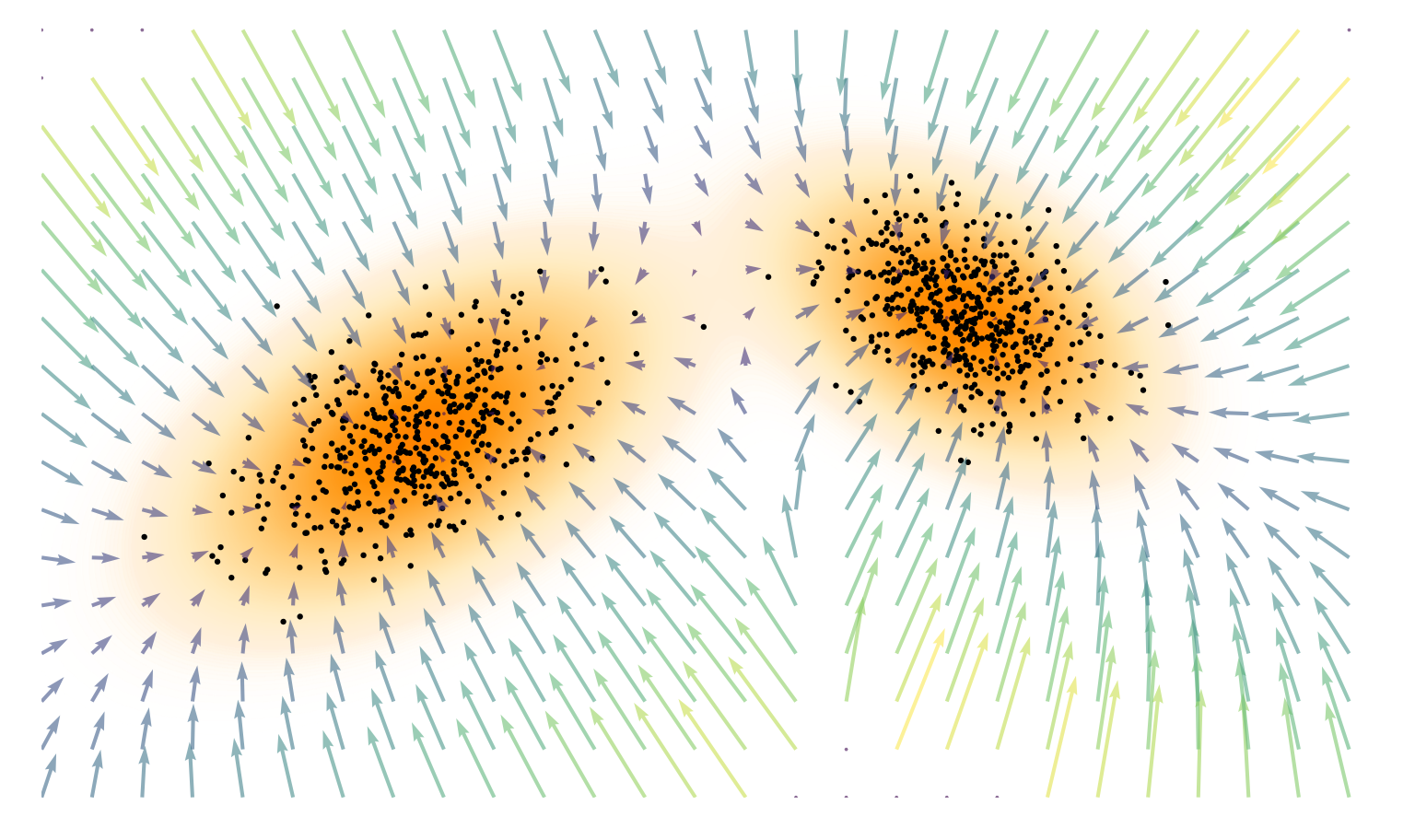
직관적으로 score는 더 높은 확률 밀도 쪽을 향하는 벡터장(vector field) 을 형성한다. 즉, 국소적으로 어느 방향으로 이동해야 데이터가 더 일어날 법한지(local likelihood)를 알려주는 일종의 나침반 역할을 한다.
💡 왜 밀도 대신 Score을 모델링할까?
Score을 직접 모델링하는 것은 이론적 ⋅ 실용적 이유 모두에서 매우 유용하다. 그 핵심 이유는 다음과 같다.
정규화 상수와 무관함
어떤 분포가 다음과 같이 정규화되지 않은 형태로 주어졌다고 하자.
p~(x)=exp(−Eϕ(x))
그렇다면 정규화된 밀도는
p(x)=Zp~(x),Z=∫p~(x)dx
여기서 Z는 계산하기 어렵기로 알려진 분배함수(partition function)이다.
그런데 score는 다음과 같이 분배함수 항이 사라지는 것을 볼 수 있다.
∇xlogp(x)=∇xlogp~(x)−=0∇xlogZ=∇xlogp~(x)
즉, 분배함수를 계산하지 않고도 score는 완전히 정의된다. EBM이나 diffusion에서 score를 다루는 근본적인 이유다.
Score는 분포를 완전히 표현할 수 있음
Score는 로그 밀도의 기울기이기 때문에, 이를 통해 원래의 분포를 (정규화 상수만 제외하고) 복원할 수 있다.
이는 수학적으로 선적분(line integral) 의 정의를 통해 증명할 수 있는데, 예를 들어 시간 t∈[0,1]에 대해 x가 다음과 같이 t로 매개변수화 r(t)=x0+t(x−x0) 된다고 가정하자. 여기서 x0은 일종의 reference point이다.
이제 g(t):=logp(r(t))라 가정하고 미분의 연쇄법칙(chain rule) 을 사용하면,
즉, 모델의 score와 데이터의 score 사이의 거리(제곱 오차, 혹은 ℓ2 오차)를 최소화하는 것이다. 하지만 문제는,
데이터 분포의 score인 ∇xlogpdata(x)는 관측 불가능하다.
이를 직접 계산하기 위해서는 데이터의 실제 확률밀도 함수를 알아야 하는데, 현실적으로는 절대 알 수 없는 정보이다.
✏️ 부분적분으로 데이터 Score 계산 우회하기
Hyvärinen은 부분적분(integration by parts) 을 이용하면 위 손실 LSM(ϕ)을 pdata의 개입 없이, 오로지 에너지 함수 Eϕ과 그 도함수만으로 서술할 수 있음을 보였다. 이 과정은 수학적으로 다소 복잡할 수 있으나, 차근차근 따라가보면 쉽게 이해할 수 있다.
여기서 ∇x2Eϕ(x)는 에너지 함수 Eϕ에 대한 헤시안 행렬(Hessian matrix) 이다.
이러한 형태의 목적 함수는 분배함수 Zϕ를 제거하고, 또 학습 과정에서 모델 분포로부터 샘플링할 필요도 없게 해주기 때문에 매력적이다. 하지만 한 가지 치명적인 단점이 있는데, 바로 2차 미분인 헤시안(Hessian) 을 계산해야 한다는 점이다.
이는 고차원 데이터에서는 계산 비용이 매우 커져 실질적으로 사용을 어렵게 만든다. 이후 글에서 이러한 한계를 해결하기 위한 다양한 접근법을 다시 살펴보고자 한다.
4️⃣ Score Function을 통한 랑주뱅 샘플링
EBM의 에너지 함수 Eϕ(x)로 정의된 모델로부터 샘플링하는 과정은 랑주뱅 동역학(Langevin dynamics) 을 통해 수행할 수 있다.
여기서는 먼저 이산 시간(discrete-time) 에서의 Langevin update를 소개하고, 이어서 그것의 연속 시간(continuous-time) 극한 형태인 확률 미분방정식(Stochastic Differential Equation; SDE) 으로의 전환을 다룰 예정이다.
그리고 마지막으로 Langevin 동역학이 복잡한 에너지 지형을 효과적으로 탐색할 수 있도록 해주는 물리적 직관에 대해 설명할 예정이다.
⏱️ 이산 시간 랑주뱅 동역학
이산 시간에서의 Langevin update는 다음과 같이 정의된다.
xn+1=xn−η∇xEϕ(xn)+2ηϵn,n=0,1,2,…
여기서 x0는 임의의 분포(보통 Gaussian)에서 초기화된 값, η>0는 스텝 크기(step size), 그리고 ϵn∼N(0,I)는 Gaussian 노이즈이다.
노이즈 항은 샘플링이 국소 최소(local minima) 에 갇히지 않도록 샘플이 확률 공간을 더 폭넓게 탐색할 수 있게 해주며, update에 확률적 요인(stochasticity) 을 부여한다.
EBM에서 사용하는 score의 정의를 대입하면 다음과 같이 update rule을 다시 서술할 수 있다.
xn+1=xn+η∇xlogpϕ(xn)+2ηϵn
여기서 score function은 샘플을 고확률(high-density) 영역 쪽으로 밀어주는 역할을 하며, 이러한 표현은 diffusion 모델들에서 핵심적인 역할을 한다.
⏳ 연속 시간 랑주뱅 동역학
스텝 크기를 η→0로 보내면, 위의 이산적 update는 자연스럽게 연속 시간에서의 확률 미분방정식(SDE) 으로 수렴하게 된다.
이 연속 시간 과정은 다음의 Langevin SDE로 주어진다.
dx(t)=∇xlogpϕ(x(t))+2dw(t)
여기서 w(t)는 표준 브라운 운동(Brownian motion) 또는 Wiener 과정을 나타낸다.
일반적인 정규성 가정(예: pϕ∝e−Eϕ, 충분히 부드러운 Eϕ) 하에서해 x(t)의 분포는 t→∞에 따라 지수적으로 빠르게 pϕ로 수렴한다.
따라서 SDE를 시뮬레이션 하는 것만으로 pϕ로부터 샘플을 생성할 수 있다.
❓ 랑주뱅 SDE의 해가 pϕ에 수렴하는 이유
더 나아가기 앞서 왜 Langevin SDE의 해 x(t)의 분포가 시간이 지나면 pϕ(x)∝e−Eϕ(x)로 수렴하는지를 Fokker-Planck 방정식(FP-Equation) 관점에서 개념적 설명과 함께 정리하고자 한다.
위의 연속 시간에서의 Langevin SDE는 개별 샘플의 확률적 움직임(경로) 을 설명하는 식이다. 하지만 여기서 근본적으로 알고 싶은 것은 다음이다.
"시간이 흐를 때 확률밀도 함수(density) ρ(x,t)는 어떻게 변화하는가?"
즉, SDE는 비유적으로 설명하자면 입자 한 개의 움직임을 설명하고, FP 방정식은 그 입자들의 분포가 시간에 따라 어떻게 흘러가는지를 설명한다.
직접적으로 Langevin SDE에 FP 방정식을 적용하기 전에 FP 방정식의 일반적인 형태부터 다루고 이후에 적용하는 방향으로 진행해보자.
우선, 다음 형태의 SDE를 가정해보자.
dx(t)=f(x)dt+2Ddw(t)
이때 확률밀도 ρ(x,t)에 대한 FP 방정식은 다음과 같다.
∂t∂ρ=−∇⋅(f(x)ρ)+DΔρ
첫 번째 항: 드리프트(gradient flow) 에 의해 밀도가 이동하는 현상
두 번째 항: 확산(diffusion) 에 의해 밀도가 퍼지는 현상
이를 현재의 Langevin SDE에 적용하면,
Gradient Flow: f(x)=−∇xEϕ(x) 또는 f(x)=∇xlogpϕ(x)
Diffusion: D=1 (왜냐하면 고정적인 2 잡음이 들어가 있기 때문)
따라서 이에 대한 FP 방정식은 아래와 같다.
∂t∂ρ=−∇⋅(ρ∇xlogpϕ)+Δρ
여기서 Δ=∇2는 라플라시안(Laplacian)을 나타낸다.
이제 정적해를 구하는 과정으로 넘어가보자. 정적해(stationary solution) 란, 시간이 지나도 밀도가 더 이상 변하지 않는 상태∂ρ/∂t=0 즉,
0=−∇⋅(ρ∇xlogpϕ)+Δρ
이 편미분방정식(PDE)를 만족시키는 ρ(x)가 SDE의 stationary solution이 된다.
이제 ρ(x)=pϕ(x)가 stationary함을 보여야 한다. 우선 pϕ를 식에 대입해보면 FP 방정식의 첫 번째 항은 다음과 같이 된다.
−∇⋅(ρ∇xlogpϕ)=−∇⋅(ρ(−∇xEϕ))=∇⋅(ρ∇xEϕ)
그리고 두 번째 항은 Δρ=∇⋅(∇ρ)로 변환할 수 있다.
이제 ρ(x)=pϕ(x)=Zϕ1e−Eϕ(x)라 두고 ∇ρ를 직접 계산해보자. 정규화 상수 Zϕ는 x에 의존하지 않는 상수이므로, 이를 고려한 채 chain rule을 적용하면,
이므로, ρ=pϕ는 Fokker-Planck 방정식의 정적해(stationary solution) 가 된다. ■
정리하자면,
Langevin SDE에 대응되는 FP 방정식을 쓰면
그 stationary solution이 바로 EBM이 정의하는 분포 pϕ(x)∝e−Eϕ(x)이고,
적당한 정규성 조건 아래에서 시간 t→∞에서의 x(t)의 분포는 이 stationary 분포 pϕ로 수렴하게 된다.
🎢 왜 랑주뱅 샘플링인가?
Langevin 샘플링을 이해하는 자연스러운 방법은 물리학적 관점에서 바라보는 것이다.
에너지 함수 Eϕ(x)는 물리학적으로 입자의 움직임을 결정하는 퍼텐셜(potential) 에너지 지형을 정의한다고 볼 수 있다.
뉴턴 역학 에 따르면, 에너지로부터 유도되는 힘(field)에 의해 움직이는 입자의 동역학은 다음 상미분방정식(ODE)로 나타낼 수 있다.
dtdx(t)=−∇xEϕ(x(t))
이 식은 입자를 에너지가 낮아지는 방향으로 계속 움직이게 하며, 결국 에너지 함수의 극소점(local minima) 로 끌려가게 만든다.
그러나 이러한 결정론적인(deterministic) 동역학은 한 가지 심각한 한계를 가진다. 바로 입자가 한 번 어떤 지역의 에너지 골짜기(극소 영역)에 빠지면, 그 지역을 빠져나올 방법이 없기 때문에 전체 데이터 분포를 충분히 탐색하지 못한다.
이 한계를 극복하기 위해 Langevin 동역학은 확률적 교란을 도입한다. 이를 위해 앞서 언급한 다음과 같은 확률 미분방정식(SDE) 형태의 Langevin 동역학이 사용된다.
dx(t)=−∇xEϕ(x(t))dt+2dw(t)
이때 2dw(t)항은 물리학적으로 시스템에 열적(thermal) 잡음 을 주입하는 역할을 하며, 다음과 같은 효과를 만든다.
입자가 에너지 장벽(energy barrier)을 넘어서
다른 지역의 모드(mode)로 이동할 수 있게 하며,
단순한 ODE와 달리, 전체 공간을 확률적으로 탐색할 수 있도록 만든다.
이 관점에서 EBM은 단순한 에너지 함수라기보다는 "샘플을 고확률(high-density) 영역으로 끌어당기는 벡터장(force field)" 을 학습하는 구조라고 볼 수 있다.
따라서 Langevin 샘플링은 이 벡터장을 따라가되, 확률적 노이즈를 섞어가면서 탐색하도록 만들어 정확한 모델 분포의 샘플을 생성하는 실질적인 방법이 된다.
그리고 이 샘플링 방식의 안정성은 확률 열역학(stochastic thermodynamics) 및 Fokker-Planck 방정식 이론에 의해 엄밀하게 정당화된다.
⚠️ 랑주뱅 샘플링 고유의 한계
Langevin 동역학은 널리 사용되는 MCMC(Markov Chain Monte-Carlo) 기반 샘플러이지만, 고차원 공간에서는 여러 심각한 한계를 지닌다.
특히, 샘플링의 효율성은 다음 요소들에 매우 민감하다.
스텝 크기(step size) η
노이즈 크기(noise scale)
목표 분포를 정확하게 근사하기 위해 필요한 반복 횟수(iterations)
이러한 민감성 때문에, 실제 모델링에서는 샘플링을 안정적으로 수행하기 위해 많은 튜닝이 필요하며 계산 비용도 크게 증가한다.
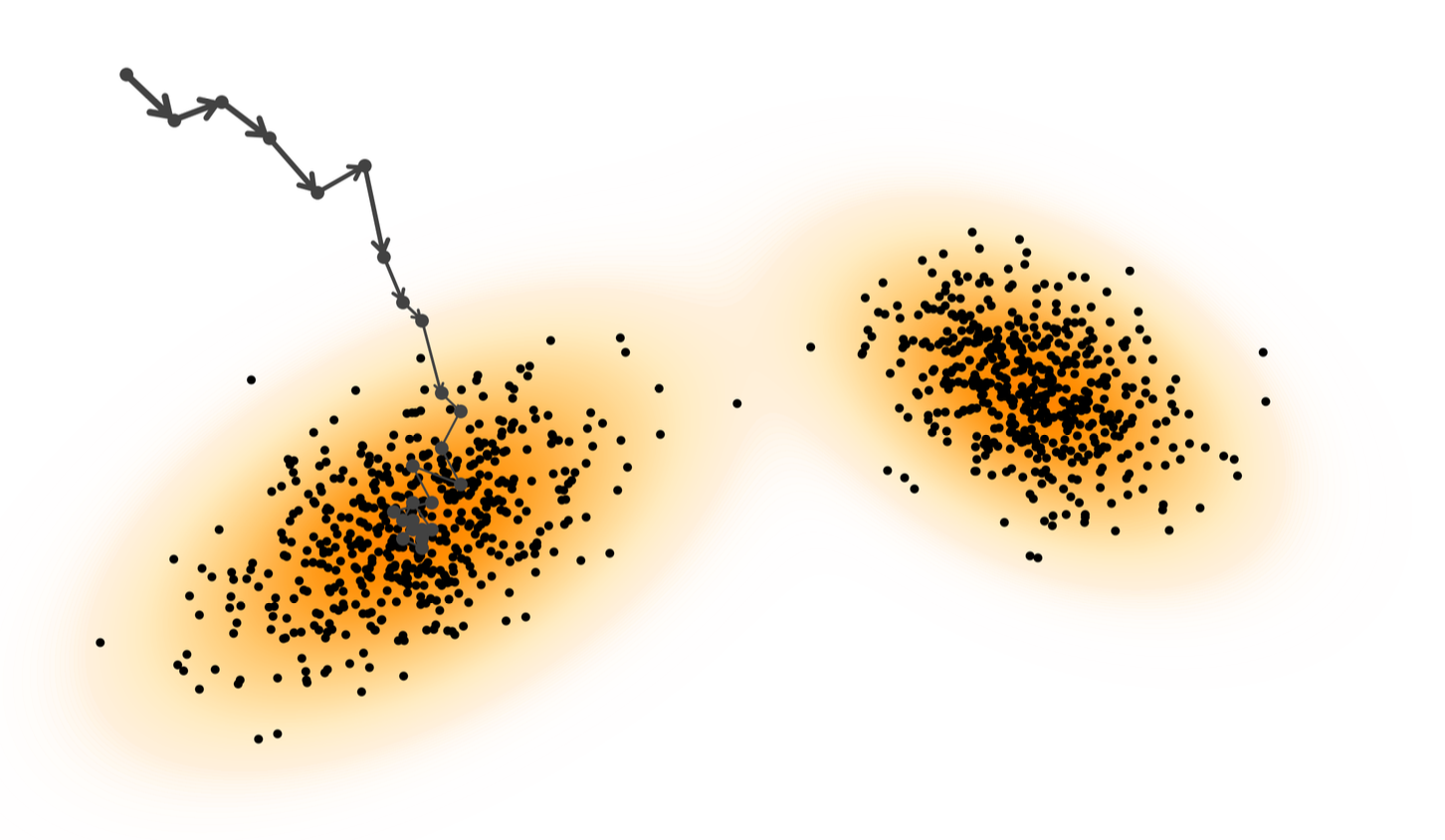
가장 본질적인 비효율성은 바로 mixing time이 매우 길어진다는 점이다. 실제 데이터 분포는 여러 개의 분리된 모드(mode) 를 가지는 경우가 많다.
이렇게 복잡하고 다중 모드(multimodality) 를 가진 분포에서는 Langevin 동역학이 한 고밀도 지역에서 다른 지역으로 넘어가려면 매우 긴 시간이 걸릴 수 있다.
이 문제는 차원이 높아질수록 극적으로 악화된다. 그 결과, Langevin 샘플링은 전체 분포를 충분히 탐색하지 못하고, 특정 영역 주변만 빈번하게 탐색하는 경향을 보이게 된다.
이러한 비효율성은 순전히 무작위적 탐색에 의존하는 방식보다, 더 구조화되고 안내된(guided) 샘플링 방법이 필요함을 시사한다. 즉, 복잡한 데이터 manifold를 더 효과적으로 탐색할 수 있는 새로운 샘플링 기법이 요구된다는 의미이다.
✅ 요약
EBM(Energy-Based Model)은 에너지 함수 Eϕ(x) 를 통해 확률분포를 정의하며, 데이터가 존재하는 영역의 에너지를 낮추는 방식으로 분포를 모델링한다. 확률밀도는
pϕ(x)=Zϕexp(−Eϕ(x))
로 주어지지만, 정규화 상수 Zϕ는 고차원에서 계산이 거의 불가능하다. 따라서 EBM에서 최대우도(MLE) 학습은 근본적으로 어려운 문제이며, 이를 우회하기 위해 다양한 방법이 제안되었다.
이 과정에서 핵심 역할을 하는 개념이 바로 score, 즉 로그 밀도의 기울기인
s(x)=∇xlogp(x)
이다. Score의 중요한 특징은 정규화 상수와 무관하게 계산할 수 있다는 점이며, 이는 p(x) 대신 비정규화된 p~(x)=exp(−Eϕ(x))를 사용해도 score를 그대로 얻을 수 있음을 의미한다. 또한 score field는 분포 자체를 완전히 복원할 수 있을 정도로 충분한 정보를 담고 있어, 밀도 함수 대신 score를 모델링하는 것이 이론적으로도 정당화된다.
Score Matching은 바로 이 점을 활용하여, 복잡한 분배함수 계산 없이 score 자체를 맞추도록 학습하는 방법이다. Hyvärinen의 결과에 따르면,
데이터 score를 직접 계산하지 않고도 손실 함수를
형태로 변형할 수 있다. 이는 분배함수 계산이나 샘플링 없이도 학습이 가능하다는 강점을 갖지만, 헤시안(Hessian)을 계산해야 하는 실질적 부담 때문에 고차원에서는 비효율적이라는 한계도 존재한다.
한편, EBM에서 샘플을 생성하는 주요 방법인 Langevin Dynamics는
xn+1=xn−η∇xEϕ(xn)+2ηϵn
과 같은 형태로 에너지 기울기를 따라가며 확률적 노이즈를 섞어 탐색을 수행한다. 연속 시간으로 보내면 이는 확률 미분방정식(SDE)이 되며, 그 해의 분포는 Fokker–Planck 방정식을 통해 pϕ(x)∝e−Eϕ(x) 로 수렴함이 보장된다.
그러나 Langevin Dynamics는 고차원에서 mixing time이 매우 길어지고, 스텝 크기 ⋅ 노이즈 크기 ⋅ 반복 횟수 등에 민감해 효율적이지 못하다는 심각한 한계를 갖는다. 특히 분포가 여러 모드로 분리된 경우, 한 모드에서 다른 모드로 이동하는 데 매우 오랜 시간이 걸리며, 이는 실제 생성 모델링에서 큰 제약으로 작용한다.
이러한 문제들은 완전히 무작위적 탐색에 의존하는 기존 EBM 샘플링 방식이 구조화된(guided) 생성 과정을 필요로 한다는 사실을 드러냈고, 이는 결국 score-based diffusion 모델의 등장을 촉발하게 되었다. Diffusion 모델은 여러 노이즈 레벨에서의 score field를 학습하여 안정적이고 효율적인 생성 경로를 구성하며, 결과적으로 현대 생성 모델의 핵심 패러다임으로 자리 잡았다.
📄 출처
[1] Lai, Chieh-Hsin, et al. The Principles of Diffusion Models. arXiv, 24 Oct. 2025, arXiv:2510.21890.