AIB18_Section7_PJT
AIB18기 DA 12팀 - AI-CINE팀
프로젝트 기간 : 2023.08.09 ~ 2023.09.05
프로젝트 도구 : Google Colab, Recbole
사용언어 : Python, SQL
조원 및 전담 파트
김영석(팀장) : 프로젝트 플래닝, 발표자료 작성
구민승(팀원) : 메모리 기반 추천시스템 작성
강규욱(팀원) : 모델 기반 추천 시스템(딥러닝)
이강우(팀원) : 컨텐츠 기반 추천 시스템
프로젝트명 : 영화 추천 시스템 개발
프로젝트 배경
- T사는 인터넷을 통해 영화 미디어 콘텐츠를 제공하는 서비스를 운영 중입니다. 시장 경쟁력을 높이고 고객 이탈을 최소화하기 위해 다양한 액션 플랜을 고려 중입니다. 이 중에서도, 영화 추천 서비스의 품질을 향상시키는 것이 중요한 과제로 여겨지고 있습니다
프로젝트 개요
- Movielens 데이터를 분석하여 영화 추천 시스템을 개선
- 개인화 추천 시스템을 기반으로 추천 시스템을 고도화
- 추천 시스템은 평가 지표를 통해 최적의 추천 시스템 선정
- 개선된 추천 알고리즘을 통해 고객 만족 및 시장 점유율 증대
프로젝트 기술스택
- 데이터 분석
- Python, Pandas
- Recbole 라이브러리
- BPR, LightFM, Ract 등
프로젝트 진행과정
- 데이터 분석을 통해 도메인 조사, 데이터 전처리 과정을 진행
- 기본 모델 구축을 통해 모델 구조 정립
- 개선 모델 구상
- 평가 지표를 이용한 모델 결과 분석
- 추천 서비스 개선
프로젝트 상세 일정

프로젝트 구현내용
1.데이터 분석
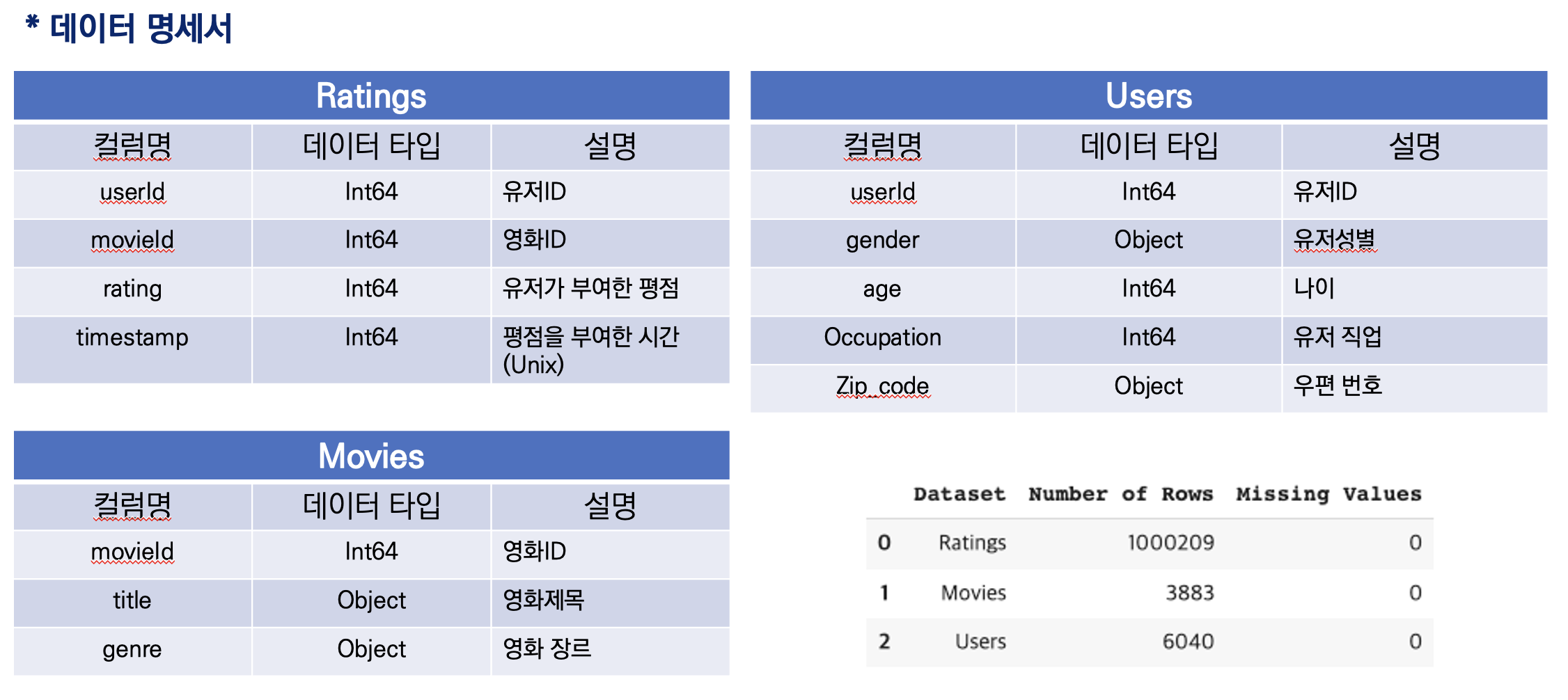
(1) 데이터 명세
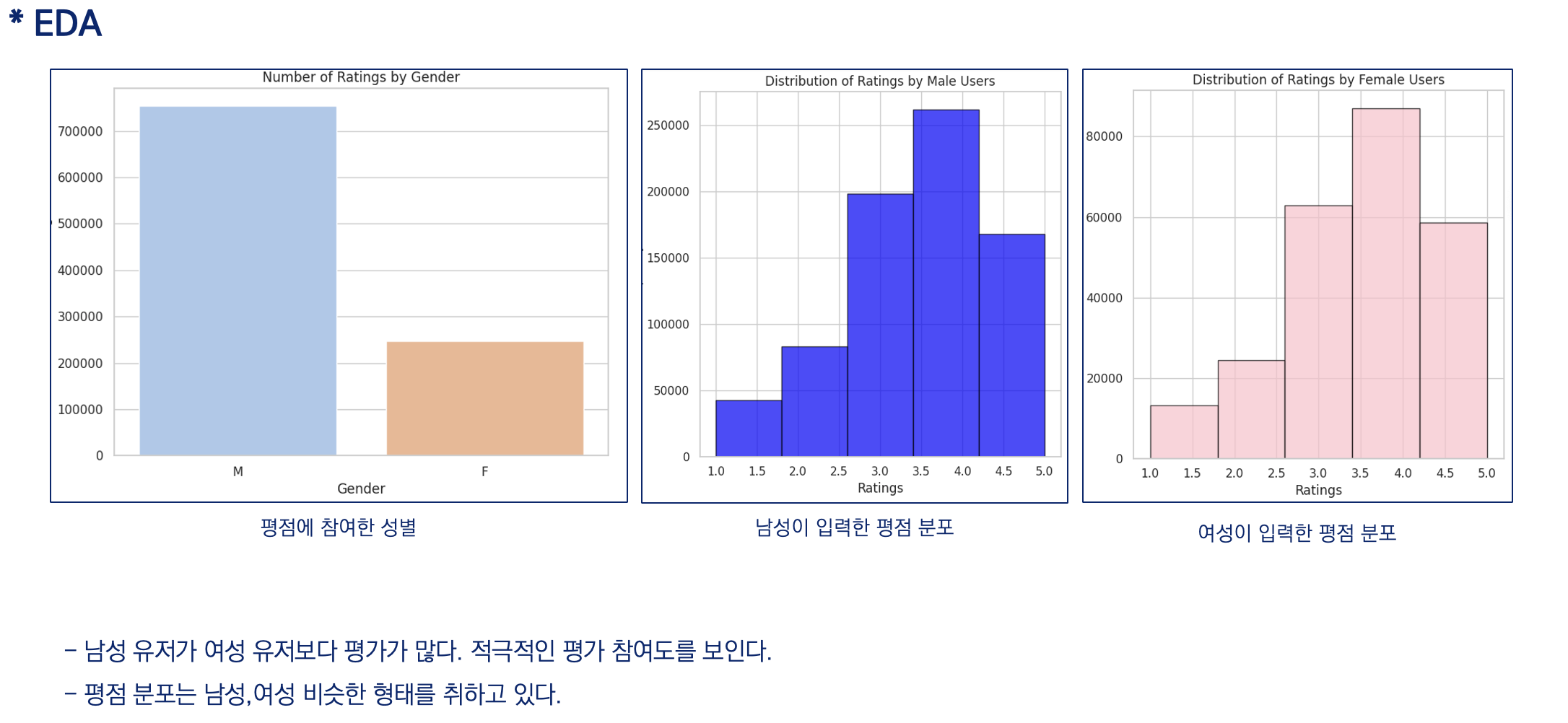
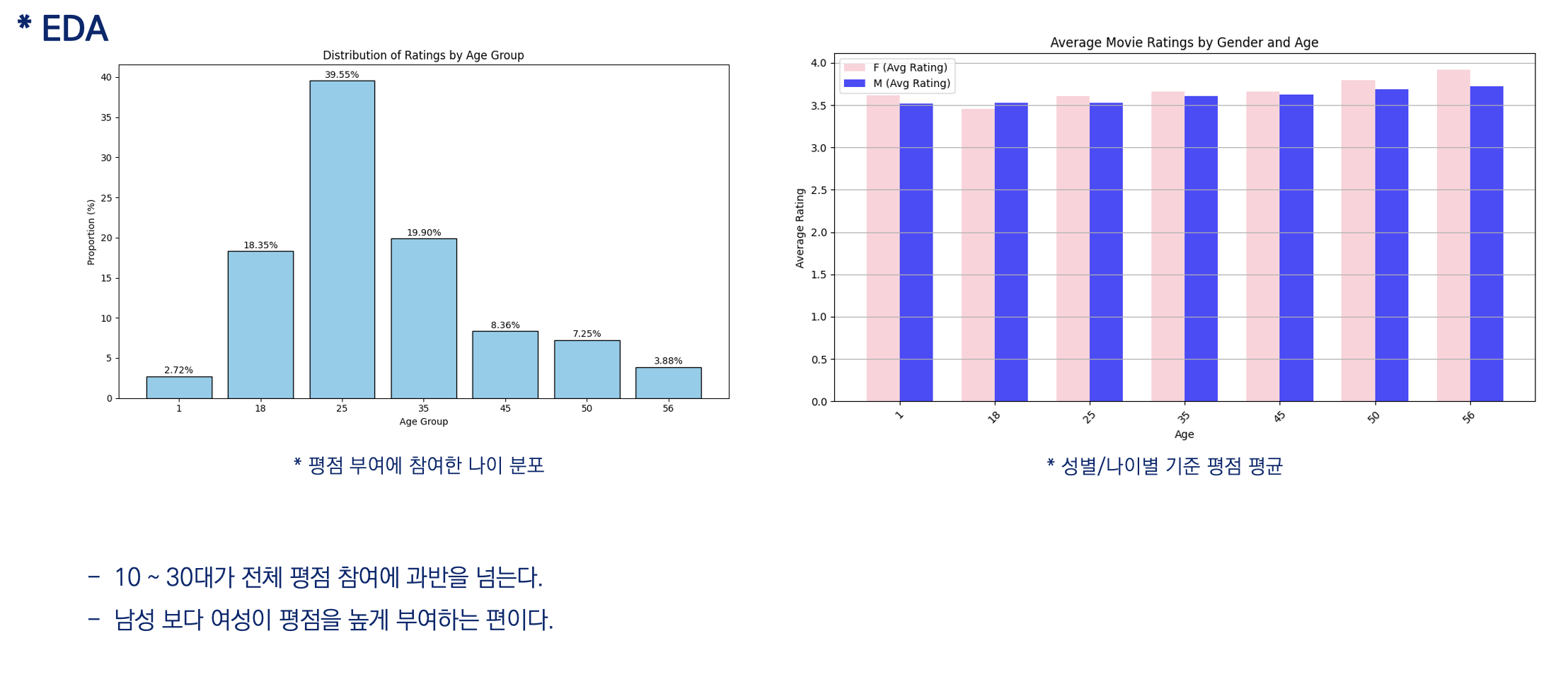
(2) EDA
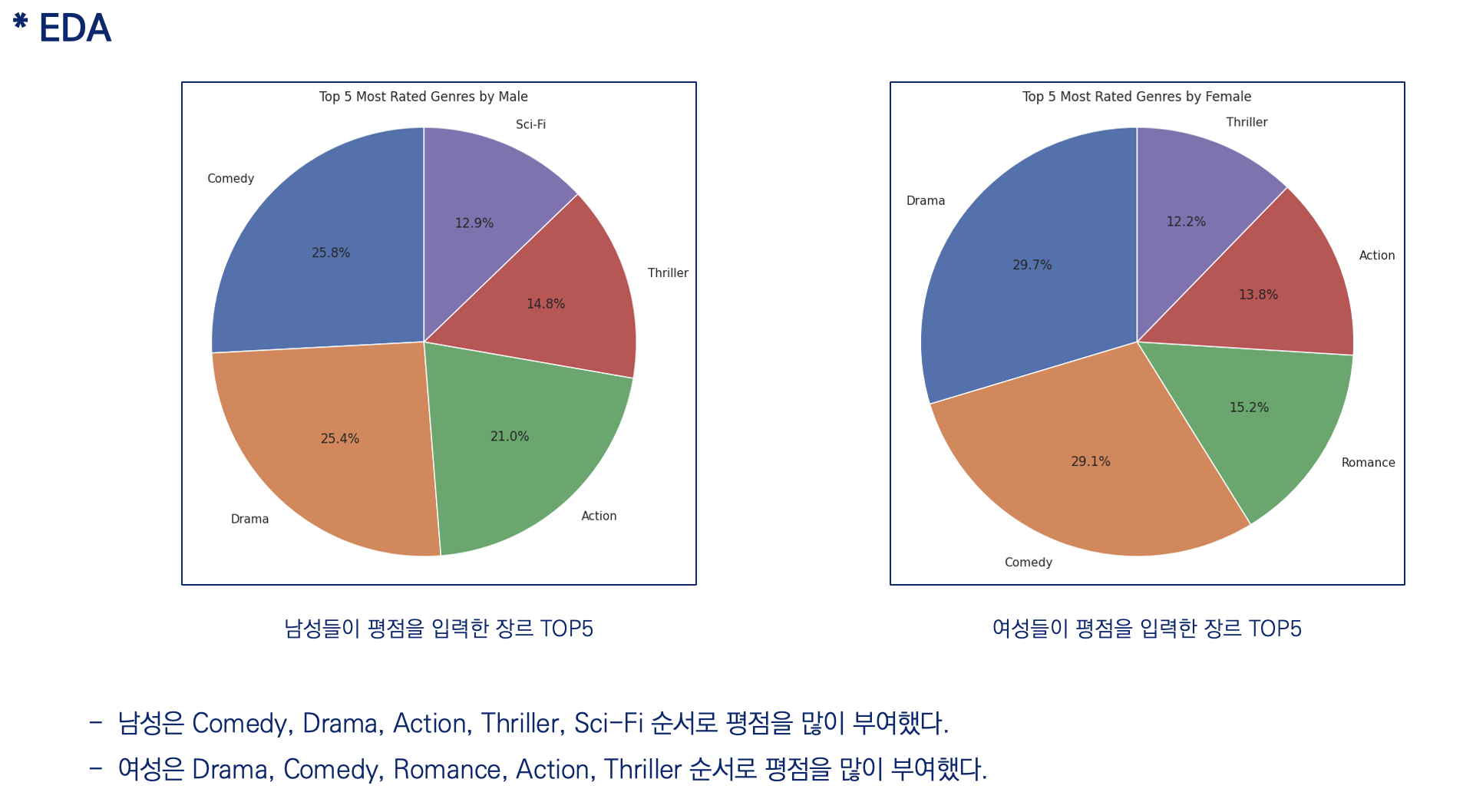
- 분석 결론
평점 참여는 여성보다 남성이 많이 참여한다.
성별에 따른 장르 선호도에 차이가 있다.
평점을 부여하는 연령대가 10~30대에 집중되어 있다.
영화 장르의 경우도 시청자의 선호도에 반영하여 개봉하는 것으로 판단된다.개선된 추천 모델을 통해 시청자 선호도가 높은 영화 장르를 위주로 추천이 되어야 합니다.
2. 기본 모델 분석
(1). 비개인화 특성
비개인화 추천은 상품의 인기도, 연관성 등을 고려하여 추천하기 때문에 유저 관련 정보가 필요하지 않습니다.
다만 비개인화 추천 시스템 또한 모든 유저에게 동일한 추천 서비스를 제공한다는 한계점을 가지고 있기 때문에 대부분의 서비스에서 비개인화 추천 시스템과 개인화 추천 시스템을 함께 사용하고 있습니다.
대표적인 시스템으로는 인기도 기반, 조회수 기반, 평점 기반 추천 등이 있습니다.
현재 주어진 비개인화 모델은 단순 인기도 기반 추천 시스템이어서 개인적 특성이 고려되지 않아 활용성이 낮은 추천 시스템
(2). 개인화 - 콘텐츠 기반 특성
유저에 대한 정보 없이도 콘텐츠(상품) 자체의 이름, 카테고리, 특징 등에 대한 데이터로 유사성을 측정하고 비슷한 아이템을 추천할 수 있습니다.
TF-IDF나 임베딩을 활용하여 콘텐츠를 하나의 벡터로 나타내고, 서로의 유사도를 측정하여 거리가 가까운 아이템들을 순차적으로 추천하는 것이 가장 기본적인 콘텐츠 기반 필터링 알고리즘입니다.
- 콘텐츠 기반 필터링(KNN)은 특정 사용자가 본 영화의 정보의 벡터를 평균하여 새로운 입력 벡터를 만들고 가장 가까운 N개의 영화를 추천하는 방식
- 장점으로는 콘텐츠 정보만 있다면 추천이 가능하기에 콜드 스타트 문제를 어느 정도 대응 가능하며 사용자간 상호작용을 고려할 필요가 없어 계산 복잡성이 낮다.
- 단점은 콘텐츠 정보가 제한적이면 추천의 정확도가 떨어질 수 있고, 사용자 간의 유사성을 고려하지 않아 유사성 추천은 어렵다.
(3). 개인화 - 협업 필터링
협업 필터링은 타겟 고객과 가장 비슷한 취향을 가진 다른 유저들의 상품 조회, 구매 이력을 참고하여 상품을 추천하는 방법입니다.
쉽게 말해 “자신과 성향이 비슷한 친구들이 본 영화를 추천한다”고 생각할 수 있습니다.
협업 필터링에서 사용되는 핵심 가정은 “자신과 비슷한 취향을 가진 사람들은 특정 아이템에 대해 비슷한 선호도를 가질 것”이라는 점입니다.
- 협업 필터링(Matrix Factorization)은 딥러닝을 활용하여 시청한 영화 기록을 학습한 후 영화를 추천해주는 시스템
- 장점으로는 다양한 사용자의 행동을 고려해 높은 수준의 개인화 구현 가능하며 대규모 데이터 셋에서도 효율적으로 활용 가능하다.
- 단점으로는 새로운 사용자나 아이템에 대한 정보가 충분하지 않을 경우, 추천의 정확성이 떨어질 수 있다.
비개인화 모델을 고도화 하는 것보다 개인화 모델에서 다양한 알고리즘을 이용한 최적의 추천 모델을 구현하자
3. 신규모델 선정
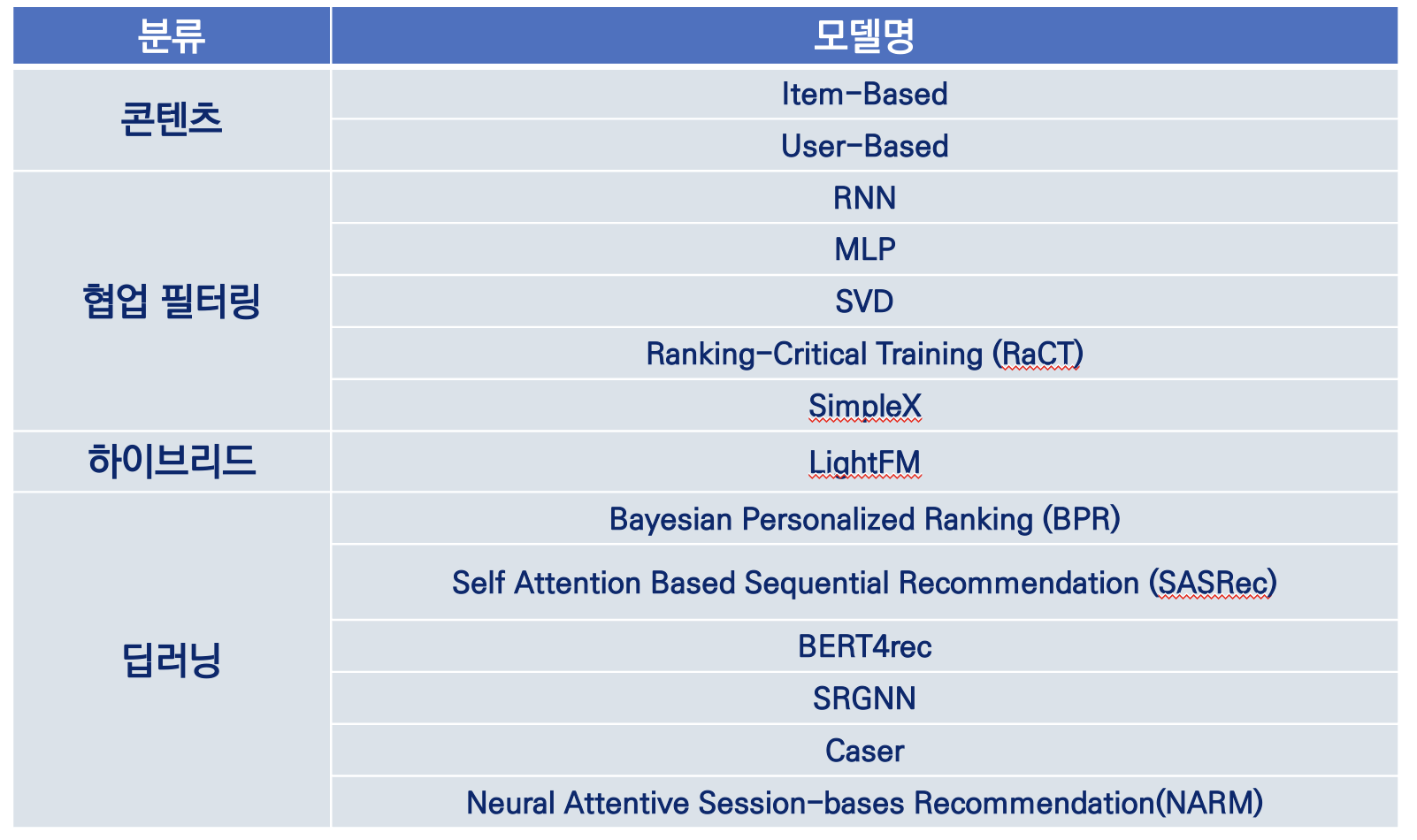
3. 모델 성능 평가 및 결과
(1). 모델 성능 평가 수립
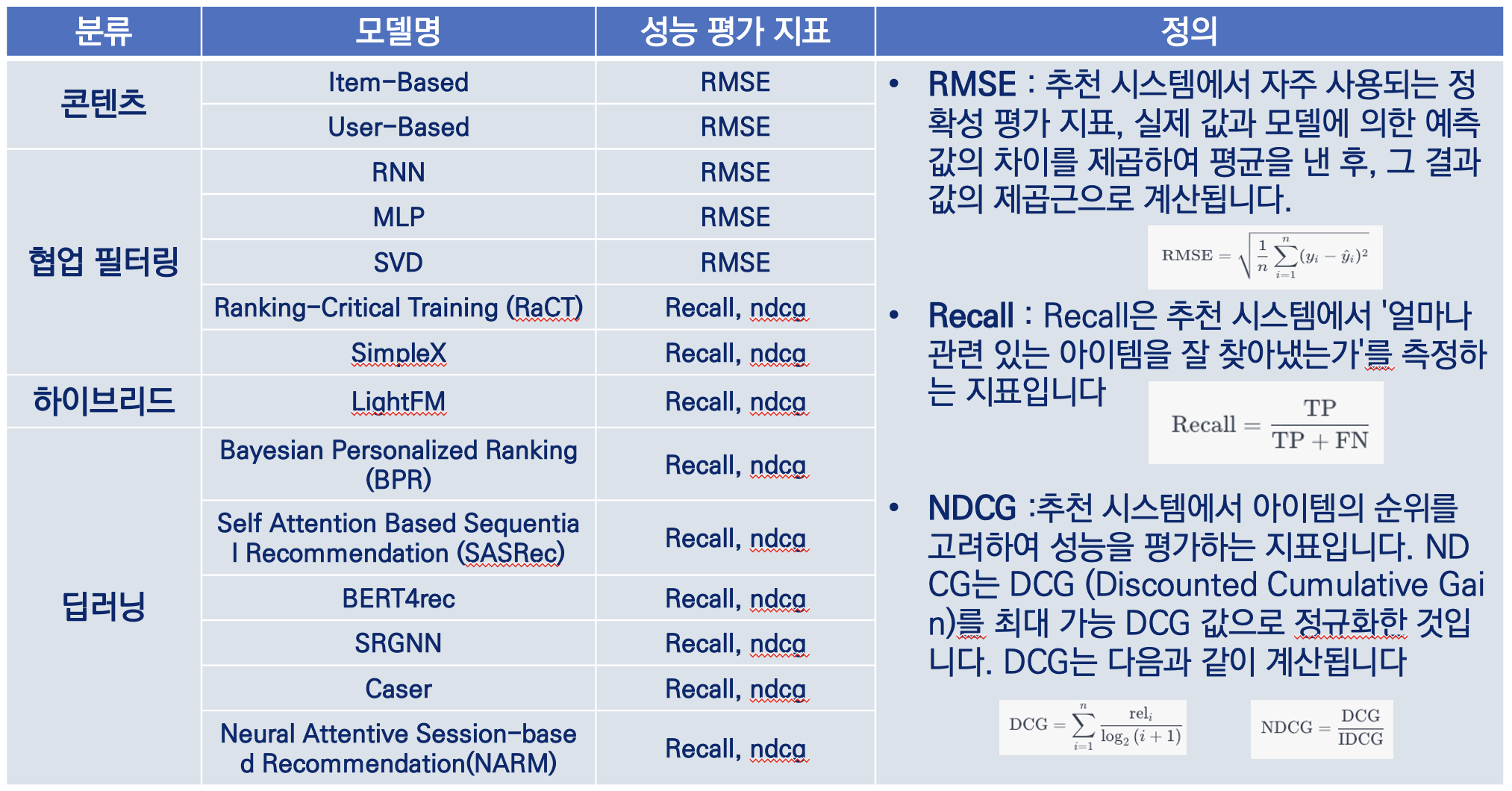
(2). 모델 작성
* LightFM
from surprise import SVD, Dataset, Reader, accuracy from surprise.model_selection import train_test_split from surprise.model_selection.search import GridSearchCV import pandas as pd import os import random class SVDRecommender(): """ Singular Value Decomposition (SVD) based collaborative filtering recommendation model. """ def __init__(self, path=None): self.load_model(path) def predict(self, user_id, top=10): """ Recommend movies based on the given user ID. Args: user_id (int): Target user ID for recommendation. top (int): Number of top recommended movies to return. Returns: list: List of top recommended movie IDs. """ if self.model is None: raise Exception("Model not loaded or trained.") ratings = pd.read_csv('./datasets/ratings.dat', sep='::', header=None, engine='python', names=['userId', 'movieId', 'rating', 'timestamp']) user_ratings = ratings[ratings['userId'] == user_id] other_movies = ratings[~ratings['movieId'].isin(user_ratings['movieId'])]['movieId'].unique() predictions = [(movie_id, self.model.predict(user_id, movie_id).est) for movie_id in other_movies] top_movies = sorted(predictions, key=lambda x: x[1], reverse=True)[:top] return [movie[0] for movie in top_movies] def save_model(self, model_path): """ Save the trained model to the specified path. Args: model_path (str): Path to save the trained model. """ from surprise.dump import dump dump(model_path, algo=self.model) def load_model(self, model_path): """ Load the pre-trained model from the specified path. Args: model_path (str): Path to the pre-trained model. """ if os.path.exists(model_path): from surprise.dump import load _, self.model = load(model_path) else: raise Exception(f"Model file not found: {model_path}") def train(ratings_path, e = [5, 10, 15, 20], lr = [0.001, 0.002, 0.005, 0.01]): """ Train the SVD model and save it to the specified path. Args: ratings_path (str): Path to the ratings.dat file. model_path (str): Path to save the trained model. """ ratings = pd.read_csv(ratings_path, sep='::', header=None, engine='python', names=['userId', 'movieId', 'rating', 'timestamp']) reader = Reader(rating_scale=(1, 5)) dataset = Dataset.load_from_df(ratings[['userId', 'movieId', 'rating']], reader) # Split the dataset into trainset and testset trainset, testset = train_test_split(dataset, test_size=0.2) # 80% for training, 20% for testing # Convert trainset back to DataFrame trainset_df = pd.DataFrame(trainset.all_ratings(), columns=["userId", "movieId", "rating"]) trainset_df['userId'] = trainset_df['userId'].apply(lambda x: trainset.to_raw_uid(x)) trainset_df['movieId'] = trainset_df['movieId'].apply(lambda x: trainset.to_raw_iid(x)) # Convert the DataFrame back to Dataset train_dataset = Dataset.load_from_df(trainset_df, reader) # Select your best algo with grid search. print('Grid Search...') param_grid = {'n_epochs': e, 'lr_all': lr} grid_search = GridSearchCV(SVD, param_grid, measures=['RMSE']) grid_search.fit(train_dataset) # Convert Trainset back to Dataset before passing print(grid_search.best_params) print(grid_search.best_score) # Getting the best model from grid search best_svd = grid_search.best_estimator['rmse'] # Training the model on the full dataset trainset = dataset.build_full_trainset() best_svd.fit(trainset) # Making predictions and evaluating on the testset using the best model testset = trainset.build_anti_testset() predictions = best_svd.test(testset) rmse_val = accuracy.rmse(predictions) print(f"RMSE: {rmse_val}") #모델 저장 print("---Saving model---") if best_svd is not None: from surprise.dump import dump dump('./models/svd.h5', algo=best_svd) print('Save Complete.')
* Recbole 라이브러리를 활용한 Bert
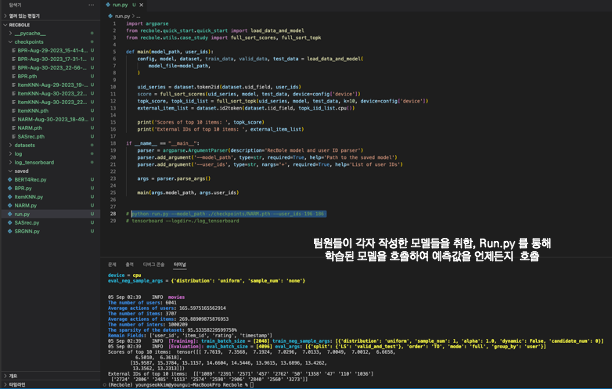
import sys from pathlib import Path import os import argparse from joblib import dump, load from recbole.config import Config from recbole.utils.enum_type import ModelType from recbole.model.general_recommender.ract import RaCT from recbole.trainer import RaCTTrainer from recbole.trainer import Trainer from recbole.data import create_dataset, data_preparation from recbole.quick_start import load_data_and_model from recbole.utils.case_study import full_sort_topk FILE = Path(__file__).resolve() ROOT = FILE.parents[0] print(ROOT) if str(ROOT) not in sys.path: sys.path.append(str(ROOT)) # add ROOT to PATH from utils import format_for_recbole, model_pth_handler def _Relative_Path(): base_path = Path(os.getcwd()) current_file_path = Path(FILE.parents[0]) return current_file_path.relative_to(base_path) def parse_opt(): parser = argparse.ArgumentParser() parser.add_argument('-t', '--train', action='store_true') parser.add_argument('-e', '--epochs',type=int, default=0) parser.add_argument('-u', '--user', type=int, default=1) parser.add_argument('-n', '--num', type=int, default=5) args = parser.parse_args() return args def _Config(parents_path=_Relative_Path(), data_path='datasets', dataset='movies', checkpoint_dir= 'saved', epochs=10): config_dict = { 'data_path': os.path.join(parents_path, data_path), # config 'checkpoint_dir': os.path.join(parents_path, checkpoint_dir), # Config 'dataset': dataset, # Config 'model': 'RaCT', # create_dataset, Config 'MODEL_TYPE': ModelType.GENERAL, # create_dataset 'learning_rate': 0.001, # Config 'train_batch_size': 128, # training 'eval_batch_size': 128, # training 'epochs': epochs, # training 'topk': 10, # training 'USER_ID_FIELD': 'userId', # dataset config 'ITEM_ID_FIELD': 'movieId', # dataset config 'RATING_FIELD': 'rating', # dataset config 'TIME_FIELD': 'timestamp', # dataset config 'NEG_PREFIX': 'neg_', # dataset config 'load_col': { # dataset config 'user': ['userId', 'gender', 'age', 'Occupation', 'zip_code'], 'inter': ['userId', 'movieId', 'rating', 'timestamp'], 'item': ['movieId', 'title', 'genres'], }, 'saved': True, 'verbose': True, # fit 'show_progress': True, # fit, fit 'state': 'INFO', 'tensorboard': True, } return config_dict def recbole_feature_engineering(config_dict=_Config()): ratings_df = format_for_recbole.load_ratings_for_recbole(config_dict['data_path']) movies_df = format_for_recbole.load_movies_for_recbole(config_dict['data_path']) users_df = format_for_recbole.load_users_for_recbole(config_dict['data_path']) ratings_df.to_csv(os.path.join(config_dict['data_path'], config_dict['dataset'], 'movies.inter'), index=False, sep='\t') movies_df.to_csv(os.path.join(config_dict['data_path'], config_dict['dataset'], 'movies.item'), index=False, sep='\t') users_df.to_csv(os.path.join(config_dict['data_path'], config_dict['dataset'], 'movies.user'), index=False, sep='\t') return ratings_df, movies_df, users_df class RaCT_Model: def __init__(self, train=True): self.config_dict = _Config(checkpoint_dir= 'saved') if not train: print("init train False") file_paths = model_pth_handler.find_saved_model(model_name=self.config_dict['model'], load_pth_dir_path=self.config_dict["checkpoint_dir"] ) self.file_model_file_name = file_paths[-1] print(self.config_dict["checkpoint_dir"]) print(f"사용할 saved 파일(모델) 경로: {self.file_model_file_name}") self.config, self.model, self.dataset, self.train_data, self.valid_data, self.test_data = load_data_and_model( model_file=os.path.join(self.config_dict["checkpoint_dir"], self.file_model_file_name), ) else: print("init train True") def train(self, epochs=20, del_model=False): print("---RaCT Model Training...---") self.config_dict['epochs'] = epochs self.config = Config(config_dict=self.config_dict) if del_model: model_pth_handler.delete_saved_model(model_name=self.config_dict['model'], saved_pth_dir_path=self.config_dict["checkpoint_dir"] ) self.dataset = create_dataset(self.config) self.train_data, self.valid_data, self.test_data = data_preparation(self.config, self.dataset) self.model = RaCT(self.config, self.dataset) if epochs: self.trainer = Trainer(self.config, self.model) else: self.trainer = RaCTTrainer(self.config, self.model) self.trainer.fit(self.train_data, self.valid_data, saved=self.config['saved'], verbose=self.config['verbose'], show_progress=self.config['show_progress'], ) print("---RaCT Model and Dataset Training Complete---") def evaluate(self): test_result = self.trainer.evaluate(self.test_data) print(f"test_data 평가 점수\n{test_result}") def predict(self, user_id=1, n=5): uid_series = self.dataset.token2id(self.dataset.uid_field, [str(user_id)]) _, topk_iid_list = full_sort_topk(uid_series, self.model, self.test_data, k=n, device=self.config['device']) external_item_list = self.dataset.id2token(self.dataset.iid_field, topk_iid_list.cpu()) return list(external_item_list[0]) if __name__ == '__main__': args = parse_opt() if args.train: print("args.train True") relative_path = _Relative_Path() # 작업 디렉토리 print(f"작업 경로{relative_path}") ract = RaCT_Model() ract.train(epochs=args.epochs, del_model=True, ) ract.evaluate() print(ract.predict()) elif args.user: print("args.train False, args.user True") config_dict = _Config() print(config_dict) ract = RaCT_Model(train=False) print(ract.predict(user_id=args.user, n=args.num)) else: print("fail")(2). 모델 성능 결과
모델 시연 결과를 확인해본 결과
콘텐츠, 협업필터링중 SVD가 rmse 값이 제일 작아 예측정확도가 높으며
하이브리드, 딥러닝 모델중에서는 RaCT 모델이 recall, ndcg 지표가 우수했습니다.
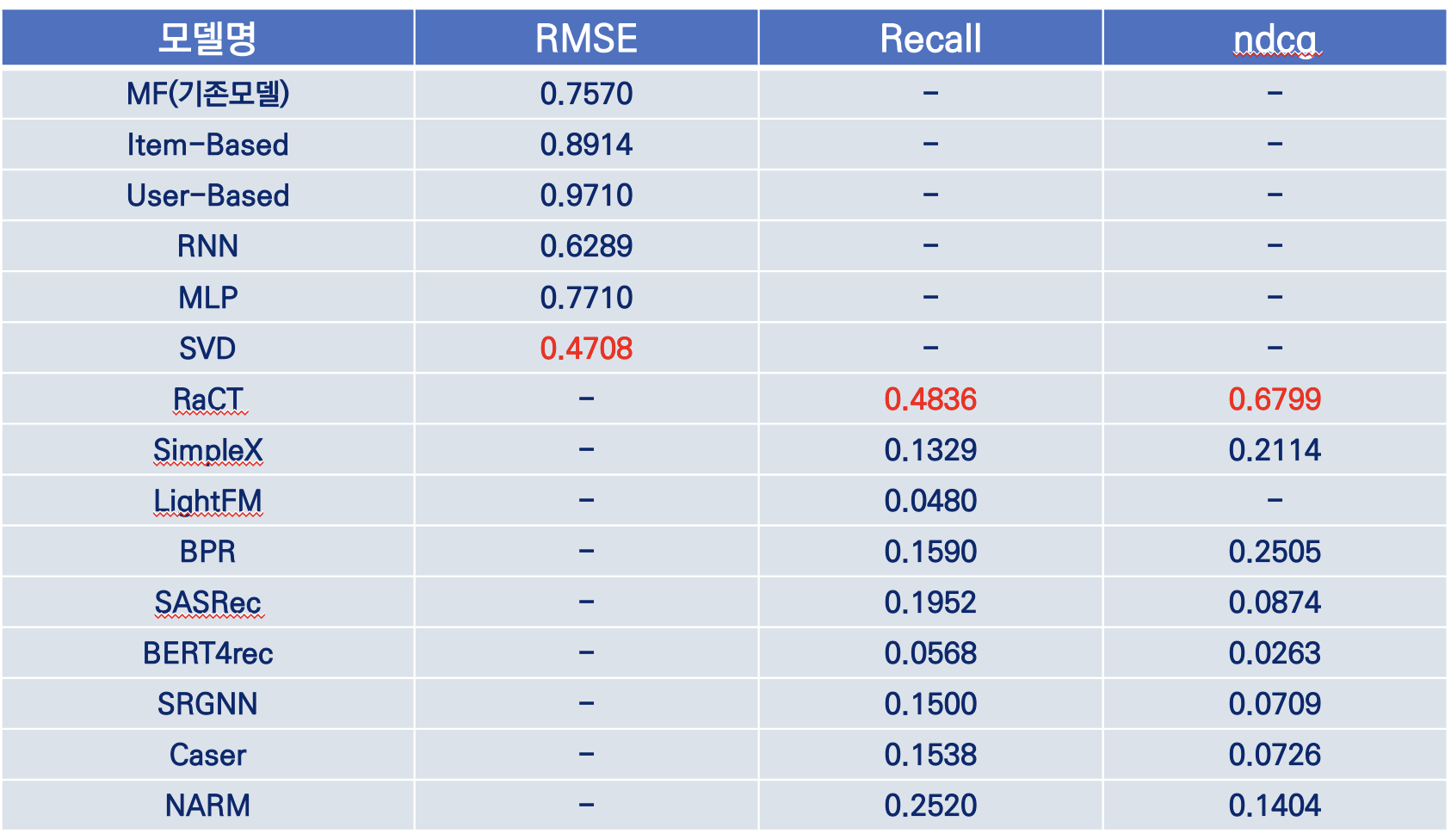
4. 최종 모델 선정
(1). 콘텐츠/협업 필터링 최종모델 - SVD 모델
- SVD 모델이 RMSE 값이 가장 적어 예측 오차를 최소화 한다고 예측된다.
- 원본 데이터의 차원이 축소하여 중요한 특성만 캡쳐했기에 모델의 중요한 패턴을 더 잘 학습한 것으로 판단 했습니다.
- SVD는 희소 행렬에 대한 정보를 효과적으로 압축, 복원할 수 있다는 점이 좋은 결과를 냈다고 판단 했습니다.
(2). 딥러닝 기반 최종모델 - RaCT
- RaCT 모델은 Actor-Critic Reinforcement Learning을 통해 랭킹에 중점을 둔 모델 학습을 진행합니다.
- 랭킹 시스템에서 사용하는 러닝 투 랭크(LTR; Learning to Rank) 방법과는 다르게, 새로운 목록(List)에 대해 최적화 과정을
다시 실행할 필요 없이 신경망을 통해 점수를 빠르게 예측하여 반환할 수 있습니다. - 아래는 Variational Autoencoder와 비교한 그래프 입니다.
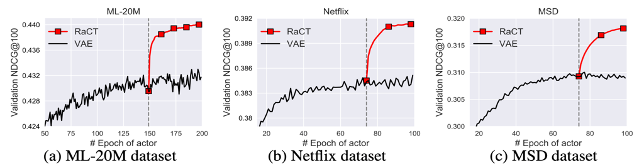
SVD, RaCT 두 모델 모두 고객 만족도를 높이는 데 크게 기여할 것으로 예상되며, 특히 RaCT 모델은 랭킹 시스템에서 뛰어난 성능을 보여 주었습니다.
개선된 모델을 통해 고객만족도 증가, 고객 이탈율 감소에 기여할 것으로 판단됩니다.
추가적으로 T사의 영화 추천 서비스는 선정된 모델들을 실제 서비스에 적용하고 피드백 로직을 구현하는 작업을 진행할 수 있습니다.
5. 피드백 로직 구현
피드백 로직은 추천 시스템에서 중요한 요소 중 하나입니다. 이는 사용자로부터 얻은 반응이나 평가를 모델에 적용하여 더 정확한 추천을 가능하게 하는 메커니즘입니다. 일반적으로 피드백 로직에는 다음과 같은 두 가지 주요 유형이 있습니다
-
명시적 피드백 (Explicit Feedback)
사용자가 직접 추천 받은 아이템에 대한 평점이나 리뷰를 제공하는 방식입니다.
예를 들어, 5점 만점에 4점을 준다거나 "이 영화가 좋았다"와 같은 코멘트를 남깁니다. -
암시적 피드백 (Implicit Feedback)
사용자의 행동을 분석하여 암묵적으로 피드백을 얻는 방식입니다.
예를 들어, 어떤 영화를 재생하고 중간에 멈춘다거나, 다른 관련 영화를 찾아보는 등의 행동입니다.
구체적인 로직 구현은
- 데이터 수집: 사용자로부터 명시적 또는 암시적 피드백을 수집합니다.
- 데이터 전처리: 수집된 데이터를 모델이 학습할 수 있는 형태로 변환합니다.
- 모델 업데이트: 피드백 데이터를 이용하여 추천 모델을 업데이트합니다.
- 성능 평가: 업데이트된 모델의 성능을 측정하고 필요한 경우 추가 튜닝을 진행합니다.
위의 과정 대로 피드백 로직은 사용자의 반응과 평가를 실시간으로 모델에 반영하여 추천의 정확도를 높입니다.
명시적 피드백은 사용자가 직접 평점이나 리뷰를 제공하는 방식이고, 암시적 피드백은 사용자의 행동을 분석하여 얻습니다.
이렇게 수집된 피드백은 추천 모델을 지속적으로 개선하는 데 사용 될 수 있으며 사용자의 새로운 니즈를 만족시키는데 도움을 줄 수 있습니다.
프로젝트 회고
개인별 회고

전체 회고
Git을 이용한 협업 프로세스
Discord를 이용한 협업 프로세스
추천 모델 구성을 위한 파이썬 모듈 구조화 방식 경험 습득