Pytorch
1.[Pytorch]inplace=True

pytoch를 살펴보면 가끔 (... , inplace=True) 를 볼 수 있다.이는 입력에 대해 copy 하지 않고 직접적으로 operation을 진행한다는 의미로 볼 수 있다.
2.[Pytorch]torch.cat()
torch.cat(tensors, dim=0, \*, out=None) → Tensortorch.cat은 tensor를 concatenate해주는 역할을 한다.
3.[Pytorch]learning rate scheduler

learning rate scheduler중에 대표적으로 사용하는 것 중 하나인 cosine-annealing-with-warmup 방법이 있다.또 스튜핏한 짓을 해버렸는데, epoch이 10짜리인 훈련에서 scheduler step을 epoch으로 가져가 버렸다.그러
4.[Pytorch]Mixed Precision Examples (작성중)
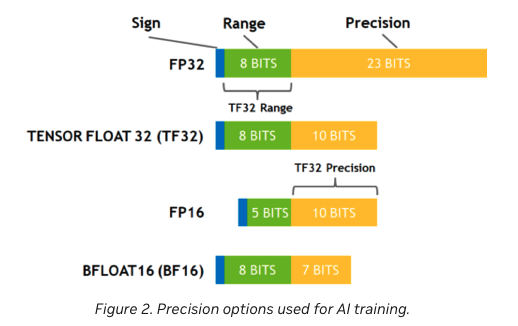
Mixed precision은 뭘까 ?
5.[pytorch]torch.topk()
torch.topk() 는 input tensor의 가장 높은 k 개의 value값들과 index를 뽑아주는 함수이다.
6.[pytorch]nn.Linear
https://pytorch.org/docs/stable/generated/torch.nn.Linear.html새롭게 알게된 점Pytorch의 Linear layer 모듈은 오직 TensorFloat32 dtype만을 지원한다.
7.[pytorch]torch.optim.AdamW (작성중)

AdamW의 수도코드는 아래와 같다.
8.[pytorch]no_grad()
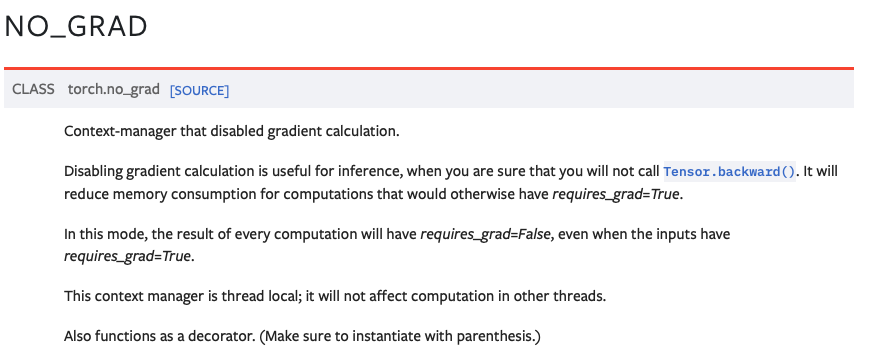
를 해주고 싶을 때 사용하면 된다.
9.[pytorch] DataParallel and DistributedDataParallel (작성중)
Pytorch DataPrallel말 그대로 Data를 병렬적으로 처리하기 위한 module level에서의 multi gpu 사용 방법이다.진짜 간단한데 다음과 같은 코드 한줄로 병렬화를 할 수 있다.DDP에 비하면 정말 간단하다 !근데 귀찮게 Data를 나누는 이유
10.[pytorch] num_workers (작성중)
Pytorch를 가지고 모델을 훈련하다보면 가끔 GPU util이 제대로 나오지 않는 상황을 발견할 수 있다.여러가지 이유가 있겠지만, 가장 먼저 생각해볼 것은 GPU에 올리기 위한 CPU의 연산이 적절히 수행되고 있는가를 살펴볼 수 있을 것이다. 특히, Imagene
11.[pytorch] Subset
가끔 데이터를 쓰다보면torch.util.data.Dataset을 list를 통해 indexing 하고 싶을 때가 있을것이다.이를 위해torch.utils.data.Subset이 존재한다.이런식으로 사용하면, 내가 원하는 index를 가지는 데이터만을 데이터셋으로 불러
12.[pytorch]torch.utils.data.ConcatDataset
위 함수를 사용하면, 여러개의 데이터셋을 합칠 수 있다.
13.[pytorch] list 안에 tensor가 존재하는 경우
list 안에 이미 torch.Tensor이 있고, 그것들의 dtype이 CUDA일 경우, 이를 하나의 torch.Tensor로 변환하려면 torch.stack을 사용할 수 있습니다. 이 함수는 주어진 텐서의 리스트를 하나의 텐서로 쌓아줍니다.다음은 예제 코드입니다:p
14.[Pytorch]nn.Conv2d()
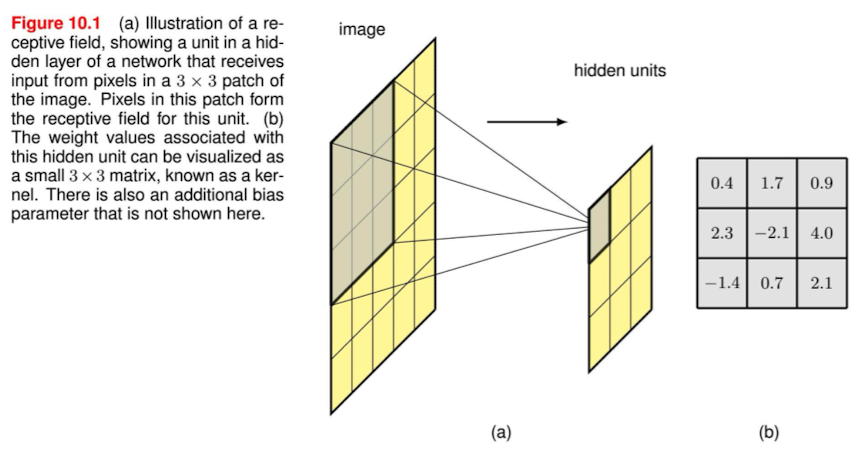
CONV2DPytorch Conv2d linkConvolutional layer란 무엇인가 ?Convolutional network를 구성하는 layer를 의미하는데, 이미지 데이터를 위해 설계된 네트워크이다. 그러면 기존의 Fully connected layer와는
15.[pytorch]nn.BatchNorm2d()
BatchNorm2d는 4D input (a mini-batch of 2D inputs with additional channel dim)에 적용되는데, Internal Covariate Shift는 줄여주는 역할을 한다고 함.코드는 아래와 같이 동작 시킬 수 있음$$
16.[pytorch] jupyter notebook gpu지정
os.environ\["CUDA_VISIBLE_DEVICES"]= 사용하고자 하는 GPU
17.[conda] create env
conda create -n ~ python=3.10 conda activate ~ conda install pytorch pytorch-cuda=11.8 -c pytorch -c nvidia conda install -c "nvidia/label/cuda-11.8.0" cuda-toolkit
18.[Pytorch]torch.flatten()

torch.flatten(input, start_dim=0, end_dim=- 1) → Tensortorch.flatten 은 입력을 1차원 텐서로 reshape 해준다. start_dim과 end_dim을 입력해줄 수 있다.요런식으로 작동한다.start_dim을 설정
19.[pytorch]torch.optim.RMSprop

https://pytorch.org/docs/stable/generated/torch.optim.RMSprop.htmlRMSprop 수도코드는 아래와 같다.차근차근 위 내용을 설명해보자.일단 RMSprop이 왜나왔나부터 보면AdaGrad의 학습이 진행될 때 학
20.[pytorch] 왜인지는 모르겠는데..
왜 얘만 deepspeed가 깔리냐
21.[Pytorch]super(class, self).__init__()
코드 보다보면, class를 정의할 때, super(class_name, self).\_\_init\_\_()을 를 사용하는 경우가 있는데 이게 왜 필요할까 .. ?부모 클래스에 이미 구현된 초기화 로직을 재사용할 수 있다. 이를 통해 코드의 중복을 줄이고 유지보수를
22.[Pytorch]torch.stack
torch.stack은 리스트 또는 배열 형태의 텐서들을 하나의 torch.Tensor로 결합해주는 함수. 입력 텐서들을 새로운 차원으로 쌓는 역할.torch.stack은 여러 텐서를 주어진 새 축(dim)을 따라 연결. 즉, 입력 텐서 리스트의 요소들은 동일한 크기를
23.[Pytorch]torch.contiguous()
contiguous()는 PyTorch에서 텐서의 메모리 레이아웃을 연속적(contiguous)으로 변환하는 역할을 함. 이 함수는 텐서가 연속적인 메모리 레이아웃을 가지지 않는 경우 이를 새로운 텐서로 만들어 반환하는 역할. PyTorch 텐서는 기본적으로 데이터를
24.[Pytorch]CrossEntropyLoss(weight)
CrossEntropyLoss에서 가중치(weight)는 softmax를 적용한 확률이 아니라, 최종 손실 값에 곱해짐. 따라서 가중치는 로그 확률에 곱해서 손실을 조정하는 역할.$$\\text{Loss} = -\\frac{1}{N} \\sum{i=1}^N \\text
25.[Pytorch]args, kwargs
파이썬에서 args와 kwwargs는 함수를 정의할 때 가변 인자(Variable-length arguments)를 받아들이기 위한 문법적 장치.여러 개의 위치 기반 인자를 튜플 형태로 전달받는다.함수나 메서드를 호출할 때, 인자의 개수가 가변적일 수 있도록 유연성을
26.[Pytorch]Resize
Pytorch의 Resize에 대해서 알아보자.