스파크 / 로컬
스파크 로컬 개요
단일 노드(CPU)에서 Spark 애플리케이션 실행하는 형태다. 클러스터 설정 없이 간편하게 Spark 사용 가능하고
테스트, 디버깅, 개발 목적에 최적화되어 있다.
spark-shell --master local[*]- local[*] → CPU 코어 수만큼 쓰레드 실행
- local[1] → 단일 쓰레드 실행
Spark Local 모드 사용 시점
| 사용 사례 | 비고 |
|---|---|
| 개발 및 테스트 | 매우 적합 |
| 소규모 데이터 분석 | 가능 |
| 디버깅 및 코드 최적화 | 적합 |
| 대용량 데이터 처리 | 클러스터 필요 |
| 실시간 스트리밍 | 클러스터 권장 |
설치
JDK
sudo apt install openjdk-11-jdk
vagrant@slave2:/opt/spark$ java -version
openjdk version "11.0.26" 2025-01-21
OpenJDK Runtime Environment (build 11.0.26+4-post-Ubuntu-1ubuntu120.04)
OpenJDK 64-Bit Server VM (build 11.0.26+4-post-Ubuntu-1ubuntu120.04, mixed mode, sharing)Spark
다운로드
wget https://dlcdn.apache.org/spark/spark-3.5.5/spark-3.5.5-bin-hadoop3.tgz
tar -xvf spark-3.5.5-bin-hadoop3.tgz
cd spark-3.5.5-bin-hadoop3환경 설정
export SPARK_HOME=$(pwd)
export PATH=$SPARK_HOME/bin:$PATH
export PATH=$SPARK_HOME/sbin:$PATH버전 확인
vagrant@slave4:~/spark-3.5.5-bin-hadoop3$ spark-shell --version
25/03/16 03:35:37 WARN Utils: Your hostname, slave4 resolves to a loopback address: 127.0.2.1; using 10.0.2.15 instead (on interface eth0)
25/03/16 03:35:37 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.5.5
/_/
Using Scala version 2.12.18, OpenJDK 64-Bit Server VM, 11.0.26
Branch HEAD
Compiled by user ubuntu on 2025-02-23T20:30:46Z
Revision 7c29c664cdc9321205a98a14858aaf8daaa19db2
Url https://github.com/apache/spark
Type --help for more information.실행
마스터 실행
자신의 IP 를 정확히 지정해 주는 것이 중요하다.
vagrant@slave4:~/spark-3.5.5-bin-hadoop3$ start-master.sh --host 192.168.56.104 --port 7077
starting org.apache.spark.deploy.master.Master, logging to /home/vagrant/spark-3.5.5-bin-hadoop3/logs/spark-vagrant-org.apache.spark.deploy.master.Master-1-slave4.out마스터가 구동되면 기본 포트인 8080로 접속하여 웹UI를 볼 수 있다.
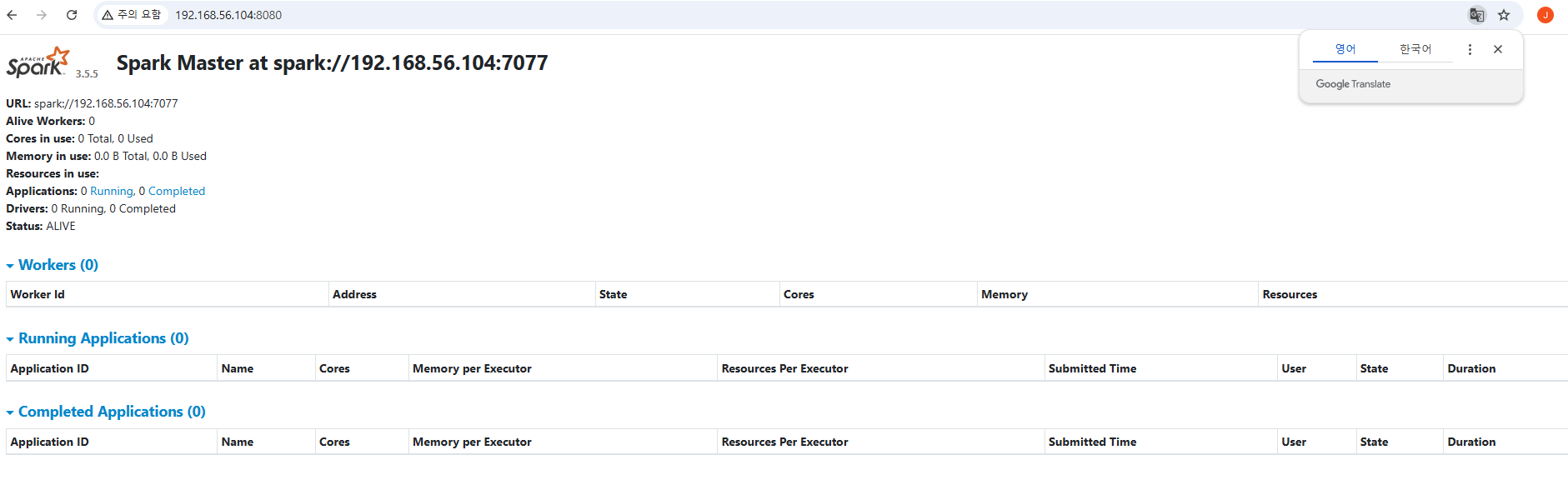
워커 실행
워크를 실행하여 마스터의 Workers 목록에 추가되었는지 확인한다.
vagrant@slave4:~/spark-3.5.5-bin-hadoop3$ start-worker.sh spark://192.168.56.104:7077
starting org.apache.spark.deploy.worker.Worker, logging to /home/vagrant/spark-3.5.5-bin-hadoop3/logs/spark-vagrant-org.apache.spark.deploy.worker.Worker-1-slave4.out워커

활용
예제 실행
spark-shell에 접속해서 대화식으로 스칼라 언어를 이용해 결과가 나오는 지 확인한다. 아래 방법으로1부터 1000까지의 합을 구한다.
vagrant@slave4:~/spark-3.5.5-bin-hadoop3$ spark-shell
25/03/16 03:51:45 WARN Utils: Your hostname, slave4 resolves to a loopback address: 127.0.2.1; using 10.0.2.15 instead (on interface eth0)
25/03/16 03:51:45 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
25/03/16 03:51:54 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://10.0.2.15:4040
Spark context available as 'sc' (master = local[*], app id = local-1742097115538).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.5.5
/_/
Using Scala version 2.12.18 (OpenJDK 64-Bit Server VM, Java 11.0.26)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val rdd = sc.parallelize(1 to 1000)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:23
scala> rdd.sum()
res0: Double = 500500.0프로세스 확인
jps(Java Process Status)는 JVM(Java Virtual Machine)에서 실행 중인 Java 프로세스를 확인하는 명령어이다. Spark, Hadoop 등 Java 기반 애플리케이션이 실행 중인지 확인하는 데 사용된다. Spark Master, Worker가 정상적으로 실행 중인지 확인할 때, Executor 프로세스가 제대로 생성되었는지 체크할 때, Spark이 비정상적으로 종료된 경우 남아 있는 프로세스를 찾을 때 사용한다.
vagrant@slave4:~/spark-3.5.5-bin-hadoop3$ jps
28800 Jps
28388 Worker
27273 Master로그 확인
vagrant@slave4:~/spark-3.5.5-bin-hadoop3$ cat /home/vagrant/spark-3.5.5-bin-hadoop3/logs/spark-vagrant-org.apache.spark.deploy.worker.Worker-1-slave4.out포트 확인
7077 이 이미 바운드되어 있다는 오류를 많이 만날 것이다. 포트는 다음과 같은 방법으로 확인할 수 있다. 해당 포트를 사용하고 있는 프로그램을 정리해 주어야 한다.
- sudo lsof -i :7077
- netstat -tulnp | grep 7077
- ps -ef 로 7077 사용중인지 확인
- (윈도즈) netstat -ano | findstr 7077

khagor