벡터 DB 개요
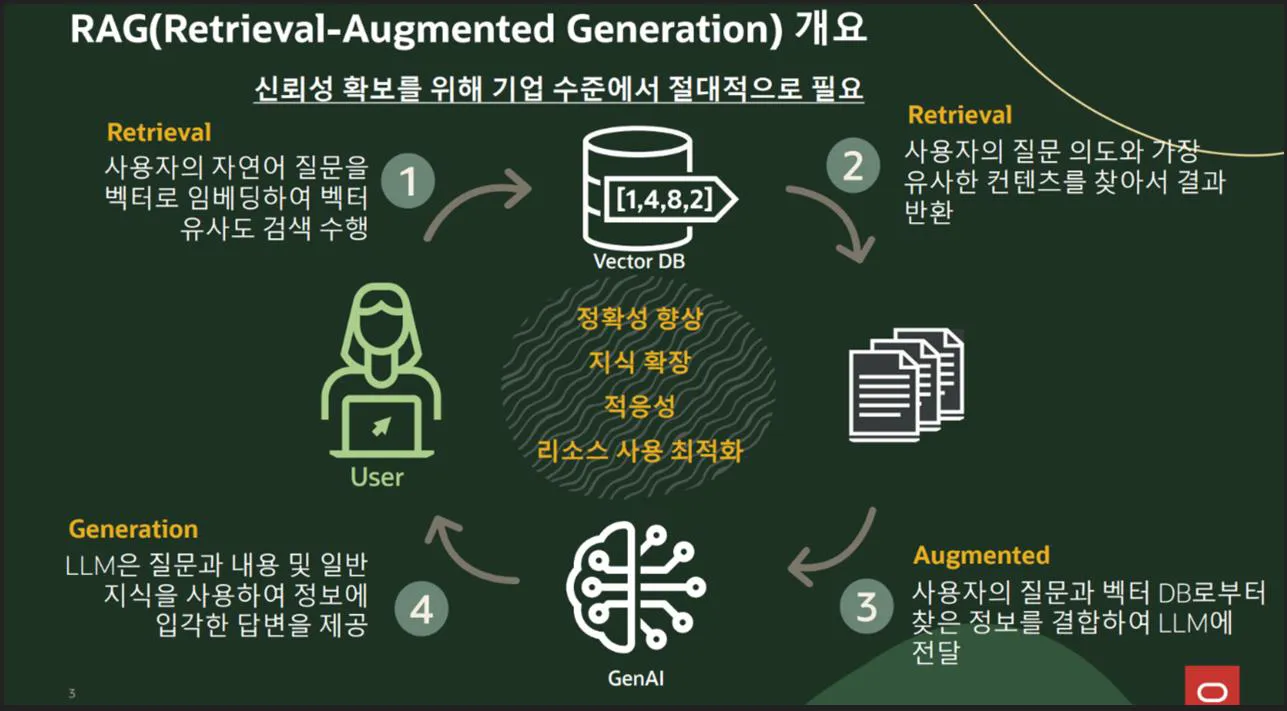
생성형 AI가 발전하면서 환각 없는 생성형 콘텐츠의 중요성이 확대됐고, 환각을 최소화하는 방안으로 RAG가 각광받고 있습니다.
또한, RAG를 위해서는 벡터 DB가 반드시 필요합니다.
전통적인 데이터베이스 vs 벡터 데이터베이스 비교
| 특징 | 전통적인 데이터베이스 (RDB, NoSQL) | 벡터 데이터베이스 (벡터 DB) |
|---|---|---|
| 데이터 타입 | 정형 데이터 (숫자, 문자열, 테이블) | 비정형 데이터 (이미지, 음성, 텍스트) |
| 기본 연산 | CRUD (Create, Read, Update, Delete) | 유사도 검색 (Nearest Neighbor Search) |
| 인덱싱 방식 | B-Tree, Hash Index | HNSW, IVF, PQ 등 |
| 쿼리 방식 | SQL, NoSQL 쿼리 | 벡터 유사도 검색 (Cosine Similarity, Euclidean Distance) |
| 응용 분야 | 전통적 Biz. Application (ERP, CRM, 금융) | AI 검색, 추천 시스템, 이미지/음성 검색 |
요약 설명
-
전통적인 데이터베이스는 ‘정확한 값을 찾는 데 강함’
-
벡터 데이터베이스는 ‘비슷한 것을 찾는 데 강함’
[참고] KNN 검색 vs. ANN 검색
| 비교 항목 | KNN (K-Nearest Neighbors) | ANN (Approximate Nearest Neighbors) |
|---|---|---|
| 정의 | 주어진 입력 벡터에 대해 가장 가까운 K개의 데이터를 찾아 분류 또는 회귀 수행 | 정확도보다는 속도와 효율성을 우선하여 근사적으로 최근접 이웃을 찾는 알고리즘 |
| 기본 개념 | 유클리디안 거리 등으로 거리 기반의 정확한 최근접 이웃 계산 | 효율적인 검색을 위해 인덱스 구조나 해싱 등을 사용하여 빠르게 근사 계산 |
| 정확도 | 매우 정확하지만 계산량이 많고 느림 | 약간의 정확도 손실이 있으나 속도가 빠름 |
| 속도 및 성능 | 느림 (특히 대규모 데이터에서는 매우 느림) | 매우 빠름 (특히 고차원 대용량 데이터에서 성능 우수) |
| 메모리 사용량 | 전체 데이터를 저장해야 하므로 큼 | 인덱스만 저장하므로 상대적으로 작음 |
| 확장성 | 낮음 – 데이터가 많아질수록 속도 급격히 저하 | 높음 – 수십억 개 벡터도 실시간 검색 가능 |
| 활용 분야 | - 분류(Classification) - 회귀(Regression) - 추천 시스템 - 이상 탐지 | - 대규모 이미지 검색 - 추천 시스템 - 문서 유사도 검색 - 임베딩 기반 검색 엔진 |
| 적합한 데이터 | 소규모, 고정된 데이터셋 | 대규모, 고차원 임베딩 데이터셋 |
요약
-
KNN: 정확도는 높지만 속도와 확장성이 떨어짐. 소규모 데이터에 적합
-
ANN: 근사값을 이용하여 빠른 검색 가능. 대규모 벡터 검색에 적합
벡터 데이터베이스의 필요성
기존 데이터베이스의 한계
-
숫자나 텍스트(예: "홍길동") 같은 구조화된 데이터 저장·검색에는 최적화되어 있음
-
이미지, 음성, 문장 의미 같은 비정형 데이터 검색은 어려움
-
이미지, 영상, 음성, 텍스트 등 비정형 데이터의 확산으로 기존 관계형 DB만으로는 한계
- SNS, 쇼핑, 스트리밍 플랫폼에서 비정형 데이터 활용 증가
-
ChatGPT, DALL·E, Stable Diffusion 등 생성형 AI 발전
-
이미지 검색, 음성 인식, 추천 시스템 등에는 고급 검색 필요
-
전통적인 데이터베이스에서는 유사도 검색의 비효율성
→ 벡터 DB 필요성 대두
벡터 데이터베이스가 해결하는 문제
- 데이터를 숫자 벡터(좌표)로 변환하여 저장하고 "비슷한 것"을 쉽게 찾을 수 있음
- 활용 예시:
- 이미지 검색: “이 사진이랑 비슷한 사진 찾아줘!”
- 음성 인식: “이 사람 목소리랑 비슷한 사람 찾아줘!”
- 추천 시스템: “내가 좋아할 만한 음악 추천해줘!”
이미지에서의 VectorDB
1. 이미지 임베딩(벡터화) 속도
-
자율주행 카메라에서 들어오는 영상 프레임을 실시간 벡터로 바꾸려면, 경량화된 모델 또는 하드웨어 가속이 필수입니다.
-
해결책:
- ONNX, TensorRT로 딥러닝 모델 경량화 및 최적화
- GPU/TPU 또는 엣지 디바이스(NVIDIA Jetson, Coral 등) 활용
- 딥러닝 모델을 Batch 처리하여 처리 효율 향상
2. 벡터 유사도 검색 속도
-
벡터 DB는 수천만 개의 벡터 중에서 유사한 벡터를 빠르게 찾아야 함
-
해결책:
- ANN (Approximate Nearest Neighbor) 알고리즘 사용 (예: HNSW, IVF)
- 벡터 DB에서 search latency를 10ms 이하로 줄이는 기술 확보
- Memory-mapped storage, RAM caching, quantization(PQ) 기법 활용
3. 동시성 및 시스템 아키텍처 최적화
-
실시간 시스템은 단일 질의 성능뿐만 아니라 동시 다수 요청 처리 능력도 중요
-
해결책:
- 마이크로서비스 기반으로 벡터화/검색 분리 (Embedding 서버 ↔ Vector DB 서버)
- 실시간 스트림 프레임워크 (Kafka, ROS 등)와 연계
- 벡터 DB는 미리 인덱싱된 데이터로만 검색하고, 새 벡터는 배치로 업데이트
실제 사용 예시
| 분야 | 사용 방식 |
|---|---|
| Tesla, Waymo | 실시간 영상에서 객체 인식 → 특징 벡터화 → 유사 장면 비교 및 판단 |
| Amazon Go | 영상 기반 사용자 행동 벡터화 → 행동 패턴과 유사도 비교 |
| 스마트 CCTV | 얼굴 인식 결과를 벡터로 변환 → 유사 인물 탐지 |
결론
-
실시간 유사도 검색은 가능하지만 고성능 하드웨어 + 최적화된 아키텍처 + 효율적인 알고리즘이 전제 조건입니다.
-
자율주행처럼 수밀리초 수준의 응답 시간이 요구되는 환경에서도 벡터 DB는 적극 활용되고 있습니다.
벡터와 벡터공간
벡터란?
- 벡터: 여러 개의 숫자로 이루어진 배열
- 예시
- 1차원 벡터:
[5] - 2차원 벡터:
[3, 4] - 3차원 벡터:
[2, 5, 1]
- 1차원 벡터:
- 활용 예시
- 위치 좌표:
[x, y] = [3, 4](지도상의 위치) - 색상 정보:
[R, G, B] = [255, 0, 0](빨간색)
- 위치 좌표:
벡터는 숫자로 이루어진 데이터의 표현 방식
고차원 벡터 공간이란?
- 벡터의 차원이 많아지면 고차원 벡터 공간이 됨
- 예: 텍스트를 벡터로 바꾸면 →
[0.2, 0.8, 0.5, 0.1, …]형태가 됨
- 이런 방식으로 텍스트, 이미지, 음성 등을 벡터로 변환 가능
벡터화 (Vectorization)란?
- 텍스트, 이미지, 오디오 등의 데이터를 벡터(숫자 배열)로 변환하는 과정
벡터 임베딩 (Embedding)이란?
- 데이터를 의미가 보존된 숫자 벡터로 변환하는 방법
- AI가 이해할 수 있도록 데이터를 표현하는 과정
벡터 임베딩은 데이터를 숫자로 변환하는 중요한 과정
벡터화 방법 예시
- 텍스트 → 벡터
Word2Vec: 단어의 의미를 숫자로 표현BERT: 문장의 의미까지 이해할 수 있도록 표현
- 이미지 → 벡터
CNN(합성곱 신경망)을 이용해 이미지의 특징을 벡터로 변환
- 오디오 → 벡터
MFCC,Wave2Vec등을 이용하여 음성을 벡터로 변환
BERT
BERT란?
- BERT (Bidirectional Encoder Representations from Transformers)는 자연어 처리(NLP)를 위한 인공지능 모델
- 구글에서 개발
- 문장의 맥락을 양방향(Bidirectional) 으로 이해하는 것이 특징
BERT의 특징
- 양방향 이해
- 기존 모델은 왼쪽 → 오른쪽 또는 오른쪽 → 왼쪽 한 방향만 학습
- BERT는 양방향으로 문장을 학습 → 문장 전체의 맥락을 더 정확히 파악 가능
- 문맥 이해 능력
- 예: "나는 은행에 갔다." → 금융기관인지, 강변인지 문맥으로 구분 가능 "나는 은행에서 돈을 찾았다." → "금융기관"으로 해석
- 예: "나는 은행에 갔다." → 금융기관인지, 강변인지 문맥으로 구분 가능 "나는 은행에서 돈을 찾았다." → "금융기관"으로 해석
- 사전 훈련 후 미세 조정 (Fine-tuning)
- 대량의 텍스트로 기본 학습 후
- 특정 작업(감성 분석, 번역 등)에 맞춰 세부 조정 가능
BERT의 활용 사례
- 검색 엔진 → 검색 결과의 정확도 향상 (예: 구글 검색)
- 챗봇 → 질문의 맥락을 이해하고 더 정확한 답변 제공
- 문장 의미 분석 → 문장의 긍정/부정 감정 분석, 질문-답변 시스템 등에 활용
BERT 간단한 실습 예제 (Hugging Face 사용)
1. 라이브러리 임포트
from transformers import BertTokenizer, BertModel2. BERT 토크나이저 불러오기
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")3. 예제 문장 정의
text = "I love natural language processing."4. 문장을 토큰화
tokens = tokenizer.tokenize(text)
print(tokens)5. 토큰을 인덱스로 변환
input_ids = tokenizer.encode(text, add_special_tokens=True)
print(input_ids)Hugging Face의 transformers 라이브러리를 사용하면 BERT 모델을 쉽게 불러와 문장을 토큰화하고, 모델이 이해할 수 있는 입력 형식으로 변환할 수 있습니다.
MFCC, Mel-Frequency Cepsrtal Coefficients
MFCC란?
- 음성 신호를 숫자로 변환(음성 벡터화)하는 기술
- 사람의 청각 특성을 반영하여 음성 데이터를 분석하는 데 유용
MFCC 원리 및 음성 처리 과정
원리
- 사람의 귀는 주파수가 낮은 소리에 더 민감함
- 이러한 청각 특성을 반영해 음성을 분석
음성 처리 과정
- 음성을 작은 조각(Frame)으로 나눔
- 각 조각을 푸리에 변환(Fourier Transform)하여 주파수 분석
- Mel 필터 적용 (인간 청각에 맞게 변환)
- Cepstrum 분석 (중요한 특징을 추출하여 벡터화)
→ 이 과정을 통해 음성을 숫자로 변환
활용 사례
- 음성 인식
- 예: "Siri, 오늘 날씨 어때?"
- 음성 감정 분석
- 사람의 감정을 분석해 상담 서비스에 활용
- 음성 인증 시스템
- 예: 은행 콜센터 등에서 목소리로 본인 확인
MFCC 실습 (Python - librosa 라이브러리 사용)
1. 라이브러리 임포트
import librosa
import librosa.display
import numpy as np
import matplotlib.pyplot as plt2. 음성 파일 로드
audio_file = "example.wav"
y, sr = librosa.load(audio_file, sr=22050)y: 음성 신호sr: 샘플링 레이트 (22050Hz)
3. MFCC 특징 추출
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)- 13개의 MFCC 계수를 추출
4. MFCC 시각화
plt.figure(figsize=(10, 4))
librosa.display.specshow(mfccs, x_axis="time")
plt.colorbar()
plt.title("MFCC")
plt.show()- MFCC 결과를 시간에 따라 시각화
요약
- 음성 데이터를 MFCC로 변환하고
- 변환된 결과를 시각화하여 분석에 활용
Wave2Vec
Wave2Vec 개요
설명
- 텍스트 레이블 없이도 음성 학습이 가능한 딥러닝 모델
- Facebook AI 연구팀이 개발
주요 특징
- 비지도 학습(Self-Supervised Learning)
- Wave2Vec은 음성 데이터만으로 사전 학습 진행
- 레이블이 없는 대량의 음성 데이터로도 학습 가능
- 음성을 직접 벡터로 변환
- 기존 방식(MFCC 등)은 중간 처리 과정이 필요
- Wave2Vec은 원본 음성(Waveform)을 바로 벡터로 변환 가능
- 적은 데이터로도 뛰어난 성능
- 기존 모델은 많은 데이터가 필요했으나
- Wave2Vec은 적은 데이터로도 높은 정확도 가능
활용 사례
- 자동 음성 인식 (ASR, Automatic Speech Recognition)
- 예: AI 비서, 콜센터 자동화
- 자연어 처리와 결합
- 음성을 텍스트로 변환 후 감정 분석 등 가능
- 다국어 음성 인식
- 적은 데이터로 다양한 언어 학습 가능
Wave2Vec 실습 예제 (Hugging Face 사용)
1. 라이브러리 임포트
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
import torch
import librosa2. Wave2Vec 모델 불러오기
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h")3. 음성 파일 로드
audio_file = "example.wav"
y, sr = librosa.load(audio_file, sr=16000)4. 음성을 모델 입력 형식으로 변환
input_values = processor(y, return_tensors="pt", sampling_rate=16000).input_values5. 모델 예측 수행
with torch.no_grad():
logits = model(input_values).logits6. 예측값을 텍스트로 변환
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)[0]
print(transcription)요약
- 음성 파일을 불러와 Wave2Vec 모델에 입력
- 음성을 텍스트로 변환하여 자동 음성 인식 구현 가능
Hugging Face
Hugging Face 개요
- 자연어 처리(NLP) 분야에서 유명한 AI 스타트업이자 오픈소스 커뮤니티
- AI 모델을 쉽게 사용할 수 있도록 다양한 도구와 라이브러리를 제공
주요 서비스 및 제품 - Transformers
- Transformers 라이브러리
- Hugging Face에서 제공하는 가장 유명한 오픈소스 라이브러리
- 다양한 사전 학습(pre-trained) 모델을 쉽게 사용할 수 있음
- 주요 모델 예시:
- BERT, GPT, T5, BART, RoBERTa, XLM-R 등
- 이 라이브러리를 통해 NLP 모델을 쉽게 로드, 훈련, 평가, 추론 가능
예시 코드
from transformers import pipeline
# 사전 학습된 모델을 사용한 감정 분석
classifier = pipeline('sentiment-analysis')
result = classifier("I love using Hugging Face!")
print(result)- Hugging Face의 사전 학습된 감정 분석 모델을 사용하여 주어진 텍스트의 감정을 분석
주요 서비스 및 제품 - Hugging Face Hub
- Hugging Face Hub
- 수천 개의 AI 모델과 데이터셋을 호스팅하는 플랫폼
- 다양한 모델을 다운로드하거나 자신만의 모델을 업로드 가능
- 텍스트, 이미지, 음성 등 여러 가지 유형의 모델과 다양한 언어를 지원
- 개발자들은 공개된 모델을 직접 사용하거나, 자신만의 모델을 공유할 수 있음
주요 서비스 및 제품 - Datasets
- Hugging Face Datasets
- 수백 가지의 NLP 중심 데이터셋을 포함한 라이브러리 제공
- 데이터를 쉽게 로드, 변환, 분석할 수 있음
- 예시 데이터셋:
- SQuAD
- GLUE
- CoNLL-03
주요 서비스 및 제품 - AutoNLP 및 AutoML
- AutoNLP
- 자동화된 NLP 모델 훈련과 최적화를 위한 서비스
- 프로그래밍 경험이 없어도 인터페이스를 통해 모델을 쉽게 훈련시키고 사용할 수 있음
Hugging Face – 핵심 특징
1. 오픈 소스
- Hugging Face의 Transformers 라이브러리는 완전 오픈 소스로 누구나 무료로 사용 가능
- 코드와 모델은 GitHub에 공개되어 있어, 누구나 자신의 모델을 업로드하거나 기여 가능
2. 다양한 사전 학습 모델 (Pre-trained)
- 다양한 사전 학습된 모델을 통해 AI 연구자와 개발자들이 이미 학습된 모델을 기반으로 빠르게 실험 및 적용 가능
- 많은 데이터로 학습된 고성능 모델이며, 텍스트 분석, 요약, 번역, 감정 분석 등 다양한 작업 가능
3. 편리한 사용
- 간단한 API와 파이프라인을 통해 복잡한 모델도 손쉽게 사용 가능
- 예:
pipeline함수를 쓰면 감정 분석, 텍스트 요약, 질의응답 시스템 등을 쉽게 구현할 수 있음
4. 협업 및 커뮤니티
- AI 커뮤니티가 잘 활성화되어 있어 여러 연구자들이 모델을 공유하고 협업 체계가 잘 구성되어 있음
