Spark / 클러스터
클러스터 모드 장점
확장성 (Scalability)
- 여러 노드를 추가하여 데이터 처리 성능을 높일 수 있음
- Local 모드는 한 개의 머신의 CPU와 메모리만 사용하지만, 클러스터 모드는 수십~수백 대의 노드가 협업하여 작업을 수행
높은 성능
- 클러스터 모드는 데이터를 분산 저장하고 병렬 처리하여 성능이 뛰어남
- Local 모드는 단일 머신 성능에 제한됨, 데이터 크기가 커질수록 병목 현상 발생
- 클러스터 모드는 노드가 많을수록 성능 향상 가능
장애 복구 및 안정성
- Local 모드는 하드웨어 장애 발생 시 작업이 중단됨
- 클러스터 모드는 노드 장애 발생 시 다른 노드에서 자동으로 작업을 재시도
대용량 데이터 처리
- Local 모드는 메모리(RAM) 한계로 인해 수십~수백 GB 이상의 데이터 처리 어려움
- 클러스터 모드는 TB~PB 단위의 데이터도 분산 저장 및 병렬 처리 가능
다양한 리소스 관리자 지원
- Spark 클러스터 모드는 다양한 리소스 관리 시스템과 연동 가능
- YARN: Hadoop과 함께 사용
- Kubernetes: 컨테이너 기반 Spark 운영
- Standalone: 독립 실행 Spark 클러스터
클러스터 모드와 로컬 모드 비교
| 특징 | Local 모드 (local[*]) | 클러스터 모드 (Standalone / YARN / Kubernetes 등) |
|---|---|---|
| 병렬 처리 | 단일 머신의 CPU 코어만 사용 | 여러 노드의 리소스를 활용 가능 |
| 확장성 | 노드 추가 불가능 | 노드 추가 가능 (수평 확장) |
| 성능 | 단일 머신 성능에 제한됨 | 분산 컴퓨팅으로 대용량 데이터 처리 가능 |
| 장애 복구 | 단일 머신 장애 시 작업 중단 | 클러스터에서 실패한 작업 자동 재시도 |
| 리소스 관리 | 단일 머신의 CPU/RAM만 사용 | YARN, Kubernetes, Mesos 등으로 리소스 최적화 |
| 실제 운영 가능 여부 | 주로 테스트 및 개발용 | 대규모 데이터 처리 및 운영 환경에서 사용 가능 |
| 스토리지 | 로컬 파일 또는 HDFS 사용 가능 | HDFS, S3, HBase, Iceberg 등 다양한 스토리지 활용 가능 |
설치
아래처럼 스파크 차트를 그대로 사용하는 것이 가능하지만 필요한 속성의 커스터마이징을 위해 차트를 내려받은 후 설치한다.
helm -n spark install spark-chart oci://registry-1.docker.io/bitnamicharts/spark --create-namespace차트 내려 받기
이미 설치한 차트가 있으면 삭제 한후 차트를 내려 받는다.
helm -n spark delete spark-chart oci://registry-1.docker.io/bitnamicharts/spark
helm pull oci://registry-1.docker.io/bitnamicharts/spark --untar속성변경
사용할 차트의 속성을 변경한다.
편의를 위해 ingress 없이 node port 로 웹콘솔에 접근하기위해 아래와 같이 value 파일을 생성한다. 노드 포트도 3000으로 직접 지정했다.
- value 파일 생성
myval.yml
service:
type: NodePort
nodePorts:
http: 30000이미 설치된 버전은 제거한다.
helm delete spark -n spark생성한 values 파일을 이용해 스파크를 설치한다.
helm -n spark install spark spark --create-namespace -f myval.yml
vagrant@master:~$ kubectl -n spark get pod -w
NAME READY STATUS RESTARTS AGE
spark-chart-master-0 1/1 Running 0 90s
spark-chart-worker-0 1/1 Running 0 90s
spark-chart-worker-1 1/1 Running 0 49s웹콘솔 접속
vagrant@slave4:~$ k get svc -n spark
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
spark-headless ClusterIP None <none> <none> 13s
spark-master-svc NodePort 10.100.85.30 <none> 7077:32597/TCP,80:30000/TCP 13s노드 포트를 통해 웹 콘솔 확인이 가능하다.
Spark / 클러스터
설치
아래처럼 스파크 차트를 그대로 사용하는 것이 가능하지만 필요한 속성의 커스터마이징을 위해 차트를 내려받은 후 설치한다.
helm -n spark install spark-chart oci://registry-1.docker.io/bitnamicharts/spark --create-namespace차트 내려 받기
이미 설치한 차트가 있으면 삭제 한후 차트를 내려 받는다.
helm -n spark delete spark-chart oci://registry-1.docker.io/bitnamicharts/spark
helm pull oci://registry-1.docker.io/bitnamicharts/spark --untar속성변경
사용할 차트의 속성을 변경한다.
편의를 위해 ingress 없이 node port 로 웹콘솔에 접근하기위해 아래와 같이 value 파일을 생성한다. 노드 포트도 3000으로 직접 지정했다.
- value 파일 생성
myval.yml
service:
type: NodePort
nodePorts:
http: 30000이미 설치된 버전은 제거한다.
helm delete spark -n spark생성한 values 파일을 이용해 스파크를 설치한다.
helm -n spark install spark spark --create-namespace -f myval.yml
vagrant@master:~$ kubectl -n spark get pod -w
NAME READY STATUS RESTARTS AGE
spark-chart-master-0 1/1 Running 0 90s
spark-chart-worker-0 1/1 Running 0 90s
spark-chart-worker-1 1/1 Running 0 49s웹콘솔 접속
vagrant@slave4:~$ k get svc -n spark
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
spark-headless ClusterIP None <none> <none> 13s
spark-master-svc NodePort 10.100.85.30 <none> 7077:32597/TCP,80:30000/TCP 13s노드 포트를 통해 웹 콘솔 확인이 가능하다.
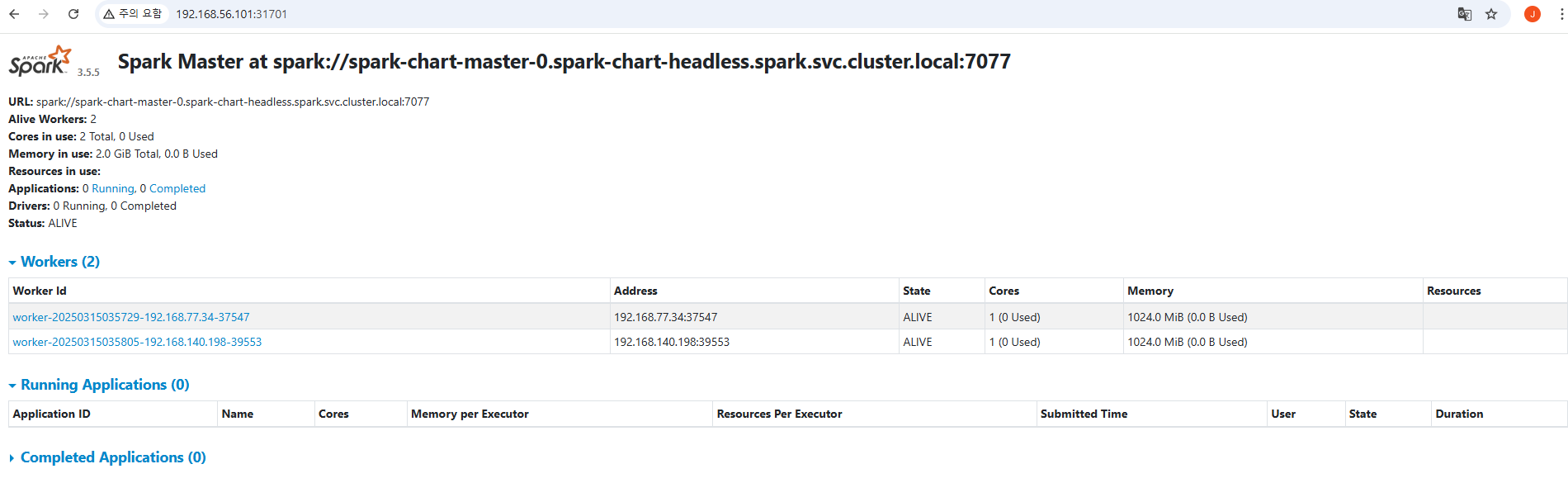
마스터 접속 URL이 다음 처럼 DNS 형태로 구성되었다.
URL: spark://spark-chart-master-0.spark-chart-headless.spark.svc.cluster.local:7077삭제는 다음과 같이 한다.
helm -n spark delete sparkspark-shell 접속
vagrant@slave4:~$ k exec -it spark-master-0 -n spark -- spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
25/03/16 04:26:53 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://spark-master-0.spark-headless.spark.svc.cluster.local:4040
Spark context available as 'sc' (master = local[*], app id = local-1742099215989).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.5.5
/_/
Using Scala version 2.12.18 (OpenJDK 64-Bit Server VM, Java 17.0.14)
Type in expressions to have them evaluated.
Type :help for more information.
scala>예제 실행
spark-submit --class org.apache.spark.examples.SparkPi \
--master local[*] \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.5.5.jar 10응용
이미지 다운로드
차트에서 사용하는 이미지는 설치한 시점 이후 버전이 바뀔 수 있으므로 이미지를 내려받아 로컬 이미지 저장소에 PUSH 한다.
vagrant@slave4:~$ sudo docker pull bitnami/spark:3.5.5-debian-12-r0
3.5.5-debian-12-r0: Pulling from bitnami/spark
5816f308486f: Pull complete
Digest: sha256:e84e48237191af203dfe1975bce555b0e1482cdd9e68128ee752bad6ac1aefa8
Status: Downloaded newer image for bitnami/spark:3.5.5-debian-12-r0
docker.io/bitnami/spark:3.5.5-debian-12-r0
vagrant@slave4:~$ sudo docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
bitnami/spark 3.5.5-debian-12-r0 6ef00abe10af 2 weeks ago 1.34GBdocker login -u {저장소아이디}
sudo docker tag bitnami/spark:3.5.5-debian-12-r0 {저장소아이디}/spark:3.5.5-debian-12-r0
sudo docker push {저장소아이디}/spark:3.5.5-debian-12-r0(테스트) 이미지를 사용하여 spark-shell 접속
vagrant@slave2:/opt/spark/bin$ kubectl run spark-shell --rm -it --image=spark:3.5.5-scala2.12-java11-ubuntu -- bash
If you don't see a command prompt, try pressing enter.
spark@spark-shell:/opt/spark/work-dir$
spark@spark-shell:/opt/spark/work-dir$ /opt/spark/bin/spark-submit --version
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.5.5
/_/
Using Scala version 2.12.18, OpenJDK 64-Bit Server VM, 11.0.26
Branch HEAD
Compiled by user ubuntu on 2025-02-23T20:30:46Z
Revision 7c29c664cdc9321205a98a14858aaf8daaa19db2
Url https://github.com/apache/spark
Type --help for more information.spark-shell
hello world
scala> spark
res0: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@3ecbfcfb
scala> val data = Seq((1, "Alice"), (2, "Bob"), (3, "Charlie"))
data: Seq[(Int, String)] = List((1,Alice), (2,Bob), (3,Charlie))
scala> val df = spark.createDataFrame(data).toDF("id", "name")
df: org.apache.spark.sql.DataFrame = [id: int, name: string]
scala> df.show()
+---+-------+
| id| name|
+---+-------+
| 1| Alice|
| 2| Bob|
| 3|Charlie|
+---+-------+RDD
scala> val rdd = spark.sparkContext.parallelize(1 to 10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:22
scala> val sum = rdd.reduce(_ + _)
sum: Int = 55
scala> println(s"Sum: $sum")
Sum: 55Spark SQL
scala> val df = spark.createDataFrame(Seq(
(1, "Alice", 23),
(2, "Bob", 25),
(3, "Charlie", 30)
)).toDF("id", "name", "age") | | | |
df: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> df.createOrReplaceTempView("people")
scala> val result = spark.sql("SELECT * FROM people WHERE age > 24")
result: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> result.show()
+---+-------+---+
| id| name|age|
+---+-------+---+
| 2| Bob| 25|
| 3|Charlie| 30|
+---+-------+---+실행 옵션
// 멀티 코어 지정
spark-shell --master local[*]
// 메모리 제한
spark-shell --driver-memory 4G마스터 접속 URL이 다음 처럼 DNS 형태로 구성되었다.
URL: spark://spark-chart-master-0.spark-chart-headless.spark.svc.cluster.local:7077삭제는 다음과 같이 한다.
helm -n spark delete sparkspark-shell 접속
vagrant@slave4:~$ k exec -it spark-master-0 -n spark -- spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
25/03/16 04:26:53 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://spark-master-0.spark-headless.spark.svc.cluster.local:4040
Spark context available as 'sc' (master = local[*], app id = local-1742099215989).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.5.5
/_/
Using Scala version 2.12.18 (OpenJDK 64-Bit Server VM, Java 17.0.14)
Type in expressions to have them evaluated.
Type :help for more information.
scala>예제 실행
spark-submit --class org.apache.spark.examples.SparkPi \
--master local[*] \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.5.5.jar 10응용
이미지 다운로드
차트에서 사용하는 이미지는 설치한 시점 이후 버전이 바뀔 수 있으므로 이미지를 내려받아 로컬 이미지 저장소에 PUSH 한다.
vagrant@slave4:~$ sudo docker pull bitnami/spark:3.5.5-debian-12-r0
3.5.5-debian-12-r0: Pulling from bitnami/spark
5816f308486f: Pull complete
Digest: sha256:e84e48237191af203dfe1975bce555b0e1482cdd9e68128ee752bad6ac1aefa8
Status: Downloaded newer image for bitnami/spark:3.5.5-debian-12-r0
docker.io/bitnami/spark:3.5.5-debian-12-r0
vagrant@slave4:~$ sudo docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
bitnami/spark 3.5.5-debian-12-r0 6ef00abe10af 2 weeks ago 1.34GBdocker login -u {저장소아이디}
sudo docker tag bitnami/spark:3.5.5-debian-12-r0 {저장소아이디}/spark:3.5.5-debian-12-r0
sudo docker push {저장소아이디}/spark:3.5.5-debian-12-r0(테스트) 이미지를 사용하여 spark-shell 접속
vagrant@slave2:/opt/spark/bin$ kubectl run spark-shell --rm -it --image=spark:3.5.5-scala2.12-java11-ubuntu -- bash
If you don't see a command prompt, try pressing enter.
spark@spark-shell:/opt/spark/work-dir$
spark@spark-shell:/opt/spark/work-dir$ /opt/spark/bin/spark-submit --version
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.5.5
/_/
Using Scala version 2.12.18, OpenJDK 64-Bit Server VM, 11.0.26
Branch HEAD
Compiled by user ubuntu on 2025-02-23T20:30:46Z
Revision 7c29c664cdc9321205a98a14858aaf8daaa19db2
Url https://github.com/apache/spark
Type --help for more information.spark-shell
hello world
scala> spark
res0: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@3ecbfcfb
scala> val data = Seq((1, "Alice"), (2, "Bob"), (3, "Charlie"))
data: Seq[(Int, String)] = List((1,Alice), (2,Bob), (3,Charlie))
scala> val df = spark.createDataFrame(data).toDF("id", "name")
df: org.apache.spark.sql.DataFrame = [id: int, name: string]
scala> df.show()
+---+-------+
| id| name|
+---+-------+
| 1| Alice|
| 2| Bob|
| 3|Charlie|
+---+-------+RDD
scala> val rdd = spark.sparkContext.parallelize(1 to 10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:22
scala> val sum = rdd.reduce(_ + _)
sum: Int = 55
scala> println(s"Sum: $sum")
Sum: 55Spark SQL
scala> val df = spark.createDataFrame(Seq(
(1, "Alice", 23),
(2, "Bob", 25),
(3, "Charlie", 30)
)).toDF("id", "name", "age") | | | |
df: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> df.createOrReplaceTempView("people")
scala> val result = spark.sql("SELECT * FROM people WHERE age > 24")
result: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> result.show()
+---+-------+---+
| id| name|age|
+---+-------+---+
| 2| Bob| 25|
| 3|Charlie| 30|
+---+-------+---+실행 옵션
// 멀티 코어 지정
spark-shell --master local[*]
// 메모리 제한
spark-shell --driver-memory 4G