k-최근접 이웃 알고리즘 -> 분류, 회귀 모델 모두 제공
훈련데이터셋에서 가장 가까운 데이터 포인트를 찾음 (끼리끼리, 유유상종)
가까운 훈련 데이터 포인트 하나를 최근접 이웃으로 찾아 예측(1)
pip install mglearn(2)
# 한글폰트 패치
import matplotlib as mpl
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina'
!apt -qq -y install fonts-nanum
import matplotlib.font_manager as fm
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
plt.rc('font', family='NanumBarunGothic')
mpl.font_manager._rebuild()(3)
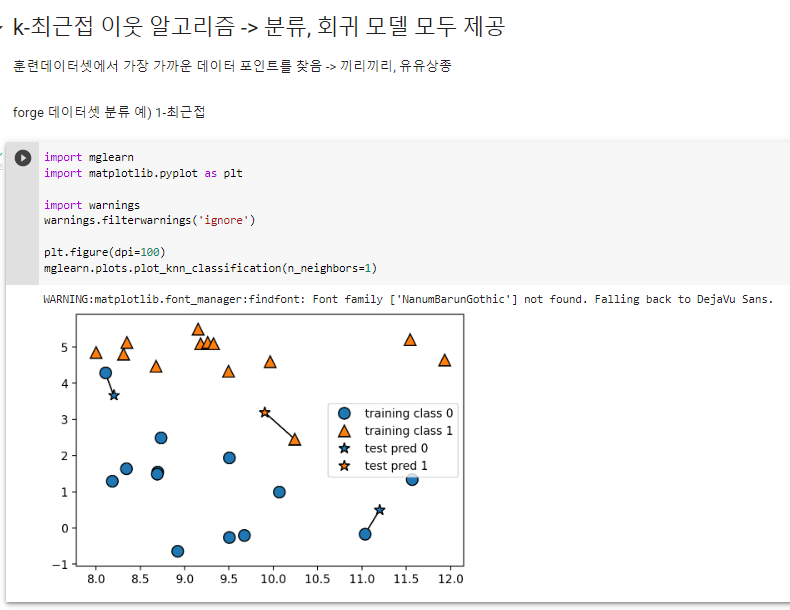
^ 근접한 1개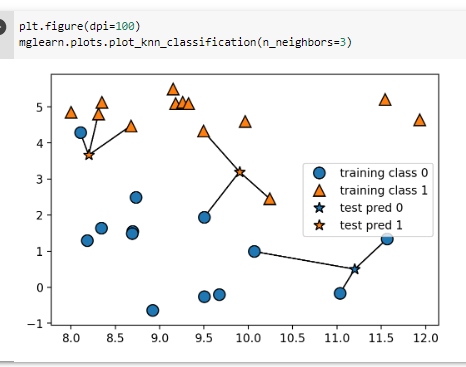
^ 별을 기준으로 3개(4)

(5)
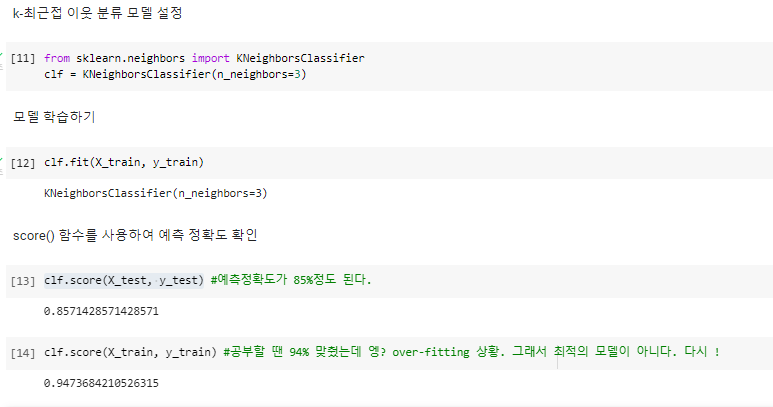
(6)
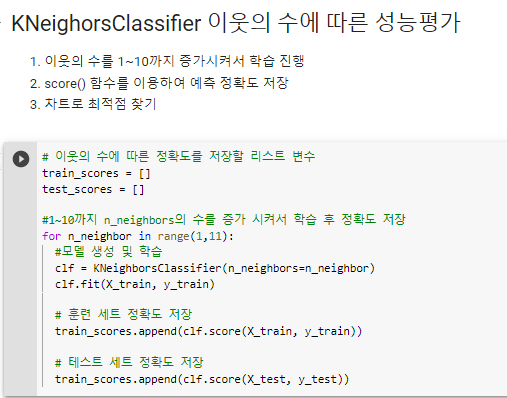
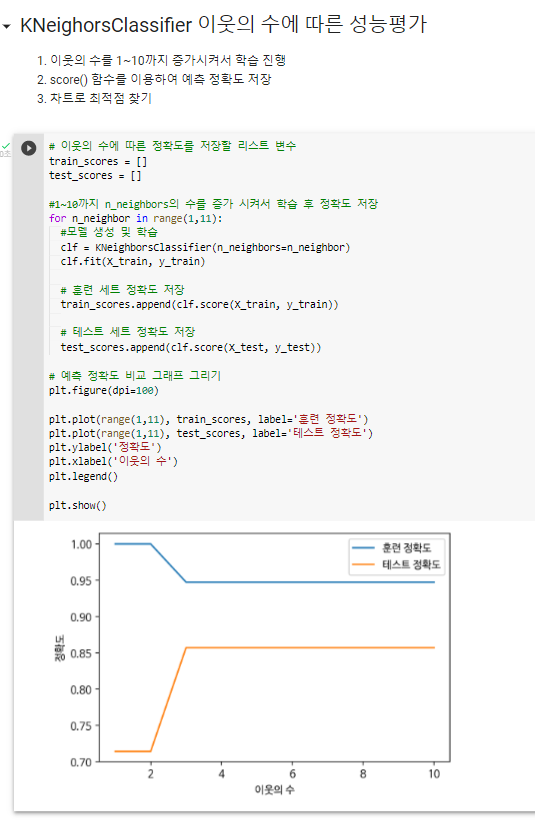

^ 최종 (같은 range(1,11)도 하나의 변수로 잡아주었다.)
유방암 데이터셋을 사용하여 이웃의 수(결정경계)에 따른 성능평가
(1)
(2)

(3)
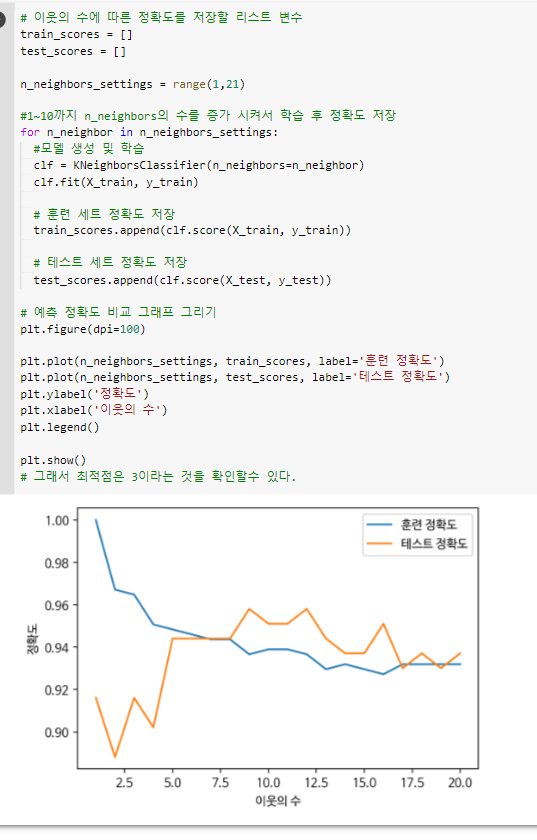
# 이웃의 수에 따른 정확도를 저장할 리스트 변수
train_scores = []
test_scores = []
n_neighbors_settings = range(1,21)
#1~10까지 n_neighbors의 수를 증가 시켜서 학습 후 정확도 저장
for n_neighbor in n_neighbors_settings:
#모델 생성 및 학습
clf = KNeighborsClassifier(n_neighbors=n_neighbor)
clf.fit(X_train, y_train)
# 훈련 세트 정확도 저장
train_scores.append(clf.score(X_train, y_train))
# 테스트 세트 정확도 저장
test_scores.append(clf.score(X_test, y_test))
# 예측 정확도 비교 그래프 그리기
plt.figure(dpi=100)
plt.plot(n_neighbors_settings, train_scores, label='훈련 정확도')
plt.plot(n_neighbors_settings, test_scores, label='테스트 정확도')
plt.ylabel('정확도')
plt.xlabel('이웃의 수')
plt.legend()
plt.show()
# 그래서 최적점은 3이라는 것을 확인할수 있다.