프로젝트 기간 : 2023.04.07 ~ 2023.04.13
프로젝트 도구 : OpenAPI, Google Colab
사용언어 : Python
프로젝트명 : 네이버 오픈 API를 이용한 상품 판매전략
프로젝트 배경
- 우리는 의류 판매를 위한 최적의 상품 가격을 선정하려고 합니다. 이 과정에서 고려해야 할 성별과 플랫폼은 무엇인지, 그리고 최적 가격에 영향을 미치는 요소들은 어떤 것들인지 파악하려 합니다.
프로젝트 개요
우리는 패션 의류에 대한 검색 패턴을 파악하기 위해 사용자의 성별과 검색 기기(PC, Mobile)를 조사하며, 최근의 트렌드에 맞는 패션 의류를 확인합니다. 네이버에서 판매되는 의류의 상품명, 카테고리, 최저가 등의 정보는 네이버의 Open API를 활용하여 수집합니다. 이후 수집된 데이터는 전처리 과정을 거칩니다. 그리고 다양한 머신러닝 기법을 활용하여 모델의 성능을 평가하고, 어떤 항목이 의류 가격에 큰 영향을 미치는지 분석합니다.
프로젝트 기술스택
- Open API, Python
- Google Colab
프로젝트 진행과정
- 네이버 Open API를 통해 성별기준 패션의류를 검색한 기기 확인
- 타겟팅할 성별과 기기를 선정
- 오픈 API를 통해 상품정보 수집(상품명, 카테고리, 가격 등)
- 데이터 전처리
- 머신러닝 모델링을 이용한 상품 가격을 결정하는 요소 확인
프로젝트 흐름도
프로젝트 구현내용
1. 네이버 Open API를 이용한 데이터 수집
(1) 오픈 API 가입
(2) API 호출 및 데이터 시각화
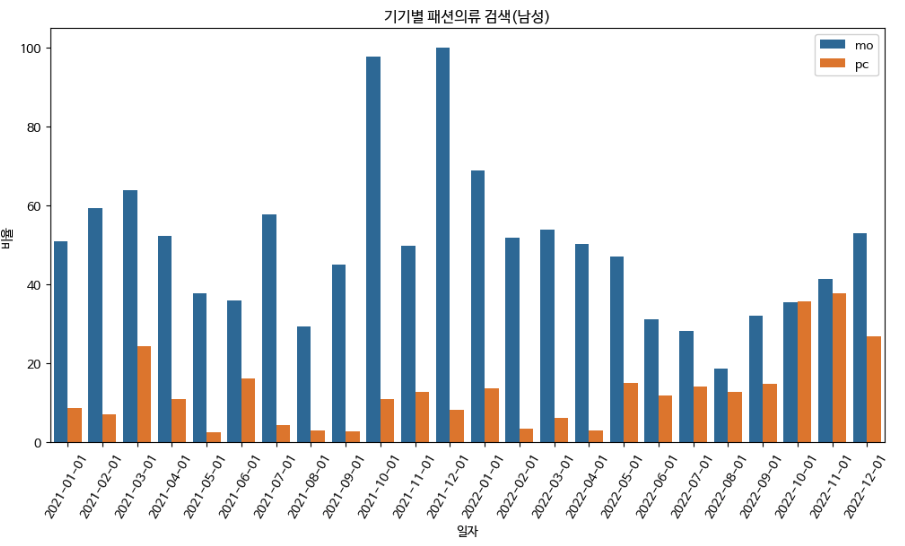
기기별 패션의류 검색 비율
# 네이버 Open API 인증 정보 client_id = "클라이언트아이디" client_secret = "패스워드" # 요청 헤더 설정 headers = { 'Content-Type': 'application/json', 'X-Naver-Client-Id': client_id, 'X-Naver-Client-Secret': client_secret } # 요청 URL url = "https://openapi.naver.com/v1/datalab/shopping/category/keyword/device" # 요청 Body body = { "startDate": "2021-01-01", "endDate": "2022-12-31", "timeUnit": "month", "category": "50000000", "keyword": "남성", "device": "", "gender": "m", "ages": [] } # API 호출 response = requests.post(url, headers=headers, data=json.dumps(body)) # 응답 데이터 확인 data = response.json() # 데이터프레임화 results = data['results'][0]['data'] df_mdevice = pd.DataFrame(results, columns=['period', 'ratio', 'group']) df_mdevice['category'] = '패션의류' df_mdevice['gender'] = '남성' # 차트 그래프 시각화 fig, ax = plt.subplots(figsize=(12, 6)) # seaborn 막대그래프 시각화 sns.barplot(data=df_mdevice, x='period', y='ratio', hue='group', ax=ax) # x, y축 라벨링 ax.set_xlabel('일자') ax.set_ylabel('비율') plt.xticks(rotation=60) # 그래프 제목 설정 title = '기기별 패션의류 검색(남성)' ax.set_title(title) # 범례 설정 ax.legend() plt.show()
21~22년 기준 남성의 경우 모바일이 압도적으로 높다.
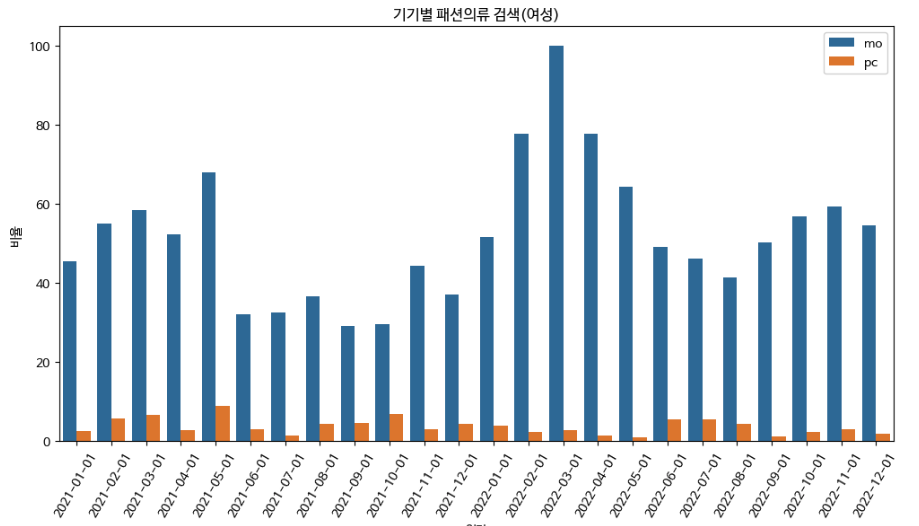
같은 방식으로 여성도 검색
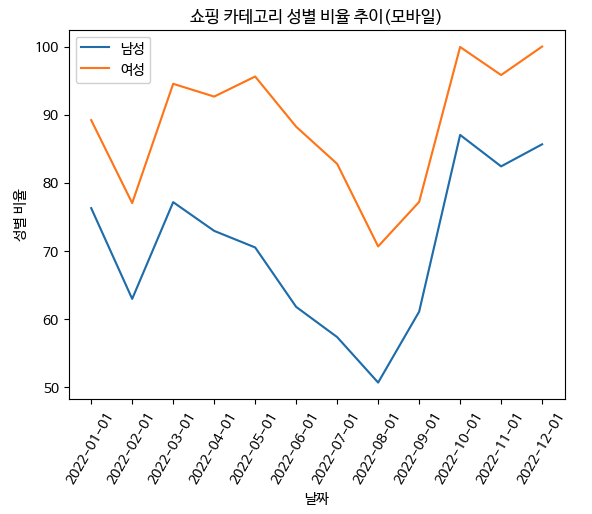
어떤 성별이 모바일로 패션의류를 검색하는지 확인했을 때 여성이 더 많이 하는 것을 확인
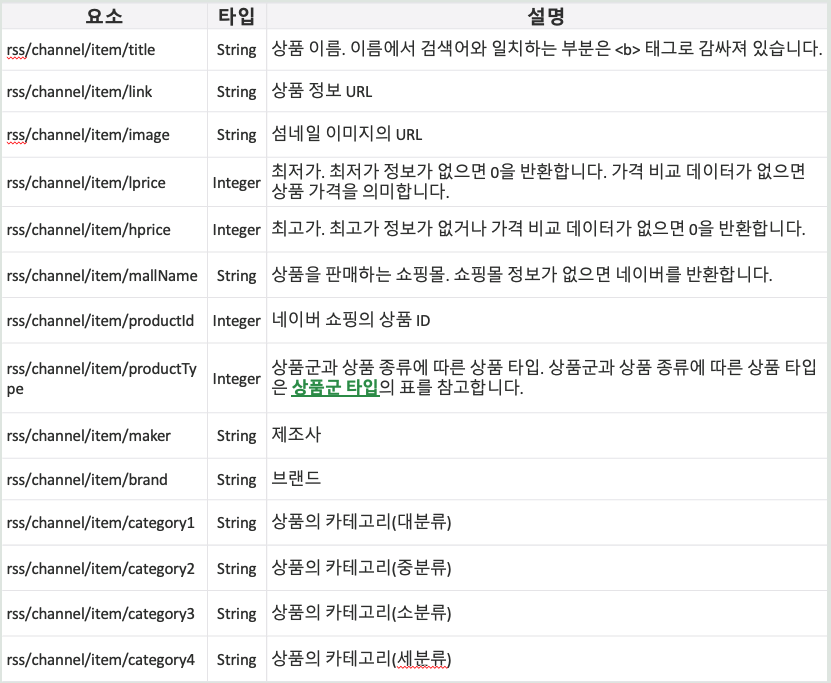
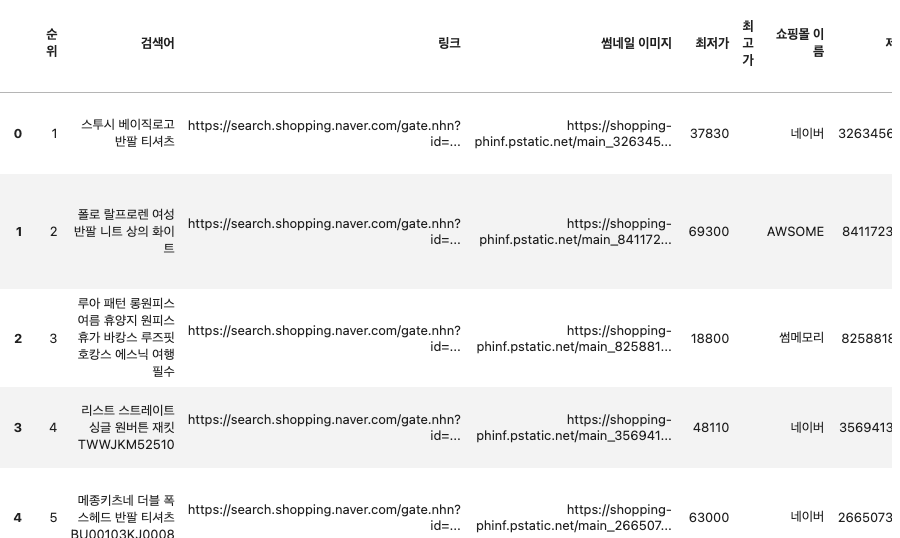
Open API를 통해 패션의류 정보 수집
# 클라이언트 아이디와 시크릿을 변수에 저장합니다. client_id = "" client_secret = "" # 검색어와 필요한 데이터 개수, 정렬 순서 등을 변수에 저장합니다. query = "패션의류" display = 100 sort = "sim" # API 요청을 보낼 URL을 생성합니다. url = f"https://openapi.naver.com/v1/search/shop.json?query={query}&display={display}&sort={sort}" # API 요청에 필요한 헤더 정보를 변수에 저장합니다. headers = { "X-Naver-Client-Id": client_id, "X-Naver-Client-Secret": client_secret, } # API 요청을 보내고, 응답 데이터를 받습니다. response = requests.get(url, headers=headers) data = response.json() # 데이터에서 모든 결과 컬럼을 추출합니다. result = [] for i, item in enumerate(data["items"]): rank = i + 1 title = item["title"] link = item["link"] image = item["image"] lprice = item["lprice"] hprice = item["hprice"] mallName = item["mallName"] productId = item["productId"] productType = item["productType"] brand = item["brand"] maker = item["maker"] category1 = item["category1"] category2 = item["category2"] category3 = item["category3"] category4 = item["category4"] result.append((rank, title, link, image, lprice, hprice, mallName, productId, productType, brand, maker, category1, category2, category3, category4)) # 추출한 데이터를 데이터 프레임으로 변환합니다. df_top100 = pd.DataFrame(result, columns=["순위", "검색어", "링크", "썸네일 이미지", "최저가", "최고가", "쇼핑몰 이름", "제품 ID", "제품 타입", "브랜드", "제조사", "카테고리1", "카테고리2", "카테고리3", "카테고리4"])
데이터 수집 완료
2. Pandas를 이용하여 데이터 정제 및 csv 파일로 변환
(1) 중복값 제거
(2) 관련 없는 열 제거
Link : 쇼핑 URL
Image : 상품 사진
High Price : 최고가. 값이 존재하지 않아 삭제
Product Id : 품번
(3) 결측치 대체
Maker와 Brand의 결측치는 각각 No-Maker, No-Brand로 대체
(4) Feature Engineering
1. Brand Point
인기있는 브랜드를 순서로 하여 3점,2점,1점 을 부여
2. Maker Point
메이커가 있는 상품이면 1점 없으면 0점을 부여
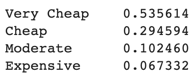
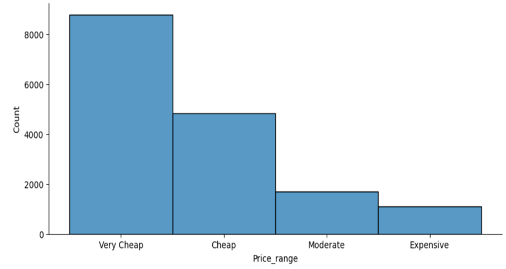
3. Price_range , Price_range_score
Low Price 컬럼에서 Min 값과 Max 값을 구해 4등분으로 나눠서 범주형으로 생성
Very cheap, Cheap, Moderate, Expensive 로 나눔, 각각 2,2,1,1 점으로 별도의 점수 부여
4. Total Point
- Brand point, Maker Point, Price_Range 의 점수를 더해 총 점수를 표현
3. 머신러닝 모델링을 통한 가격 결정 구성 요소 확인
(1) Feature Engineering에서 생성된 Price_range를 타겟으로 선정
타겟의 분포 확인 및 시각화
데이터를 7:3 비율로 나눔

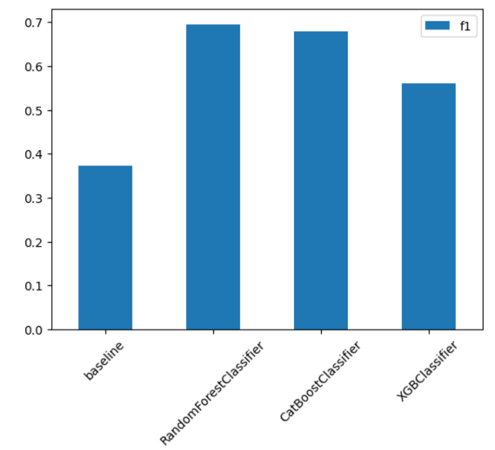
(2) RandomForestClassifier / CatBoostClassifier / XGBClassifier
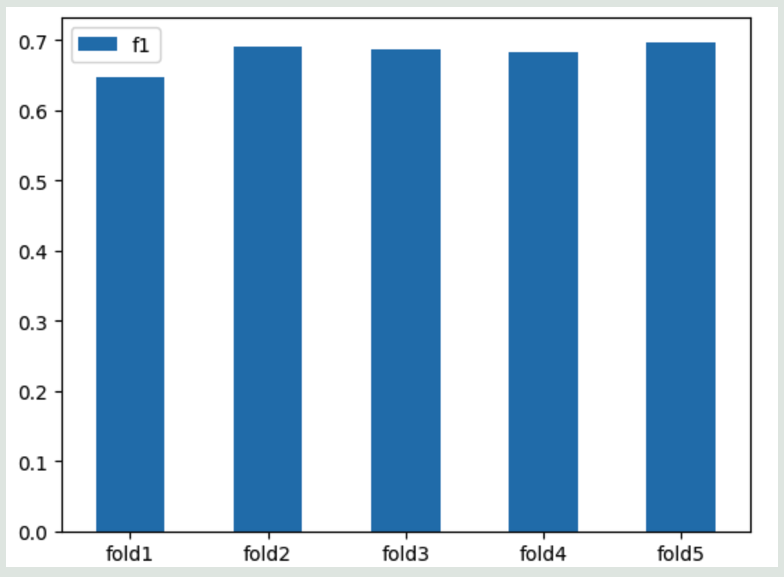
여러가지 모델링의 F1 score를 검증해본 결과 RandomForest 가 근소하게 앞섰다
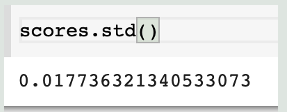
5-fold 교차검증을 수행하여 std 가 작다는 것을 확인(모델 복잡도에 비해 샘플수가 많음)
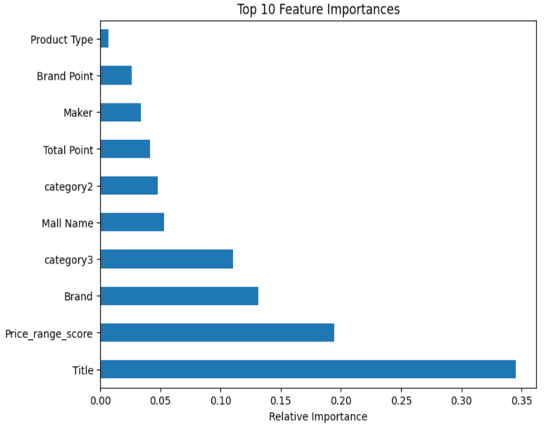
(3) 특성중요도 확인
랜덤포레스트 모델링 시 특성 중요도를 확인한 결과 Title 이 중요 변수라고 지목하지만 상품명(title)이 가격을 결정하는 요소는 아닌 것이 분명하며 상품명의 카디널리티가 많았던게 분석에 영향을 끼쳤으리라 추측
다음으로 중요하다고 한 Price_range_score 또한 타겟인 Price_range를 바탕으로 도출했기에 깊은 상관관계를 가진다고 추측
3,4 순위 Brand와 Categroy3의 연관성도 존재한다고 판단.
4. 최종 해석

