예제에 사용할 데이터셋:
k-최근접 이웃
선형 모델
결정 트리
결정 트리의 앙상블
-> 여기는 k-최근접 이웃 하려 한다.
지도학습

정답지:
y
class
레이블
종속변수
target
시험지:
x
독립변수
feature
data분류: 연속적이지 않은 숫자
회귀: 연속적인 숫자 (주식, 집값, 관객수)
Iris 품종 분류
01_붓꽃(iris)품종 분류.ipynb
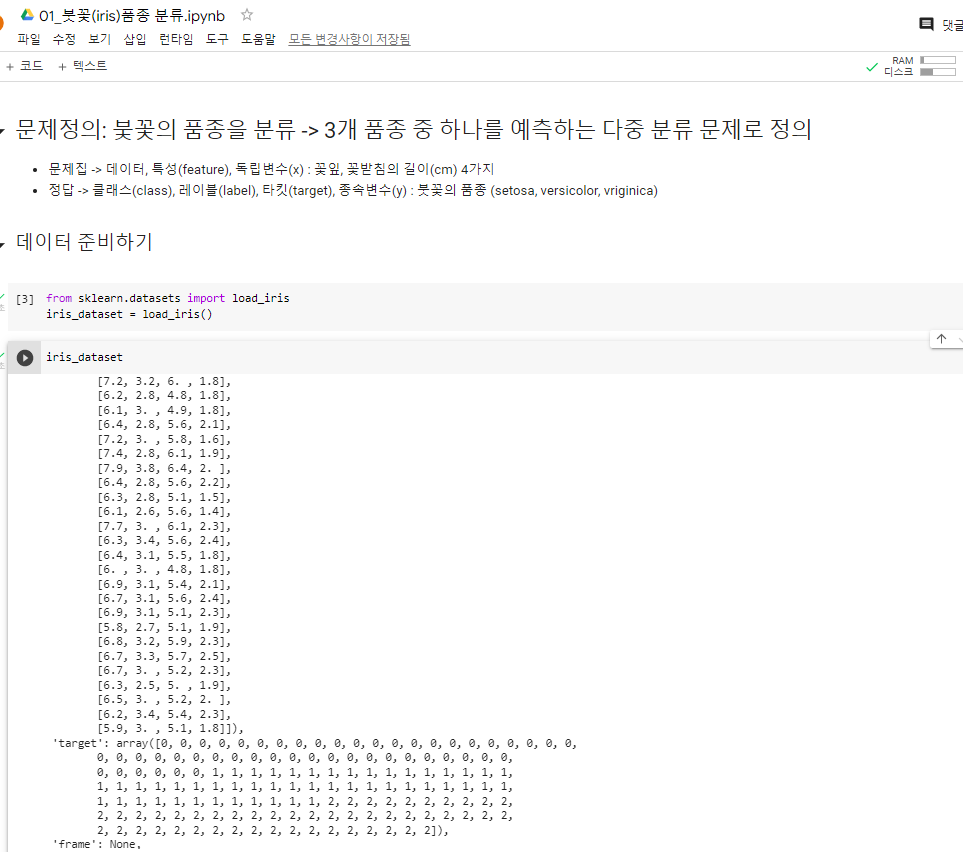
문제정의: 붗꽃의 품종을 분류 -> 3개 품종 중 하나를 예측하는 다중 분류 문제로 정의
데이터 준비하기
- 문제집 -> 데이터, 특성(feature), 독립변수(x) : 꽃잎, 꽃받침의 길이(cm) 4가지
- 정답 -> 클래스(class), 레이블(label), 타킷(target), 종속변수(y) : 붓꽃의 품종
(setosa, versicolor, vriginica)
3개의 품종 중 하나를 예측 -> 다중분류
(1-1)

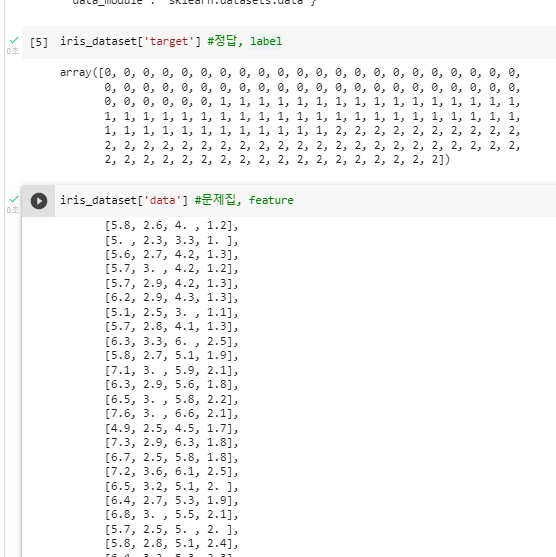
^ 결과를 보면 첫 번째 품종은 0,
두 번째 품종은 1,
세번째 품종은 2 인 것을 확인할 수 있다. (1-2)
(1-3)
^ 수를 계산해주는 numpy 라이브러리인 것을
확인할 수 있다. (= 수학적인 계산이 빠른 리스트이다.)
(1-4)
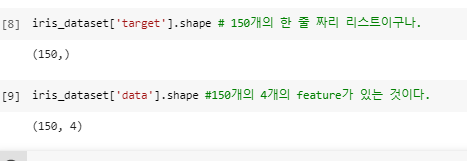
^ 모양이 어떻게 생겼는지 이해할 수 있다. 
^ 위에 [9] shape을 보았을 때
150개 4개의 콜럼으로 구성된 것을 확인할 수 있다. (1-5)

^ shape 에서 확인한 것과 같이 150개와 4개의 콜럼으로 구성(1-6)
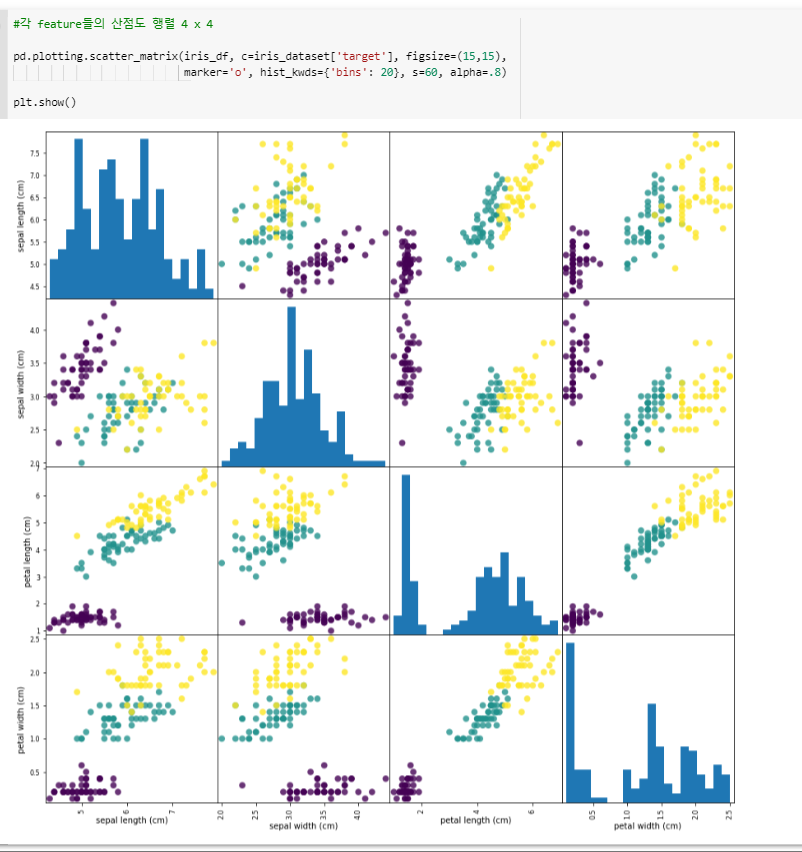
^ 자기 자신을 히스토그램으로 찍고 비교할 친구들을 점으로 표현.
(150개의) 비율로 그려진 것이다.
콜럼이 4개이니 그래프를 이렇게 그려줌.
alpha : 투명도
bins : 로 비율 조정
s : 동그라미 사이즈(1-7)
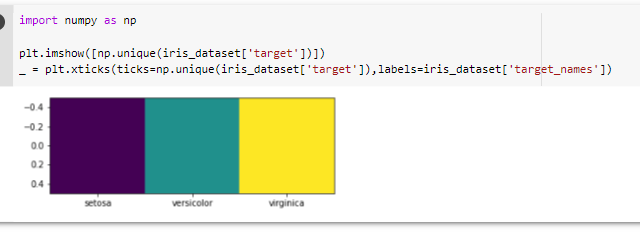
^ 위의 그래프가 어떠한 품종인지 알아보기.
_언더스코어라고 한다.
1) return타입으로 보여지는 값을 안보이게 처리해준다.
2) 안 쓸 변수명을 언더스코어(_)로 처리해준다. (1-8)

^ 두 개의 셀만 골라낸것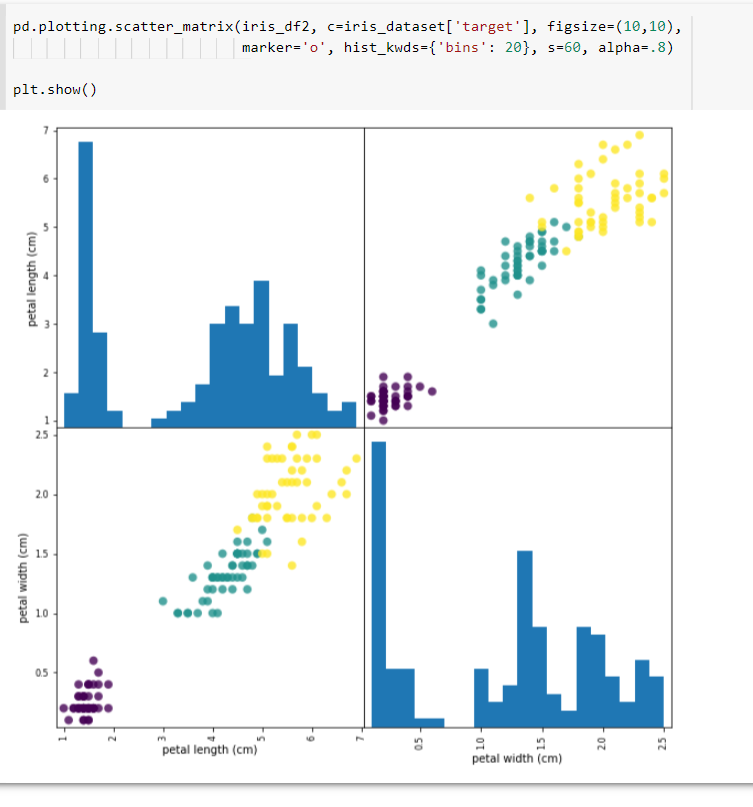
^ 비교적 명확히 구분이되는 두 개의 셀을 뽑아낸것이다. 훈련데이터와 테스트데이터 분리

(1-9)
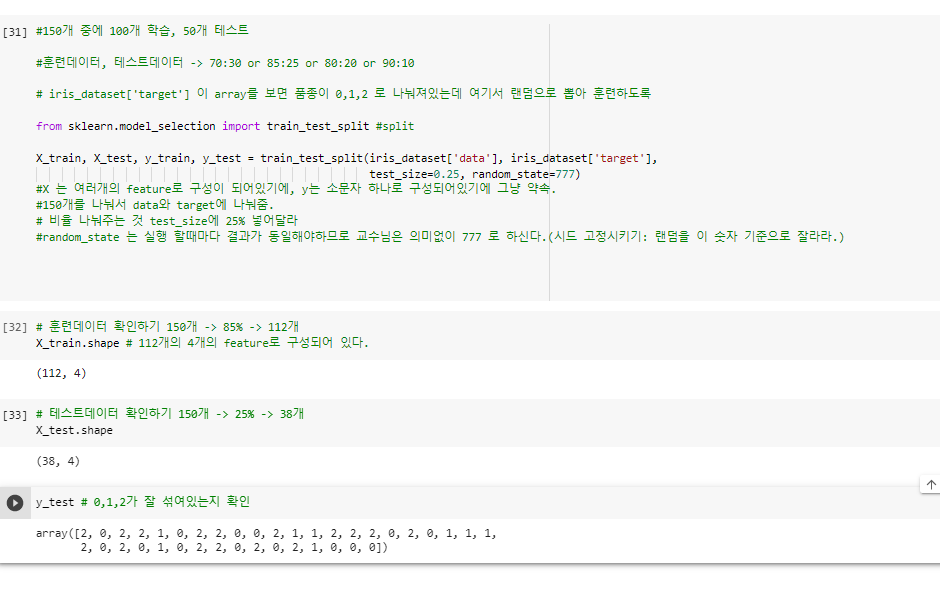
^ 훈련데이터랑 테스트데이터 분리시켜주고 랜덤화해주기머신러닝 모델 설정 -> k-최근접 이웃 알고리즘
(1-10)
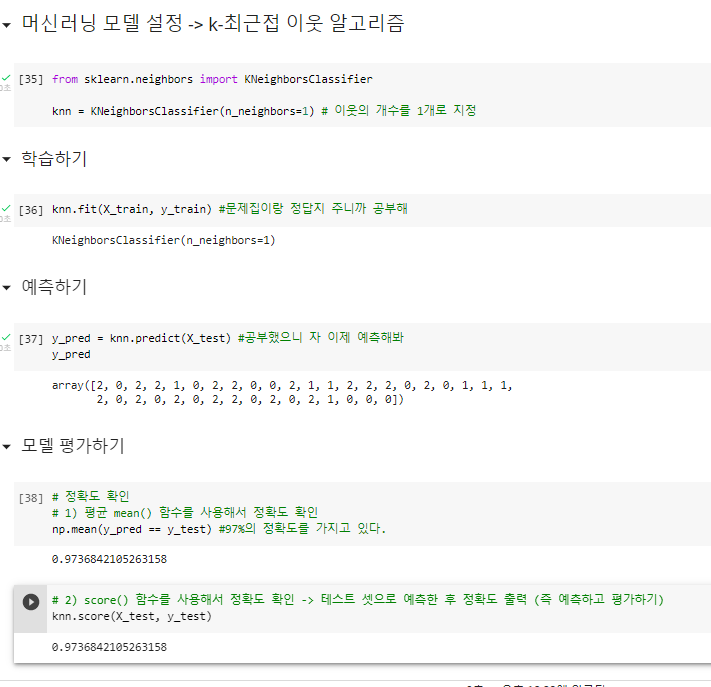
^ 학습시키고 예측하고 정확도 확인하기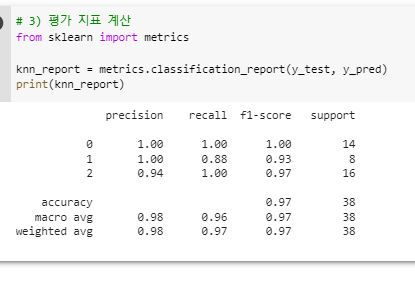
^ -평가 지표 계산하기
-이 지표를 보면 품종 0의 정확도는 1.0으로 100%이다.
-그래서 다음 단계에서는 1과 2의 품종에 대해
-정보 수집을 추가적으로 하면 성능이 좋아짐.
- 책 딥러닝 입문 54페이지
- precision (정밀도) 예측한거에서 맞은 갯수와
정답 중 예측한 갯수
- recall (재현율) 실제 데이터 중 제대로 예측 한 갯수
- fi-score 평균일반화, 과대적합, 과소적합

^ 테스트할때 최적점을 넘어가면
모델이 과대적합되는 상태로 넘어간다. (암기의 단계랄까)
데이터셋에 다양한 데이터 포인트가 많을수록 과대적합 없이 더 발전 가능하다. 02_지도학습 분류와 회귀 데이터셋 확인.ipynb
(2-1) 깔아주기
pip install mglearn(2-2) 한글패치
# 한글폰트 패치
import matplotlib as mpl
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina'
!apt -qq -y install fonts-nanum
import matplotlib.font_manager as fm
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
plt.rc('font', family='NanumBarunGothic')
mpl.font_manager._rebuild()(2-3)

(2-4)

(2-5)
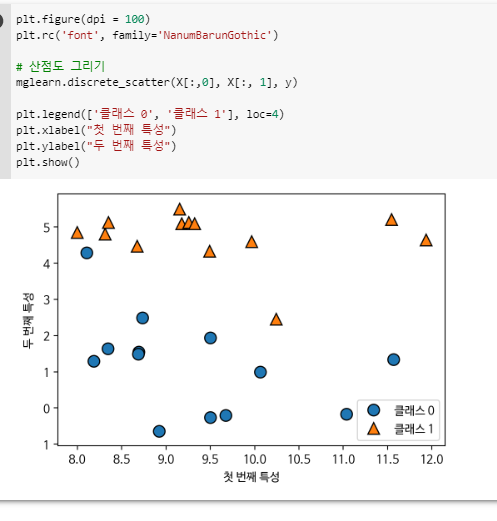
(2-6)
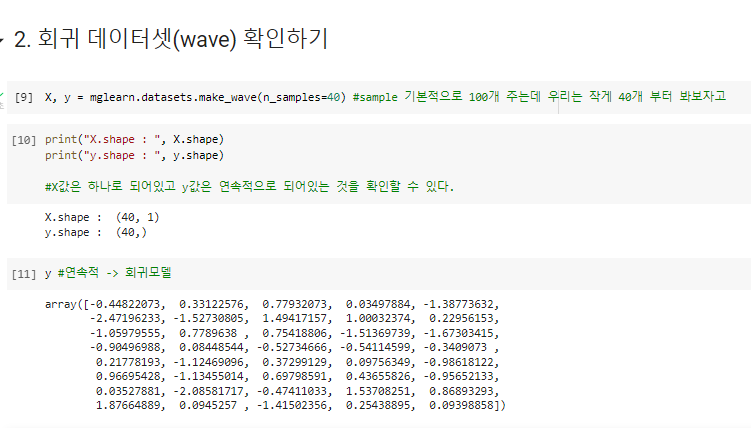
(2-7)
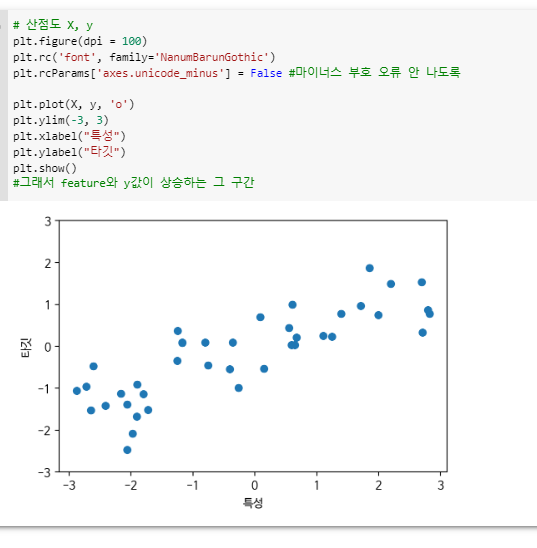
((8)) 원본 데이터셋

^ M과 B로 구분할 수 있구나.
texture와 같은 것들로 구분지을 수 있구나.(2-9)

(2-10)

^ 어떻게 dataset이 이루어져 있는지(2-11)

^ 30개의 특성(2-12)
sklearn.datasets
^ 근데 이 데이터셋을 보니 0이 약성이고 1이 양성이다. 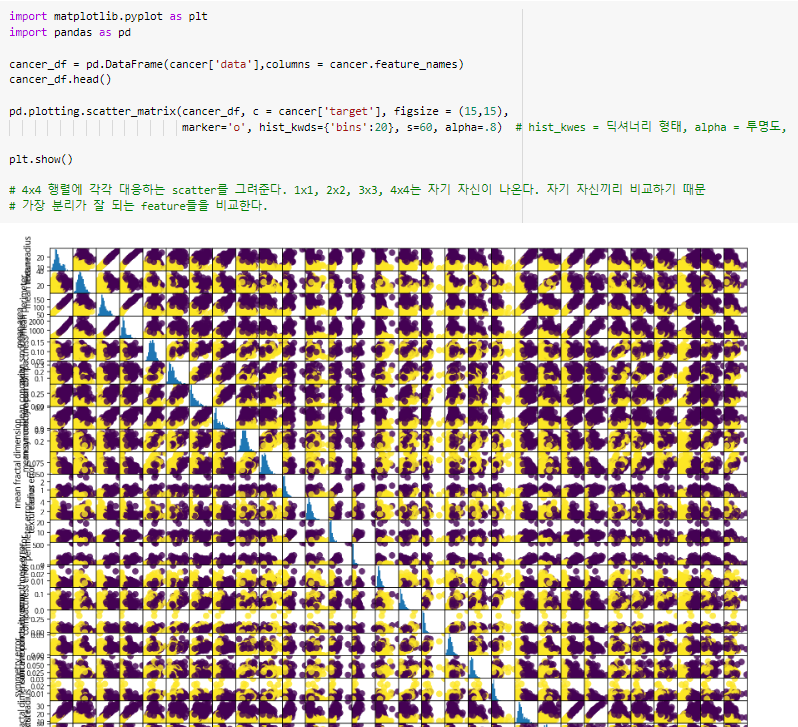
^ 데이터를 보고 분류해내기 좋은 얘들 골라 쓰면 된다.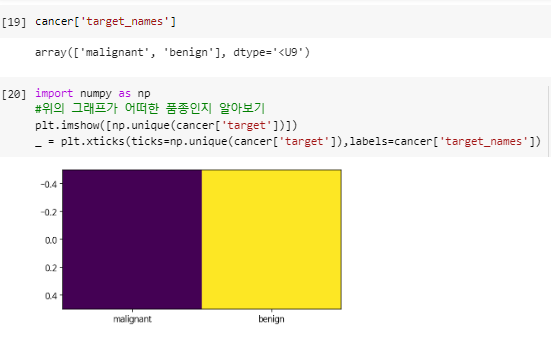
회귀 문제정의: 보스톤 주택 가격 데이터셋을 사용한 평균 주택 가격 예측
boston data
kaggle boston housing
just for reference
책 파이썬 머신러닝 완벽 가이드 324페이지
(3-1)
from sklearn.datasets import load_boston
boston = load_boston()(3-2)
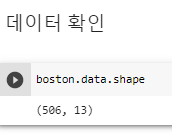
^ 506개 13개 콜롬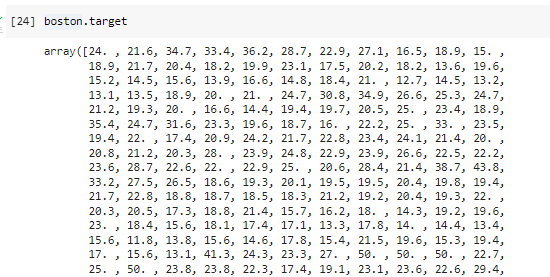
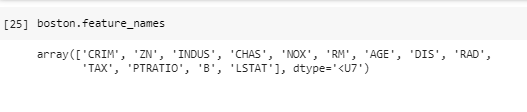
^ 13개의 콜롬 이름
^ 위의 13개의 콜럼이 어떤 콜럼인지 정리해주기