[C#/Unity] 게임 서버 #1 - 멀티스레드, 캐시, 메모리배리어
본 게시물은 Rookiss님의 '[C#과 유니티로 만드는 MMORPG 게임 개발 시리즈] Part4: 게임 서버' 강의를 듣고 정리한 내용임을 미리 알립니다.
멀티 스레드
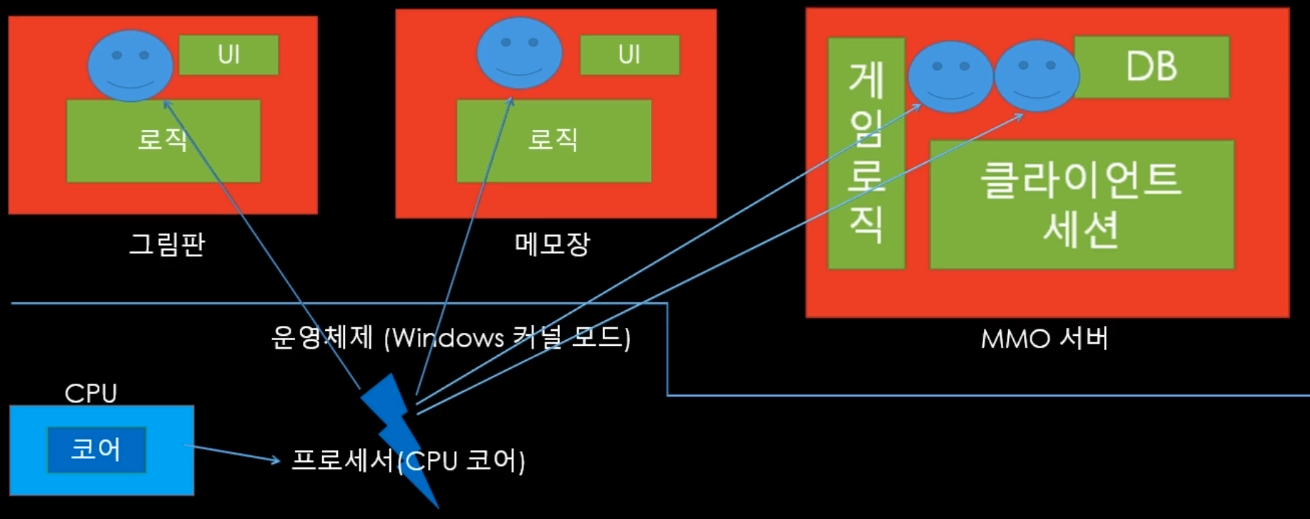
위의 그림을 보자. 번개 그림은 CPU 코어를, 웃는 얼굴은 프로그램을 수행하는 스레드를 뜻한다. 우리가 여러 프로그램을 한번에 실행할 수 있는 이유는, 한 코어가 여러 스레드에 빠른 속도로 옮겨다니며 일을 처리하기 때문이다. 코어를 스레드에 할당하는 일은 스케줄링이라 하며, 이것은 운영체제, 정확히는 커널에서 처리한다.
요즘은 CPU가 여러 코어를 달고 있는 멀티 코어지만, 스레드를 옮겨다니는 행위 자체가 큰 퍼포먼스를 잡아먹어, 무작정 스레드를 통해 작업을 분리하는 것이 좋은 방법은 아니다.
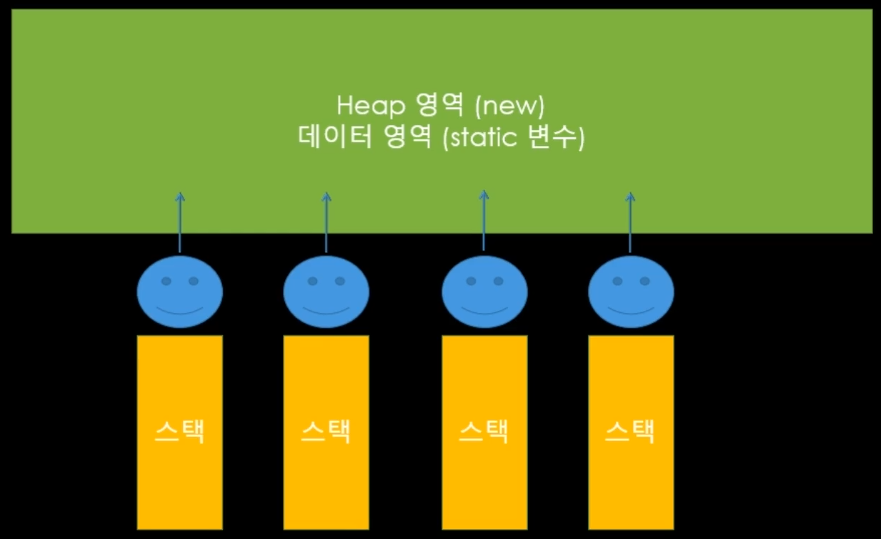
하지만 이 스레드들은 힙 영역과 데이터 영역을 공유하기 때문에, 이 공용 영역을 여러 스레드가 사용하면 관리가 어려워진다. 결국 여러 스레드들이 충돌이 나지 않고 잘 돌아가는 것이 우리의 목표이다.
스레드 생성
Thread 클래스
C#에서는 스레드를 어떻게 관리하는지 알아보자. 먼저 Thread 클래스를 이용해보자.
namespace ServerCore
{
class Program
{
static void MainThread(object state)
{
for (int i = 0; i < 5; i++)
{
Console.WriteLine("스레드 작동");
}
}
static void Main(string[] args)
{
Thread t = new Thread(MainThread);
t.IsBackground = true; // Foreground 스레드가 끝나면 같이 종료
t.Start();
Console.WriteLine("스레드 조인 대기중");
t.Join();
Console.WriteLine("스레드 조인 완료");
}
}
}Main 함수에서 Thread 객체인 t를 생성했다. 이것에 MainThread라는 메소드를 지정했다. Thread.Start 메소드를 통해 스레드를 시작해주었고, Thread.Join 메소드를 통해 스레드가 끝나기를 기다렸다.
ThreadPool 클래스
이 Thread 클래스는 원초적이고, 모든 스레드를 직접 관리해야해 불편함이 많다. 이럴 때 유용한 것이 ThreadPool 클래스다.
namespace ServerCore
{
class Program
{
static void MainThread(object state)
{
for (int i = 0; i < 5; i++)
{
Console.WriteLine("스레드 작동");
}
}
static void Main(string[] args)
{
// SetMinThreads, SetMaxThreads로 최소, 최대 스레드 개수를 지정할 수 있음. 두번째 인자는 IO 관련
ThreadPool.SetMinThreads(1, 1);
ThreadPool.SetMaxThreads(5, 5);
for (int i = 0; i < 5; i++)
{
ThreadPool.QueueUserWorkItem((obj) => { while (true) { } });
}
ThreadPool.QueueUserWorkItem(MainThread);
}
}
}ThreadPool 클래스는 마치 오브젝트 풀링처럼, 스레드들을 .Net Framework에서 저장했다 내놨다 하면서 관리해주는 클래스이다. 이 코드에서 ThreadPool.QueueUserWorkItem 메소드로, 다음 작업을 할 수 있는 스레드를 할당해준다. 물론 SetMinThreads, SetMaxThreads로 최소, 최대 스레드를 지정해주므로, 최대 스레드 이상을 넘어갈 때 스레드를 요청하면 스레드가 끝날 때까지 기다렸다가 할당해준다. 따라서 금방 일이 끝난다는 보장이 있으면 좋지만, 아니라면 스레드 할당을 보장받지 못한다. 위의 코드에서 ThreadPool.QueueUserWorkItem(MainThread);로 요청한 스레드는 최대 스레드 수를 초과했기 때문에 할당받지 못한다.
Task 클래스
이런 단점을 보완한 것이 Task 클래스다.
namespace ServerCore
{
class Program
{
static void MainThread(object state)
{
for (int i = 0; i < 5; i++)
{
Console.WriteLine("스레드 작동");
}
}
static void Main(string[] args)
{
Task t = new Task(() => { while (true) { } }, TaskCreationOptions.LongRunning);
ThreadPool.SetMinThreads(1, 1);
ThreadPool.SetMaxThreads(5, 5);
for (int i = 0; i < 5; i++)
{
ThreadPool.QueueUserWorkItem((obj) => { while (true) { } });
}
ThreadPool.QueueUserWorkItem(MainThread);
while (true) { }
}
}
}Task 클래스는 ThreadPool을 활용한 스레드 객체다. 새 Task 객체 생성 시, ThreadPool에서 스레드를 가져오게 된다. 물론 이것도 ThreadPool의 스레드 개수를 넘어가면 대기한다. 하지만 위의 코드처럼 TaskCreationOptions.LongRunning을 인자로 써주면 ThreadPool의 개수와 관계없이 새로운 스레드를 생성한다. 이번 코드의 ThreadPool.QueueUserWorkItem(MainThread);는 스레드가 제대로 할당이 된다.
컴파일러의 코드 최적화
다음의 코드를 보자.
namespace ServerCore
{
class Program
{
/*volatile*/ static bool _stop = false;
static void ThreadMain()
{
Console.WriteLine("스레드 시작");
while (_stop == false)
{
}
Console.WriteLine("스레드 종료");
}
static void Main(string[] args)
{
Task t = new Task(ThreadMain);
t.Start();
Thread.Sleep(1000); // 1초 동안 슬립해 스레드가 충분히 실행될 시간 제공
_stop = true;
Console.WriteLine("stop 호출");
Console.WriteLine("종료 대기중");
t.Wait();
Console.WriteLine("종료 성공");
}
}
}Task t 객체를 통해 ThreadMain 함수를 새 스레드로 할당한다. 이후 t를 시작하고, 메인 스레드가 1초 Sleep해 t 객체가 실행될 시간을 충분히 준다. _stop 변수를 true가 되면, "스레드 종료"가 출력된다.
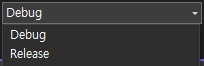
Visual Studio에서 Debug 모드에서는 잘 출력되지만, 이를 Release 모드로 바꾸면 "스레드 종료"가 절대 출력되지 않는다. 이는 왜일까?
Release 모드에서는 컴파일러가 자체적으로 코드 최적화를 진행한다. 위 코드에서 while문 안에서 _stop 변수가 변하는 것이 없기 때문에, 컴파일러가 자체적으로 _stop의 변화를 감지하지 않게 코드를 변경한다.
if (_stop == false)
{
while (true)
{
}
}위의 while문은 다음과 같이 변경되어 있다. 컴파일러는 기본적으로 멀티스레드를 고려하지 않고 코드를 재구성하기 때문에, _stop이 밖에서 바뀔 수도 있다는 것을 알지 못한 것이다.
volatile 키워드
이럴 때 volatile 키워드를 변수에 추가하면, 컴파일러가 자체적으로 관련 코드를 재구성하지 않는다. volatile은 키워드는 컴파일러에게 이 변수는 최적화하지 말라고 명령하는 것이다. 또한 '변수의 캐시를 무시하고 최신의 값을 가져와라' 라는 의미도 추가한다. 근데 C#에서는 다소 이상하게 동작해 전문가들이 사용을 지양한다고 한다.
volatile static bool _stop = false;이렇게 _stop 변수의 선언을 바꿔주면, Release 모드여도 "스레드 종료"가 잘 출력된다.
지금은 volatile 키워드에 집중하는 것이 아니라, Release 모드에서 코드 최적화 등으로 멀티스레드 상황에서 다양한 문제가 생길 수 있다는 걸 알아두자. 후에 메모리 배리어, 락 등으로 해결할 수 있다.
캐시
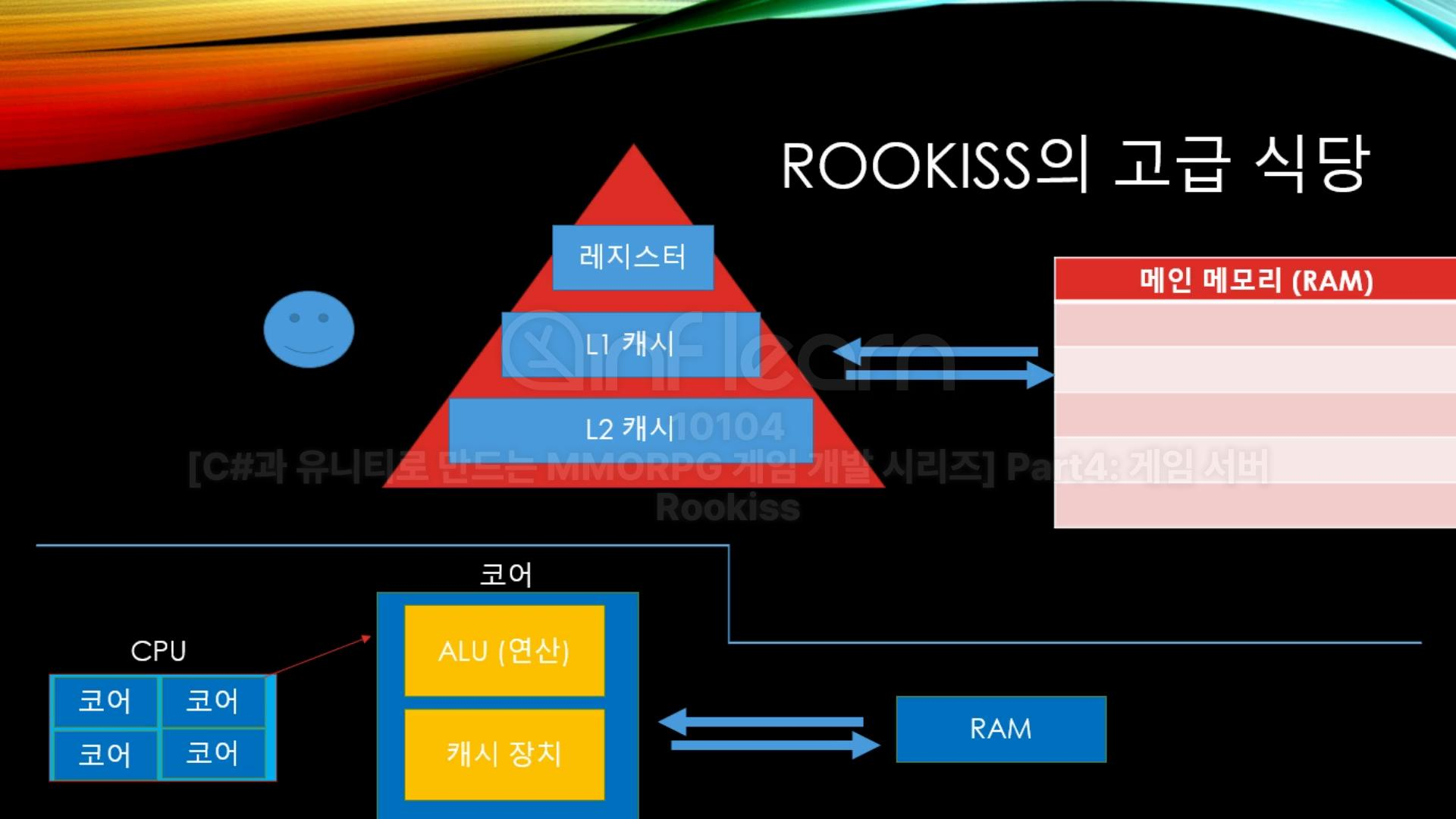
CPU의 코어는 각각 ALU(연산장치), 캐시 장치를 가지고 있다. 캐시 장치는 중요한 정보를 저장하는 공간으로, 레지스터, L1 캐시, L2 캐시로 구성되어 있다. 램에 바로 정보를 올리지 않고, 잠시 캐시 장치에 저장을 해놨다가 한꺼번에 램으로 갱신하는 작업이다.
결국 스레드에서 캐시에 있는 변수를 바꿨다고 해서, 그게 무조건 바뀐다고 확정지을 수 없다는 것이 핵심이다.
캐시의 지역성
캐시는 무척 작은 용량이기 때문에 캐시에 어떤 정보가 들어갈지 잘 정하는 것이 중요하다. 캐시의 지역성은 이때 어떤 정보를 담을지 정하는 방식이다.
시간적 지역성(Temporal Locality)
시간적 지역성은 방금 접근한 그 변수를 또 요청할 확률이 높다고 생각하는 방식이다.
공간적 지역성(Spatial Locality)
공간적 지역성은 방금 접근한 변수와 인접한 곳이 확률이 높다고 생각하는 지역성이다. 오름차순, 내림차순으로 각 변수를 접근한다면 효율이 크게 증가한다.
예제
지역성을 예제를 통해 체감해보자.
namespace ServerCore
{
class Program
{
static void ThreadMain()
{
int[,] arr = new int[10000, 10000];
// [[], [], [], [] ,[]], [[], [], [], [] ,[]], [[], [], [], [] ,[]], [[], [], [], [] ,[]], [[], [], [], [] ,[]]
// 얘는 연속적으로 접근하기 때문에 캐시의 지역성 때문에 빠름
{
long start = DateTime.Now.Ticks;
for (int y = 0; y < 10000; y++)
{
for (int x = 0; x < 10000; x++)
{
arr[y, x] = 1;
}
}
long end = DateTime.Now.Ticks;
Console.WriteLine($"(y, x) 순서 걸린 시간 {end - start}");
}
// 얘가 더 느림
// 이유는 캐시의 지역성 때문
{
long start = DateTime.Now.Ticks;
for (int y = 0; y < 10000; y++)
{
for (int x = 0; x < 10000; x++)
{
arr[x, y] = 1;
}
}
long end = DateTime.Now.Ticks;
Console.WriteLine($"(y, x) 순서 걸린 시간 {end - start}");
}
}
}
}위 코드는 각각 똑같은 작업을 반복하지만, 위 블록은 배열의 두번째 요소부터, 아래 블록은 배열의 첫번째 요소부터 변경이 된다. 2차원 배열은 두번째 요소들이 먼저 배치되고 첫번째 요소가 변경되는 방식으로 메모리에 할당된다. 따라서 위 블록이 오름차순으로 메모리를 접근하기 때문에, 여기서 캐시의 지역성이 유효하게 작용한다.

결국 위 블록의 실행시간이 훨씬 빠르다는 것을 알 수 있다.
메모리 배리어
CPU의 코드 재배치
위의 컴파일러 코드 최적화에서 컴파일러가 재구성한 코드가 오류를 발생하는 경우를 보았다. 하지만 컴파일러뿐만 아니라 하드웨어도 이런 신기한 현상을 만들어낸다. 다음의 코드를 보자.
namespace ServerCore
{
class Program
{
static int x = 0;
static int y = 0;
static int r1 = 0;
static int r2 = 0;
static void Thread_1()
{
y = 1; // Store y
r1 = x; // Load x
}
static void Thread_2()
{
x = 1; // Store x
r2 = y; // Load y
}
static void Main(string[] args)
{
int count = 0;
while (true)
{
count++;
x = y = r1 = r2 = 0;
Task t1 = new Task(Thread_1);
Task t2 = new Task(Thread_2);
t1.Start();
t2.Start();
Task.WaitAll(t1, t2);
if(r1 == 0 && r2 == 0)
{
break;
}
}
}
}
}t1와 t2 Task 객체에 각각 Thread_1, Thread_2 메소드를 넣어 스레드로 할당한다. 이 스레드들을 시작하고 r1과 r2가 둘다 0이여야 끝내라고 지시하자. 과연 이 코드는 끝날 수 있을까?
평범하게 생각해보면, t1과 t2가 어떤 순서로 실행되더라도 r1과 r2 중 하나는 1이 되어야 한다. 따라서 while에서 빠져나가지 못할 것이라고 예상하지만, 빠져나가진다. 왜일까?
우리의 CPU는 코드를 코드대로 받아들이지 않고, 자신이 봤을 때 서로 의존성이 없는 코드라고 판단하면, 코드의 순서를 뒤바꾸기도 한다.
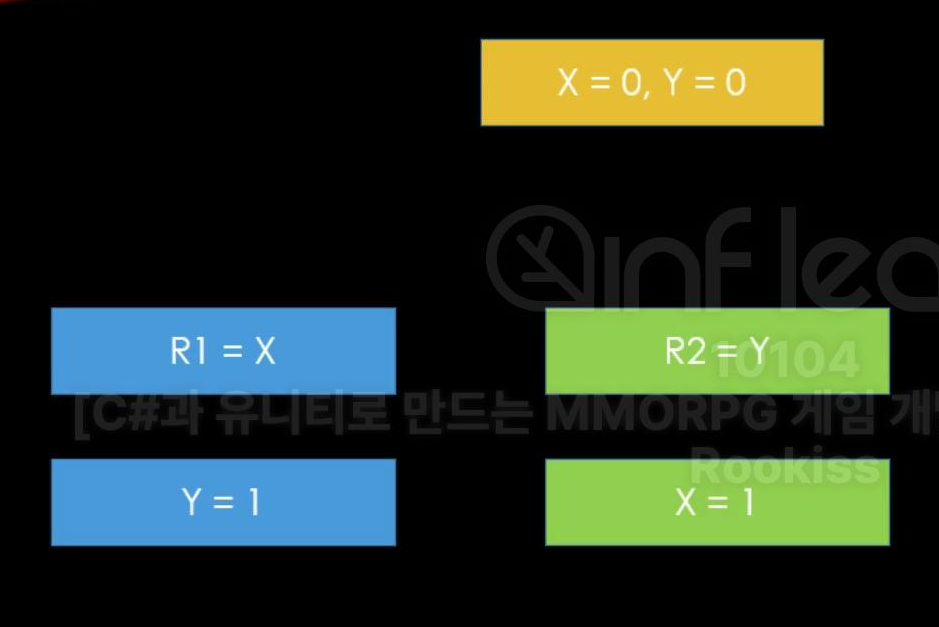
따라서 지금 Thread_1과 Thread_2 메소드는 이런 코드로 실행되고 있는 것이다. 이런 상황을 막기 위해 메모리 배리어가 존재한다.
메모리 배리어
C#의 메모리 배리어는 간단하다. Thread.MemoryBarrier(); 만 써주면 끝이다. 위의 코드에서 Thread_1, Thread_2 메소드에 이를 추가해보자.
static void Thread_1()
{
y = 1; // Store y
Thread.MemoryBarrier();
r1 = x; // Load x
}
static void Thread_2()
{
x = 1; // Store x
Thread.MemoryBarrier();
r2 = y; // Load y
}이 코드는 더 이상 우리가 예상하는 대로 동작해, while문을 빠져나오지 못한다. 그럼 메모리 배리어는 무슨 역할을 할까?
메모리 배리어는 크게 1. 코드 재배치 억제, 2. 가시성 두가지 역할을 한다.
1번은 말 그대로 메모리 배리어가 자신의 위와 아래를 명확히 갈라놓아, 재배치를 억제하는 역할을 한다. 메모리 배리어를 기준으로 침범하지 못하는 것이다.
2번의 가시성은 캐시에 있었던 변수들의 값을 메인 메모리에 저장하는 것을 의미한다. 즉, 특정 스레드의 캐시에서만 존재하던 변수의 값을 모두가 볼 수 있게 메인 메모리로 올려 가시성을 확보한다는 것이다. 또한 메인 메모리에 있던 값들도 캐시로 다시 끌어온다는 의미도 있다.
멀티스레드 환경에서는 각 스레드들끼리의 정보가 메인 메모리에 전달이 되지 않아 의도치 않은 상황이 많이 일어난다. 그때 주요하게 작용하는 것이 메모리 배리어다. 앞서 봤던 volatile 키워드도 이런 메모리 배리어가 작동한다고 보면 된다.
