AIB18_Section3_PJT
프로젝트 기간 : 2023.05.10 ~ 2023.05.16
프로젝트 도구 : Selenium, Google Colab
사용언어 : Python
프로젝트명 : 네이버 쇼핑 리뷰를 이용한 소비자 감정 분석 예측
프로젝트 배경
- 대기질이 좋지 않는 날이 지속되어 공기청정기에 대한 수요는 꾸준히 증가하고 있기에
소비자들은 지속적인 리뷰를 작성할 것이고 제조사들은 제품에 대한 성능 추가 및 개선을 계속할 것이다.
제품에 대한 만족도나 불만사항은 리뷰에 반영되어 나타날 것이고
텍스트 마이닝을 통해 소비자들이 제품에 대한 만족도를 느꼈을 시 어떤 단어를 사용하는지 파악할 수 있을 것이다.
이 단어들을 알 수 있다면 향후 공기청정기를 판매 or 구입 시 예측 기준이 되리라 본다.
프로젝트 개요
Review Text Data : 네이버 랭킹 추천순위가 높은 공기청정기를 리뷰(삼성, LG, Dyson, 위닉스)
-> 소비자들은 제조사에 따라 만족도가 다를까?
-> 소비자들이 어떤 단어를 이용해 긍정적/부정적인 감정을 표현했을까?
프로젝트 기술스택
- Python(Selenium)
- Google Colab
프로젝트 진행과정
- 셀레니움을 이용하여 네이버 쇼핑 리뷰를 크롤링
- 제조사 평점별로 10페이지씩 추출(총 1548 리뷰)
- 크롤링한 리뷰 데이터를 정제(특수문자제거, 빈도수 낮은 단어 제거)
- 두 가지 모델로 진행, 제조사 정보를 이용한 소비자 감정분석과 특정 평점 이상일 경우를 기준으로 감정분석
프로젝트 흐름도
프로젝트 구현내용
1. 네이버 쇼핑몰 리뷰 수집
네이버 쇼핑몰 리뷰를 셀레니움을 이용하여 크롤링
-
네이버 쇼핑 자체 상품 평가 알고리즘인 ’네이버 랭킹’을 통해 각 제조사별 히트 상품 1개만 선택하여 리뷰를 크롤링 (광고상품제외)
-
제조사(삼성,LG,Dyson,위닉스) 평점별로 10페이지씩 추출 (총 1548개 리뷰 추출)
-
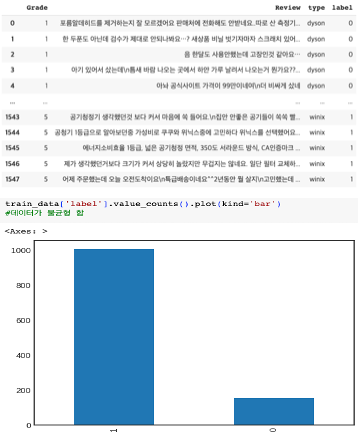
소비자들은 4,5점을 많이 부여했다.
1,2,3 점은 리뷰 수가 적음
2. 데이터 정제
- 한글과 공백을 제외하고 특수 문제 모두 제거

- OKT(Open Korean Text)를 이용 리뷰 형태소 분석
- 토큰화 및 불용어 제거
- 빈도수 낮은 단어 제거

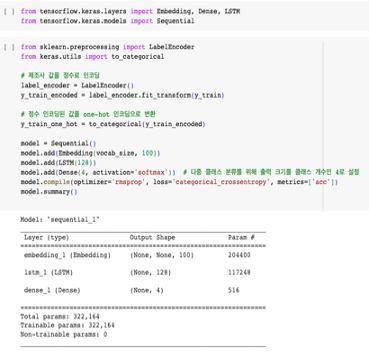
3. 딥러닝 모델 작성
(1) 제조사 기준
- 감정 상태 분류 모델을 선언하고 학습
일반적인 LSTM 모델을 사용
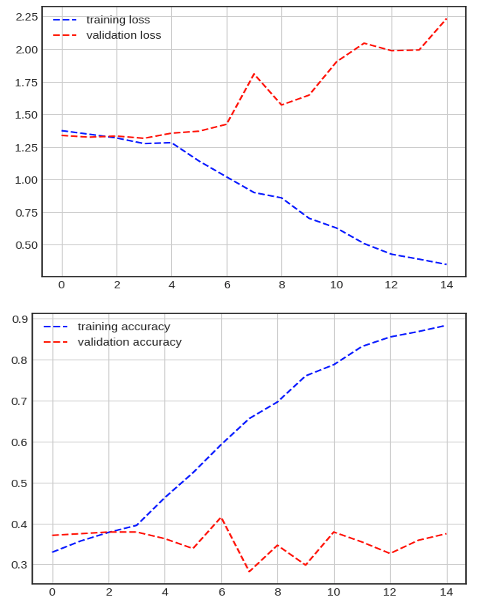
- 성능 분석 결과 Score 가 0.375가 나와 매우 낮은 성능
epoch을 진행해도 개선이 되지 않음
- 하단 그림의 훈련 loss와 평가 loss가 반복할 때마다 역전되는 현상을 확인
Overfitting 발생
제조사(text) 컬럼 원-핫 인코딩 및 다중클래스 분류를 거쳤어도,
정확도를 높이는 것이 실패했음을 의미
- 감정 예측을 실시했지만 긍정/부정을 정확하게 나누지 못함


(2) 평점 기준
- 과적합이 발생된 것으로 보이나 정확도 및 loss 부분에서 안정적인 수치를 보여줌
- 감정 예측 실시, 제조사 기준 모델보다 조금 더 정확하게 예측하는 것을 확인


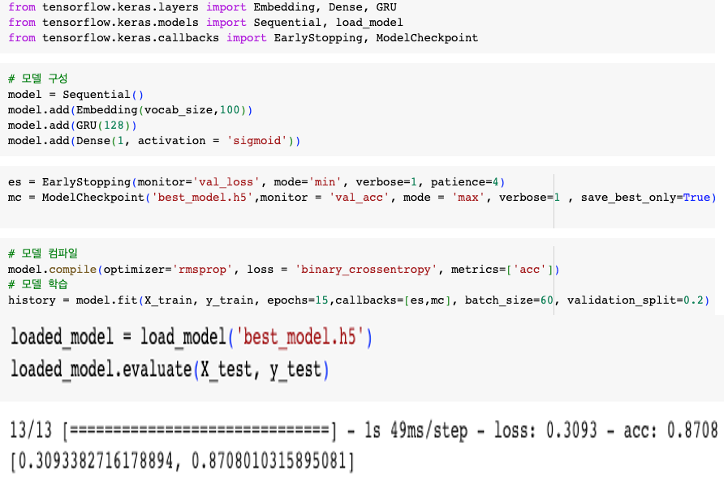
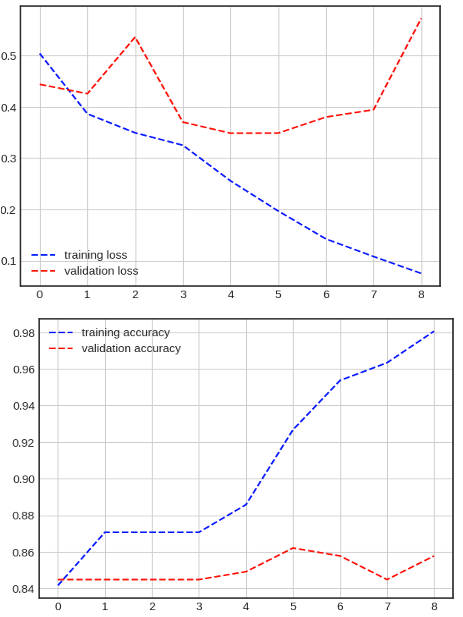

3. 최종 해석
-
제조사 정보를 이용한 소비자 감성분석은 감성 예측에는 도움이 되지 못했다.
-
평점을 이용하여 일정 점수가 넘을 경우로 분류하는 것이 감정분석 예측에 더 효과적이었다.
-
제작한 감성분석 예측 모델을 이용하여 단어를 입력하면 긍정적일지 부정적일지 예측이 가능하다.
