문제
https://www.acmicpc.net/problem/9466
이번 가을학기에 '문제 해결' 강의를 신청한 학생들은 텀 프로젝트를 수행해야 한다. 프로젝트 팀원 수에는 제한이 없다. 심지어 모든 학생들이 동일한 팀의 팀원인 경우와 같이 한 팀만 있을 수도 있다. 프로젝트 팀을 구성하기 위해, 모든 학생들은 프로젝트를 함께하고 싶은 학생을 선택해야 한다. (단, 단 한 명만 선택할 수 있다.) 혼자 하고 싶어하는 학생은 자기 자신을 선택하는 것도 가능하다.
학생들이(s1, s2, ..., sr)이라 할 때, r=1이고 s1이 s1을 선택하는 경우나, s1이 s2를 선택하고, s2가 s3를 선택하고,..., sr-1이 sr을 선택하고, sr이 s1을 선택하는 경우에만 한 팀이 될 수 있다.
예를 들어, 한 반에 7명의 학생이 있다고 하자. 학생들을 1번부터 7번으로 표현할 때, 선택의 결과는 다음과 같다.
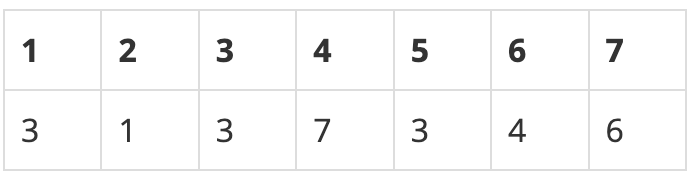
위의 결과를 통해 (3)과 (4, 7, 6)이 팀을 이룰 수 있다. 1, 2, 5는 어느 팀에도 속하지 않는다.
주어진 선택의 결과를 보고 어느 프로젝트 팀에도 속하지 않는 학생들의 수를 계산하는 프로그램을 작성하라.
입력
첫째 줄에 테스트 케이스의 개수 T가 주어진다. 각 테스트 케이스의 첫 줄에는 학생의 수가 정수 n (2 ≤ n ≤ 100,000)으로 주어진다. 각 테스트 케이스의 둘째 줄에는 선택된 학생들의 번호가 주어진다. (모든 학생들은 1부터 n까지 번호가 부여된다.)
출력
각 테스트 케이스마다 한 줄에 출력하고, 각 줄에는 프로젝트 팀에 속하지 못한 학생들의 수를 나타내면 된다.
예제 입력 1
2
7
3 1 3 7 3 4 6
8
1 2 3 4 5 6 7 8
예제 출력 1
3
0
접근
얼마 전에 풀었던 2668 숫자고르기 문제가 DFS를 통한 사이클 판별 문제였는데, 처음 접해보는 유형이라.. 완전 하드 코딩해서 풀었다. 그래서 조만간 다시 풀어봐야지 생각하고 있었는데, 공교롭게도 오늘 푼 이 문제가 2668 숫자고르기와 꽤나 유사한 DFS를 통한 사이클 판별 문제였다.
이 문제는 사이클을 형성하지 않는 노드의 수를 찾아야 한다는 게 차이점이었다.
구현
1차 시도
DFS로 사이클 판별하는 걸 한 번도 해본 적이 없었는데, 일단 그냥 처음에는 풀이를 안 보고 내 생각대로 한 번 구현해봤다.
for문을 통해 시작 지점(init)을 순차적으로 지정하고, 그래프를 타고 들어가다가 처음 시작 지점으로 돌아온 경우 사이클로 판별하고 사이클 노드 수만큼을 감소시키는 방향으로 구현했다.
import java.io.*;
import java.util.*;
class Main {
static int[] selection;
static Set<Integer> grouped = new HashSet<>();
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int T = Integer.parseInt(br.readLine());
StringBuilder sb = new StringBuilder();
for (int t = 0; t < T; t++) {
int N = Integer.parseInt(br.readLine());
String[] input = br.readLine().split(" ");
selection = new int[N + 1];
for (int i = 1; i <= N; i++) {
selection[i] = Integer.parseInt(input[i - 1]);
}
for (int i = 1; i <= N; i++) {
if (grouped.contains(i)) {
continue;
}
dfs(i, 0, new HashSet<>());
}
sb.append(N - grouped.size()).append("\n");
grouped.clear();
}
System.out.println(sb.toString());
}
private static void dfs(int init, int curr, Set<Integer> path) {
if (init == curr) {
path.add(init);
grouped.addAll(path);
return;
}
if (path.contains(curr)) {
return;
}
if (curr == 0) {
dfs(init, selection[init], path);
return;
}
path.add(curr);
dfs(init, selection[curr], path);
}
}
80% 정도에서 시간 초과가 났다.
최종 구현
사이클이 꼭 시작 지점이 아니더라도 탐색 중간에 발견될 수도 있는데, 내가 구현한 코드는 무조건 시작으로 돌아오는 사이클이 아니면 중간에 사이클이 발견되더라도 무시되는 게 가장 큰 문제였다. 이렇게 되면 이미 발견했던 사이클을 재차 발견하기 위해 중복 탐색이 불가피하다.
나도 이게 문제라는 건 알았는데, 시작 지점으로 다시 돌아왔다는 걸 감지하는 건 시작 지점을 저장해두면 쉽게 알 수 있는 반면 중간에 만들어진 사이클을 어떻게 감지하는지 감이 잘 안 왔다.
그래서 챗지피티를 좀 닦달했다!
import java.io.*;
import java.util.*;
class Main {
static int[] selection;
static boolean[] visited;
static boolean[] inCycle; // 사이클에 포함된 노드 표시
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int T = Integer.parseInt(br.readLine());
StringBuilder sb = new StringBuilder();
for (int t = 0; t < T; t++) {
int N = Integer.parseInt(br.readLine());
String[] input = br.readLine().split(" ");
selection = new int[N + 1];
visited = new boolean[N + 1];
inCycle = new boolean[N + 1];
for (int i = 1; i <= N; i++) {
selection[i] = Integer.parseInt(input[i - 1]);
}
for (int i = 1; i <= N; i++) {
if (!visited[i]) {
dfs(i);
}
}
int cycleCount = 0;
for (int i = 1; i <= N; i++) {
if (inCycle[i]) cycleCount++;
}
sb.append(N - cycleCount).append("\n");
}
System.out.println(sb.toString());
}
private static void dfs(int start) {
int curr = start;
List<Integer> path = new ArrayList<>();
while (true) {
if (visited[curr]) { // 이미 방문한 노드인 경우
// 현재 탐색 중 방문한 노드인 경우(== 사이클 발견)
if (path.contains(curr)) {
int cycleStartIndex = path.indexOf(curr);
for (int i = cycleStartIndex; i < path.size(); i++) {
inCycle[path.get(i)] = true;
}
}
return;
}
visited[curr] = true;
path.add(curr);
curr = selection[curr];
}
}
visited[curr] = true; // 방문 처리
path.add(curr);
curr = selection[curr]; // 다음 노드로 이동
}
}
}
왔던 지점을 다시 방문했다면 사이클로 판별하자.
사실 별 거 아닌데, 내가 처음 구현했을 때는 시작 지점 외의 노드에 대한 재방문은 오히려 사이클이 아니라고 판별하는 식으로 생각하고 했던지라 사고가 좀 갇혀 있었던 것 같다.

이해한 내용 바탕으로 숫자고르기도 다시 풀어봐야겠다...!
