내용을 시작하기 전에...
2주차 공부를 위해 터벅슨 터벅슨... 카페를 가고 있는 나에게 온 메세지 하나
다른 사람들이 올린 글도 구경 많이 했는데 다들 열심히 하셨길래
와 우수혼공족은 절대 못 되겠다... 싶었는데ㅜㅜ
감사합니다...
자유게시판 대화 눈팅하다 매머드 커피 알게 됐는데..ㅎㅎ 이걸 받아버렸다!!!
열심히 할게요 ㅎ

01) K-NN
지도 학습 알고리즘
- 분류 -> ch.02
- 회귀 : 어떠한 숫자를 예측
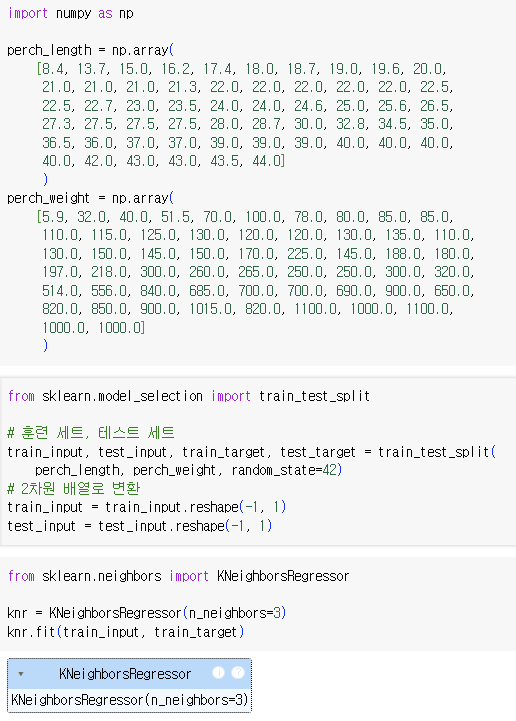
- 데이터 준비
-
데이터 불러오기 -> 산점도 그려보기 -> 훈련/테스트 세트로 나누기

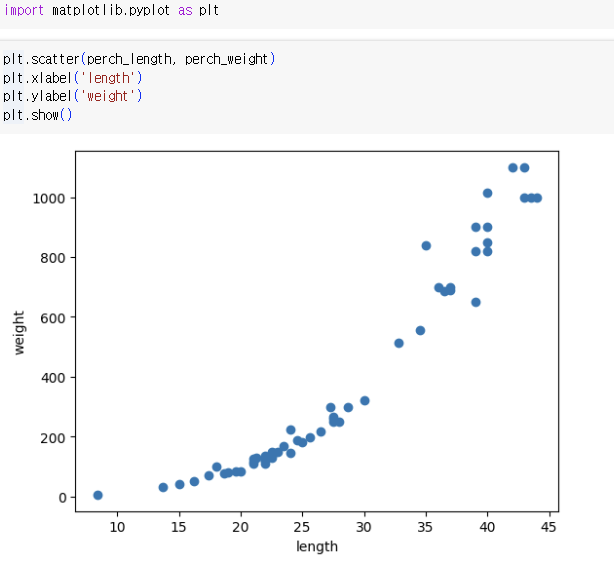

=> perch_length가 1차원 배열이라 train_input, test_input 모두 1차원 배열
당연함. 그걸 이용해 만든 거임.
사이킷런에 사용할 훈련 세트는 2차원 배열이어야 하기 때문에 변환해야 함!크기가 (3, )인 배열과 (3, 1)인 배열 -> 원소의 개수는 동일
-
reshape()사용해 배열 크기 변경 -> 배열 크기 지정 가능
#test_array()는 (4,)배열
test_array = test_array.reshape(2, 2) #배열 크기 지정
print(test_array,shape)!!주의!!
지정 크기와 원본 배열의 원소의 개수가 동일해야 함

- 결정계수(R²)
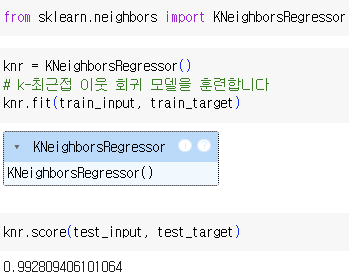
=> 점수의 의미
-
분류 -> 정확도
-
회귀 -> 결정계수(R²)
> 결정계수(R²)
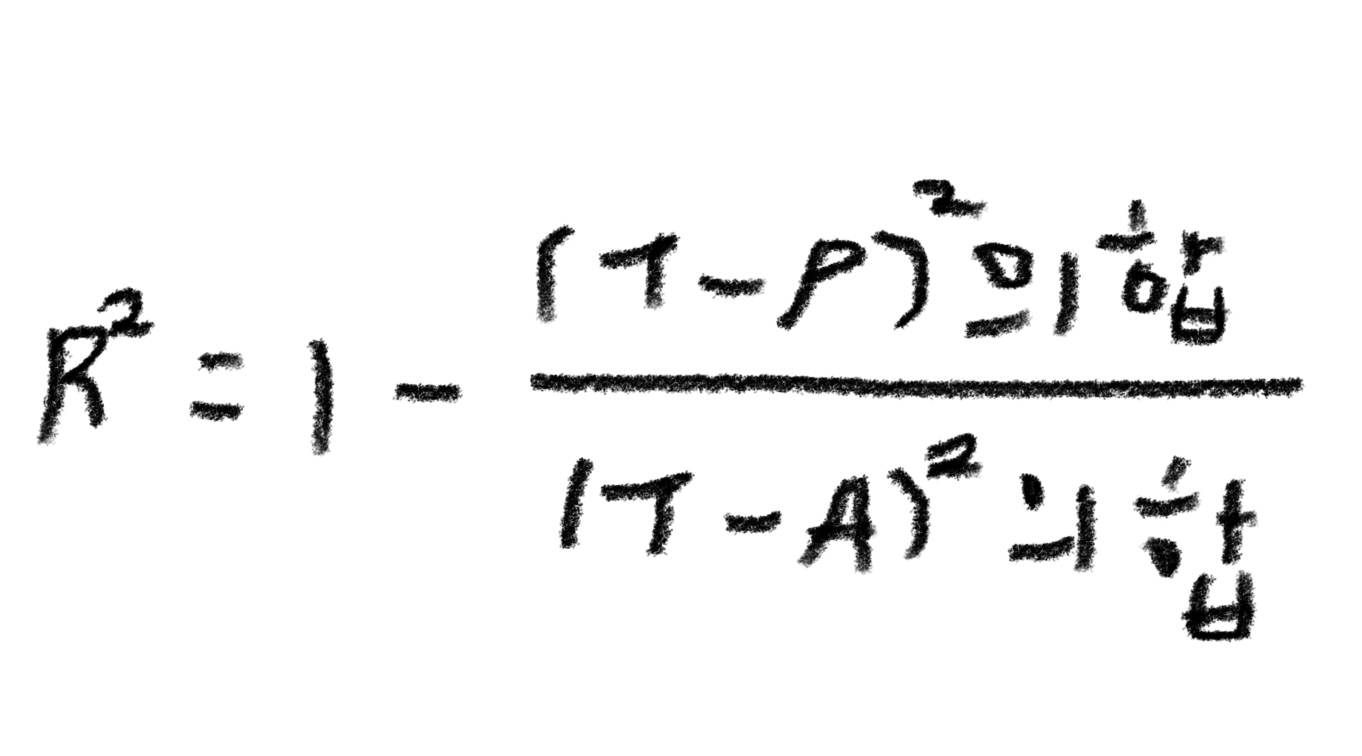 T : 타깃
T : 타깃
P : 예측
A : 평균 -
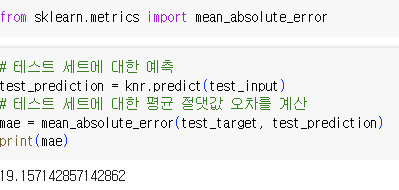
mean_absolute_error
-> 타깃과 예측의 절댓값 오차를 평균해 반환
- 과대적합 vs 과소적합

=> 과소 적합
- 과대 적합
: 훈련 세트 점수 > 테스트 세트 점수 - 과소 적합
: 훈련 세트 점수 < 테스트 세트 점수 || 두 점수가 모두 낮음
=> 모델이 너무 단순해 적절한 훈련이 이뤄지지 X
=> 실습의 과소적합 문제를 해결하기 위해선 모델을 복잡하게 만들기!
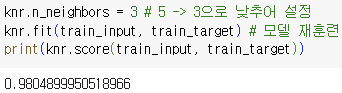
K-NN의 경우 기본 k값은 5 -> 3으로 낮추기
- 테스트 세트 점수
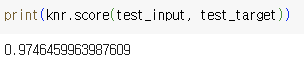
=> 두 값을 비교한 결과 테스트 세트 < 훈련 세트 즉, 과소적합 해결
02) 선형 회귀
- K-NN의 한계
 => 3 - 1에서와 마찬가지로 최근접 이웃 개수를 3으로 모델 훈련
=> 3 - 1에서와 마찬가지로 최근접 이웃 개수를 3으로 모델 훈련

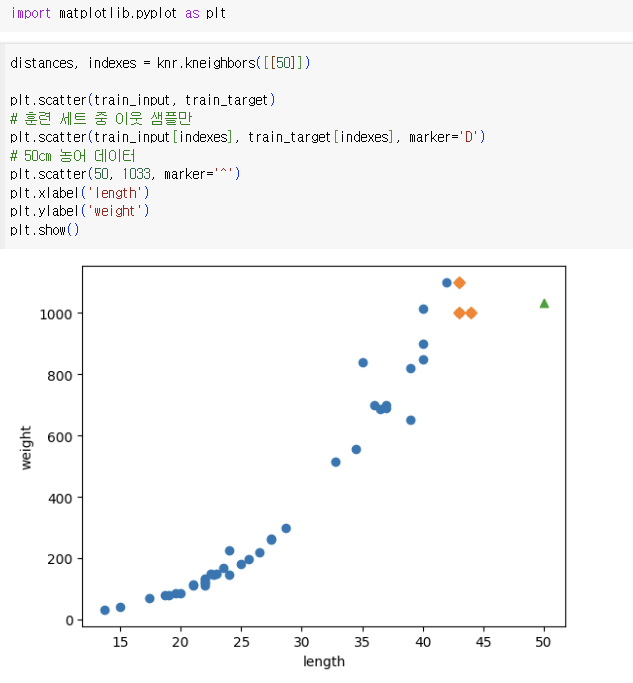
 => 모델의 예측 값과 일치
=> 모델의 예측 값과 일치
=> 새 샘플이 훈련 세트의 범위를 벗어나면 정확한 예측 불가능
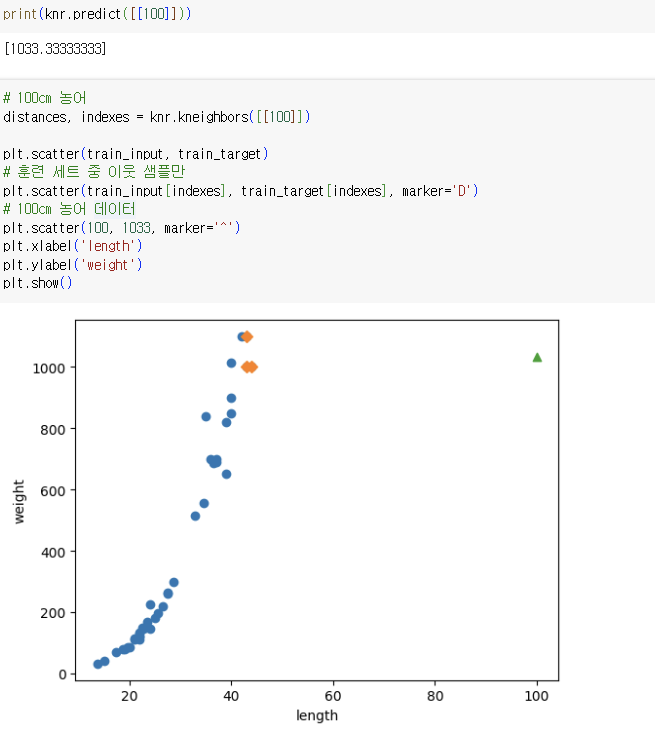
=> 이것이 K-NN의 한계!! 다른 알고리즘을 이용해야 함
- 선형 회귀
: 특성이 하나인 경우 어떤 직선을 학습하는 알고리즘
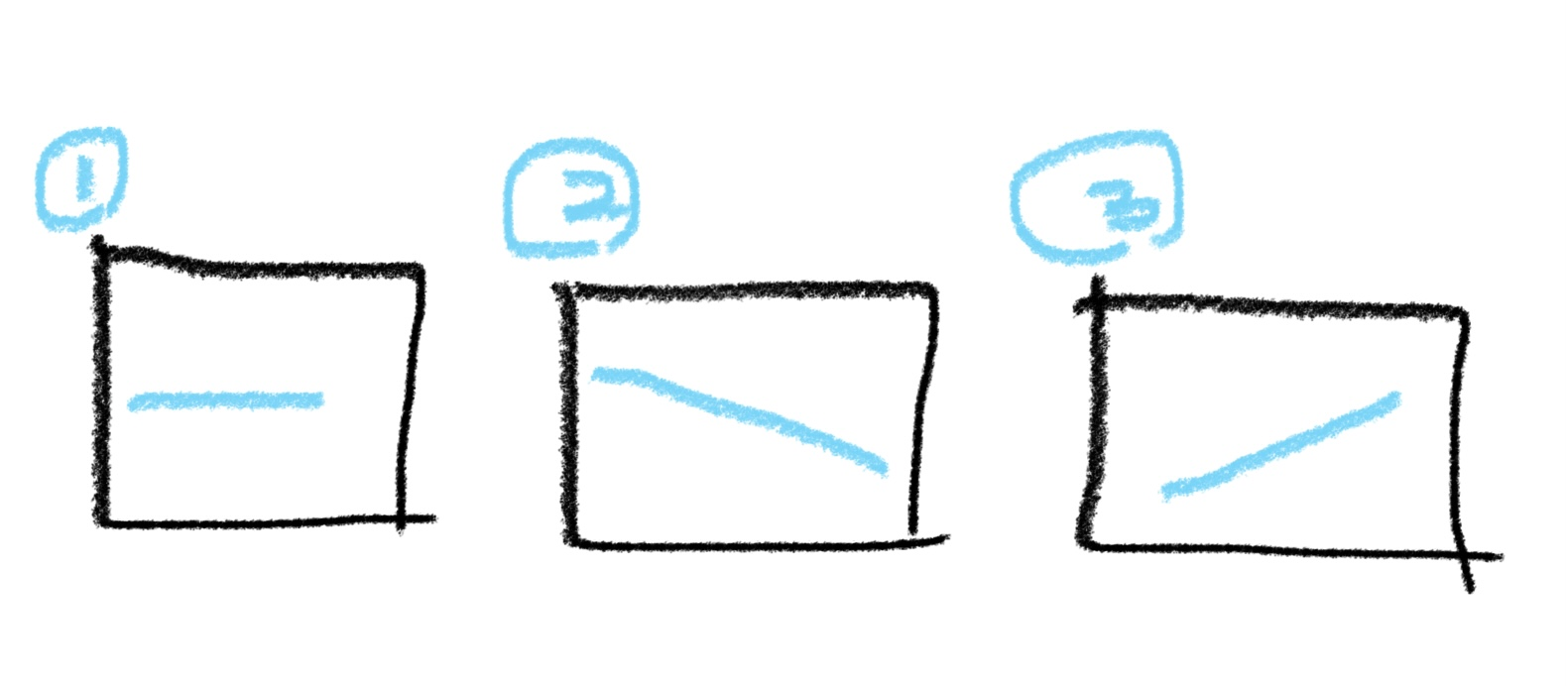 => 이 세 가지 그래프 중 그래프 3이 데이터를 가장 잘 표현
=> 이 세 가지 그래프 중 그래프 3이 데이터를 가장 잘 표현
y : 농어 무게
x : 농어 길이
a : 기울기
b : 절편
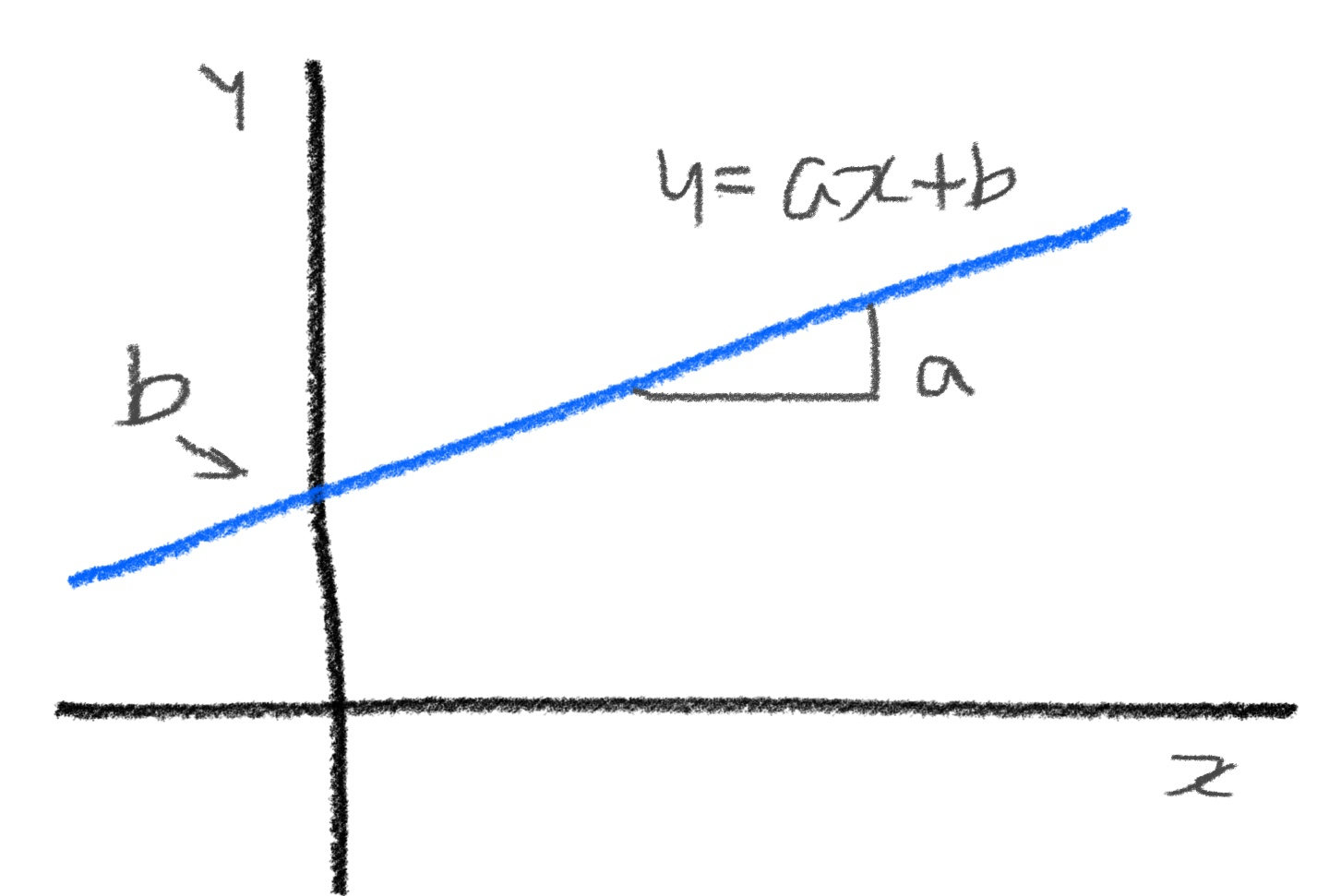
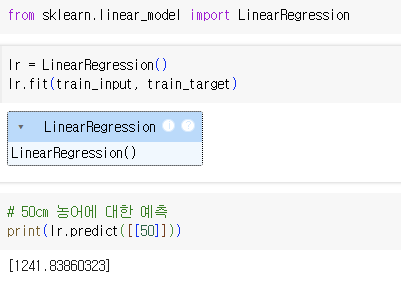
- LinearRegression클래스가 a, b를 찾음
-> lr객체의 coef_(계수 혹은 가중치라고 함)와 intercept 속성에 저장
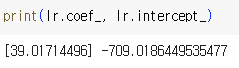
=> 예측 값이 직선의 연장선에 존재 즉, 예측에 성공!

=> 뭔가 싸늘함을 느낄 수 있음..
무게가 0 이하? 현실 초월이 되...
- 다항 회귀
y : 농어 무게
x : 농어 길이
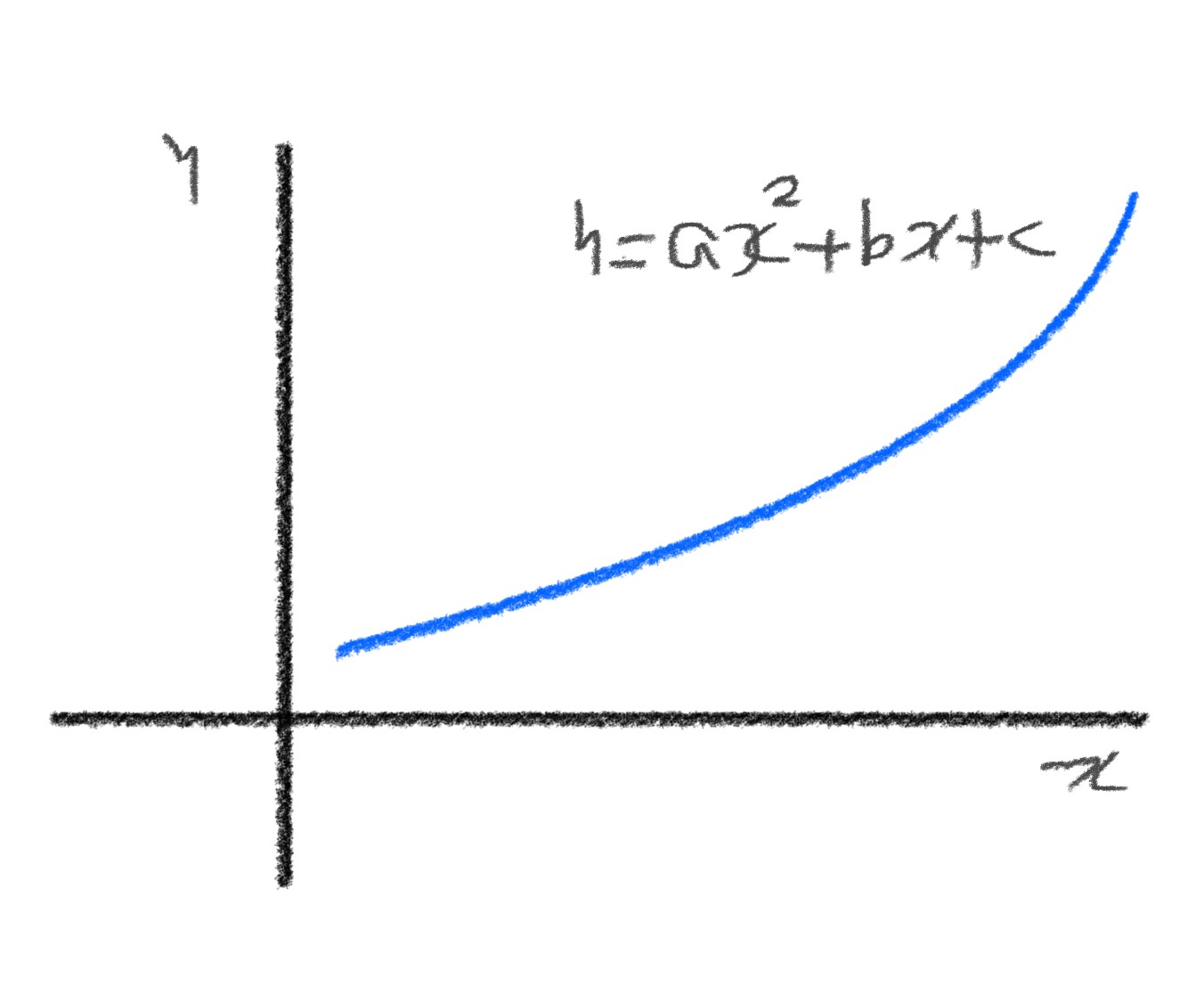
- 농어의 길이를 제곱해 원래 데이터 앞에 붙이기
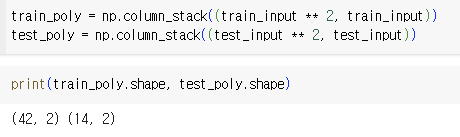 => train_input ** 2에 넘파이 브로드캐스팅 적용(=> 해당하는 모든 원소 제곱)
=> train_input ** 2에 넘파이 브로드캐스팅 적용(=> 해당하는 모든 원소 제곱)

- 모델이 훈련한 계수와 절편
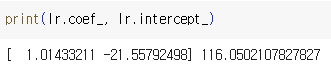
무게 = 1.01 길이² - 21.6 길이 + 116.05 -> 다항식 -> 다항 회귀
- 다항회귀
: 다항식을 사용한 선형 회귀
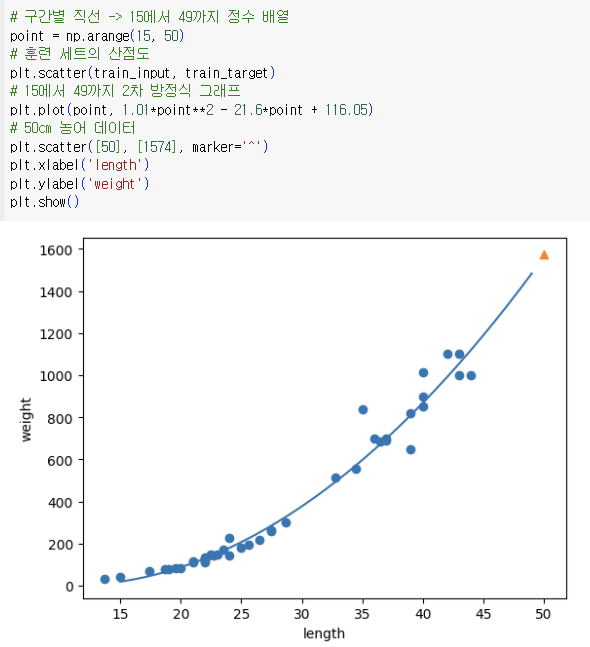 => 음수 존재XX
=> 음수 존재XX
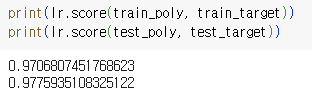
=> 두 점수가 높아졌지만 과소적합이 남아 있는 상태...
03) 특성 공학과 규제
- 특성공학
: 기존의 특성을 활용해 새 특성을 뽑아냄
-데이터 준비
- 판다스
: 데이터 분석 라이브러리
핵심 구조로 dataframe이 있음 -> csv파일 활용
- 사이킷런의 변환기
- 변환기
: 특성을 만들거나 전처리하기 위한 다양한 클래스
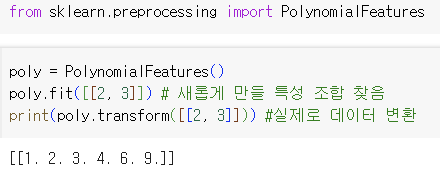
- PolynomialFeatures클래스
: 기본적으로 각 특성을 제곱한 항을 추가하고 특성끼리 서로 곱한 항 추가 - 사이킷런의 선형 모델
: 자동으로 절편 추가 -> 굳이 특성 만들 필요 XX
=> include_bias = F지정




- 다중 회귀 모델 훈련하기

=> 두 점수 확인 결과 과소적합 문제 해결된 것을 알 수 있음

=> 열의 개수 = 특성의 개수
여기서 드는 의문점 -> 이러면 과대적합 될텐데... 이걸 노리고 하는 거겠죠???
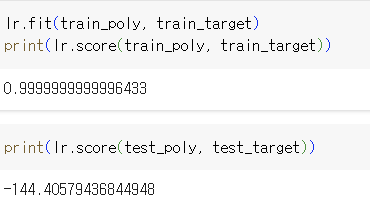 => 대박적인 점수... 레전드 과대적합
=> 대박적인 점수... 레전드 과대적합
- 규제
: ML 모델이 훈련 세트에 과대적합되지 않게 함
 => ss 초기화 후 훈련 어게인
=> ss 초기화 후 훈련 어게인
- 릿지 -> 선호
: 계수 제곱한 값을 기준으로 규제 적용 - 라쏘
: 계수의 절댓값 기준으로 규제 적용
=> 두 알고리즘 모두 계수의 크기를 줄임(라쏘는 아예 0으로 만들기 가능)
- 릿지 회귀
 => 테스트 세트 점수 정상화
=> 테스트 세트 점수 정상화
alpha 값으로 규제 강도 조절
값이 크면 과소적합, 값이 작으면 과대적합 될 가능성 큼
적절한 alpha값 -> alpha값에 대한 R²값의 그래프 그려보기
 train과 test 점수가 가장 가까운 지점이 최적의 alpha값
train과 test 점수가 가장 가까운 지점이 최적의 alpha값
 => 동일한 간격으로 값을 출력하기 위해 로그함수로 바꿔 지수로 표현
=> 동일한 간격으로 값을 출력하기 위해 로그함수로 바꿔 지수로 표현
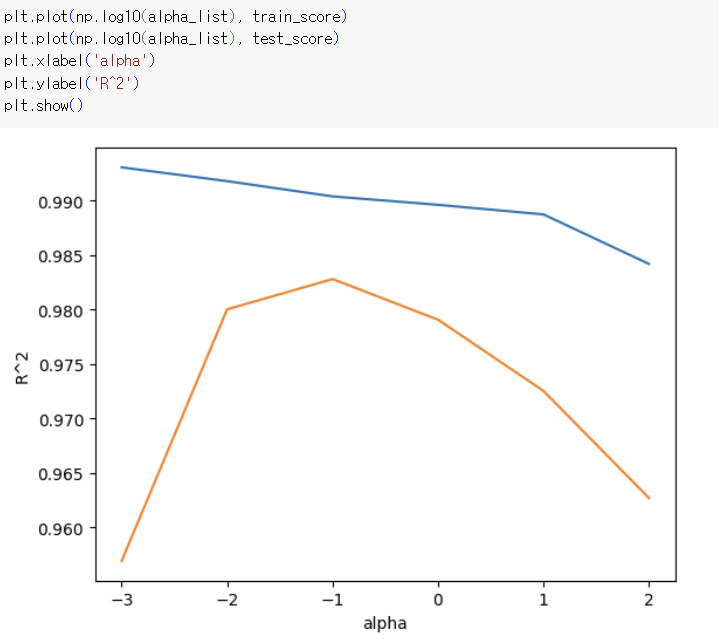 => 왼쪽 : 과대적합, 오른쪽 : 과소적합
=> 왼쪽 : 과대적합, 오른쪽 : 과소적합
적절한 alpha값 -> -1 즉, 0.1
- 라쏘 회귀
릿지를 라쏘로 바꾸면 끝.
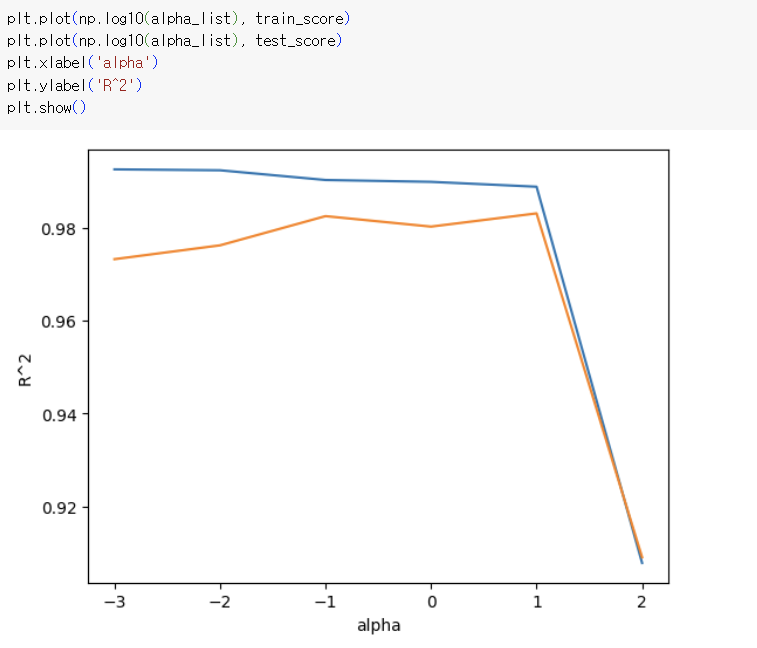 => 마찬가지로 왼쪽 : 과대적합, 오른쪽 : 과소적합
=> 마찬가지로 왼쪽 : 과대적합, 오른쪽 : 과소적합
적절한 alpha값 -> 1 즉, 10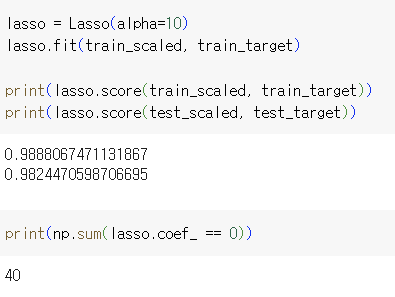 => 라쏘는 계수 값을 아예 0으로 만들 수 있음. 마지막 코드는 0의 개수를 출력한 것
=> 라쏘는 계수 값을 아예 0으로 만들 수 있음. 마지막 코드는 0의 개수를 출력한 것
<숙제>
- K-NN의 k값을 1, 5, 10으로 바꿔가며 훈련해보고 농어 길이를 5 ~ 45로 바꿔가며 그래프 그리기

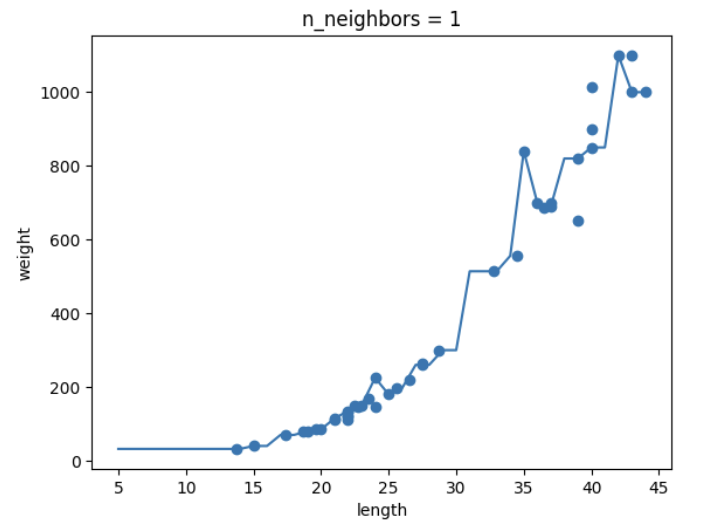
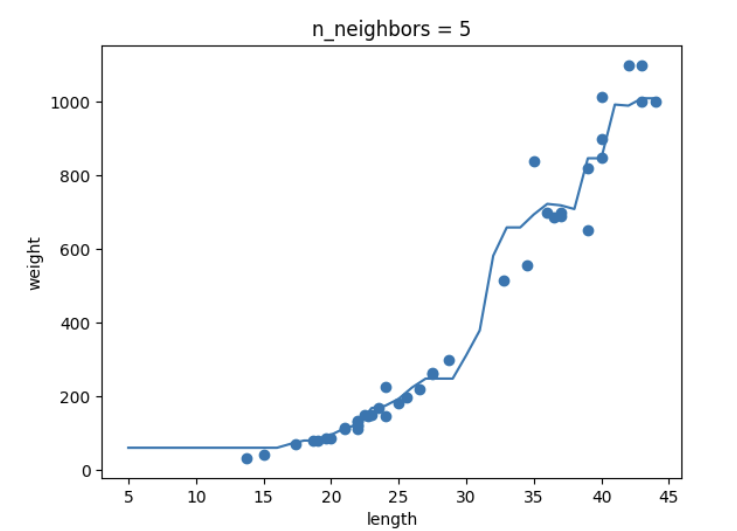
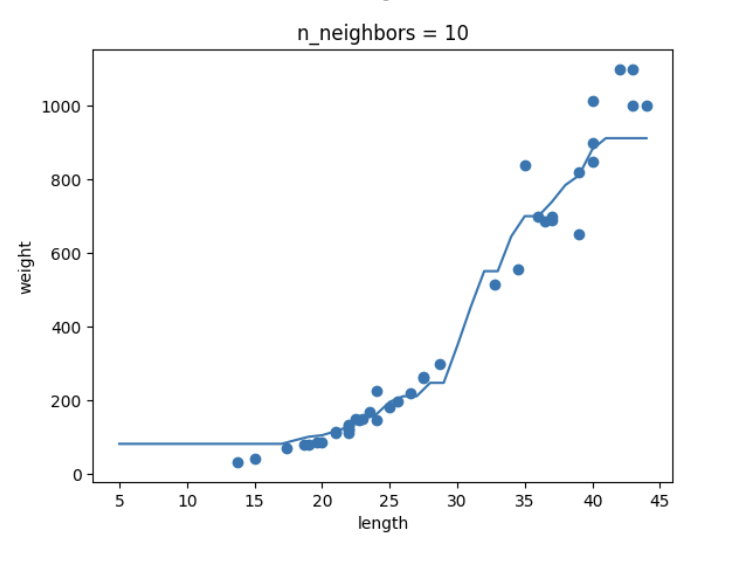
-추가 숙제
- 파라미터란?
: 모델 내부에서 결정되는 변수 -> 학습을 하는 동안 변하는 값
가중치 역할을 함!
