
DB를 사용하다보면 성능이 느려지는 경우를 만나게 된다. 보통은 동시 사용자 수의 증가, 데이터 양의 증가, 비효율적인 SQL문 작성 이 세 가지 요인 때문에 성능 저하를 경험한다.
DB 성능 향상 방법
DB 성능 향상하기 위해 다양한 방법들이 존재한다.
- SQL 튜닝
- 캐시 사용
- 레플리케이션 (Master/Slave)
- 샤딩
- 스케일업
이중에서 가장 먼저 SQL 튜닝을 고려하게 된다. 그 이유는 다른 방법들은 금전적, 시간적으로 추가적인 비용이 발생한다. 따라서 시스템 변경 없이 성능을 개선할 수 있는 SQL 튜닝을 보통 먼저 진행한다. 또한, SQL 튜닝을 통해 근본적인 문제를 해결할 가능성도 높다. 간단한 개선으로 큰 성능 향상을 얻을 수 있는 것이다.
MySQL 아키텍처
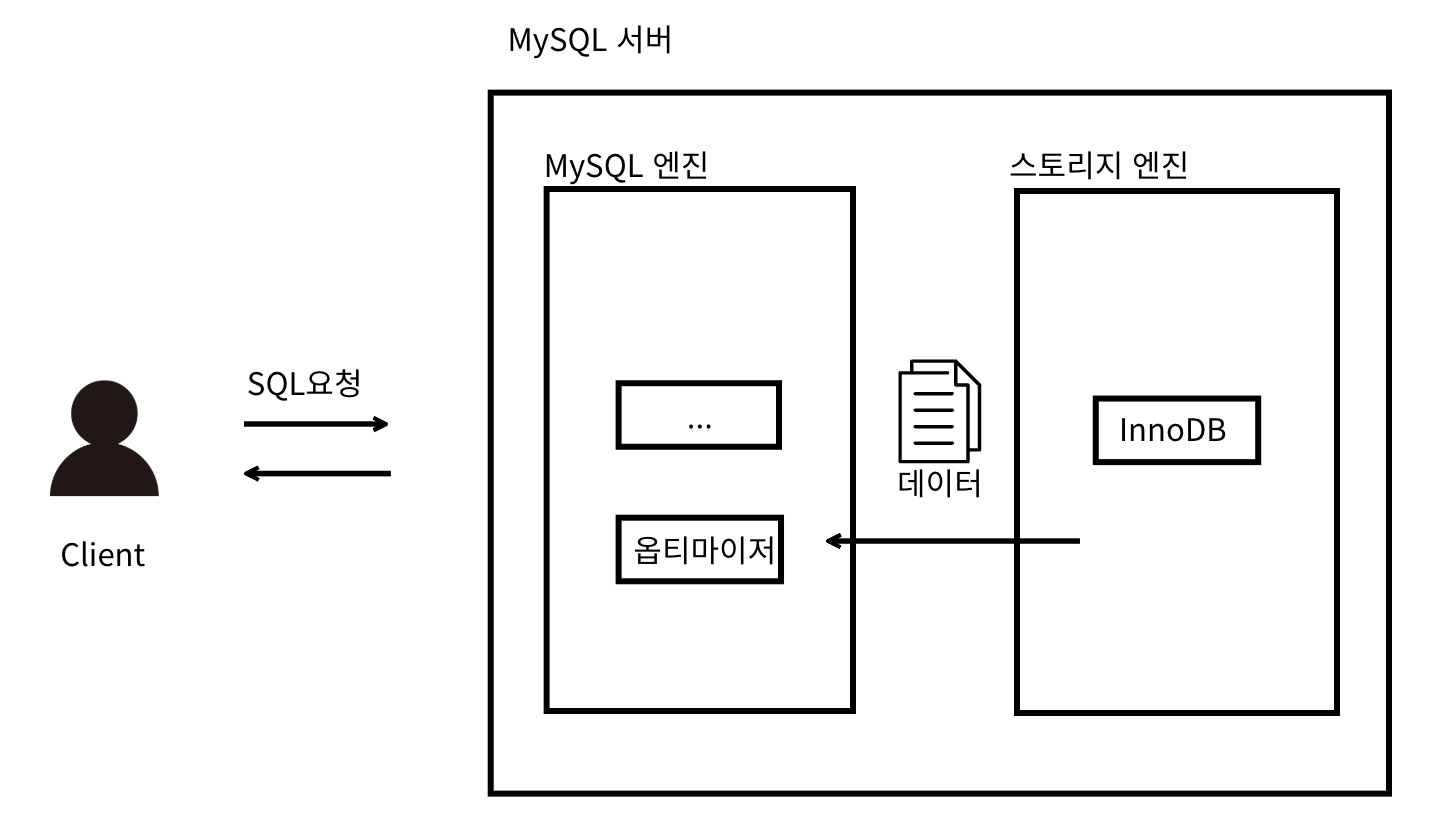
-
클라이언트(서버)가 DB에 SQL 요청을 보낸다.
-
MySQL 엔진에서 옵티마이저가 SQL문을 분석한 뒤 빠르고 효율적으로 데이터를 가져올 수 있는 계획을 세운다. 어떤 순서로 테이블에 접근할 지, 인덱스를 사용할 지, 어떤 인덱스를 사용할 지 등을 결정한다.
(옵티마이저가 세운 계획은 완벽하지 않다. 따라서 SQL 튜닝이 필요) -
옵티마이저가 세운 계획을 바탕으로 스토리지 엔진에서 데이터를 가져온다.
-
MySQL 엔진에서 정렬, 필터링 등의 마지막 처리를 한 뒤에 클라이언트에게 SQL 결과를 응답한다.
DB 성능에 문제가 생기는 대부분의 원인은 스토리지 엔진으로부터 데이터를 가져올 때 발생한다.
SQL 튜닝의 핵심은 스토리지 엔진에서 데이터를 찾기 쉽게 바꾸거나 스토리지 엔진으로부터 가져오는 데이터의 양 줄이는 것이다.
실행 계획(Explain)
옵티마이저가 SQL문을 어떤 방식으로 어떻게 처리할 지 계획을 의미한다. 이 실행 계획을 보고 비효율적으로 처리하는 방식이 있는 지 확인하고, 비효율적인 부분이 있다면 더 효율적인 방법으로 SQL문을 개선할 수 있다.
실행 계획을 확인하는 방법
# 실행 계획 조회하기
EXPALIN [SQL문]
# 실행 계획 대한 자세한 정보 조회하기
EXPLAIN ANALYZE [SQL문]EXPLAIN 컬럼 종류

select_type
SELECT 문의 유형을 나타낸다.
- simple : 단순한
SELECT문 - primary : 서브쿼리나
UNION을 포함하는 쿼리에서 가장 바깥쪽SELECT문 - subquery :
FROM절이 아닌 곳에서 사용된 서브쿼리. - derived:
FROM절에 사용된 서브쿼리 - union :
UNION으로 결합된SELECT문 중 두 번째 이후의SELECT문 - union result :
UNION결과를 담는 임시 테이블
partitions
쿼리가 접근하는 파티션을 표시
type
테이블에 있는 데이터를 어떤 방식으로 조회했는지를 나타낸다. 성능 개선을 위해 살펴볼 주요 컬럼이다.
- ALL : 풀 테이블 스캔(Full Table Scan), 테이블 전체를 스캔
- index : 풀 인덱스 스캔(Full Index Scan), ALL 보다 빠름.
- const : 1건의 데이터를 바로 찾을 수 있는 경우
- range : 인덱스 레인지 스캔 (Index Range Scan)
- ref : 비고유 인덱스를 활용하는 경우
- eq_Ref : 조인 시 PRIMARY KEY나 UNIQUE 인덱스를 사용하여 다른 테이블의 행과 정확히 일치하는 하나의 행을 찾는 경우
이 외에도 ref_or_null, unique_subquery, index_subquery, fulltext 등 다양한 type이 존재하지만 자주 나오는 type은 위의 정도이다.
possible_keys
쿼리를 실행할 때 MySQL이 사용할 수 있는 인덱스 목록
key
데이터 조회할 때 실제로 사용된 인덱스
ref
어떤 값을 기준으로 Join 했는지
rows
쿼리를 실행하기 위해 테이블에 접근한 (access) 개수 - 쿼리 튜닝에 핵심
filtered
rows에서 읽은 행 중에서 WHERE 필터 조건으로 얼마나 필터링 처리를 했는지, 남은 행의 비율(%)을 예측한 값 [rows * (filtered / 100)]
rows, filtered 값은 정확한 값이 아니라, 추정값이다.
EXPLAIN ANALYZE [SQL문]
EXPLAIN ANALYZE
SELECT * FROM USERS;
결과
-> Table scan on USERS (cost=0.35 rows=1) (actual time=0.071..0.0732 rows=1 loops=1)User 테이블에서 모든 사용자를 조회하는 SQL문에 EXPLAIN ANALYZE를 사용 시 해당 SQL의 실행 계획 정보가 나온다.
여기서 USERS테이블을 모두 스캔하였고 그 중 1개의 행을 찾았다. 여기서 주요하게 볼 값은 두 번째 rows와 actual time이다.
rows는 실제 결과 행의 수이고 actual time은 첫 번째 행을 찾는데 0.071ms 가 걸리고, 작업을 완전히 끝내는데 총 0.0732초가 걸렸다는 뜻이다.
이를 핵심 쿼리에 적용하여 실제 데이터를 가져오는데에 걸리는 시간을 측정하고 개선을 진행할 수 있다.
인덱스(Index)
인덱스(Index)는 데이터베이스 테이블에 대한 검색 성능의 속도를 높여주는 자료 구조를 뜻한다.
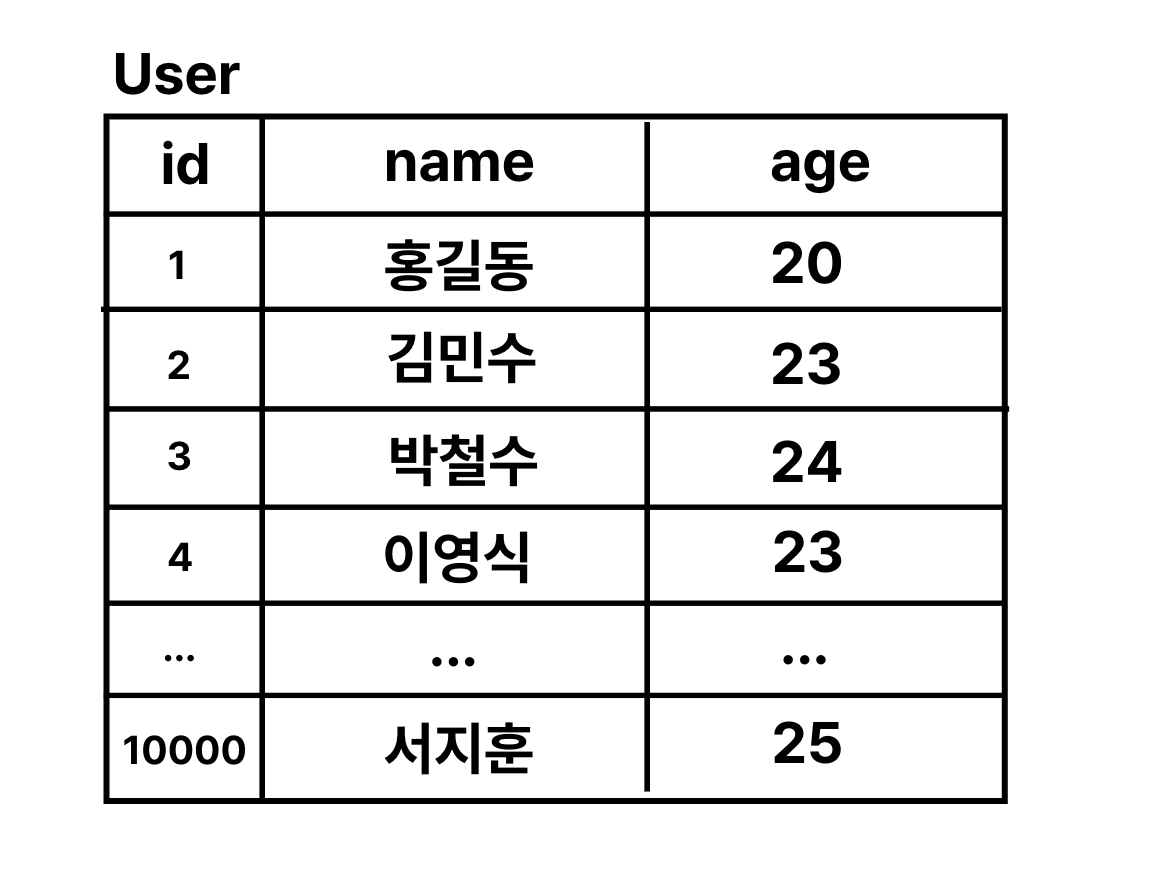
예를 들어, User 테이블에 id(PK), name, age 컬럼들이 저장된다고 가정해보자.
데이터를 삽입하면 기본적으로 id(PK) 순으로 데이터가 쌓이고 저장이 될 것이다.
이때, 나이가 20살인 사용자를 전부 찾으려고 하면, 나이가 뒤죽박죽으로 섞여있기 때문에 모든 행을 전부 검사해서 나이가 20살인 사용자를 찾아내야 한다.
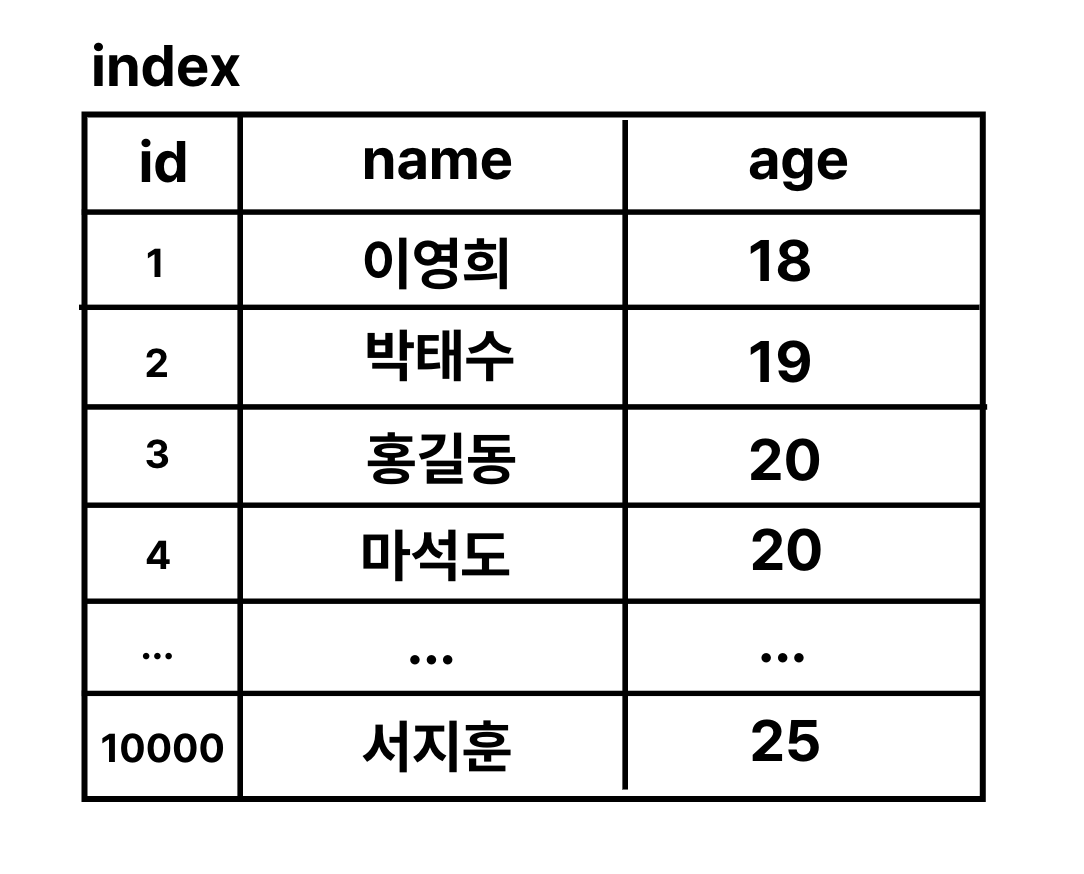
age로 인덱스를 생성하면 나이별로 정렬이 되어서 20살로 시작되는 지점과 21살이 시작되는 지점만 찾은 뒤 그 사이에 값들을 모두 조회하면 된다. 훨씬 효율적으로 데이터를 조회할 수 있다.
인덱스 생성 방법
CRREATE INDEX idx_age ON users(age);인덱스를 많이 생성하면 안되는 이유
인덱스를 추가한다는 것은 인덱스용 테이블도 생성이 된다. 인덱스를 활용하면 조회 성능은 향상되지만 반대로 삽입, 수정, 삭제에 대해 모든 테이블을 쓰기 작업을 해야 하므로 성능이 저하된다.
SQL 쿼리 튜닝
DB에서 데이터를 가져올 때 어떻게 쿼리를 작성하는지에 따라 성능이 크게 달라지게 된다.
1. SELECT * 대신 필요한 컬럼만 명시
불필요한 데이터 조회는 네트워크 트래픽과 I/O를 증가시킨다. 필요한 Row와 Column만 가져오는 것이 좋다.
2. 서브쿼리(subquery)보다 조인(JOIN) 사용 고려
보통 서브쿼리는 반복적으로 실행되어 비효율적이다. 가능하면 JOIN을 사용하자.
3. 적절한 JOIN 사용
조인의 순서와 유형에 따라 실행 계획이 달라질 수 있다. 테이블의 크기, 필터링의 조건 등을 고려하여 적절한 조인을 선택하는 것이 좋다. 크기가 작은 테이블을 먼저 조인하거나, 불필요한 조인 대신 EXISTS, IN 등 적절한 연산자를 선택한다.
4. OR 대신 UNION 사용
OR 연산자는 한 번의 스캔으로 모든 조건을 확인해야하므로 인덱스를 제대로 활용하지 못하는 경우가 있다. 이때 각각의 조건으로 나누어 UNION 연산자를 사용하여 각 조건마다 별도의 쿼리를 수행하고 인덱스도 활용하여 빠르다.
5. LIKE 검색에서 (%) 사용 지양
LIKE 검색에서 '%문자열' 은 모든 테이블을 다 풀 스캔하게 되므로 필요 시 되도록 '문자열%'로 사용하자.
6. 부정형 검색을 피하자
NOT, !=, <> 같은 부정형 비교는 인덱스를 사용하기 어렵게 만들기 때문에 긍정형 조건으로 바꾸어 표현하는 것이 좋다.
7. 불필요한 DISTINCT 제거
DISTINCT는 중복을 제거하기 위해 내부적으로 정렬하거나 해시를 사용한다. 이 연산은 CPU 자원을 많이 사용하게 되어 쿼리 속도가 느려질 수 있다.
비전공자도 이해할 수 있는 MySQL 성능 최적화 입문/실전 (SQL 튜닝편)
SQL 쿼리 튜닝하는 여러가지 방법
쿼리 튜닝(Feat. MS-SQL) - 튜닝의 기본/쿼리 최적화 방법
