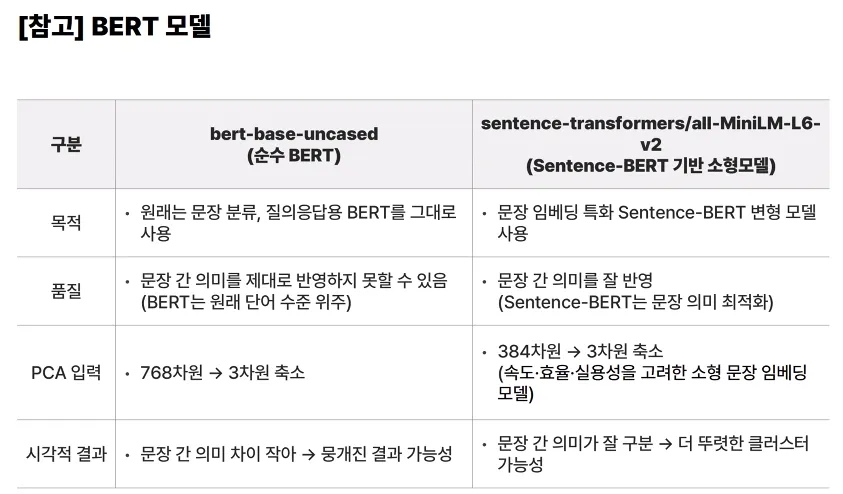
벡터 DB 소개
벡터 DB 정의
"고차원 벡터 데이터를 효율적으로 저장, 관리, 검색하기 위해 설계된 데이터베이스"
특징 및 설명
- 텍스트, 이미지, 오디오 등의 데이터를 임베딩(벡터화)하여 저장하고, 관리하며, 검색 기능을 제공하는 임베딩 벡터 전용 DB
- 고차원(벡터 차원 수)의 공간(인덱스)에 임베디드 벡터를 인덱싱하여 저장하는 방식
주요 기능
- 입력 Query와 가장 가까운 이웃을 찾아주는 방식 사용
- ANN (Approximate Nearest Neighbor) 기반 알고리즘으로 검색 효율성 향상
- 기본적인 CRUD (Create, Read, Update, Delete) 지원
- 벡터 DB 서비스 제공자마다 서로 다른 인덱싱 및 검색 알고리즘 방식 사용
처리 단계
- Indexing
- Querying
- 이외에도 검색 성능을 높이기 위한 추가 단계:
- Loading
- Transforming
- Post-Processing (→ 벡터 DB가 자체적으로 지원하거나 외부에서 처리)
목적
- 비정형 데이터를 벡터화하여
- 유사한 데이터를 빠르게 찾을 수 있도록 설계된 시스템
주요 특징 - 확장성
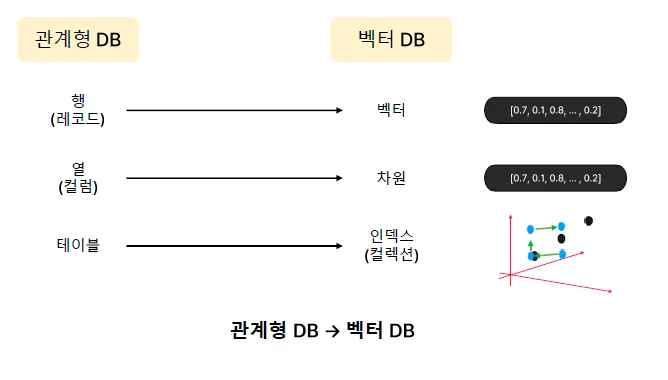
기존 DB와 벡터 DB의 차이
| 확장 방식 | 전통적 RDB | 벡터 DB |
|---|---|---|
| Scale-up (수직 확장) | 서버 성능을 업그레이드 | 성능 개선 한계 존재 |
| Scale-out (수평 확장) | 어려움 (데이터 분할, 샤딩 필요) | 클러스터를 통해 쉽게 확장 가능 |
벡터 DB의 수평 확장 방식
- Sharding (샤딩)
- 벡터 데이터를 여러 노드에 분산 저장
- 예: 10억 개의 벡터를 10개 노드에 1억 개씩 배치
- Distributed Indexing (분산 인덱싱)
- 검색 시 여러 노드에서 병렬로 처리하여 속도 향상
- 예: HNSW + IVF를 혼합 적용 가능
- Load Balancing (부하 분산)
- 대량의 검색 요청을 균등하게 분배하여 성능 유지
- 예: 여러 개의 검색 서버가 동시에 요청 처리
활용 사례
- AI 기반 이미지 검색 서비스
- 수억 개 이미지 저장 및 검색
- 대규모 추천 시스템
- 예: Netflix, Amazon 등의 제품 추천 시스템
주요 특징 - 메타데이터 통합 관리 기능
메타데이터란?
- 벡터와 함께 저장되어 검색 결과에 대한 추가 정보를 제공하는 데이터
- 벡터 데이터 자체는 숫자(좌표)로 표현되기 때문에, 실제 의미를 설명할 부가 정보가 필요함
예시
| 벡터 데이터 | 메타데이터 (추가 정보) |
|---|---|
| [0.2, 0.8, -0.5] | "이미지 파일: cat.jpg, 업로드 날짜: 2025-03-18" |
| [0.7, -0.2, 0.4] | "논문 제목: AI in Healthcare, 저자: Dr. Kim" |
활용 사례
- AI 검색엔진: 사용자 입력 텍스트와 유사한 문서를 찾은 후 제목, 저자, 링크 제공
- 전자상거래 추천 시스템: 유사한 제품 추천 시 상품명, 가격, 브랜드 등 함께 표시
- 의료 데이터 분석: 환자 유사도 검색 시 환자 ID, 병원, 진료 기록 등과 연계
메타데이터를 활용한 향상된 검색
- 벡터 검색 이후, 필터링(Query Filtering) 가능
- 예: '강아지 이미지' 검색 결과 중 최근 1년 이내 업로드된 데이터만 조회
주요 특징 - 동적 데이터 업데이트 지원
기존 RDB의 문제점
- 새로운 데이터를 추가할 때 전체 인덱스를 다시 생성해야 함
- → 처리 속도 느림
- 벡터 데이터는 고차원 공간에 위치해 있기 때문에 위치가 바뀌면 업데이트가 어려움
벡터 DB에서의 동적 업데이트 방식
- Incremental Indexing (점진적 인덱싱)
- 전체 인덱스를 재구성하지 않고 기존 인덱스에 새 데이터를 추가
- 예: HNSW 방식에서 새로운 노드를 기존 구조에 연결
- Lazy Update (지연 업데이트)
- 벡터를 즉시 반영하지 않고, 일정 시간 후 일괄 업데이트(batch)
- 검색 성능 유지하면서 동적 데이터 반영 가능
- Delete & Rebuild (삭제 후 재구성)
- 일정 시간마다 불필요한 벡터를 삭제하고 인덱스를 재구성하여 최적화 유지
활용 사례
- 실시간 감성 분석: SNS에서 사용자 감정(긍정/부정)을 업데이트하여 최신 트렌드 반영
- 보안 시스템 (얼굴 인식): 새로운 얼굴 벡터를 실시간으로 추가하여 보안 강화
- 뉴스 추천 시스템: 새로운 기사가 추가되면 즉시 벡터화하여 추천 시스템에 반영
벡터 DB의 중요성
- 대용량 데이터도 빠르게 검색 가능
- 고속 검색을 위한 알고리즘 활용: 예) HNSW, IVF, PQ 등
- 고속 검색을 위한 알고리즘 활용: 예) HNSW, IVF, PQ 등
- 메타데이터 통합 관리
- 검색 결과에 부가 정보를 함께 제공하여 더 풍부한 결과 도출 가능
- 실시간 데이터 업데이트 지원
- 새로운 데이터가 추가되면 즉시 반영 가능, 최신 상태 유지
벡터 DB는 AI 시대의 필수 기술
- OpenAI, Google, Facebook 등에서 사용하는 핵심 기술
- AI 모델을 활용한 다양한 서비스에 적용됨
- 예) 추천 시스템, 보안, 검색, 자연어 처리(NLP), 의료 AI 등
#3. 벡터와 벡터 공간

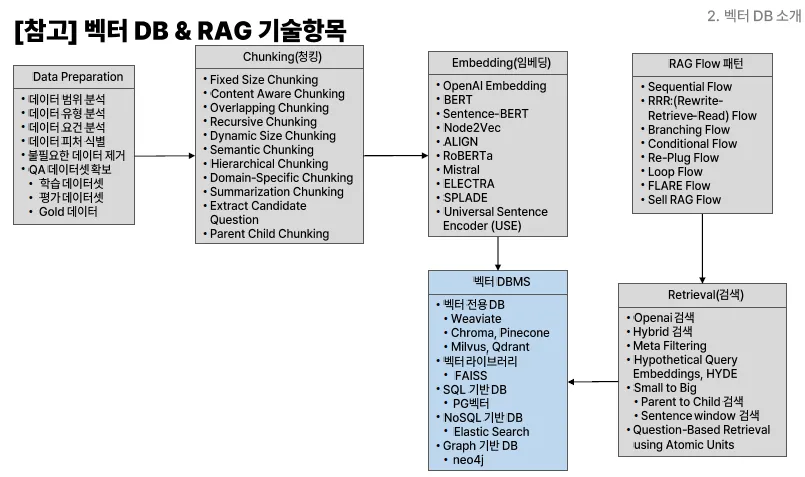
유클리드 거리 (Euclidean Distance)
- 가장 기본적인 거리 측정 방식
- 두 벡터 간의 직선 거리(피타고라스 정리 기반)를 계산
- 저차원(2D, 3D)에서는 효과적이지만, 차원이 증가할수록 성능이 저하
공식:
고차원에서의 문제점
- 차원의 저주 (Curse of Dimensionality)
- 차원이 높아질수록 벡터 간 거리가 균등하게 증가
- → 거리 기반 검색의 효용이 떨어짐
- → 데이터가 희소해지고, 유사한 벡터를 찾기 어려워짐
- 유사한 벡터 간 거리 차이가 작아짐
- 고차원 공간에서는 대부분의 점들이 서로 비슷한 거리를 가지게 되어, 분별력이 낮아짐
해결 방법: 코사인 유사도 (Cosine Similarity)
- 벡터 간의 방향(각도)를 비교하여 유사도를 측정
- 방향이 중요한 경우에 효과적 (예: 자연어 처리에서 단어 벡터)
공식:
- 0도 (동일 방향): 유사도 = 1
- 90도 (직각): 유사도 ≈ 0
- 180도 (반대 방향): 유사도 = -1
요약
- 고차원 공간에서는 유클리드 거리보다 코사인 유사도가 더 적합한 경우가 많음
- 특히, 단어 임베딩이나 BERT 등의 자연어 처리 벡터에서는 방향 정보가 중요
벡터 DB
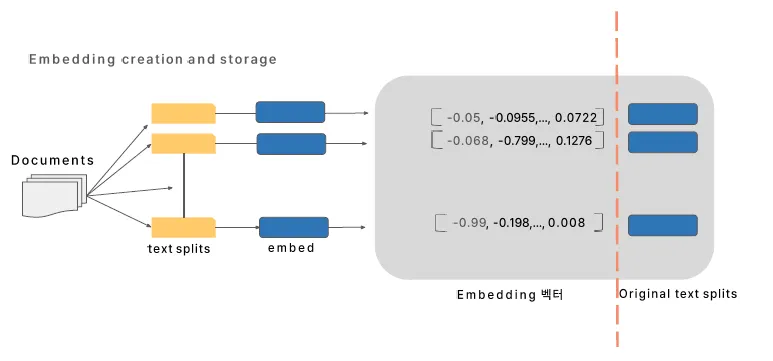
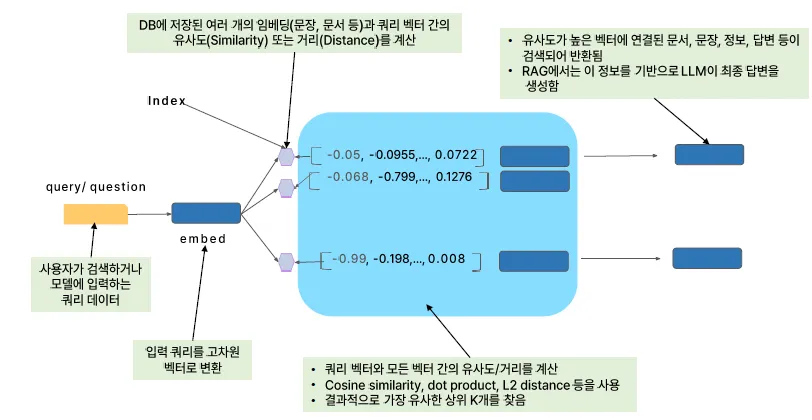
쿼리가 들어오면 Index를 비교
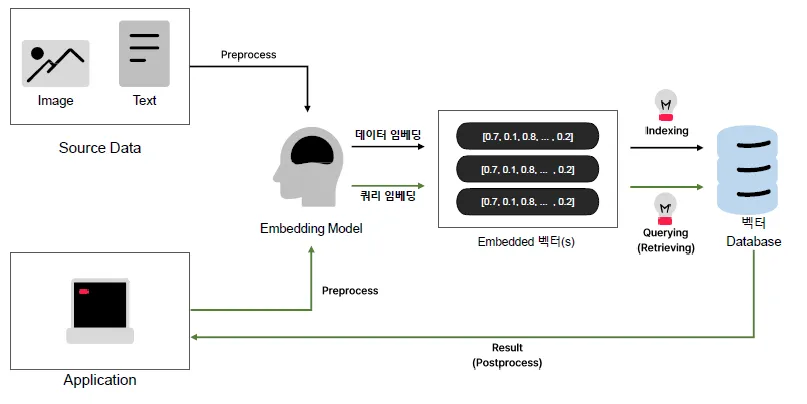
전체 프로세스
관계형 VS 벡터 DB
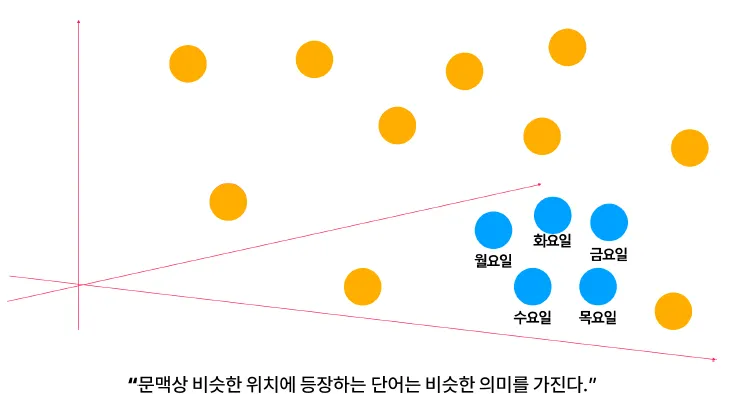
벡터 Embedding 기초
단어, 문장, 이미지 같은 데이터를 숫자로 변환하는 과정
비유: 도시 위치
- 우리가 살고 있는 도시는 비슷한 지역끼리 가까운 위치에 배치되어 있음
- 서울 vs. 부산 → 같은 나라, 비슷한 카테고리
- 서울 vs. 도쿄 → 가깝지만 다른 나라, 유사성 존재
- 서울 vs. 고양이 → 완전히 무관, 관련 없음
벡터 임베딩과의 연관성
- 벡터 임베딩도 같은 원리
- 비슷한 의미를 가진 단어나 이미지끼리는 가까운 숫자 벡터로 변환
벡터 임베딩의 목적
- 텍스트, 이미지, 소리 등 비정형 데이터를 숫자로 표현하는 과정
- 컴퓨터가 의미를 이해하고, 이를 통해 검색, 추천, 번역 등에 활용
요약하자면, 벡터 임베딩은 의미가 비슷한 데이터들을 공간상에서 가깝게 위치시키는 방식이며, 이를 통해 AI는 인간처럼 유사성을 판단할 수 있게 됩니다.
word2vec → BERT
Word2Vec (2013)
- 아이디어
- "비슷한 의미의 단어들은 벡터 공간에서 가깝게 위치할 것"
- 단어를 숫자로 변환하여 의미를 벡터화
- 특징
- 단어를 고정된 벡터로 표현 (문맥 고려하지 않음)
- 문맥 이해 부족 → 예: “bank”가 은행인지, 강변인지 구분 불가
- 예시 벡터
단어 Word2Vec 벡터 예시 king [0.2, 0.5, 0.8] queen [0.3, 0.6, 0.6] apple [0.8, 0.1, 0.2] - 장점
- 연산 가능: "king - man + woman = queen"과 같은 관계 유추 가능
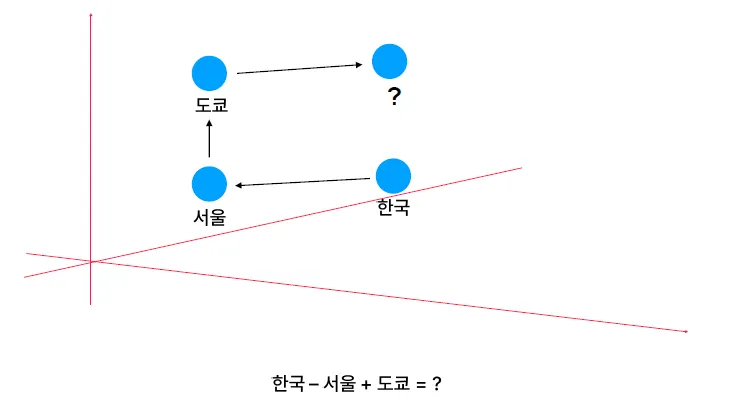
해당 연산이 답은 “일본”
BERT (2018, Google)
- 개요
- Word2Vec의 한계를 개선한 최신 기법
- 문맥을 반영하여 단어의 의미를 더 정교하게 임베딩
- 특징
- Transformer 기반 모델
- 문장의 양방향 문맥을 활용하여 단어의 의미 파악
- 예: "나는 은행(bank)에서 돈을 찾았다." → 금융 "강둑 은행(bank)에 앉아 있었다." → 강변 → 문맥에 따라 의미를 정확히 구분 가능
- 활용
- 문장 의미 파악, 검색, 챗봇, AI 번역 등 다양한 NLP 응용에 활용
핵심 비교 요약
| 항목 | Word2Vec | BERT |
|---|---|---|
| 문맥 반영 | 안 함 | 함 |
| 벡터 표현 | 단어당 고정 | 문장에 따라 달라짐 |
| 기반 모델 | 간단한 신경망 | Transformer 구조 |
| 활용 분야 | 단어 유사성, 관계 유추 | 검색, 번역, 질문응답 등 넓음 |
Word2vec 학습 메커니즘
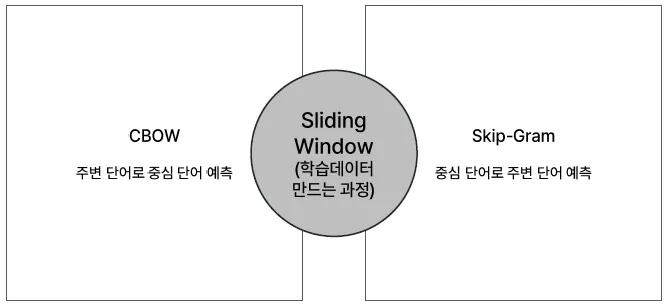
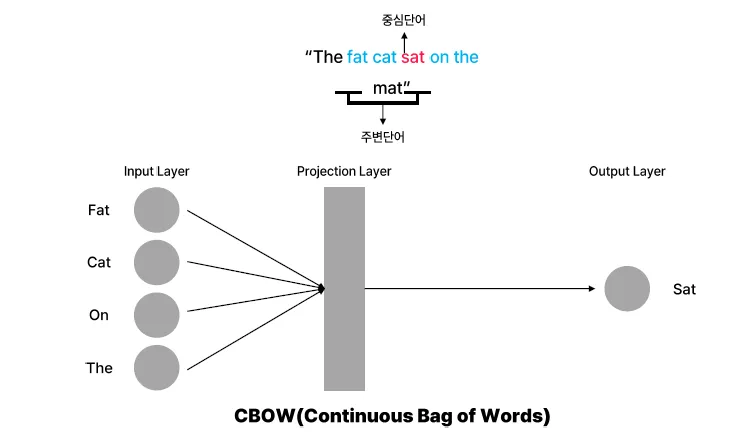
CBOW (Continuous Bag of Words)
- 개념: 문맥(Context) 단어를 보고 중심 단어(Target Word)를 예측하는 방식 예: "나는 맛있는 피자를 먹었다."
- 중심 단어: "피자"
- 주변 단어: ["나는", "맛있는", "먹었다"] → 입력: ["나는", "맛있는", "먹었다"] → 출력: "피자"
- 구조: 입력(주변 단어) → 신경망 학습 → 출력(중심 단어 예측)
- 특징:
- 학습 속도가 빠름
- 자주 등장하는 단어 예측에 유리
- 문맥을 고려한 예측 가능
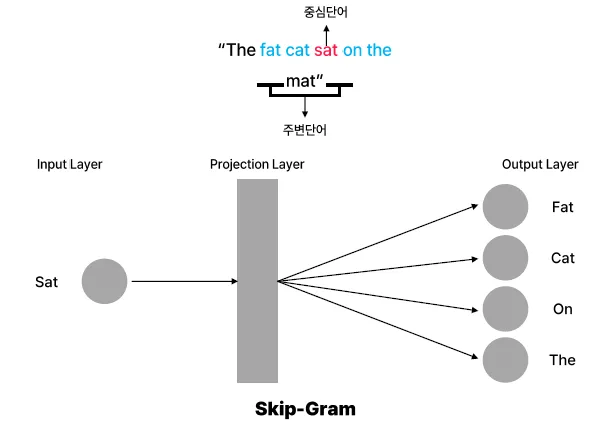
Skip-Gram
- 개념: 중심 단어(Target Word)를 보고 주변 단어(Context Words)를 예측하는 방식 예: "나는 맛있는 피자를 먹었다."
- 중심 단어: "피자"
- 주변 단어: ["나는", "맛있는", "먹었다"] → 입력: "피자" → 출력: ["나는", "맛있는", "먹었다"]
- 구조: 입력(중심 단어) → 신경망 학습 → 출력(주변 단어 예측)
- 특징:
- 희귀 단어 학습에 강함
- CBOW보다 학습 속도는 느림
- 데이터가 적을 때도 성능이 좋음
요약 비교
| 항목 | CBOW | Skip-Gram |
|---|---|---|
| 입력 | 주변 단어 | 중심 단어 |
| 출력 | 중심 단어 | 주변 단어들 |
| 학습 속도 | 빠름 | 느림 |
| 특징 | 자주 쓰는 단어 학습에 유리 | 희귀 단어 학습에 유리 |
| 데이터 요구 | 데이터 많을 때 성능 좋음 | 데이터 적을 때도 잘 작동 |
윈도우 크기와 문맥(Context)
- 윈도우 크기 2 라면:
- 중심 단어 기준으로 앞쪽 2개, 뒤쪽 2개의 단어를 문맥으로 보는 것을 의미
- 예: 중심 단어가 "fox"일 때 → 문장: the quick brown fox jumps over the lazy dog → 주변 단어: ["quick", "brown", "jumps", "over"]
- CBOW 모델: 주변 단어를 보고 중심 단어를 예측
- Skip-Gram 모델: 중심 단어를 보고 주변 단어를 예측
- 윈도우 크기가 n이라면, 주변 단어 수는 총 2n개
정의
문장 전체에 슬라이딩 윈도우를 적용하여 학습용 데이터를 만드는 과정을
슬라이딩 윈도우(sliding window) 라고 부름.
Word2Vec의 한계점
1. 문맥 무시
- 같은 단어라도 문맥에 따라 의미가 달라질 수 있음 → 기존 임베딩은 이를 고려하지 않음
- 예시:
- "단풍잎이 시뻘겋다."
- "얼굴이 시뻘겋다." (같은 단어 "시뻘겋다"지만 의미 다름)
2. 다의성 해결 불가
- 같은 단어인데도 여러 의미(다의어)를 가지는 경우 하나의 벡터로만 표현됨
- 예시:
- "모자(cap)" → 모자(의류), 모자(엄마와 아들) → 의미 구분 불가
- "모자(cap)" → 모자(의류), 모자(엄마와 아들) → 의미 구분 불가
3. 장기 의존성 문제
- 기존 모델은 근처 단어에만 의존하여 학습함
- 멀리 떨어져 있어도 의미적으로 연관된 단어 간의 관계를 반영하지 못함
- 예시:
- "나는 많은 나라를 여행했고, 그 중 프랑스는 내가 좋아하는 나라 중 하나였다." → "프랑스"와 "좋아하는 나라" 사이의 연관성 반영 어려움
- "나는 많은 나라를 여행했고, 그 중 프랑스는 내가 좋아하는 나라 중 하나였다." → "프랑스"와 "좋아하는 나라" 사이의 연관성 반영 어려움
이미지 임베딩 : CNN 기반 특성 추출
CNN (합성곱 신경망, Convolutional Neural Network)
1. CNN의 개념
- CNN은 사람이 이미지를 볼 때, 먼저 큰 특징(예: 얼굴, 배경)을 보고, 점차 세부적인 특징(예: 눈, 입, 턱)을 인식하는 방식과 유사한 구조로 설계된 딥러닝 모델이다.
2. CNN의 핵심 과정
- Conv Layer (합성곱 층) 필터를 사용하여 이미지에서 엣지, 모양 등 중요한 패턴을 추출한다.
- Pooling Layer (풀링 층) 정보를 압축하여 연산 속도를 높이고, 불필요한 부분을 제거한다.
- Fully Connected Layer (완전 연결 층) 벡터화된 정보를 바탕으로 객체(강아지, 고양이, 사람 등)를 분류한다.
3. 활용 방식
- CNN은 이미지를 숫자 벡터로 변환하여, 유사한 이미지끼리 벡터 간의 거리로 비교할 수 있도록 한다.
- 예: 얼굴 인식 시스템에서는 비슷한 얼굴일수록 유사한 벡터 값을 갖게 되어, 이를 기반으로 얼굴을 매칭한다.
멀티모달 임베딩 (텍스트 + 이미지 결합)
멀티모달 (Multimodal)
1. 개념
- 여러 형태의 데이터를 동시에 이해할 수 있는 AI 모델 예: 텍스트, 이미지, 음성 등을 함께 처리
- 예: ChatGPT 같은 AI가 "고양이"라는 텍스트를 입력받고 실제 고양이 이미지를 찾아낼 수 있는 기능
예시 및 적용 사례
CLIP (OpenAI)
- 텍스트(예: 설명)와 이미지(예: 사진)를 동일한 벡터 공간에 배치
- 예: "개"라는 단어를 입력하면 개와 관련된 이미지 벡터를 가까운 위치로 매칭시킴
DALL·E (OpenAI)
- 텍스트로 설명한 내용을 바탕으로 AI가 이미지를 생성
멀티모달 임베딩 방식의 예
- 텍스트: "바닷가에서 노는 강아지"
- 이미지 벡터: 실제 바닷가에서 노는 강아지 사진
- 벡터 비교: 텍스트 벡터와 이미지 벡터 간의 거리를 계산해 가까운 것을 매칭
→ 검색 엔진에서 "강아지"라고 검색하면 강아지 이미지가 자동으로 나오는 원리와 유사
정리: 벡터 임베딩 기초
1. 벡터 임베딩이란?
- 데이터를 숫자로 변환하여 AI가 이해할 수 있도록 하는 과정
2. 텍스트 임베딩 (Word2Vec → BERT)
- 문맥을 이해하는 방식으로 발전
- 검색, 번역, 챗봇 등 다양한 자연어 처리 분야에서 활용됨
3. 이미지 임베딩 (CNN 기반)
- 이미지의 특징을 벡터로 변환
- 검색, 분류, 추천 시스템 등에 사용됨
4. 멀티모달 임베딩 (텍스트 + 이미지 결합)
- AI가 텍스트와 이미지를 동시에 이해하도록 하는 기술
- 대표 예: CLIP, DALL·E 등