
| 항목 | 링크 |
|---|---|
| 논문 | https://arxiv.org/pdf/2402.05546 |
Introduction
-
Machine learning 분야에서 최근 몇년간 model과 dataset size 의 규모를 키우는 것이 큰 성능 향상을 가져옴
- 예를 들어, chatgpt 나 gemini 등 엄청난 성과들을 볼 수 있음

- 예를 들어, chatgpt 나 gemini 등 엄청난 성과들을 볼 수 있음
-
Imitation learning 분야인 Behavior cloning (주어진 데이터셋을 기반으로 학습)도 위 사례와 유사하게, 규모의 확장을 통해 Multi-task 학습 성능이 엄청 증가했다고 함
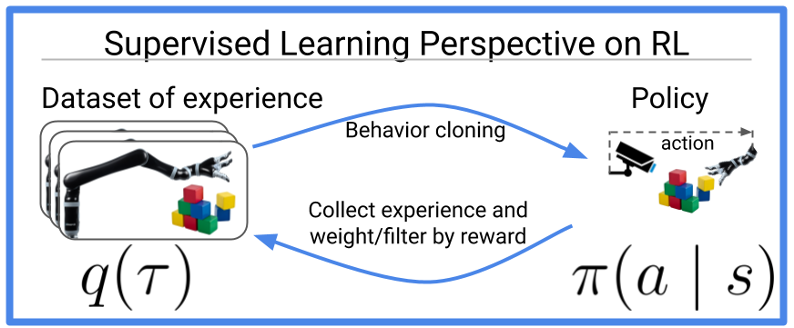
[출처 : Reinforcement learning is supervised learningo n optimized data (https://bair.berkeley.edu/blog/2020/10/13/supervised-rl/)] -
하지만 Behavior Cloning은 높은 품질의 데이터를 필요로 하고, robotics 에서는 높은 품질의 데이터를 얻는 것이 굉장히 어렵다고 함
-
따라서 본 논문에서는 sub-optimal data나 학습 과정 중에 만들어내는 데이터 (사람의 개입 없이)를 이용해 학습할 수 있는 Offline RL 알고리즘을 제안하고 있음
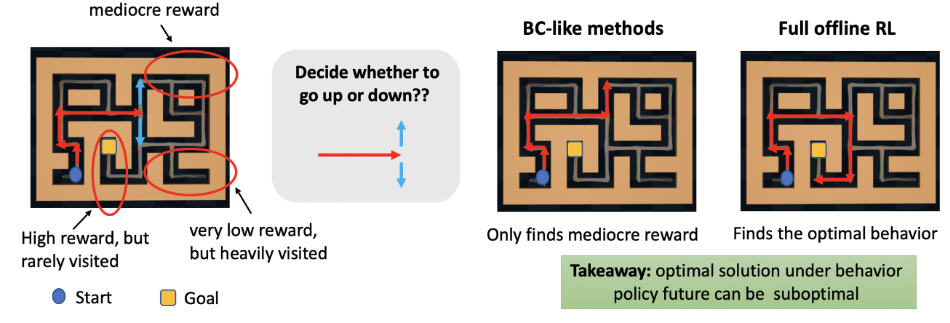
[출처 : Should I Use Offline RL or ImitationLearning? (https://bair.berkeley.edu/blog/2022/04/25/rl-or-bc/)]
Method
Perceiver-Actor-Critic : PAC
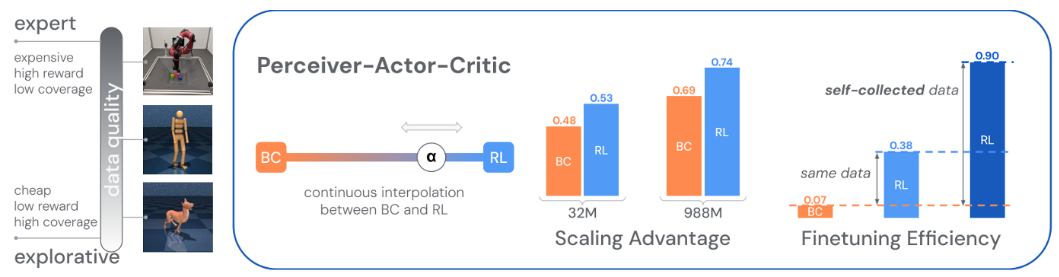
- 본 논문에서는 PAC 라는 offline actor-critic algorithms을 제안하고 있고, 이 알고리즘을 통해 large model과 dataset 으로 규모를 확장할 수 있다고 함
- 강화학습으로 학습하면서 sub-optimal \& 스스로 생성한 데이터셋에 대한 이점을 가져가면서
- expert dataset 에 대해서는 Behavior cloning 의 이점을 가져가는 방법 (supervised learning term 이용)
Notation
- ChatGPT에게 보기 좋게 정리해달라고 했다 :)

Equations
-
본 논문의 Objective function은 아래와 같음

-
위 function은 세 가지 terms으로 구성되어 있음
- 빨간 색 term : 강화학습에 대한 term. 주어진 데이터셋을 기반으로 향상된 정책인 pi imp가 있을 때, pi imp와 가까우면서도 더 좋은 행동을 찾도록 학습하는 term
- 이때 pi imp와 너무 멀어지지 않도록 KL divergence를 활용함
- 노란색 : Behavior cloning 과 관련된 term. 주어진 데이터셋에서 state, tau, action을 가져와서 그대로 학습하도록 하는 term
- b와 pi theta가 너무 멀어지지 않도록 KL divergence를 활용함
- 이때 alpha의 값이 클수록 Behavior cloning 만 학습되고, alpha가 작을 수록 데이터 셋 외 행동들도 선택할 수 있도록 학습됨 (강화학습)
- 보라색 : target network와 학습된 Q 분포 간의 차이가 너무 크지 않도록 KL-divergence를 활용
- 빨간 색 term : 강화학습에 대한 term. 주어진 데이터셋을 기반으로 향상된 정책인 pi imp가 있을 때, pi imp와 가까우면서도 더 좋은 행동을 찾도록 학습하는 term
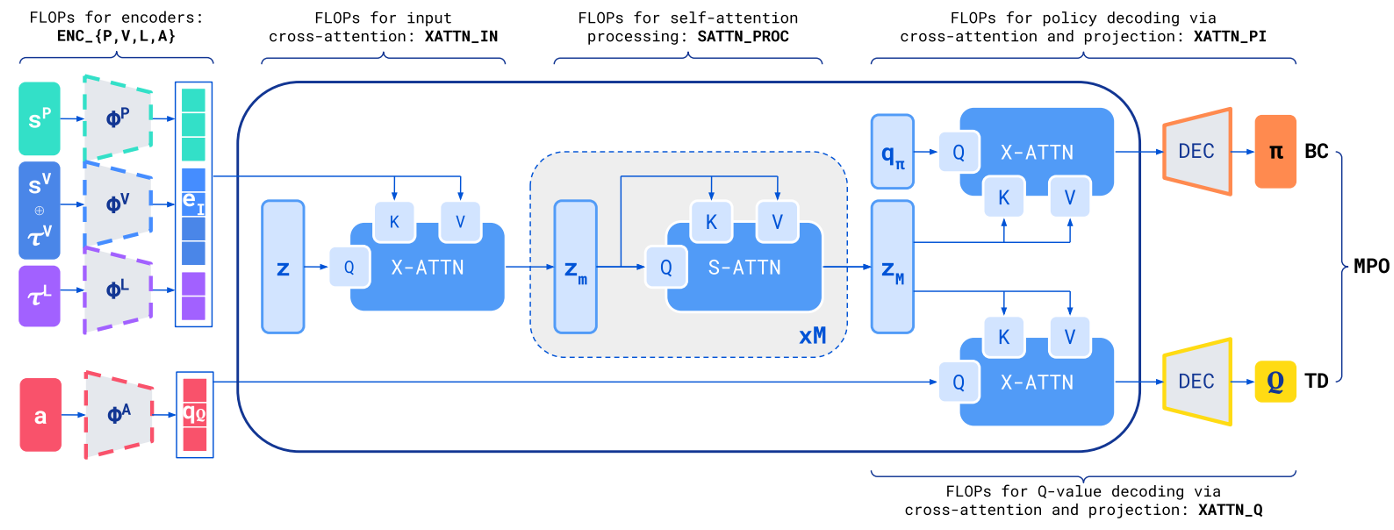
Model architecture
Experiments
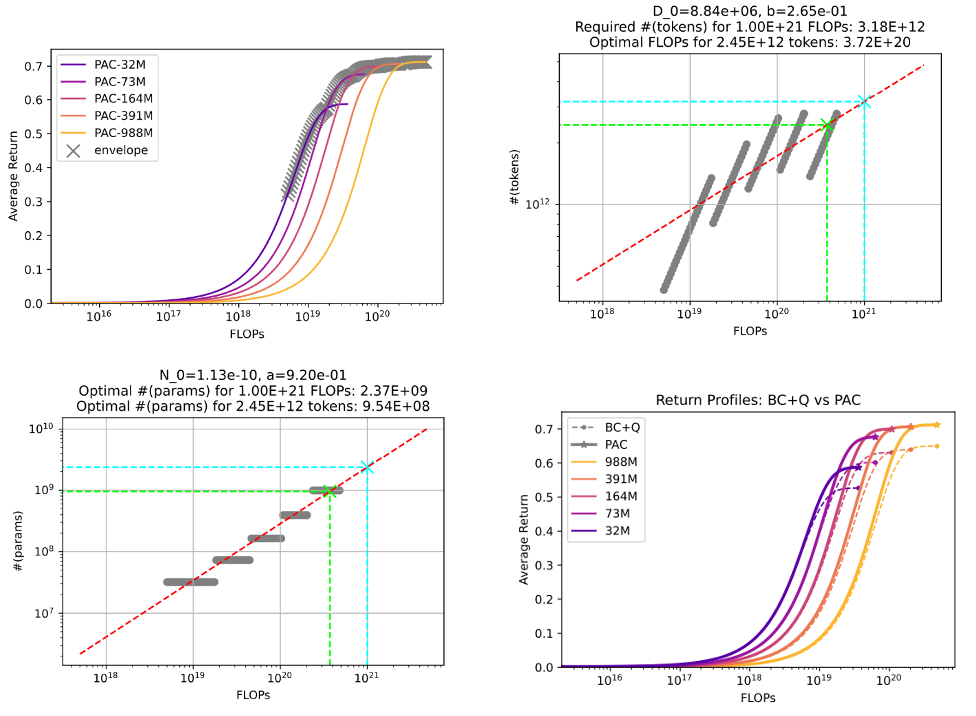
Scale 에 비례한 성능 증가
- FLOPs는 딥 러닝 모델의 연산 복잡도를 평가하는 중요한 지표
- 모델 복잡도와 Average return이 비례하게 증가하는 것을 볼 수 있음
Fine tuning 성능 & alph 와 beta 계수 tuning 성능
- BC < PAC < Fine tuning 순으로 성능이 좋아지는 것 볼 수 있음


RL하는 사람