에너지 기반 모델(EBM) 은 생성이 정규화된 전체 확률 밀도가 아니라, 확률이 더 높은 영역을 가리키는 score에만 의존한다는 점을 보여준다. Score matching은 정규화 상수(partition function)를 피할 수 있지만, 에너지를 통해 학습하는 방식은 여전히 비용이 큰 second-order derivative 를 필요로 한다.
이에 대한 핵심 아이디어는 Langevin dynamics를 이용한 샘플링이 score만을 필요로 한다는 점에 있다. 따라서 신경망을 이용해 이 score를 직접 학습할 수 있다. 에너지를 모델링하는 관점에서 score를 모델링하는 관점으로의 이러한 전환이 바로 score-based generative model의 기반 을 이룬다.
🏹 본격적인 Score Matching
1️⃣ Score Matching으로 학습하기
🎯 Score Matching
데이터 분포 pdata(x)로부터의 샘플을 이용해 score 함수 s(x)=∇xlogpdata(x)를 근사하기 위해 이를 신경망으로 paraterized된 벡터장sϕ(x)로 직접 근사한다.
sϕ(x)≈s(x)
Score matching은 이 벡터장을 실제 score과 추정된 score 사이의 다음과 같은 평균제곱오차(MSE) 를 최소화함으로써 학습한다.
LSM(ϕ):=21Ex∼pdata[∥sϕ(x)−s(x)∥22]
🕹️ Tractable한 Score Matching
겉으로 보기에는 이 목적 함수는 intractable해 보인다. 그 이유는 회귀의 목표로 사용되는 실제 score s(x)가 알려져있지 않기 때문이다. 그러나 다행히도 Hyvärinen과 Dayan(2005)는 부분적분 을 적용하면, 실제 score에 접근하지 않고도 모델 sϕ와 데이터 샘플에만 의존하는 동등한 목적 함수를 얻을 수 있음을 보였다. 이에 대한 증명은 이전 글에서 자세히 다루었으니 참고하면 좋을 듯 하다.
명제 3.2.1 – Hyvärinen의 Tractable한 Score Matching 형태
Score matching의 일반적인 목적 함수를 다음과 같이 서술할 수 있다.
이며, C는 ϕ에 의존하지 않는 상수이다, 이 목적 함수의 최소해 s∗는 다음과 같이 주어진다 s∗(⋅)=∇xlogp(⋅).
위 식에 주어진 동등한 목적 함수를 사용하면, 실제 score 함수에 대한 접근 없이도 관측된 데이터 분포 pdata의 샘플만을 이용해 score 모델 sϕ(x)를 학습할 수 있다.
💡 Tractable한 Score Matching 형태에 대한 직관
Score matching 목적 함수의 대안 L~SM(ϕ)는 그 안에 포함된 두 항을 통해 직접적으로 이해할 수 있다.
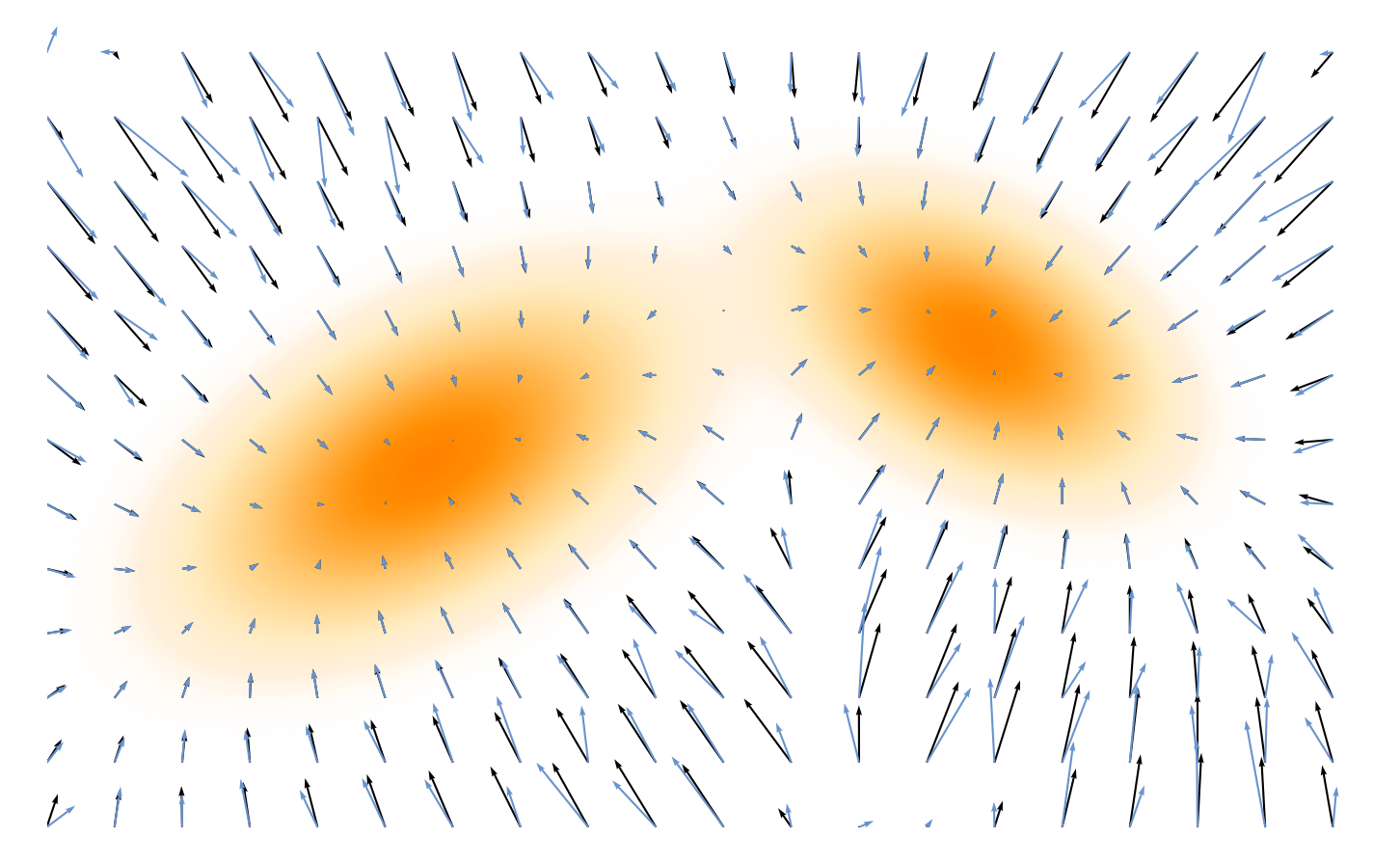
노름 항 21∥sϕ(x)∥22는 pdata가 큰 영역에서 score을 억제하여, 해당 지점들이 정류점(stationary point) 이 되도록 만든다. 발산 항 Tr(∇xsϕ(x))는 음의 값을 선호하므로, 이러한 정류점들을 끌어당기는 일종의 sink로 작용하게 된다.
이 두 항이 함께 작용함으로써, 손실 함수는 높은 밀도를 가진 영역을 score field 상에서 안정적이며 수축하는 점 들로 형성한다. 아래에서 좀 더 자세히 살펴보도록 하자.
✋🏻 크기 항에 의한 정류성(Stationarity)
L~SM(ϕ)에서의 기댓값은 pdata에 대애 취해지므로, pdata가 큰 영역, 즉 데이터 밀도가 높은 영역이 손실에 가장 크게 기여하게 된다. 따라서 크기(magnitude) 항 21∥sϕ(x)∥22는 이러한 높은 확률 영역에서 sϕ(x)→0이 되도록 유도하며, 그 결과 해당 위치들은 정류점이 된다.
🥣 벡터장이 근사적으로 그래디언트일 때의 오목성(Concavity)
발산항 Tr(∇xsϕ(x))은 데이터 밀도가 높은 영역에서 벡터장이 음의 발산(negative divergence) 을 갖도록 유도한다. 음의 발산은 인접한 벡터들이 퍼지기보다는 서로 수렴함을 의미하므로, 이러한 영역에 존재하는 정류점들은 앞서 언급한 일종의 sink 로 작용하게 된다.
즉, 주변의 궤적들이 안쪽으로 끌려 들어간다. 이를 엄밀히 하기 위해 로그 밀도를 맞추는 상황에서 자연스럽게 sϕ=∇xu라고 가정하자. 여기서 u:RD→R는 스칼라 함수이다.
그러면 ∇xsϕ=∇x2u는 헤시안(Hessian)이고, ∇⋅sϕ(x)=Tr(∇x2sϕ(x))는 발산이 된다.
정류점 x⋆에서 sϕ(x⋆)=∇xu(x⋆)=0라고 하면, 2차 테일러 전개를 통해
만약 헤시안 ∇x2u(x⋆)가 음의 정부호 라면(≺0), u는 x⋆에서 국소적으로 오목(concave) 하며 로그 밀도는 그 지점에서 엄격한 국소 최대값(strict local maximum)을 가진다. 헤시안의 모든 고유값이 음수이므로 그 대각합 역시 음수가 되어 Tr(∇x2u(x⋆))<0이다.
따라서 학습된 벡터장은 음의 발산을 가지며, 해당 정류점은 sink가 된다, 즉 작은 섭동(perturbations)들은 다시 x⋆ 방향으로 수축된다.
2️⃣ 랑주뱅 역학으로 샘플링하기
L~SM을 최소화하여 학습이 완료되면, score 모델 sϕ×(x)은 샘플링 과정에서 Langevin dynamics에 사용되는 oracle score을 대체할 수 있다.
xn+1=xn+ηsϕ×(x)=2ηϵn,ϵn∼N(0,I)
여기서 n=0,1,2,…이며 x0에서 초기화된다. EBM에 경우에서와 마찬가지로 이 점화식은 연속 시간 Langevin SDE의 Euler-Maruyama 이산화에 정확히 대응한다.
dx(t)=sϕ×(x(t))dt+2dw(t)
따라서 step-size(η)이 충분히 작아지는 극한(η→0)에서는, 이산적 공식과 연속적 공식이 서로 일치하게 된다. 실제로는 이산 샘플링을 수행하거나 혹은 해당 SDE를 직접 시뮬레이션하는 방식 중 하나를 택하면 된다.
✅ 요약
이 글에서는 EBM에서 출발해 score 함수가 생성 모델링의 핵심으로 자리잡게 되는 관점의 전환을 설명했다. 이어서 score matching과 그 tractable한 형태를 통해 실제 score를 알지 못하더라도 데이터 샘플만으로 score field를 학습할 수 있음을 보이고, 이렇게 학습된 score을 Langevin dynamics에 사용해 샘플링이 가능함을 설명하였다.
앞으로의 글에서는 현대적인 diffusion 모델에서 score 함수가 수행하는 근본적인 역할을 살펴볼 예정이다. 원래 score 함수는 에너지 기반 모델을 효율적으로 학습하기 위해 도입되었지만, 이후 새로운 세대의 생성 모델에서 핵심적인 구성 요소로 발전해 왔다. 이러한 기반 위에서, score 함수가 score 기반 diffusion 모델의 이론적 정식화와 실제 구현에 어떤 방식으로 반영되는지를 탐구하며, 확률적 과정을 통해 데이터를 생성하는 데에 관한 원리적인 틀을 제시할 예정이다.
📄 출처
[1] Lai, Chieh-Hsin, et al. The Principles of Diffusion Models. arXiv, 24 Oct. 2025, arXiv:2510.21890.