Mixed Precision training
모델 훈련은 Float32 !!!
Adding autocast
Instances of torch.autocast serve as context managers that allow regions of your script to run in mixed precision.
In these regions, CUDA ops run in a dtype chosen by autocast to improve performance while maintaining accuracy. See the Autocast Op Reference for details on what precision autocast chooses for each op, and under what circumstances.
for epoch in range(0): # 0 epochs, this section is for illustration only
for input, target in zip(data, targets):
# Runs the forward pass under autocast.
with torch.autocast(device_type='cuda', dtype=torch.float16):
output = net(input)
# output is float16 because linear layers autocast to float16.
assert output.dtype is torch.float16
loss = loss_fn(output, target)
# loss is float32 because mse_loss layers autocast to float32.
assert loss.dtype is torch.float32
# Exits autocast before backward().
# Backward passes under autocast are not recommended.
# Backward ops run in the same dtype autocast chose for corresponding forward ops.
loss.backward()
opt.step()
opt.zero_grad() # set_to_none=True here can modestly improve performanceMixed precision training이란
Mixed precision training이란, 모델 훈련의 계산 효율성을 최적화를 목표로하는 기술로, 특정 변수를 lower-precision numerical format으로 사용함으로써 이를 수행한다.
전통적으로, 대부분의 모델은 32-bit floating point precision (fp32 or float 32)을 변수로 사용한다. 그러나 모든 변수가 정확한 결과를 위해 이렇게 높은 precision level을 필요로 하지 않을 것이다. 여기서 언급되는 precision은 어떤 정밀한 정도를 의미한다고 보면 될 것 같다. (예를들어 우리가 32자리 수로 나타낼 수 있는 것과 16자리로 나타내는 것이 전달할 수 있는 정보가 다르기 때문)
따라서, 16-bit floating point (fp16 or float16)과 같은, 좀 더 작은 numerical format을 특정 변수의 precision을 줄이는 것으로써, 계산의 속도를 높일 수 있을 것이다. 왜냐면 이러한 접근법은 half-precision에서 계산이 수행될 것이고, 몇몇은 여전히 full precision을 유지하기 때문이다. 이러한 방법을 mixed precision training이라고 한다.
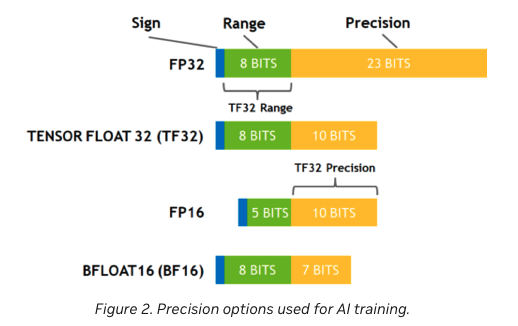
대부분의 공통적인 mixed precision training은 fp16 (float16)을 data type으로 사용함으로써 훈련을 진행한다. 그러나 몇몇 GPU 아키텍쳐 (such as the Ampere architectur)는 bf16 그리고 tf32 (CUDA internal data type)을 사용한다.
CUDA AUTOMATIC MIXED PRECISION EXAMPLES
Pytorch Documentation - Mixed Precision
일반적으로, "automatic mixed precision training" 은 torch.autocast 그리고 torch.cuda.amp.GradScaler를 함께 사용하여 training하는 것을 의미한다.
torch.autocast의 instance들은 선택된 지역에 대해 autocasting할 수 있도록 해준다. 이 때 Autocasting이란, 자동적으로 GPU 연산이 accuracy를 유지한 채 성능을 향상시킬 수 있도록 precision을 선택해주는 것이다.
torch.cuda.amp.GradScaler는 gradient scaling의 단계가 편리하게 수행될 수있도록 도와준다. Gradient scaling은 gradient의 underflow를 최소화함으로써, float16 gradient로 모델이 convergence할 수 있도록 도와준다.
torch.autocast와 torch.cuda.amp.GradScaler는 modular이다.
Typical Mixed Precision Training
# Creates model and optimizer in default precision
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# Creates a GradScaler once at the beginning of training.
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
# Runs the forward pass with autocasting.
with autocast(device_type='cuda', dtype=torch.float16):
output = model(input)
loss = loss_fn(output, target)
# Scales loss. Calls backward() on scaled loss to create scaled gradients.
# Backward passes under autocast are not recommended.
# Backward ops run in the same dtype autocast chose for corresponding forward ops.
scaler.scale(loss).backward()
# scaler.step() first unscales the gradients of the optimizer's assigned params.
# If these gradients do not contain infs or NaNs, optimizer.step() is then called,
# otherwise, optimizer.step() is skipped.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()Working with Unscaled Gradients
모든 gradients들은 scaler.scale(loss).backward()로 scaled된다. 만약에 backward() 와 scaler.step(optimizer)사이에서 .grad attributes 파라미터를 조사하거나 수정하기를 원한다면, unscale을 먼저 해줘야 할 것이다. 예를들어, 일련의 gradient들에게 clipping 조작을 원한다면, 그것들의 global normtorch.nn.utils.clip_grad_norm_()) 혹은 maximum magnitude (torch.nn.utils.clip_grad_value()_()) 는 <= 일부 유저가 정한 threshold보다 작도록 하는 것. 즉, 일반적인 mixed precision training같은 경우, 내부 gradient가 scaled되어있기 때문에 이를 조작하기 위해서는 unscaled하여야 한다는 의미이다. 만약에 unscaling을 하지 않고 clip을 적용한다고 한다면, gradient들의 norm/maximum magnitude가 똑같이 scaled되어있기 때문에, threshold가 유효하지 않을 수 있다.
scaler.unscale_(optimizer) 는 optimzer의 할당된 파라미터들을 unscale해준다. 만약에 model혹은 다른 optimizer(say optimizer2)에 할당된 파라미터인 경우, scaler.unscale_(optimizer2)를 각각 지정해주어야 할 것이다.
Gradient clipping
clipping을 하기 전에, unscaled된 gradient를 사용하기 때문에 scaler.unscale_(optimizer)를 호출한다.
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
with autocast(device_type='cuda', dtype=torch.float16):
output = model(input)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
# Unscales the gradients of optimizer's assigned params in-place
scaler.unscale_(optimizer)
# Since the gradients of optimizer's assigned params are unscaled, clips as usual:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
# optimizer's gradients are already unscaled, so scaler.step does not unscale them,
# although it still skips optimizer.step() if the gradients contain infs or NaNs.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
scaler는 이미 optimizer에서 이번 iteration에 호출된 scaler_unscale_(optimizer)가 기록되어있다, 그래서 scaler.step(optimizer)는 optimizer.step()을 부르기 전의 unscale gradients를 알고 있다.
unscale_은 optimizer가step되기 전에 호출되어야 하고, 오직 모든 gradients들이 축적되고 나서 사용이 가능하다.unscale_을 두번 호출하는 것은RuntimeError를 일으킬 수 있다.
