1. 파이토치(PyTorch)
1.1 PyTorch란?
딥러닝을 위한 오픈소스 머신러닝 프레임워크 by Meta(facebook)
- 너무나도 훌륭한 Document
- Pythonic한 문법과 동적 계산 그래프(Dynamic Computational Graph) 지원으로 직관적인 코드 작성이 가능
- PyTorch의 Tensor는 NumPy 배열과 매우 유사, GPU 연산을 지원
- GPU 연동을 통해 대규모 모델도 빠르게 학습할 수 있음
- 동적으로 back-propagation 경로 생성 가능
- pytorch.org/docs의 documnet를 적극 활용하자!
1.2 GPU 기본 개념 및 Colab에서 GPU 사용하기
GPU 기본 개념 및 Colab에서 GPU 사용하기 요약 정리 글
- PyTorch에서는 연산 대상이 되는 모든 텐서가 동일한 장치(device) 에 있어야 함!
- GPU도 여러 개가 있을 수 있는데, 동일한 장치에 있어야 함
| 기능 | 코드 예시 | 설명 |
|---|---|---|
| GPU 사용 가능 여부 확인 | torch.cuda.is_available() | GPU 사용 가능한 환경인지 확인 |
| 텐서를 GPU로 이동 | x.cuda() 또는 x.to('cuda') | CPU → GPU |
| 텐서를 CPU로 이동 | x.cpu() 또는 x.to('cpu') | GPU → CPU |
| 장치 확인 | x.device | 텐서의 현재 장치 정보 출력 |
| 장치 일치 필수 | x + y 연산 시 | x와 y는 동일 device에 있어야 함 |
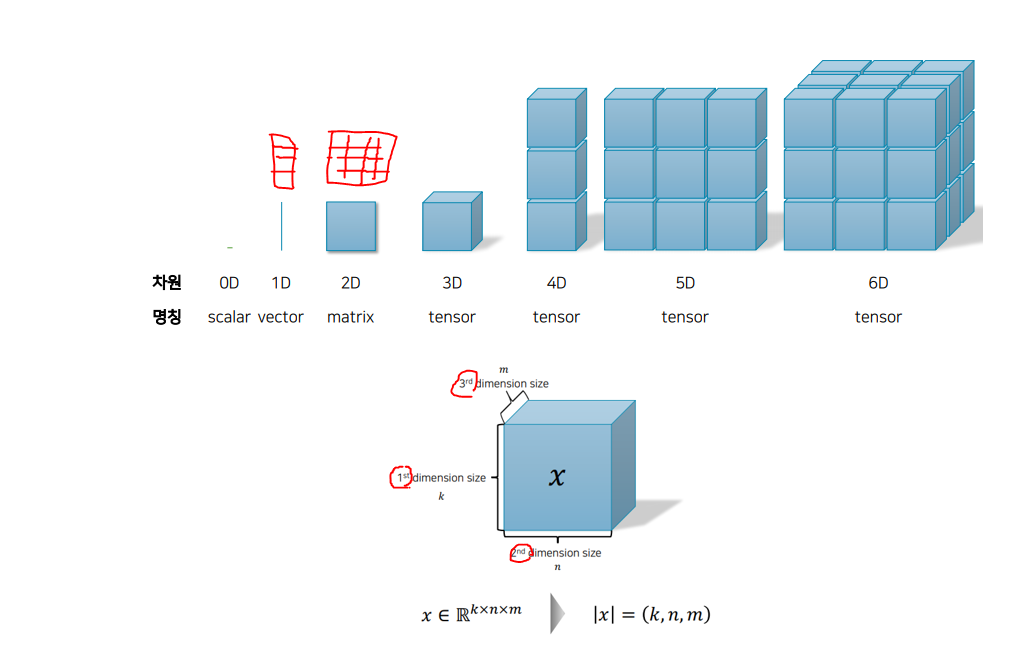
2. Tensor 속성 및 생성 방법
2.1 Tensor란?
다차원 배열의 자료구조
- 스칼라(0차원), 벡터(1차원), 행렬(2차원) 등 모든 수학적 데이터를 일반화한 구조
- PyTorch에서의 텐서(tensor)는 기능적으로 넘파이(NumPy)와 매우 유사
- GPU 연산(병렬 연산)이 가능하다는 점이 NumPy 배열과의 큰 차이점
- PyTorch에서는 텐서를 사용해 딥러닝 모델의 입력, 출력, 가중치 등을 표현
- PyTorch의 텐서는 자동 미분(autograd) 기능을 제공
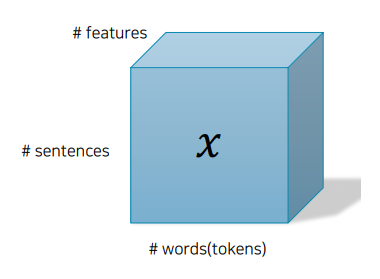
- 예시 1: 감정분석 데이터,
- |x| = (#s, #w, #f) / (#img, h, w)
- |xi| = (#w, #f) / (h, w)
- |xi,j| = (#f) / (w)
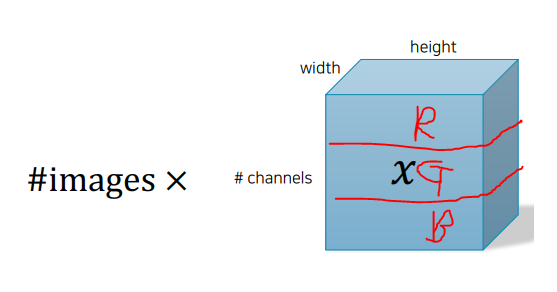
- 예시 2: 이미지 데이터(RGB) (4차원)
- |x| = (#img, #ch h, w)
- |xi| = (#ch, h, w) (한 장의 이미지, 3차원)
2.2 텐서의 속성
-
텐서의 기본 속성으로는 다음과 같은 것들이 있다.
- 모양 (shape)
- 데이터 형식 (data type)
- 저장된 장치 (device)
-
Pandas Dataframe과 매우 유사.
import torch
tensor = torch.rand(3, 4) # 3 by 4
print(tensor)
print(f"Shape: {tensor.shape}") # 차원 경우에는 가장 바깥 대괄호부터 세면 됨
print(f"Data type: {tensor.dtype}") # 기본적으로 float
print(f"Device: {tensor.device}") # 기본적으로 CPU
x = torch.FloatTensor([[[1, 2, 3],
[3, 4, 5]],
[[5, 6, 7],
[7, 8, 9]],
[[9, 10, 11],
[11, 12, 13]]])
print(x.shape) #torch.Size([3, 2, 3]) → 제일 큰 껍데기의 차원이 맨 앞으로
2.3 텐서 초기화
- 리스트 데이터에서 직접 텐서를 초기화할 수 있다.
data = [
[1, 2],
[3, 4]
]
x = torch.tensor(data)
print(x)
ft = torch.FloatTensor(data)
print(ft)
lt = torch.LongTensor(data)
print(lt)
bt = torch.ByteTensor(data) #0부터 255까지의 범위 → 메모리 사용량 절약
print(bt)
bool_tensor = torch.tensor([True, False, True, False], dtype=torch.bool)
print(bool_tesnor)
- NumPy 배열에서 텐서를 초기화할 수 있다.
a = torch.tensor([5])
b = torch.tensor([7])
c = (a + b).numpy()
print(c)
print(type(c))
result = c * 10
tensor = torch.from_numpy(result)
print(tensor)
print(type(tensor))2.4 다른 텐서로부터 텐서 초기화하기
- 다른 텐서의 정보를 토대로 텐서를 초기화할 수 있다.
- 속성: 모양(shape), 자료형(dtype) 등 복사 가능
x = torch.tensor([
[5, 7],
[1, 2]
])
# x와 같은 모양, 값이 0으로 채워진 텐서
x_zeros = torch.zeros_like(x)
print(x_zeros)
# x와 같은 모양, 값이 1인 텐서 생성
x_ones = torch.ones_like(x)
print(x_ones)
# x와 같은 모양, 초기화된 값은 무작위 (메모리 상태에 따라 달라짐)
x_empty = torch.empty_like(x)
print(x_empty)
# x와 같은 모양, 모든 값을 지정된 값(예: 42)으로 채움
x_full = torch.full_like(x, fill_value=42)
print(x_full)
# x와 같은 모양, 자료형은 float으로 변경하고 랜덤 값 생성
x_rand = torch.rand_like(x, dtype=torch.float32) # uniform distribution [0, 1)
print(x_rand)2.5 randperm: Random Permutation
x = torch.randperm(10)
print(x) # tensor([8, 1, 0, 5, 6, 4, 3, 7, 2, 9])3. 텐서의 형변환 및 차원 조작
- 텐서는 넘파이(NumPy) 배열처럼 조작할 수 있다.
- Pandas랑 굉장히 비슷
3.1 텐서 일부분 접근 (Indexing, slicing)
- 텐서의 원하는 차원에 접근할 수 있다.
- 파이썬, Pandas에서 사용하는 인덱싱, 슬라이싱 기법 그대로 사용 가능
tensor = torch.tensor([
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
])
print(tensor[0]) # 첫 번째 행, tensor[0], :)도 가능
print(tensor[:, 0]) # 첫 번째 열
print(tensor[..., -1]) # 마지막 열 ...(ellipsis, 생략)는 모든 앞 차원을 의미, PyTorch에서 고차원 배열을 다룰 때 자주 쓰이는 슬라이싱 문법
x = torch.FloatTensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]],
[[9, 10],
[11, 12]]])
print(x.size())
print(x[0])
print(x[0, :])
print(x[0, :, :])
print(x[1:3, :, :].size()) #indexing이 아니라 sliciing으로 하면 dimension reduction 발생 x
print(x[:, :1, :].size())
print(x[:, :-1, :].size())
3.2 텐서 자르기 (Split)
x = torch.FloatTensor(10, 4)
splits = x.split(4, dim=0)
for s in splits:
print(s.size())
# torch.Size([4, 4])
# torch.Size([4, 4])
# torch.Size([2, 4])
x = torch.FloatTensor(8, 4)
chunks = x.chunk(3, dim=0)
for c in chunks:
print(c.size())
# torch.Size([3, 4])
# torch.Size([3, 4])
# torch.Size([2, 4]) 3.3 텐서 이어붙이기 (Concatenate)
- 두 텐서를 이어 붙여 연결하여 새로운 텐서를 만들 수 있다.
- pandas의 concat과 유사 (axis ≈ dim)
tensor = torch.tensor([
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
])
result = torch.cat([tensor, tensor, tensor], dim=0) #dim은 차원 나오는 순서 == 가장 바깥 대괄호부터
print(result) # 행 방향으로 붙이기
result = torch.cat([tensor, tensor, tensor], dim=1)
print(result) # 열 방향으로 붙이기3.4 텐서 쌓기 (Stack)
- 원리는 지정한 차원에 대해 unsqueeze를 한번하고 concat을 하게 되는 것
- stack은 for문과 함께 진짜 많이 쓰이게 된다 (pd.concat처럼)
unsqueeze: 차원이 1인 축(axis)을 생성하는 함수
- 지정한 위치(dim)에 크기 1인 차원을 추가하는 함수
squeeze: 차원이 1인 축(axis)을 제거하는 함수
- dim 지정 안 하면 모든 1짜리 차원을 다 제거함.
x = torch.FloatTensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
y = torch.FloatTensor([[10, 11, 12],
[13, 14, 15],
[16, 17, 18]])
print(x.size(), y.size())
z = torch.stack([x, y])
print(z.size()) # torch.Size([2, 3, 3])
# z = torch.cat([x.unsqueeze(0), y.unsqueeze(0)], dim=0)와 동일한 것
z = torch.stack([x, y], dim=-1)
print(z.size()) # torch.Size([3, 3, 2])
z = torch.stack([x, y], dim=1)
print(z.size()) # torch.Size([3, 2, 3])
3.5 텐서 복제해서 차원 넓히기 (Expand)
- broadcasting의 원리가 이 expand를 사용하는 것
x = torch.FloatTensor([[[1, 2]],
[[3, 4]]])
print(x.size()) # torch.Size([2, 1, 2])
y = x.expand(*[2, 3, 2])
print(y)
print(y.size()) # torch.Size([2, 3, 2])3.5 텐서 형변환 (Type Casting)
- .float(), .long()처럼 축약 메서드로 변환 가능
- pandas의 astype() 하고 비슷하네
a = torch.tensor([2], dtype=torch.int)
b = torch.tensor([5.0])
print(a.dtype)
print(b.dtype)
print(a.float())
print(b.int())
print(a + b) # 자동 형변환 (a가 float으로 바뀜)
print(a + b.type(torch.int32)) # b를 int32로 바꿔서 연산3.6 텐서의 모양 변경 (View, Reshape)
- view()나 reshape()는 텐서의 모양을 변경할 때 사용한다.
- 이때, 텐서(tensor)의 순서는 변경되지 않는다.
a = torch.tensor([1, 2, 3, 4, 5, 6, 7, 8])
b = a.view(4, 2)
b = a.reshape(4, 2)
print(b.shape)
b = b.reshape(2,-1)
print(b.shape)
a[0] = 7
print(b) # 얕은 복사 문제 발생
c = a.clone().view(4, 2) # 깊은 복사로는 학습 그래프 끊으면서 카피할 수 있는 clone 제일 많이 사용
a[0] = 9
print(c)3.7 텐서의 차원 교환 (Permute)
- 하나의 텐서에서 특정한 차원끼리 순서를 교체할 수 있다.
a = torch.rand((64, 32, 3))
print(a.shape)
b = a.permute(2, 1, 0)
print(b.shape)3.8 차원 늘리기 / 줄이기 (Squeeze)
- unsqueeze() 함수는 크기가 1인(해당 차원에 원소가 1개만 있는) 차원 하나를 추가한다.
→ 배치(batch) 차원을 추가하기 위한 목적으로 흔히 사용된다. - squeeze() 함수는 크기가 1인(해당 차원에 원소가 1개만 있는) 차원을 모두 제거한다.
batch: 딥러닝 학습 시 한 번에 모델에 넣는 데이터 묶음
a = torch.Tensor([[[[1, 2, 3, 4], [5, 6, 7, 8]]]])
print(a.shape) # torch.Size([1, 1, 2, 4])
print(a.unsqueeze(0).shape) # dimension arg 필수
print(a.unsqueeze(3).shape)
print(a.squeeze(0).shape)
print(a.squeeze().shape) # 크기 1짜리 차원 모두 제거4. 텐서의 연산과 함수
- 기본적으로 요소별(element-wise) 연산
4.1 텐서의 연산 (산술연산)
a = torch.tensor([[1, 2], [3, 4]])
b = torch.tensor([[5, 6], [7, 8]])
# Arithmetic operations
print(a + b)
print(a - b)
print(a * b)
print(a / b)
print(a ** b)
# Logical operation
print(a == b)
# Inplace Operation
print(a)
print(a.mul(b)) # 그냥 곱하기
print(a)
print(a.mul_(b)) # 주소값을 덮어씌우는 것 → 메모리 절약하는 방법이긴 한데 Pytorch가 이미 메모리 최적화 잘 해둠
print(a) # a 덮어씌워짐
# Broadcast in Operations
x = torch.FloatTensor([[1, 2],
[4, 8]])
y = torch.FloatTensor([3,
5])
print(x.size()) # torch.Size([2, 2])
print(y.size()) # torch.Size([2])
z = x + y
print(z)
print(z.size()) # torch.Size([2, 2])
x = torch.FloatTensor([[1, 2]])
y = torch.FloatTensor([[3],
[5]])
print(x.size()) # torch.Size([1, 2])
print(y.size()) # torch.Size([2, 1])
z = x + y
print(z)
print(z.size()) torch.Size([2, 2])
# 사실 scalar 1을 더하는 것도, 1이 차원이 맞춰지면서 전체로 더해지는 것
# 에러가 안 나는 게 좋은 것만은 아닐 수 있다 → 의도치 않은 broadcasting을 조심하라!
# broadcasting이 불가능하면 에러 발생
4.2 행렬곱
print(a.matmul(b))
print(torch.matmul(a, b))4.3 평균/합계 함수 (Dimension Reducing Operation)
a = torch.Tensor([[1, 2, 3, 4], [5, 6, 7, 8]])
print(a.mean()) # 전체 평균
print(a.mean(dim=0)) # 행 연산
print(a.mean(dim=1)) # 열 연산
print(a.sum())
print(a.sum(dim=0))
print(a.sum(dim=1))4.4 정렬 (Sort)
x = torch.randperm(3**3).reshape(3, 3, -1)
values, indices = torch.sort(x, dim=-1, descending=True)
print(values)
print(indices)4.5 최대 / 최댓값 인덱스
- max() 함수는 원소의 최댓값을 반환한다.
- argmax() 함수는 가장 큰 원소(최댓값)의 인덱스를 반환한다.
- min에 대해서는 min(), argmin()을 사용하면 됨
print(a.max())
print(a.max(dim=0)) 어떤 차원을 기준으로 수행할지
print(a.max(dim=1))
print(a.argmax())
print(a.argmax(dim=0))
print(a.argmax(dim=1))
# print(x)
x = torch.tensor([
[[18, 9, 25],
[ 0, 16, 8],
[24, 20, 14]],
[[ 1, 4, 17],
[ 2, 22, 7],
[ 5, 10, 12]],
[[15, 13, 23],
[ 3, 21, 19],
[26, 6, 11]]])
print(x.size())
# torch.Size([3, 3, 3])
y = x.argmax(dim=-1)
print(y)
# tensor([[2, 1, 0],
# [2, 1, 2],
# [2, 1, 0]])
print(y.size())
# torch.Size([3, 3])4.6 최대값과 인덱스 뽑기 (topk)
values, indices = torch.topk(x, k=1, dim=-1)
print(values.size()) # torch.Size([3, 3, 1]) # k=1이여도 차원이 살아있음
print(indices.size()) # torch.Size([3, 3, 1])
_, indices = torch.topk(x, k=2, dim=-1)
print(indices.size()) torch.Size([3, 3, 2])
print(x.argmax(dim=-1) == indices[:, :, 0])
# tensor([[True, True, True],
# [True, True, True],
# [True, True, True]])
# Top K로 Sorting하기
target_dim = -1
values, indices = torch.topk(x,
k=x.size(target_dim),
largest=True)
print(values)
4.7 마스킹하고 값 채우기 (where or Masked fill)
x = torch.FloatTensor([i for i in range(3**2)]).reshape(3, -1)
# 방법 1: torch.where(조건, 참일 때, 거짓일 때)
y = torch.where(x > 4, torch.tensor(-1.0), x)
print(y)
# 방법 2: tensor 클래스의 masked_fill 내장 메서드 사용
mask = x > 4
print(mask)
y = x.masked_fill(mask, value=-1)
print(y)5. 기울기(Gradient)와 자동 미분(Autograd)
5.1 기울기 개념이 왜 필요할까?
- 딥러닝 모델은 결국 수많은 파라미터(가중치)를 조절해서 예측을 더 정확하게 만드는 게 목적
- 즉, 손실 함수(loss) 값을 줄이기 위해 모델의 파라미터(weight) 를 업데이트해야 함
- 이때, 기울기(gradient) 가 필요 →
어느 방향으로, 얼마나 바꿔야 할까?❗ 기울기란?
어떤 값(x)을 조금 바꿨을 때, 출력(y)이 얼마나 바뀌는지를 알려주는 방향 + 민감도
5.2 딥러닝 학습 흐름
-
순전파 (forward)- 입력 데이터를 넣고, 예측 결과를 냄 (output = model(input))
-
손실 계산 (loss)- 예측값과 정답(label)의 차이 계산
-
역전파 (backward)← ★ 여기서 autograd가 등장!- .backward()를 호출하면 PyTorch가 자동으로 모든 파라미터에 대한 기울기 계산
-
가중치 업데이트- Optimizer가 기울기를 보고 파라미터를 업데이트
5.3 자동 미분(Autograd)
- 수식 따로 미분 안 해도 됨! (수천만 개 파라미터도 자동으로 처리)
- 연산을 추적하는 계산 그래프(computational graph) 를 만들어서 .backward() 한 번으로 끝
- PyTorch는
동적 그래프기반이라 직관적이고 유연함- 동적 그래프 방식: 연산 그래프를 미리 만들어두지 않고, 연산이 수행될 때마다 계산 그래프를 즉시 만들어주는 방식
leaf variable: 연산을 통해 만들어지지 않고,requires_grad=True로 생성된 사용자 정의 텐서 (주로 Input parameter)
x = torch.tensor([3.0, 4.0], requires_grad=True)
y = torch.tensor([1.0, 2.0], requires_grad=True)
z = x + y
print(z)
print(z.grad_fn)
out = z.mean()
print(out)
print(out.grad_fn)
out.backward() # scalar에 대하여 가능, not scalar 출력일 때는 반드시 gradient를 줘야 함 (out.shape과 동일해야 함)
print(x.grad) # x값이 바뀔 때 z는 얼마나 바뀌는지
print(y.grad) # y값이 바뀔 때 z는 얼마나 바뀌는지
print(z.grad) # leaf variable(초기 변수)에 대해서만 gradient 추적이 가능하다. 따라서 None.- 학습 시에는
requires_grad=True로 기울기 추적 - 추론(inference) 시에는 불필요한 추적 방지 →
with torch.no_grad()
temp = torch.tensor([3.0, 4.0], requires_grad=True)
print(temp.requires_grad)
print((temp ** 2).requires_grad)
# 기울기 추적을 하지 않기 때문에 계산 속도가 더 빠르다.
with torch.no_grad():
temp = torch.tensor([3.0, 4.0], requires_grad=True)
print(temp.requires_grad)
print((temp ** 2).requires_grad)
만두는 목말라