[논문리뷰] Grandmaster-Level Chess Without Search
abstract
- 최근 machine learning에서의 큰 성공들은 주로 scale(규모)에서 나오고 있음
- 예를 들어, attention-based architectures나 large datasets 등이 이와 같음
- 본 논문에서는 (1) 1천만 개의 chess game datasets을 이용하여 (2) 2억 7천만 parameter를 가지는 transformer model로 지도 학습을 진행함
- 기존 : 복잡한 휴리스틱이나 explicit search, 또는 이 둘의 조합에 의존하고 있는 chess engines 사용
- datasets의 각 보드에는 Stochfish 16엔진(체스 엔진)으로 얻어낸 action 값들이 주석으로 달려 있고, 이로 인하여 150억 개의 data point가 생성된다고 함
- 본 논문의 contributions은 아래와 같음
- Stochfish 16의 approximation을 neural predictor로 distill하여 novel board states에 대해서도 잘 일반화 됨
- 인간 player 대랑 Lichess blitz Elo는 2895에 이르고, search 없이도 성공적인 chess play가 가능함
- ELO rating system : 대결 게임에서 사용하는 실력 측정 및 평가 산출법. '플레이어가 보여주는 실적은 정규분포의 확률변수이고 이것의 평균이 플레이어의 실력이며 실력은 시간에 따라 서서히 변화한다' 라는 가정을 기반으로 특정 기간의 모든 유저들의 게임들을 모은 뒤 ELO 분포를 업데이트 함
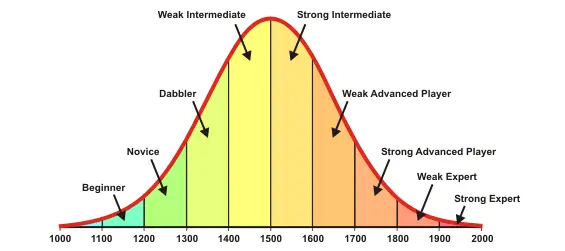
- 2024년 5월 23일 기준 ELO 1등 점수는 2830
- Stochfish 16의 ELO는 3640 정도 된다고 함
- ELO rating system : 대결 게임에서 사용하는 실력 측정 및 평가 산출법. '플레이어가 보여주는 실적은 정규분포의 확률변수이고 이것의 평균이 플레이어의 실력이며 실력은 시간에 따라 서서히 변화한다' 라는 가정을 기반으로 특정 기간의 모든 유저들의 게임들을 모은 뒤 ELO 분포를 업데이트 함
- model size와 dataset size의 ablations을 진행하여 robust generalization이나 strong chess play 를 위해서는 충분한 scale이 필요함을 보임
1. Intro

- 1997년 IBM의 딥블루가 세계 체스 챔피언 Garry Kasparov를 이기면서, 인공지능이 인간을 이길 수 있다는 최조로 중요한 단서가 됐다고 함
- 딥블루는 chess knowledge와 휴리스틱 알고리즘을 결합한 것으로 tree search algorithm을 사용했고, Stochfish 16도 이와 유사한 방법을 이용하고 있음
- 대체로 game AI에서 위와 같은 방법을 이용하는데, AlphaZero(2017)는 휴리스틱 알고리즘을 사용하지만 사람의 game 지식을 사용하지 않음
- 과거의 딥블루처럼 AI systems의 규모를 확장하는 ‘획기적인 발전’을 이루고 있는 ChatGPT, LLaMA, Gemini 등 주로 attention-based architecture를 기반으로 이루어져 있음
- 본 논문에서는 “Explicit search 없이 strong chess policy를 얻기 위해 지도 학습을 사용할 수 있는가?” 에 대해 중점적으로 다뤄보고자 함
- 이를 위해 standard supervised learning & standard attension-based architecture를 이용해 predictors를 학습시킴
- 이를 위해 standard supervised learning & standard attension-based architecture를 이용해 predictors를 학습시킴
2. Method
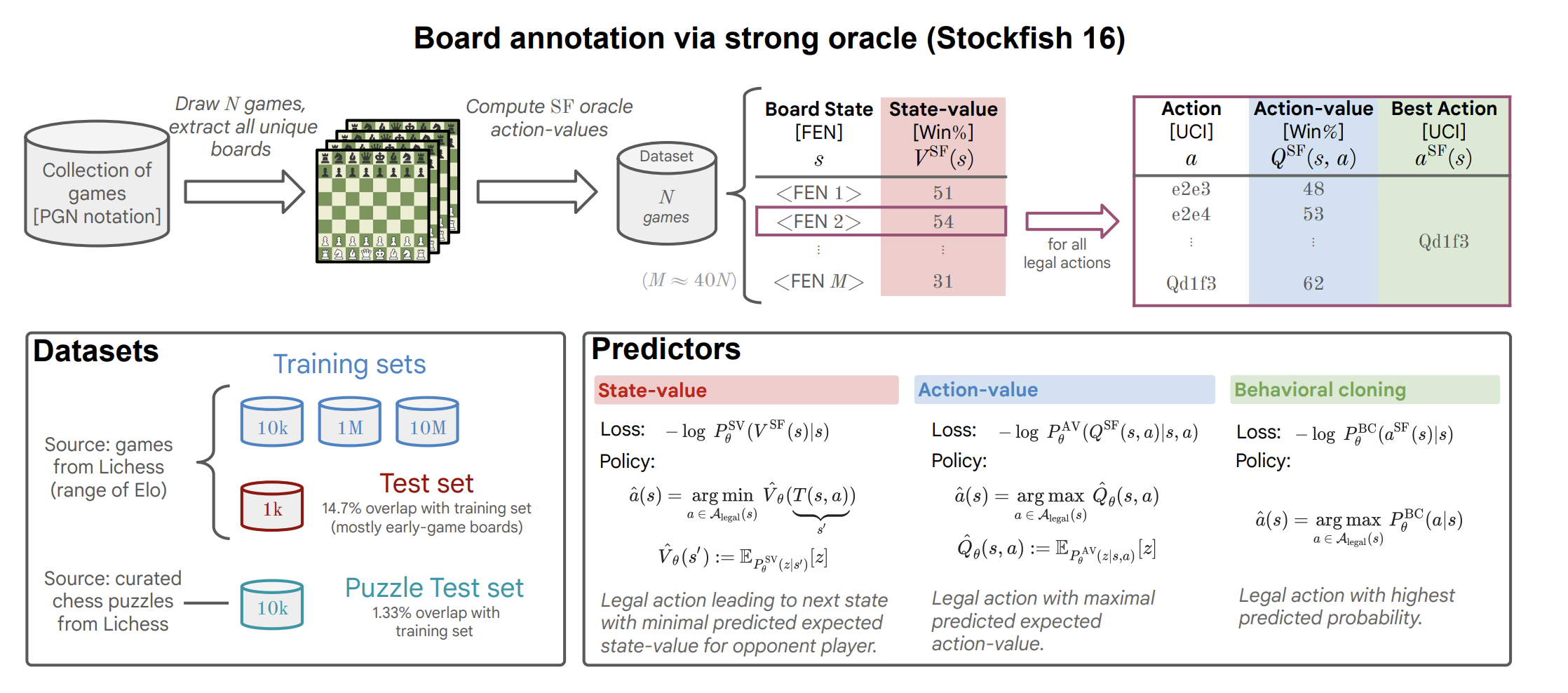
Data
| key | value |
|---|---|
| Training data | Lichess에서 1천만 게임을 다운로드하여 1532억개의 데이터 (state-value, action value) 생성 |
| Test data | • training data와 다른 기간의 1천만 게임을 다운로드, 보드 초반은 training data와 중복이 있을 수 있음 (14.7%의 중복 존재) |
| Puzzle data | • 1만 개의 어려운 보드 상태, correct sequence of move를 제공 (evaluation data 같은 느낌?) |
[State-Value]
- 모든 보드 상태 s를 추출, Stockfish 16으로 각 상태의 State-value 를 추정
- 이때 unbounded depth and level로 50ms 시간 제한
- State-value는 Stochfish가 추정한 승률로 0 ~ 100% 사이 값을 가짐
[Action-Value]
- 각 상태 s에서 가능한 legal action 에 대해 Stockfish 16으로 Action-values 를 추정
- 이때 unbounded depth and max skill level로 50ms 시간 제한
마지막으로, predictor는 classifier이기 때문에, 승률을 구간화하여 K 개의 classes를 만듬 (0 ~ 100% 사이 구간 균일하게 나눔 )
Tokenization
- 보드 상태 s는 FEN 문자열로 인코딩됨

- FEN 은 보드 상의 말의 위치 / 차례 / 양쪽 플레이의 캐슬링 가능 여부 등을 내타냄
- Action은 단일 토큰으로 나타내며, 모든 가용 action은 1969개
Predictors and Policies
[Action-value prediction]
- Action-value 를 구간화한 를 예측하는 predictor
with - Action-value가 최대가 되는 action을 선택
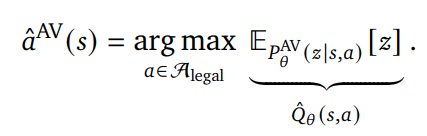
[State-value prediction]
- State-value를 구간화한 를 예측하는 predictor
with - State-value
- 현재 state에서 도달 가능한 모든 next state s’에 대해 평가하고, s’의 평가값이 가장 작은 action을 선택함
- s’은 상대방 차례를 의미하기 때문에, state-value가 높을 수록 나에게는 안 좋은 action이 됨 (state-value는 승률)
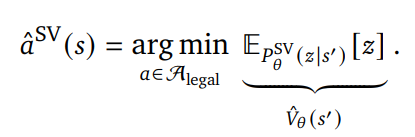
[Behavioral cloning]
- 현재 state에서의 ground truth action 의 index를 예측
- 가장 높은 확률의 action을 예측함
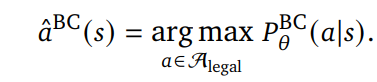
Evaluation
[Action-accuracy]
- ground-truth의 best action이 선택되는지에 대한 정확도
[Action-ranking]
- ground-truth action과 예측된 action의 순위 상관 관계 ( -1 ~ 1)
- ground-truth 순위는 Stochfish의 action-value 로 제공됨
[Puzzle-accuracy]
- 399 ~ 2867 Elo 난이도의 puzzle set에서 평가
- action 순서가 알려진 solution의 action 순서와 정확하게 일치하는지에 대한 퍼센트를 의미
[Game Playing strength(ELO)]
- Lichess에서 봇이나 사람과 400 게임 진행
- BayesElo (Coulom, 2008)를 사용하여 Elo 등급을 계산
3. Results
Main result
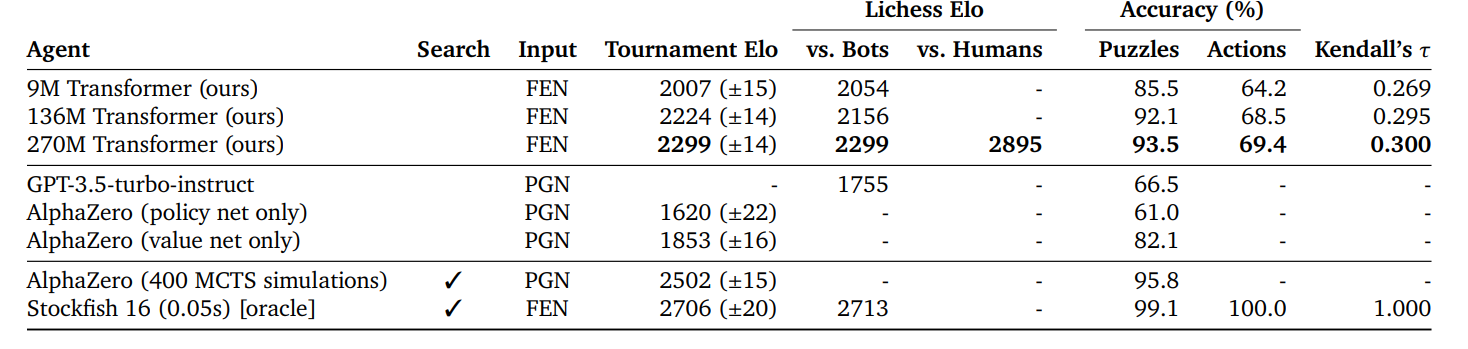
- vs 인간이 vs 봇 보다 더 점수가 높은 이유. 명확한 이유는 모르지만, 세 가지 가능성이 있음
- 인간은 ‘기권’을 하지만 봇은 기권을 하지 않음
- 인간 vs 봇에 대한 대전 정보가 거의 없기 때문에 제대로된 ELO를 계산할 수 없음
- 본 논문의 모델은 가끔 전술적 실수를 하며, 공격적인 스타일을 가짐. 이는 전술적 계산에 능한 엔진에게는 잘 작동하지 않음.
- 봇에 의한 대부분의 패배는 하나의 전술적인 실수만으로도 일어남.
Puzzles
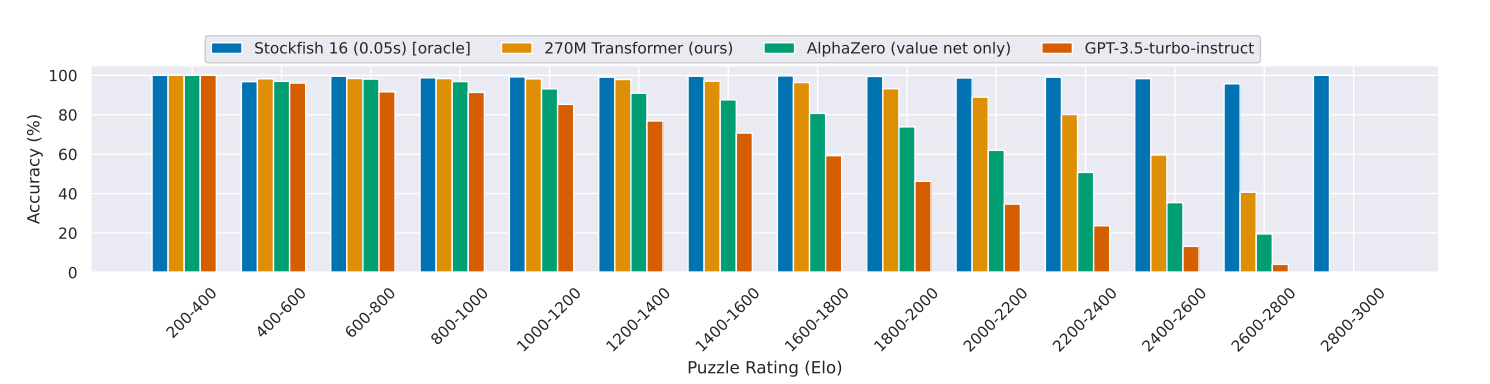
- Alphazero의 value net only 로 평가에 사용한 이유 (뇌피셜)
- puzzle을 해결하기 위해 정확한 시퀀스가 필요함. policy는 explicitly plan을 계획할 수 없기 때문에 좋은 가치를 추정하는 것이 중요하다고 함.
- 따라서 가치 추정을 위한 value network를 이용해 평가를 했다? (???)
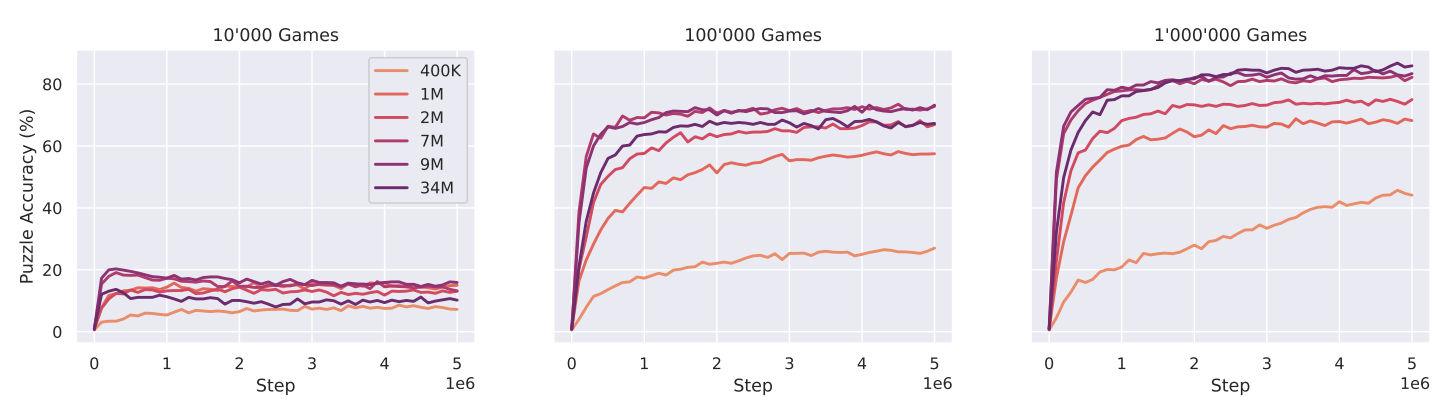
Scaling “Laws”
- 왼쪽 적은 dataset에서는 모델의 크기가 클 수록 overfitting 되는 것을 볼 수 있고, 오른쪽으로 가서 dataset이 커질 수록 최종 정확도가 증가하는 것을 볼 수 있음
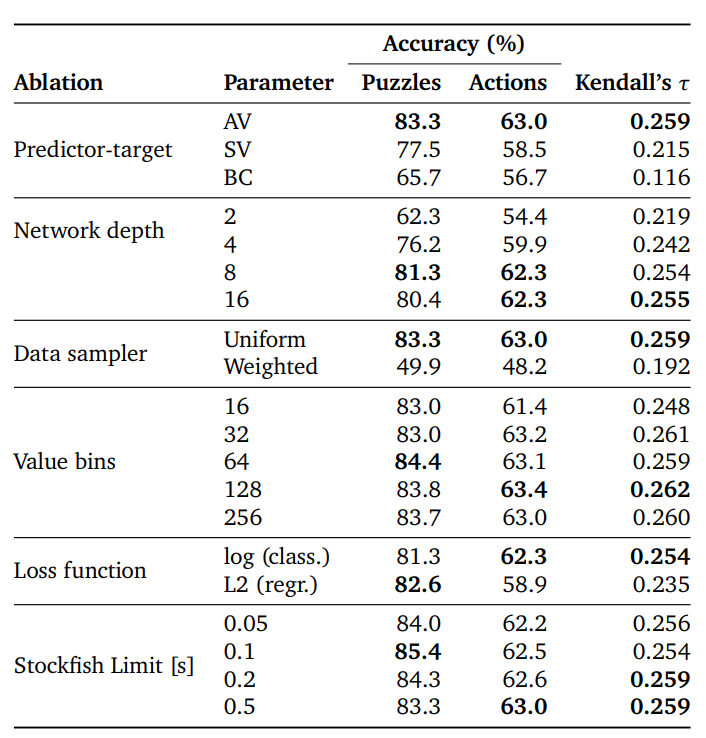
Variants and Ablations
4. Related Work
- 체스 인공지능 연구는 초기에는 명시적인 탐색 전략과 휴리스틱을 설계하는 데 중점을 두었음
- 대형 언어 모델의 등장은 체스 인공지능에서도 혁신을 가져옴
- 예를 들어, Kamlish의 언어 기반 모델(Kamlish et al., 2019), 체스 게임의 자연어 인코딩(DeLeo and Guven, 2022; Toshniwal et al., 2022) 및 LLM의 체스 플레이 능력 평가(Carlini, 2023; Gramaje, 2023) 등
5. Limitations
Limitations
- 모델의 성능이 높긴 하지만, 아직 Stockfish 16을 완전하게 따라잡지는 못함
- 하지만 충분한 데이터의 추가와 충분히 큰 모델을 사용한다면, 이런 차이는 결국 메울 수 있다고 생각
- 현재는 게임 히스토리에 기반한 예측을 하지 않음
- next state s’만 보기 때문에, search 의 영역이 작음 (이는 논문에서 주장하고 있는 no search 방법과 상충됨)
6. Conclusion
- transformer 활용 지도 학습으로 체스 잘 둘 수 있다!
- 경험하지 않았던 보드 상태에서도 일반화 잘 되더라!
- 이와 같은 결과는 (1) 충분한 데이터 (2) Large model 이기 때문이다!

RL하는 사람