RL
1.[논문리뷰 | RL] World models

The image of the world around us, which we carry in our head, is just a model. Nobody in his head imagines all the world, government or country. He ha
2.[논문리뷰 | RL] Stabilizing Contrastive RL: Techniques for Offline Goal Reaching
line : https://chongyi-zheng.github.io/stable_contrastive_rl/self-supervised learning에 주로 의존하는 robot systems은 control strategies를 학습하는 데 필요한 huma
3.[논문리뷰 | RL] Efficient Online Reinforcement Learning with Offline Data

복잡한 도메인에서 많은 성과를 내고 있음(ex. google의 chip design)이러한 성과들은 보통 simulator와의 많은 Interation을 통해 이뤄짐Chip design의 경우에도 환경을 simulation 할 수 있기 때문에 굉장히 많은 양의 데이터를
4.[논문리뷰 | RL] Alpha Zero
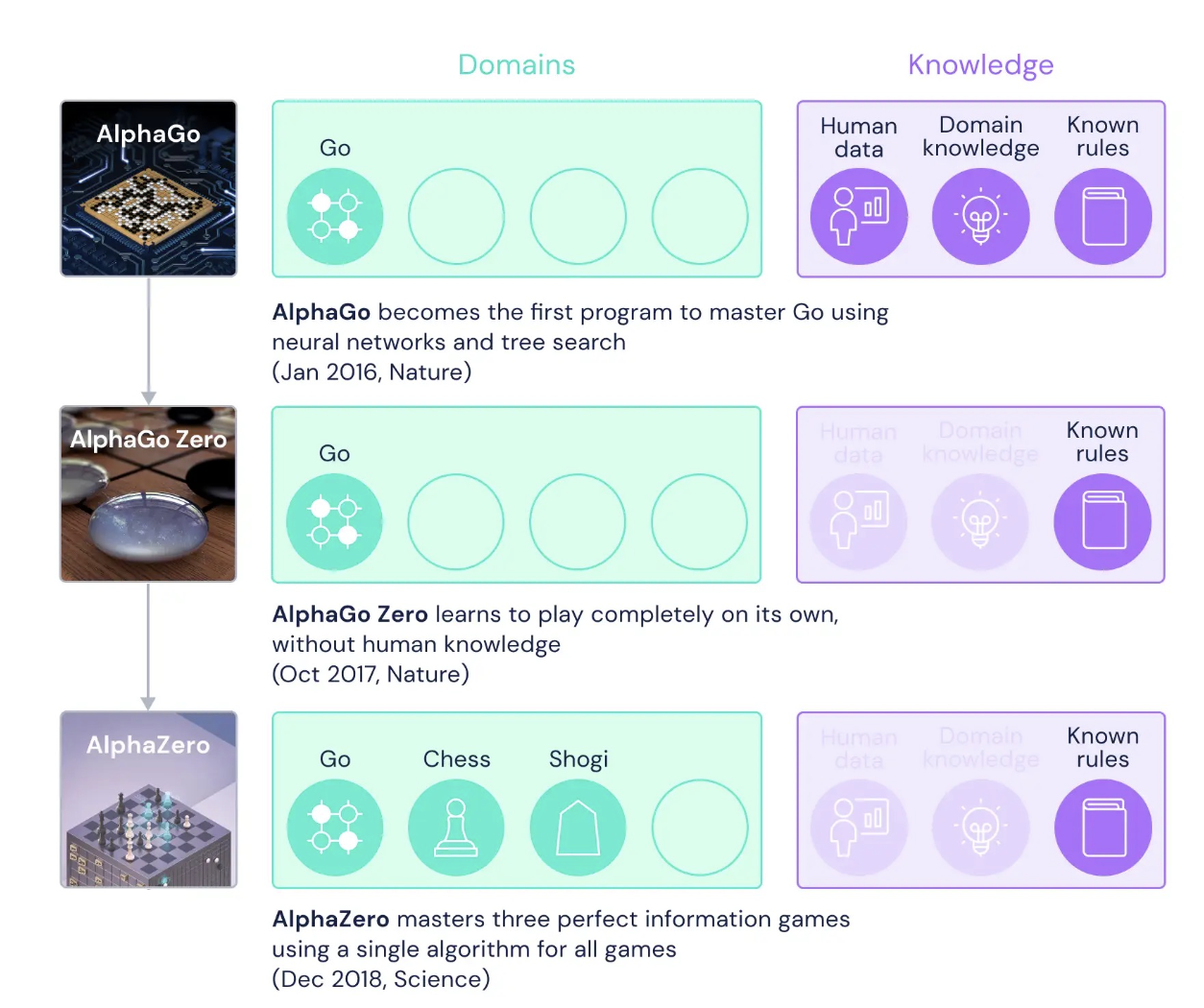
paper : 본 논문에서는 2016년 AlphaGo, 2017년 AlphaGo Zero를 통해 바둑(Go)에 대한 성공을 경험한 후, AlphaGo Zero의 more generic version 인 AlphaZero를 소개하고 있음.(https://www
5.[논문리뷰 | RL]A Perspective of Q-value Estimation on Offline-to-Online Reinforcement Learning (AAAI 2024)
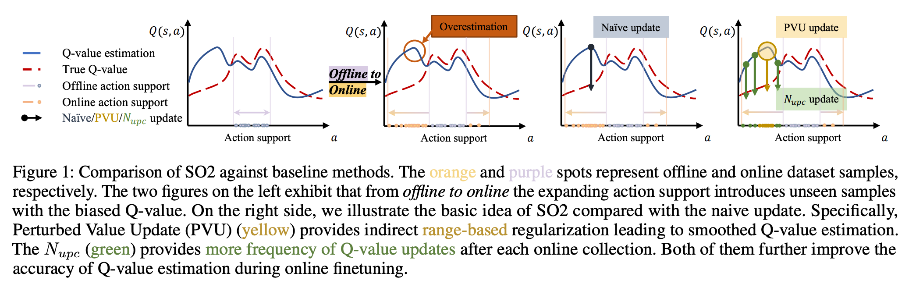
최근 들어서 Offline RL이 많은 주목을 받고 있음. 이는 다양한 로그 데이터나, 전문가의 지식(ex. 사람이 만든 데이터)을 활용해 policy를 학습하는 것에 초점을 맞추고 있음일반적으로 CV나 NLP 쪽에서 사전학습하고, fine tuning 하는 등의 방식
6.[논문리뷰 | RL] Offline Actor-Critic Reinforcement Learning Scales to Large Models

Machine learning 분야에서 최근 몇년간 model과 dataset size 의 규모를 키우는 것이 큰 성능 향상을 가져옴예를 들어, chatgpt 나 gemini 등 엄청난 성과들을 볼 수 있음 Imitation learning 분야인 Behavior cl