🤗 소개
복잡한 데이터를 기존의 일반적인 VAE보다 더 높은 성능으로 모델링하기 위해 도입된 계층형 변분 오토인코더(Hierarchical VAE; HVAE) 는 기존 VAE 구조에 여러 단계의 잠재 변수 계층(latent hierarchy) 을 추가한다.
이러한 깊고 층층이 쌓인 구조 덕분에 모델은 데이터 속 다양한 수준의 abstract한 특성을 동시에 포착할 수 있으며, 이는 모델의 표현력을 크게 확장 시키는 효과를 낸다. 결과적으로 HVAE는 현실 세계 데이터가 본질적으로 갖는 구성적 구조를 더 잘 반영할 수 있게 된다.
이번 글에서는 일반적인 VAE의 개념을 확장하여 HVAE의 전반적인 내용을 심층적으로 다뤄보고자 한다.
🌄 VAE부터 HVAE까지
이전 글에서 다루었듯이, VAE(Variational Autoencoder) 는 데이터를 저차원의 잠재 공간(latent space)에 확률적으로 압축하고, 그 잠재 변수를 다시 복원하는 방식으로 새로운 데이터를 생성할 수 있는 확률적 생성 모델이다. 인코더는 입력을 잠재 분포로 변환하고, 디코더는 그 분포에서 샘플링한 값을 이용해 원본 데이터를 재구성한다.
직접 계산하기 어려운 로그 가능도 대신 ELBO라는 하한을 최대화하며 학습하며, 이를 통해 데이터의 구조를 학습하고 새로운 샘플까지 만들어낼 수 있는 간단하면서도 강력한 생성 모델이다.
⛔ 표준 VAE의 한계
표준 VAE는 단일 잠재 공간에 모든 정보를 압축하려다 보니 복잡한 데이터의 다계층적 구조를 충분히 표현하지 못한다는 근본적 한계를 가진다.
특히 서로 다른 입력들이 latent space에서 쉽게 겹침(overlap) 으로 인해, 디코더는 해당 영역에 대해 여러 가능한 데이터를 평균낸 출력(mean outputs) 을 만들어내며, 그 결과 생성 이미지가 흐릿하고(blurred) 세밀한 구조를 포착하지 못한다.
또한 단일 층의 잠재 변수만으로는 고수준 의미(semantic structure) 와 저수준 세부 정보(low-level details) 를 동시에 모델링하기 어렵기 때문에, 복잡한 분포를 제대로 학습하지 못하는 문제가 발생한다.
이러한 한계가 HVAE가 등장하게 된 핵심 동기 이며, HVAE는 여러 계층의 latent 변수 를 도입하여 데이터의 다양한 수준의 추상화와 구조를 계층적으로 분리해 표현할 수 있도록 설계되었다.

1️⃣ HVAE 모델링
표준 VAE가 하나의 latent code z만 사용하는 것과 달리, 계층형 VAE(HVAE)는 여러 개의 잠재 변수를 top-down 계층 구조 로 배치한다.
각 잠재 계층은 바로 아래 계층을 조건부로 결정하며, 이렇게 연결된 조건부 prior의 사슬(chain of conditional priors) 은 데이터의 구조를 점점 더 섬세하고 다양한 추상화 수준에서 포착할 수 있게 한다.
이러한 계층적 생성 과정은 다음과 같은 top-down 형태의 결합 분포 분해 로 표현된다.
pϕ(x,z1:L)=pϕ(x∣z1)i=2∏Lpϕ(zi−1∣zi)p(zL)
이 구조를 통해 주변 데이터 분포(marginal data distribution) 를 다음과 같이 정의할 수 있다.
pHVAE(x):=∫pϕ(x,z1:L)dz1:L
생성 과정은 단계정으로 진행된다. 가장 위 계층의 잠재 변수 zL에서 시작해, 각 잠재 변수를 차례차례 아래 계층의 z1까지 decoding한 뒤, 마지막으로 관측 데이터 x를 생성한다.
인코딩(encoding) 단계에서 HVAE는 생성 과정의 계층 구조를 그대로 반영한 구조적이고 learnable한 변분 인코더 qθ(z1:L∣x)를 사용한다. 일반적으로는 bottom-up 방식의 Markov 분해(factorization) 를 활용하며, 이는 다음과 같이 표현된다.
qθ(z1:L∣x)=qθ(z1∣x)i=2∏Lqθ(zi∣zi−1)
2️⃣ HVAE의 ELBO
표준 VAE의 ELBO와 비슷하게, HVAE의 ELBO 또한 얀센 부등식(Jensen's Inequality) 로부터 시작하여 유도할 수 있다.
logpHVAE(x)=log∫pϕ(x,z1:L)dz1:L=log∫qθ(z1:L∣x)pϕ(x,z1:L)qθ(z1:L∣x)dz1:L=logEqθ(z1:L∣x)[qθ(z1:L∣x)pϕ(x,z1:L)]≥Eqθ(z1:L∣x)[logqθ(z1:L∣x)pϕ(x,z1:L)]=:LELBO(ϕ)
pϕ(x,z1:L)와 qθ(z1:L∣x) 의 분해된 형태를 ELBO 식에 대입하면 다음과 같다.
LELBO=Eqθ(z1:L∣x)[logqθ(z1∣x)∏i=2Lqθ(zi∣zi−1)p(zL)∏i=2Lpϕ(zi−1∣zi)pϕ(x∣z1)]
이 계층형 ELBO는 재구성 항(reconstruction term)과 더불어, 각 계층의 생성 조건분포 와 그에 대응하는 변분 근사 분포 사이의 KL 발산 항들로 깔끔하게 분해되며, 이런 구성 덕분에 각 항을 직관적으로 이해할 수 있다.
⭐ HVAE의 의의
HVAE는 깊고 층층이 쌓인 잠재 구조를 활용해 데이터를 생성하는 방식이 얼마나 강력한지를 보여주었고, 이러한 계층적(hierarchical) 설계 철학 은 이후 현대 생성 모델의 핵심 개념으로 자리 잡았다.
이를 통한 핵심적인 통찰은 단순하지만 매우 강력하다.
여러 계층을 쌓아올리면, 모델은 거친(coarse) 윤곽에서 시작해 단계마다 더 세밀한 정보를 추가하는 점진적(progressive) 생성 과정 을 수행할 수 있다.
이러한 생성 방식은 고차원 데이터가 가진 복잡한 구조를 훨씬 더 쉽게 포착할 수 있게 해준다.
3️⃣ 표준 VAE에서 깊은 인코더/디코더의 한계
표준적인 평면(flat) VAE에는 인코더와 디코더를 아무리 깊게 만들어도 해결되지 않는 두 가지 근본적인 한계 가 존재한다.
🔒 첫 번째 한계 – Unimodal Gaussian
첫 번째 한계는 변분 분포(variational family) 자체에 있다. 표준 VAE에서 인코더 분포는
qθ(z∣x)=N(z;μθ(x),diag(σθ2(x)))
이므로, 주어진 x에 대해 인코더가 표현할 수 있는 posterior는 대각 공분산을 가진 단일 Gaussian 하나뿐이다. 네트워크를 깊게 만들어 μθ와 σθ의 표현력이 좋아진다 하더라도, 분표의 형태 자체 는 변하지 않는다.
대각이 아니라 완전한(full) 공분산을 허용하더라도, 결국 posterior는 하나의 단봉(unimodal) 타원체(ellipsoid) 에 불과하다.
하지만 실제 pθ(z∣x)가 여러 개의 봉우리를 가진(multi-peaked) 복잡한 분포라면 이런 단일 Gaussian family는 이를 제대로 근사할 수 없다. 그 결과 ELBO는 더 느슨해지고, 추론 품질도 떨어질 수 밖에 없다.
즉, 이 문제를 해결하려면 단순히 네트워크를 깊게 하는 것이 아니라, posterior 자체의 표현력을 확장한 더 풍부한 분포의 함수족(family)이 필요하다.
💥 두 번째 한계 – Posterior Collapse
두 번째 한계는 디코더(decoder) 가 지나치게 강력할 때 발생하는 posterior collapse 문제이다. 왜 이런 현상이 생기는지 이해하기 위해, VAE의 목적함수를 다시 살펴보자.
Epdata(x)[LELBO(x)]=Epdata(x)qθ(z∣x)[logpϕ(x∣z)]−Epdata(x)[DKL(qθ(z∣x)∣∣p(z))]=Epdata(x)qθ(z∣x)[logpϕ(x∣z)]−Iq(x;z)−DKL(qθ(z)∣∣p(z))
여기서 Iq(x;z)는 다음과 같이 정의되는 상호정보량(mutual information) 이다.
Iq(x;z)=Eq(x,z)[logq(z)qθ(z∣x)]=Epdata(x)DKL(qθ(z∣x)∣∣q(z))
여기서 q(z)는 aggregated posterior 즉, q(z)=∫pdata(x)qθ(z∣x)dx이다.
만약 디코더가 z를 사용하지 않고도 데이터를 충분히 잘 모델링할 수 있다면, 즉 pϕ(x∣z)안에 pdata(x)와 거의 동일한 r(x)가 포함되어 있다면, ELBO를 최대화하는 해는
qθ(z∣x)=p(z)
가 된다. 이 경우 상호정보량 Iq(x;z)=0이며, aggregated posterior도 qθ(z)=p(z)가 된다.
이러한 "z를 무시하는" 해는 네트워크를 아무리 깊게 만들어도 사라지지 않는다.
1. 학습된 잠재 코드는 x와 독립적 이게 되어, 이후 작업에 유용한 데이터의 의존적 구조를 전혀 담지 못한다.
2. 생성 과정에서 x를 바꾸거나 조건을 걸어도 출력이 전혀 변하지 않기 때문에, 원하는 방식으로 제어 가능한 생성(controllable generation)이 불가능 해진다.
4️⃣ 계층 구조가 가져오는 변화
HVAE는 여러 개의 잠재 수준(latent levels)를 도입한다.
pϕ(x,z1:L)=pϕ(x∣z1)i=2∏Lpϕ(zi−1∣zi)p(zL)
이에 대응하는 ELBO는 다음과 같다.
LELBO(x)=Eq[logpϕ(x∣z1)]−Eq[DKL(qθ(z1∣x)∣∣pϕ(z1∣z2))]−i=2∑L−1Eq[DKL(qθ(zi∣zi−1)∣∣pϕ(zi∣zi+1))]−Eq[DKL(qθ(zL∣zL−1)∣∣p(zL))]
여기서 Eq=Epdata(x)qθ(z1:L∣x)라고 표기하였다.
각 추론 조건부 분포(inference conditional)는 위에서 아래로 내려오는 생성 조건부 분포와 정확히 짝 을 이룬다.
- 최하위 계층 qθ(z1∣x)↔pϕ(z1∣z2)
- 중간 계층 qθ(zi∣zi−1)↔pϕ(zi∣zi+1)
- 최상위 계층 qθ(zL∣zL−1)↔p(zL)
이 구조는 정보 페널티가 계층 간에 분산되도록 만들며, 인접한 KL 항을 통해 학습 신호가 각 계층에 local하게 전달 된다.
이러한 성질들은 단순히 flat VAE를 더 깊게 쌓는 것으로는 얻을 수 없으며, 계층적 잠재 그래프(hierarchical latent graph) 에서 비롯되는 고유한 특성이다.
5️⃣ HVAE의 한계
HVAE는 표현력을 높이기 위해 여러 층의 잠재 변수를 도입하여 VAE의 구조를 확장하지만, 그만큼 특유의 학습적 어려움 을 안고 있다.
인코더와 디코더를 동시에 최적화해야 하므로 학습이 불안정 해지기 쉽다. 예를 들어, 낮은 층(lower-level latents)과 디코더만으로도 입력 x를 충분히 복원할 수 있게 되면, 더 높은 층의 잠재 변수(higher-level latents)는 유의미한 신호를 거의 받지 못하게 된다.
또한, 더 깊은 계층에 도달하는 gradient 신호는 간접적이고 약해지기 때문 에 이러한 higher-level 잠재 변수들이 학습 과정에서 제대로 기여하기가 어렵다.
여기에 더해 모델의 capacity 균형 또한 까다롭다. 조건부 분포들이 지나치게 표현력이 커지면 재구성 작업을 사실상 lower-level 계층이 모두 처리 해 버려 higer-level 잠재 변수의 역할을 약화시키는 문제가 발생한다.
흥미롭게도, 이렇게 깊고 층층이 쌓인 계층 구조의 핵심 아이디어는 이후 Diffusion 모델 에서 더욱 강력한 형태로 재탄생한다. Diffusion 모델은 HVAE의 점진적 생성 구조(progressive hierarchy) 는 그대로 계승하면서도, 그 취약점들은 참신하게 회피한다.
특히 인코딩 과정을 고정(fixed) 해두고 생성(reverse) 과정만 학습함으로써 학습의 안정성과 모델링 유연성을 동시에 확보해 생성 품질의 획기적인 도약을 이룬다.
✅ 요약
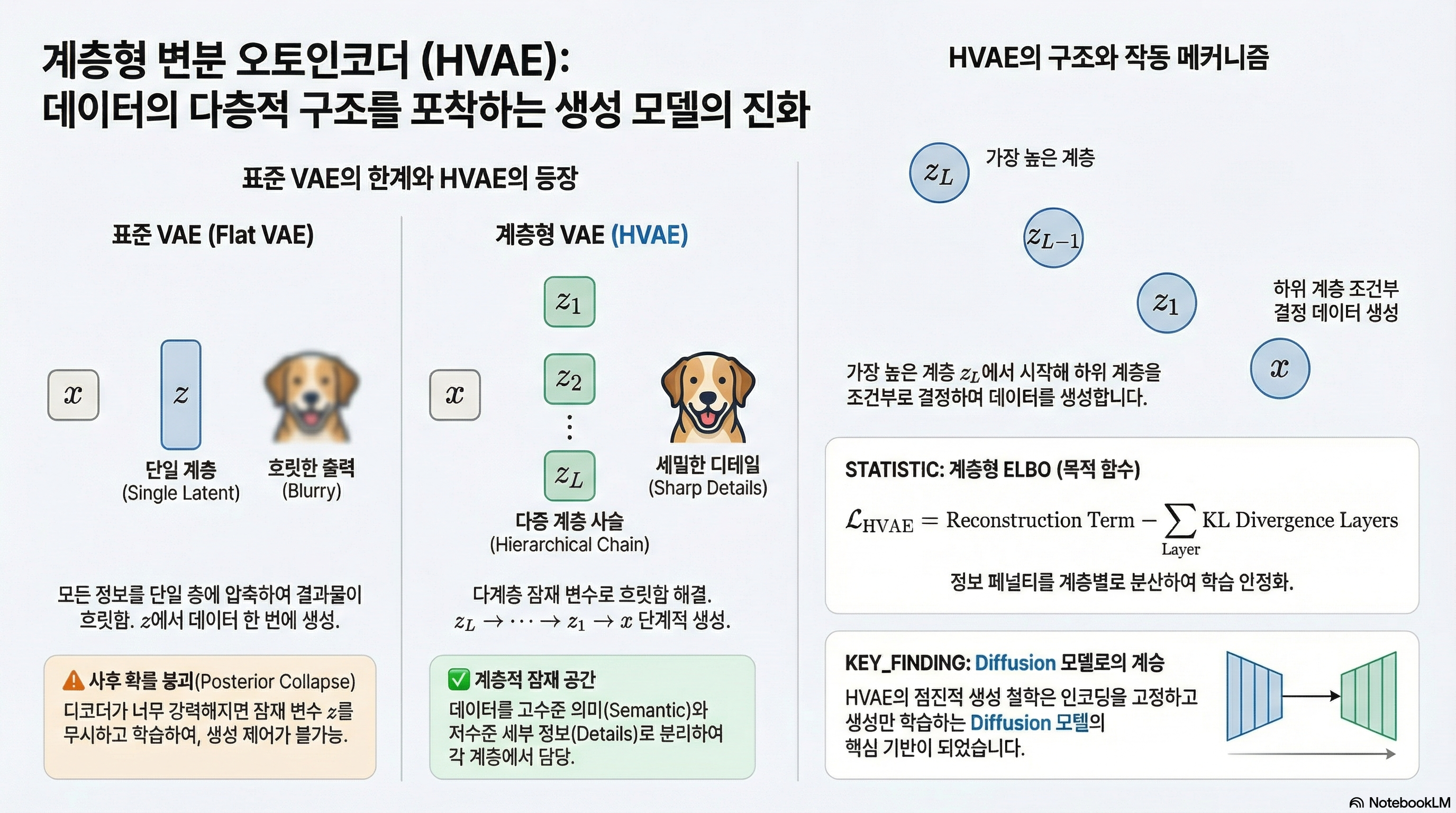
HVAE는 단순히 VAE를 깊게 쌓은 형태가 아니라, 잠재 변수를 계층적으로 조직 하여 고차원 데이터의 다층적 구조를 효과적으로 포착 하는 모델이다. 이러한 구조 덕분에 표준 VAE가 가진 두 가지 근본적 한계인 단일 가우시안 posterior의 표현력 부족과 posterior collapse 를 구조적으로 완화할 수 있다.
하지만 HVAE 또한 학습 신호의 약화, 계층 간 불균형, 용량 조절의 어려움 같은 고유한 문제들을 가진다. 특히 높은 계층(latent high levels)이 충분한 학습 신호를 받지 못해 의미 있는 표현을 배우지 못하는 문제가 자주 발생한다.
이러한 한계들을 넘어가기 위해, HVAE의 핵심 아이디어였던 점진적 ⋅ 계층적 생성 방식은 이후 Diffusion 모델 에서 더욱 강력한 형태로 재해석된다. Diffusion 모델은 인코딩 과정을 고정시키고, 생성(reverse) 과정만 학습하는 방식으로 HVAE의 취약점들을 피해가며 안정적이고 유연한 모델링 능력을 확보했다. 이는 현대 생성 모델링에서 큰 도약을 이루는 기반이 된다.
📄 출처
[1] Lai, Chieh-Hsin, et al. The Principles of Diffusion Models. arXiv, 24 Oct. 2025, arXiv:2510.21890.

