| 항목 | 링크 |
|---|---|
| 논문 | https://arxiv.org/pdf/2312.07685 |
Intro.
개요
- 최근 들어서 Offline RL이 많은 주목을 받고 있음. 이는 다양한 로그 데이터나, 전문가의 지식(ex. 사람이 만든 데이터)을 활용해 policy를 학습하는 것에 초점을 맞추고 있음
- 일반적으로 CV나 NLP 쪽에서 사전학습하고, fine tuning 하는 등의 방식과 유사하게 강화학습에서도 Offline rl로 사전 학습을 진행하고 online fine tuning(Offline to Online; O2O)을 하는 접근법들이 많이 등장함
- 이는 few sample을 통해 성능을 올릴 수 있다는 장점이 있지만 offline과 online data의 state-action distribution shift로 인한 차이 때문에 직접적인 fine tuning 은 효율적이지 않음
- Q) 만약 online과 동일한 환경에서 얻은 offline 데이터를 사용한다면 distribution shift가 일어나지 않으니 사용해도 괜찮지 않을까?
Q value estimation
- state-action distribution shift가 발생할 경우, 잘못된 policy를 학습하게 됨. 즉 잘못된 Q-value를 학습하는 문제가 발생함
- Q-value는 state-action에 대한 expected reward를 의미하기 때문에, 잘못된 Q-value의 예측은 특정 행동에 대해 과대 또는 과소 평가할 가능성을 가져옴
- 즉 학습이 불안정해지고 이상한 행동들을 많이 하면서 좋지 않은 방향으로 학습될 가능성이 있음
- 기존의 Offline RL 방법들은 이런 Q-value의 estimation 문제를 해결하기 위해, CQL(Conservative Q-Learning), Action constraints, Q-Ensemble 등의 방법을 사용하고 있지만 여전히 편향된 Q-value를 얻게 된다고 함
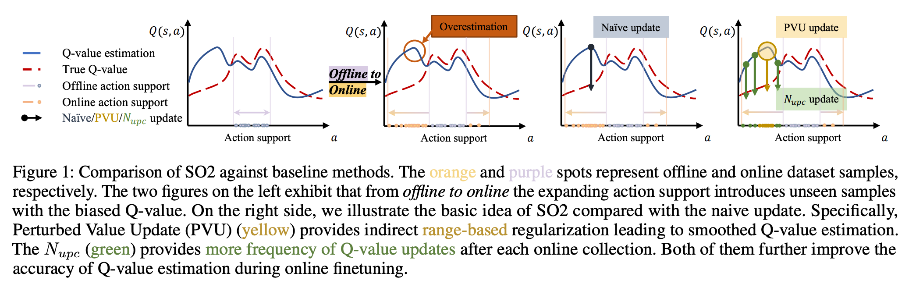
제안된 두 가지 방법 (SO2; Simple method for O2O RL)
- perturbed value update : Q value에 노이즈를 주어 특정 action(데이터에 존재하지만 일반적이지 않은 상황)에 overfitting 되는 것을 막고 다양한 action을 탐험하도록 유도. 이를 통해 Q-value estimation의 편향을 줄일 수 있음
- increased frequency of Q-value updates : Q value를 더 자주 업데이트하여 새로운 경험에 더 빠르게 반응할 수 있도록 함
Background
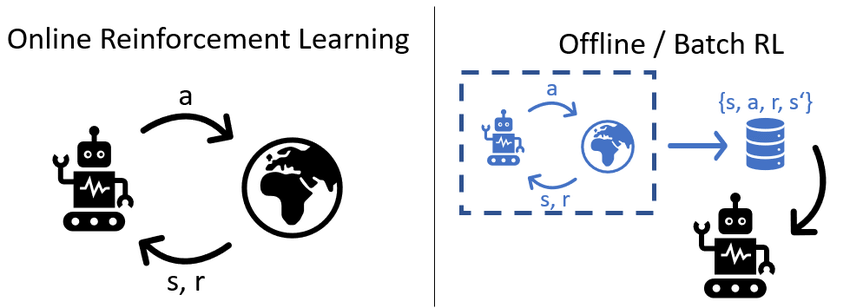
Online RL & Offline RL
(출처)
- Online RL은 환경과 상호작용 하면서 강화학습을 진행하는 방법
- Offline RL은 보유한 데이터셋을 기반으로 강화학습을 진행하는 방법론으로, 환경과 상호작용 하지 않고 학습하는 특징을 가짐
- Offline RL은 static datasets을 이용하여 학습하기 때문에, 경험하지 못 한 state-action에 대한 Q-value over-estimation 문제를 가지고 있음. 이에 대한 기존 연구들의 해결책은 아래 3 가지로 나뉘어짐
- Policy constraint methods [1][2][3] : logged dataset과 behavior policy와의 alignment를 강제하여, behavior cloning 및 KL-divergence를 통해 policy distribution shift를 최소화함
- Pessimistic value methods [4] : RL object에 conservative penalty를 추가하여 Q-value를 정규화하고 OOD state-action pairs에 대한 over-estimation을 완화함
- Uncertainty-based methods [5][6][7] : Q-value의 불확실성 추정을 사용해 distribution shift를 측정하고 policy update를 위한 robust signal을 제공함
Online RL with offline datasets (Offline to Online RL; O2O RL)
-
O2O RL은 (1) Offline 으로 학습된 모델을 이용해 (2) Online Fine tuning을 통해 성능을 올릴 수 있는 방법론
(출처)
-
기존의 연구들은 Offline dataset이 '최적'이라는 가정하에 Online RL을 개선하기 위해 offline dataset을 활용하는 방법들을 진행했었음. 그러나 실제 offline dataset은 sub-optimal인 경우가 훨씬 많고 이때문에 estimation bias가 발생할 수 있음. 이런 문제들을 완화시킬 수 있는 대안의 접근법들이 있는데, 이런 방법들은 Online fine tuning 과정에서 Offline dataset과 Online dataset의 samples 간의 distribution gaps에 중점을 두고 있음
- AWAC [1] : logged dataset과 behavior policy와의 alignment를 강제하함. 또한 Q-ensemble과 balanced replay를 사용하여 neural network가 예측한 online-ness predictions을 기준으로 offline dataset 중 policy와 가까운 samples를 선택하고 이를 통해 더 효율적으로 학습되도록 유도함
- AdaptiveBC [8] : randomized ensemble of Q-function을 제안하며, agent의 성능과 학습 안정성에 따라서, RL의 objective와 behavior cloning의 균형을 동적으로 맞춰가며 학습
- IQL [9] : 각 state에 대한 Q-value의 upper bound를 근사하고, Q-value 추정으로부터 policy를 추출해 fine tuning을 진행
- ODT [10] : equence modeling 및 entropy regularizers를 기반으로 한 O2O RL 알고리즘을 제안하여 offline pertaining과 online fine tuning 과정을 통합함
- PEX [11] : policy set에 offline policy와 추가 학습을 위한 another policy를 포함하는 policy expansion 기반의 RL 알고리즘
- QDagger [12] : Reincarnating RL paradigm 내에서 knowledge transfer efficiency를 최적화하는데 중점을 둔 방법론
- 일부 이전 연구들은 부정확한 Q-value estimation에 대한 문제를 인정하지만 이에 따른 fine tuning 에 미치는 부정적인 영향을 명시적으로 분석하지 않았음
- 본 연구에서는 문제를 밝혀내는 것에 중점을 둠
Q-Value Estimation Issues in O2O RL
본 section에서는 O2O RL에서 Q-value estimation 문제를 중점으로 다루고 있음. 먼저, Offline RL의 성능을 평가하고 그 후 성능 하락의 근본적인 원인이 Q-value estimation에 있음을 설명함
Performance
- 온라인 강화학습에는 SAC(Soft Actor Critic)과 EDAC의 online 버전을 이용함. 훈련 시 어떠한 offline dataset도 사용하지 않음
- Offline RL 방법에는 policy constraints (TD3- BC), conservative Q-value learning (CQL)과 Q-ensemble (EDAC)을 이용함
- 추가적으로 Offline RL 단계 이후 Online fine tuning 단계에서 pessimistic constraints를 제거한 loose variant 도 함께 평가하고자 함
- 그림 (a)를 보면 Offline 알고리즘은 모두 Offline 단계에서는 좋은 성능을 보이지만, Online 단계에서는 성능 향상이 느리거나 심지어 떨어지는 경우도 볼 수 있음
Normalized difference of the Q-value
- normalized difference를 이용하여 추정된 Q-value와 실제 Q-value의 차이를 측정함
- 그림 (b)를 보면 TD3-BC, CQL의 경우 offline에서 보지 못 한 state-action에 대해 Q value를 over estimation 하는 걸 볼 수 있고, EDAC의 경우 Q-value 추정 편향 문제에 직면하여 Q값이 과소평가되는 것을 확인함
Kendall’s τ coefficient over Q-value
- Kendall’s τ coefficient는 두 변수 집합간의 rank correlation을 측정함
- 그림 (c)를 보면 Offline RL 알고리즘들이 SAC에 비해 K값이 엄청 낮은 것을 볼 수 있음. 즉 추정된 Q-value가 다양한 state-action에 대한 상대적인 퀄리티를 평가하기에 정확하지 않음을 보인다고 함
Summary
Offline RL 알고리즘은 그 자체로 높은 성능을 얻을 수 있고 online fine tuning을 위한 좋은 시작점을 제공하지만, Q-value estimation의 문제로 인하여 성능이 천천히 올라가거나 오히려 저하되는 등의 문제가 존재함. 따라서 정확한 Q-value를 추정하는 것이 O2O RL의 bottleneck 이라고 볼 수 있음
A Simple but Effective Approach to O2O (Smoothed Offline-to-Online; SO2)
RL Algorithmic Details
본 논문은 Online 단계에서 성능을 올리기 위해 Q-value estimation의 정확성을 올리는 접근법을 제시함. 실험에서는 SAC(Soft Actor-Critic)과 Q-ensemble에 기반을 둔 두 가지 수정 사항을 포함하고 있음
- (1) Perturbed Value Update (PVU) : value에 노이즈를 추가
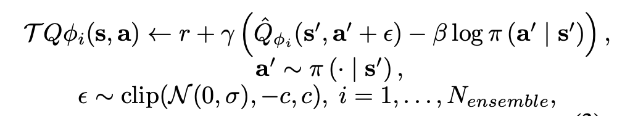
- ϵ 은 action 노이즈로, Q(s, a) 를 Q(s, a + ϵ )으로 수정하여 노이즈를 추가함. 또한 노이즈는 (-c, c) 사이 값을 가지도록 범위를 제한함
- 이로 인해 Q-value 추정에 사용되는 action의 분포를 확대하면서, 더 smooth한 Q-value 추정이 가능해짐. 그리고 이러한 smooth 추정을 통해 Q-value가 편향되어 있는 상태에서 over-estimation을 방지할 수 있음
- (2) Increased Frequency of Q-value Update : Q-value 업데이트 빈도 증가
- Offline RL의 부정확한 Q-value 추정을 완화시키기 위해, online 단계에서 Q-value를 업데이트하는 빈도를 증가시킴
- 구체적으로는 N_upc를 업데이트 빈도로 나타내어 사용한다고 하며, 이는 구현 세부나 실험쪽 pseudo code에서 확인 가능하지 않을까 싶음
Implementation Details
- DRL framework인 DI-engine을 기반으로 SAC + Q-ensemble 사용
- Pseudo code : (1) Online으로 데이터를 수집하고 (2) Off+Online dataset buffer에서 데이터를 샘플링 (3) N번 network 업데이트

Experiments
💡실험을 통해 설명하고 싶은 것들
- Performance : Online RL이나 기존 O2O RL보다 높은 성능을 얻는지?
- N_upc : Q-value 업데이트 빈도를 증가시키는 것이 효과적으로 성능 향상에 영향을 주는지?
- PVU : Perturbed value update가 O2O RL 학습을 안정시키는지?
- Q-value estimation : 제안된 방법이 Q-value estimation 문제와 estimation bias, inaccurate rank를 효과적으로 해결할 수 있는지?
- Extension : robot manipulation tasks와 같이 challenging 한 문제에도 사용될 수 있는지?
- Compatibility : 다른 O2O RL 방법론들과 호환이 되는지?
Evaluation on MuJoCo tasks
✏️ Setup
- MuJoCo tasks 중 HalfCheetah, Walker2d와 Hopper를 포함한 세 가지 환경으로 구성된 D4RL-v2 데이터셋에서 학습
- 각 환경에는 서로 다른 수준의 policy로 수집된 Random, Medium, Medium-Replay, Medium-Expert 데이터셋이 포함됨
- 성능은 D4RL의 standard normalized return metric을 통해 측정하고, 4개의 seed에 대한 평균을 냈다고 함
✏️ Comparative evaluation : 아래와 같은 방법들을 비교 기준으로 선정
-
Background
방법론 실험 기준 - OFF2ON : Offline dataset에서 near on-policy sample을 사용해 balanced replay를 제안하는 pessimitic Q-ensemble RL 방법. OFF2ON의 공식 구현체를 사용했음
- IQL-ft : Q-value distribution의 upper bound를 근사하고 Q-value estimation에서 policy를 추출하여 강력한 fine tuning 성능을 보이는 Offline 방법론. rlkit에서 제공하는 IQL 구현을 사용했음
- AWAC : High advantage estimates를 가진 actions을 모방하도록 policy를 학습시키는 O2O RL 방법. AWAC의 공식 구현체를 사용했음
- ODT : Offline 및 Online fine tuning을 통합된 framework에서 진행하는 sequence modeling 기반 O2O RL 알고리즘
- PEX : policy set에 offline policy와 추가 학습을 위한 another policy를 포함하는 policy expansion 기반의 RL 알고리즘
- 100K environment steps 동안 policy를 학습하고, 1000 steps 마다 평가함
- σ = 0.3, c = 0.6, and N_upc = 10으로 사용하며, 디테일한 설정은 Appendix에 기술함
- 옆에서 소개한 O2O 알고리즘들을 이용해 Online fine tuning 단계의 성능을 공정하게 비교하기 위해 모든 알고리즘을 재실행하여 성능을 확인함
-
본 논문에서 제안하는 SO2 알고리즘은 다음 세 가지 이점을 가짐
- sample efficiency와 asymptotic performance(수렴하는 최종 성능) 모두에서 다른 알고리즘들의 성능을 큰 차이로 능가함
- 대부분의 환경이나 datasets에 대해 작은 분산을 가지는 경향이 있음
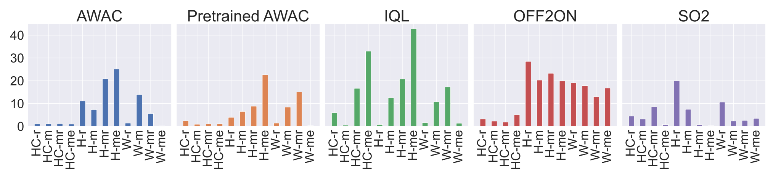
- Random policy에 의해 수집된 데이터에서도 few online interactions 만으로 높은 성능을 달성함
-
특히, standard off-policy 알고리즘인 SAC와 비교했을 때도 적은 time steps 만으로도 SAC 성능을 훌쩍 뛰어 넘는 결과를 확인함
- 1M HalfCheetah-Random 데이터셋으로 offline pretraining 진행 (심지어 random policy고 1M 데이터셋만을 가지고 학습한 거라 0.17M만에 SAC 만큼의 성능을 달성한 것은 대단하긴 함)
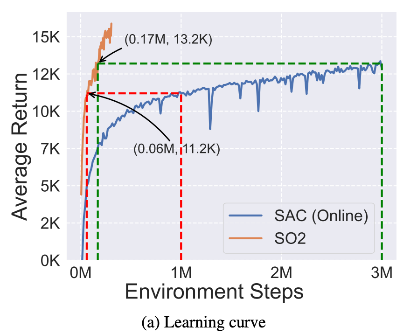
- 1M HalfCheetah-Random 데이터셋으로 offline pretraining 진행 (심지어 random policy고 1M 데이터셋만을 가지고 학습한 거라 0.17M만에 SAC 만큼의 성능을 달성한 것은 대단하긴 함)
-
여러 O2O RL 알고리즘에 대한 성능 비교
- SO2는 모든 dataset에 대해 우상향하는 성능을 확인할 수 있는데, 다른 방법론들은 미세한 우상향 또는 성능 하락(Hopper-Medium-Exper의 OFF2ON)이나 성능이 거의 변화 없음(Halfcheetah-Medium-Replay)을 확인할 수 있음
- 방법론에 따라서 초기 성능이 다른 것을 볼 수 있는데, 이는 각기 다른 baseline을 사용하고 이에 따른 hyper-parameters를 사용했기 때문임
- hyper-parameteres는 각각의 baseline results에 맞추어져 있기 때문에 본질적으로 민감하며, 모든 알고리즘에서 일관된 초기 성능을 달성하기 위해서는 많은 hyper-parameters tuning 이 필요함
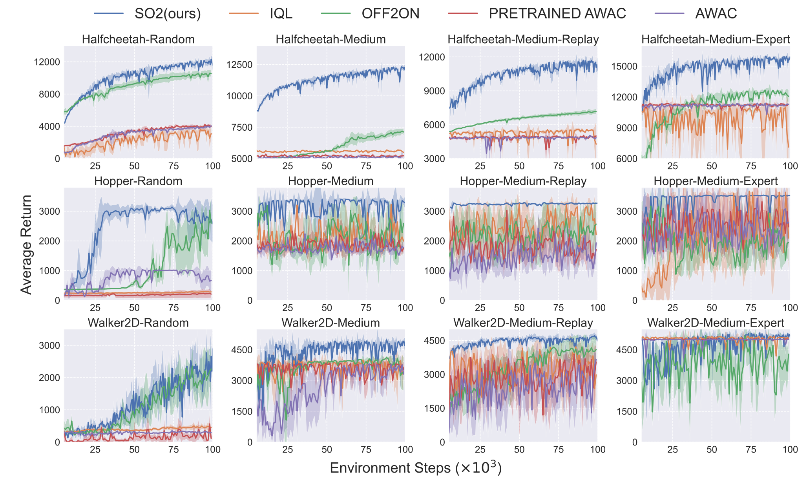
✏️ Analysis on Perturbed Value Update
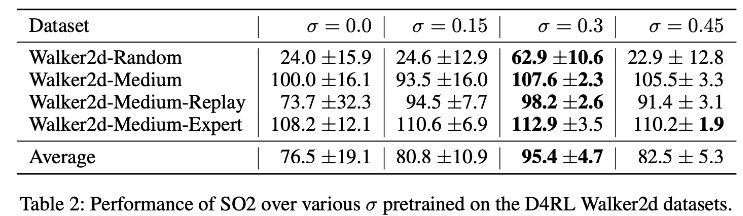
- target noise의 효과를 증명하기 위해 σ 값을 바꿔가며 ablation study 진행
- 위 표를 보면 σ = 0.0 일 때 모든 offline 데이터셋에 대해 분산이 큰 것을 확인할 수 있으며 0.3 정도에서 가장 낮은 분산을 가지는 것 확인함
- 높은 분산은, 학습된 정책이 특정 조건에서는 잘 작동하지만, 모든 조건에서 일관되게 잘 작동하게 하지 않는 것을 보여줌
✏️ Analysis on N_upc
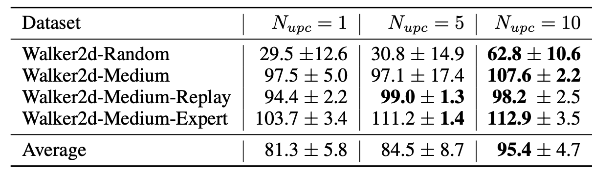
- Q-value update 빈도 증가의 효과를 확인하기 위해, N 값을 바꿔가며 ablation study 진행
- 위 표를 표면 N이 증가함에 따라 평균 성능이 모두 증가하는 것을 확인할 수 있음
- 특히 Random 정책으로 수집된 데이터셋에서 그 효과가 더 뚜렷하게 나타남
- N을 증가시키면 Q-value의 estimation이 명확해지기 때문에 초기 추정이 최적이 아닌 경우 더 높은 효과를 볼 수 있음
✏️ Analysis on Q-value estimation
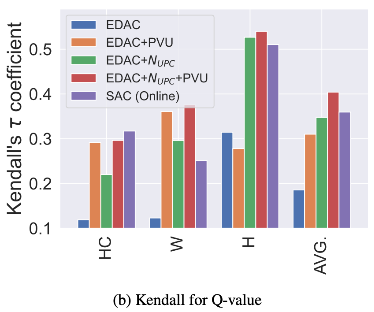
- 그림 (b)는 estimated Q-value rank의 정확도를 비교한 것임
- PVU와 N_upc를 적용한 실험의 Q-value 정확도가 online 을 능가한 것을 확인할 수 있음
Evaluation on Adroit tasks
✏️ Setup
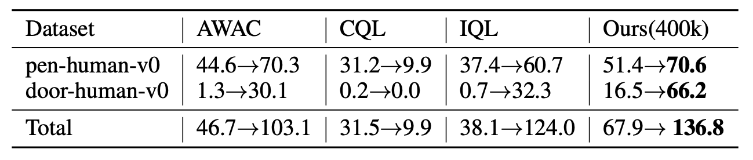
- 24-DoF robotic hand을 제어하여 펜을 잡거나 문을 여는 작업을 대상으로 평가함
- Offline 학습은 D4RL-v0 데이터셋을 사용하여 학습했고, Online fine tuning에서 AWAC, CQL, IQL의 경우 1M stpes & Ours는 400k steps만을 이용하여 학습함
- AWAC, CQL, IQL의 결과는 IQL 논문에서 인용함
✏️ Comparative evaluation
- 다른 알고리즘을 큰 차이로 능가하는 것을 보여줌
Conclusion
- 본 논문을 통해 O2O RL에 대한 깊은 탐구와, O2O RL의 bottleneck에 대한 연구를 진행함
- 대부분의 기존 연구들과 달리 Offline -> Online 단계에서의 Q-value estimation 문제, 특히 biased estimation과 inaccurate rank of the Q-value에 집중하여 해결점을 제시함
- 제안된 방법은 state-action distribution의 explicit estimation이나 offline & online replay buffer의 복잡한 balance 과정없이도 MuJoCo와 Adroit 환경에서 성능을 최대 83.1%까지 향상시킴
Reference
[1] Nair, A.; Gupta, A.; Dalal, M.; and Levine, S. 2020. Awac: Accelerating online reinforcement learning with offline datasets. arXiv preprint arXiv:2006.09359. (https://arxiv.org/pdf/2006.09359)
[2] Fujimoto, S.; and Gu, S. S. 2021. A minimalist approach to offline reinforcement learning. Advances in neural information processing systems, 34: 20132–20145. Fujimoto, S.; Meger, D.; and Precup, D. 201
[3] Wu, Y.; Tucker, G.; and Nachum, O. 2019. Behavior regularized offline reinforcement learning. arXiv preprint arXiv:1911.11361.
[4] Kumar, A.; Zhou, A.; Tucker, G.; and Levine, S. 2020. Conservative q-learning for offline reinforcement learning. Advances in neural information processing systems, 33: 1179– 1191.
[5] An, G.; Moon, S.; Kim, J.-H.; and Song, H. O. 2021. Uncertainty-based offline reinforcement learning with diversified q-ensemble. Advances in neural information processing systems, 34: 7436–7447.
[6] Kumar, A.; Fu, J.; Soh, M.; Tucker, G.; and Levine, S. 2019. Stabilizing off-policy q-learning via bootstrapping error reduction. Advances in Neural Information Processing Systems, 32
[7] Bai, C.; Wang, L.; Yang, Z.; Deng, Z.-H.; Garg, A.; Liu, P.; and Wang, Z. 2021. Pessimistic Bootstrapping for Uncertainty-Driven Offline Reinforcement Learning. In International Conference on Learning Representations.
[8] Zhao, Y.; Boney, R.; Ilin, A.; Kannala, J.; and Pajarinen, J. 2022. Adaptive behavior cloning regularization for stable offline-to-online reinforcement learning. In European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning.
[9] Kostrikov, I.; Nair, A.; and Levine, S. 2021. Offline Reinforcement Learning with Implicit Q-Learning. In International Conference on Learning Representations. (https://arxiv.org/pdf/2110.06169, 코드 : https://github.com/rail-berkeley/rlkit)
[10] Zheng, Q.; Zhang, A.; and Grover, A. 2022. Online decision transformer. In international conference on machine learning, 27042–27059. PMLR.
[11] Zhang, H.; Xu, W.; and Yu, H. 2022. Policy Expansion for Bridging Offline-to-Online Reinforcement Learning. In The Eleventh International Conference on Learning Representations.
[12] Agarwal, R.; Schwarzer, M.; Castro, P. S.; Courville, A. C.; and Bellemare, M. 2022. Reincarnating reinforcement learning: Reusing prior computation to accelerate progress. Advances in Neural Information Processing Systems, 35: 28955– 28971.
[13] Lee, S.; Seo, Y.; Lee, K.; Abbeel, P.; and Shin, J. 2022. Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble. In Conference on Robot Learning, 1702–1712. PMLR (https://arxiv.org/pdf/2107.005910)
