해당 글은 FastCampus - '모두를 위한 2025 AI 바이블 : AI Signature' 강의를 듣고,
추가 학습한 내용을 덧붙여 작성하였습니다.
1. 데이터 셋 cloning
- 날씨 이미지 데이터 세트
Reference: https://www.kaggle.com/datasets/pratik2901/multiclass-weather-dataset
!git clone https://github.com/ndb796/weather_dataset
%cd weather_dataset # 현재 작업 디렉토리를 weather_dataset 폴더로 변경2. 라이브러리 세팅
import torch
import torchvision
import torchvision.transforms as transforms
import torchvision.models as models
import torchvision.datasets as datasets
import torch.optim as optim
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import random_split
import matplotlib.pyplot as plt
import matplotlib.image as image
import numpy as np3. 데이터 세트 불러오기(Load Dataset)
- Data Augmentation을 명시하여 초기화할 수 있다.
- 이미지를 불러올 때 어떤 방법(회전, 자르기, 뒤집기 등)을 사용할 것인지 명시한다.
- 이후에 DataLoader()를 이용하여 실질적으로 데이터를 불러올 수 있다.
- 어떤 데이터를 사용할 것인지, 배치 크기(batch size), 데이터 셔플(shuffle) 여부 등을 명시한다.
- next() 함수 이용하여 tensor 형태로 데이터를 배치 단위로 얻을 수 있다.
Data Augmentation
학습 데이터를 늘리거나 다양하게 만드는 기법
예: 이미지를 회전, 뒤집기, 밝기 조절 등으로 다양하게 변형
# 이미지 전처리: 학습용 데이터에 적용할 torchvision의 transforms로 순차적 전처리 정의
transform_train = transforms.Compose([
transforms.Resize((256, 256)), # 모든 이미지를 256x256 크기로 resize by Bilinear interpolation (2D)
# 새 픽셀 값을 계산할 때, 주변 가장 가까운 2×2 픽셀(총 4개)을 참고해서 보간
transforms.RandomHorizontalFlip(), # 좌우로 이미지 뒤집기 (데이터 증강)
transforms.ToTensor(), # PIL 이미지 → Tensor로 변환, [0, 1] 스케일링
transforms.Normalize( # 이미지 정규화 (0~1 → -1~1)
mean=[0.5, 0.5, 0.5], # RGB 평균
std=[0.5, 0.5, 0.5] # RGB 표준편차
)
])
# 검증(validation)용 데이터 전처리: 학습과는 다르게 데이터 증강 없음
transform_val = transforms.Compose([
transforms.Resize((256, 256)), # 크기만 조정
transforms.ToTensor(),
transforms.Normalize(
mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]
)
])
# 테스트 데이터 전처리도 검증과 동일 (일관성 있게 증강 없이)
transform_test = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]
)
])
# 학습용 데이터셋 로딩 (ImageFolder: 폴더명을 라벨로 자동 매핑해줌)
train_dataset = datasets.ImageFolder(
root='train/', # 학습 이미지가 들어 있는 폴더
transform=transform_train # 위에서 정의한 transform 적용
)
# 전체 학습 데이터 중 일부를 검증용으로 분할
dataset_size = len(train_dataset) # 전체 데이터 개수
train_size = int(dataset_size * 0.8) # 80% 학습용
val_size = dataset_size - train_size # 20% 검증용
# 학습 / 검증 데이터셋으로 분리
train_dataset, val_dataset = random_split(train_dataset, [train_size, val_size])
val_dataset.dataset.transform = transform_val
# 테스트 데이터셋 로딩 (라벨도 자동 매핑됨)
test_dataset = datasets.ImageFolder(
root='test/',
transform=transform_test
)
# 데이터로더(DataLoader) 설정: 배치 단위로 데이터를 로딩
train_dataloader = torch.utils.data.DataLoader(
train_dataset, batch_size=64, shuffle=True # 학습용: 매 epoch마다 섞기
)
val_dataloader = torch.utils.data.DataLoader(
val_dataset, batch_size=64, shuffle=False # 검증용: 순서 고정
)
test_dataloader = torch.utils.data.DataLoader(
test_dataset, batch_size=64, shuffle=False # 테스트용: 순서 고정
)
4. 데이터 시각화(Data Visualization)
# 시각화 설정
plt.rcParams['figure.figsize'] = [12, 8] # 그래프 크기 설정
plt.rcParams['figure.dpi'] = 60 # 해상도 설정
plt.rcParams.update({'font.size': 20}) # 글꼴 크기 설정
# 이미지 출력 함수 정의
def imshow(input):
# 텐서 → 넘파이로 변환, 채널 순서도 (C, H, W) → (H, W, C)로 변경
input = input.numpy().transpose((1, 2, 0))
# 정규화 해제 (원래 이미지 값으로 복원)
mean = np.array([0.5, 0.5, 0.5])
std = np.array([0.5, 0.5, 0.5])
input = std * input + mean
input = np.clip(input, 0, 1) # 값 범위 0~1로 제한
# 이미지 출력
plt.imshow(input)
plt.show()
# 클래스 라벨 이름 정의
class_names = {
0: "Cloudy",
1: "Rain",
2: "Shine",
3: "Sunrise"
}
# 학습 이미지 배치 하나 로드
iterator = iter(train_dataloader) # DataLoader를 이터레이터로 변환
imgs, labels = next(iterator) # 첫 배치 로드
# 이미지 그리드로 묶기 (앞에서 4장만 보기)
out = torchvision.utils.make_grid(imgs[:4])
# 이미지 출력
imshow(out)
# 해당 이미지들의 클래스 이름 출력
print([class_names[labels[i].item()] for i in range(4)])
Output

['Rain', 'Sunrise', 'Sunrise', 'Shine']
5. 딥러닝 모델 학습(Training)
- 레이어의 깊이를 늘리고 파라미터의 개수를 증가시켜 보면서,
단일 선형층만 있는 아주 단순한 모델부터, 은닉층 + 드롭 아웃이 포함된 심층 모델까지,
총 세 개의 모델을 각각 학습 - 은닉층: Input layer와 Output layer 사이 모든 층을 말함
- 드롭 아웃: 과적합(overfitting)을 막기 위한 규제(regularization) 기법 중 하나로, 학습할 때 일부 뉴런을 무작위로 꺼버리는 것
모델 정의
import torch.nn as nn
import torch.nn.functional as F
# 단일 선형층만 있는 아주 단순한 모델
class Model1(nn.Module):
def __init__(self):
super(Model1, self).__init__() # forward, parameters(), .to(device) 같은 부모 클래스 기능 사용하기 위해 부모 클래스 초기화
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(256 * 256 * 3, 4) # 입력을 flatten 후 바로 클래스 4개로 매핑
def forward(self, x):
x = self.flatten(x) # 이미지(3x256x256) → 1D 벡터
x = self.linear1(x) # 선형 변환
return x
# 은닉층(hidden layer) 1개 추가된 모델
class Model2(nn.Module):
def __init__(self):
super(Model2, self).__init__()
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(256 * 256 * 3, 64) # 첫 번째 은닉층
self.linear2 = nn.Linear(64, 4) # 출력층
def forward(self, x):
x = self.flatten(x)
x = self.linear1(x) # 은닉층 (활성화 함수 없음)
x = self.linear2(x)
return x
# 은닉층 + 드롭아웃이 포함된 심층 모델
class Model3(nn.Module):
def __init__(self):
super(Model3, self).__init__()
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(256 * 256 * 3, 128)
self.dropout1 = nn.Dropout(0.5)
self.linear2 = nn.Linear(128, 64)
self.dropout2 = nn.Dropout(0.5)
self.linear3 = nn.Linear(64, 32)
self.dropout3 = nn.Dropout(0.5)
self.linear4 = nn.Linear(32, 4) # 최종 클래스 4개 출력
def forward(self, x):
x = self.flatten(x)
x = F.relu(self.linear1(x)) # ReLU + Dropout 반복
x = self.dropout1(x)
x = F.relu(self.linear2(x))
x = self.dropout2(x)
x = F.relu(self.linear3(x))
x = self.dropout3(x)
x = self.linear4(x)
return x
# resnet50(ImageNet==대규모 이미지 데이터셋을 이미 훈련시킨 모델)을 transfer learning(이미 훈련된 모델을 가져와서 목적에 맞게 재사용)
class ModelTransfer(nn.Module):
def __init__(self):
super(ModelTransfer, self).__init__()
# ResNet50 모델 불러오기
model = models.resnet50(pretrained=True)
num_features = model.fc.in_features # 마지막 FC 레이어에 들어오는 입력 크기 (2048)
# model.fc.in_features → 2048 (입력 크기)
# model.fc.out_features → 1000 (출력 크기)
model.fc = nn.Linear(num_features, 4) # fc(fully connected layer, 마지막 Layer)에서 output 차원을 1000개 클래스 대신 내가 원하는 4개 클래스 분류기로 교체
self.model = model # self.model로 저장
def forward(self, x): # 메서드 오버라이딩
return self.model(x) # forward 메서드에서 모델 실행모델 학습, 검증, 테스트 함수 정의
import time
# 학습 함수
def train():
start_time = time.time()
print(f'[Epoch: {epoch + 1} - Training]')
model.train() # 모델을 학습 모드로 설정
total = 0
running_loss = 0.0
running_corrects = 0
for i, batch in enumerate(train_dataloader):
imgs, labels = batch
imgs, labels = imgs.cuda(), labels.cuda() # GPU로 이동
outputs = model(imgs) # 순전파
optimizer.zero_grad() # 이전 기울기 초기화
_, preds = torch.max(outputs, 1) # 클래스 차원(1번 축)에서 가장 큰 값의 index를 반환
loss = criterion(outputs, labels) # 손실 계산
loss.backward() # 역전파 → 기울기 계산
optimizer.step() # 파라미터 업데이트
total += labels.shape[0]
running_loss += loss.item() # 연산 그래프와 loss 값을 담고 있는 tensor에서 loss 숫자(float)를 꺼내는 함수
running_corrects += torch.sum(preds == labels.data)
# 일정 step마다 로그 출력
if i % log_step == log_step - 1:
print(f'[Batch: {i + 1}] running train loss: {running_loss / total}, running train accuracy: {running_corrects / total}')
print(f'train loss: {running_loss / total}, accuracy: {running_corrects / total}')
print("elapsed time:", time.time() - start_time)
return running_loss / total, (running_corrects / total).item()
# 검증 함수
def validate():
start_time = time.time()
print(f'[Epoch: {epoch + 1} - Validation]')
model.eval() # 모델을 평가 모드로 설정
total = 0
running_loss = 0.0
running_corrects = 0
for i, batch in enumerate(val_dataloader):
imgs, labels = batch
imgs, labels = imgs.cuda(), labels.cuda()
with torch.no_grad(): # 기울기 추적 비활성화 → 더 빠르고 메모리 절약
outputs = model(imgs)
max_values, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
total += labels.shape[0]
running_loss += loss.item()
running_corrects += torch.sum(preds == labels.data)
if (i == 0) or (i % log_step == log_step - 1):
print(f'[Batch: {i + 1}] running val loss: {running_loss / total}, running val accuracy: {running_corrects / total}')
print(f'val loss: {running_loss / total}, accuracy: {running_corrects / total}')
print("elapsed time:", time.time() - start_time)
return running_loss / total, (running_corrects / total).item()
# 테스트 함수 (검증과 거의 동일)
def test():
start_time = time.time()
print(f'[Test]')
model.eval()
total = 0
running_loss = 0.0
running_corrects = 0
for i, batch in enumerate(test_dataloader):
imgs, labels = batch
imgs, labels = imgs.cuda(), labels.cuda()
with torch.no_grad():
outputs = model(imgs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
total += labels.shape[0]
running_loss += loss.item()
running_corrects += torch.sum(preds == labels.data)
if (i == 0) or (i % log_step == log_step - 1):
print(f'[Batch: {i + 1}] running test loss: {running_loss / total}, running test accuracy: {running_corrects / total}')
print(f'test loss: {running_loss / total}, accuracy: {running_corrects / total}')
print("elapsed time:", time.time() - start_time)
return running_loss / total, (running_corrects / total).item()학습률(learning rate)을 epoch 수에 따라 조정하는 함수
-
초반에는 큰 학습률로 빠르게 학습
→ 빠르게 최적점 근처로 이동 -
후반에는 작은 학습률로 미세하게 튜닝
→ 이미 어느 정도 좋은 지점에 도달, 너무 크게 움직이면 오히려 최적점을 지나쳐 버릴 수 있음 -
오버 피팅을 줄이고 일반화 성능을 줄여 더 좋은 성능과 안정적인 수렴을 얻을 수 있음
import time
def adjust_learning_rate(optimizer, epoch):
lr = learning_rate # 초기 학습률을 가져옴
# epoch >= 3일 때 학습률을 1/10로 감소
if epoch >= 3:
lr /= 10
# epoch >= 7일 때 다시 한 번 1/10로 감소 (즉, 원래의 1/100)
if epoch >= 7:
lr /= 10
# optimizer에 있는 모든 파라미터 그룹의 학습률을 변경
for param_group in optimizer.param_groups:
param_group['lr'] = lr
6. 학습 결과 확인
Model 1: 단일 선형층만 있는 아주 단순한 모델
learning_rate = 0.01
log_step = 20
model = Model1()
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
num_epochs = 20
best_val_acc = 0
best_epoch = 0
history = []
accuracy = []
for epoch in range(num_epochs):
adjust_learning_rate(optimizer, epoch)
train_loss, train_acc = train()
val_loss, val_acc = validate()
history.append((train_loss, val_loss))
accuracy.append((train_acc, val_acc))
if val_acc > best_val_acc:
print("[Info] best validation accuracy!")
best_val_acc = val_acc
best_epoch = epoch
torch.save(model.state_dict(), f"best_checkpoint_epoch_{epoch + 1}.pth")
torch.save(model.state_dict(), f"last_checkpoint_epoch_{num_epochs}.pth")
plt.plot([x[0] for x in accuracy], 'b', label='train')
plt.plot([x[1] for x in accuracy], 'r--',label='validation')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
test_loss, test_accuracy = test()
print(f"Test loss: {test_loss:.8f}")
print(f"Test accuracy: {test_accuracy * 100.:.2f}%")Output
[Epoch: 1 - Training]
train loss: 0.2685530501824838, accuracy: 0.6029629707336426
elapsed time: 6.362705230712891
[Epoch: 1 - Validation]
[Batch: 1] running val loss: 0.25105223059654236, running val accuracy: 0.65625
val loss: 0.36737381071734004, accuracy: 0.692307710647583
elapsed time: 1.214353322982788
[Info] best validation accuracy!
...
[Epoch: 20 - Training]
train loss: 0.05483319741708261, accuracy: 0.8414815068244934
elapsed time: 5.412205696105957
[Epoch: 20 - Validation]
[Batch: 1] running val loss: 0.1295606642961502, running val accuracy: 0.734375
val loss: 0.1441787206209623, accuracy: 0.7337278127670288
elapsed time: 1.2089176177978516
[Test]
[Batch: 1] running test loss: 0.2731671631336212, running test accuracy: 0.625
test loss: 0.17309151234575862, accuracy: 0.7295373678207397
elapsed time: 0.9299411773681641
Test loss: 0.17309151
Test accuracy: 72.95%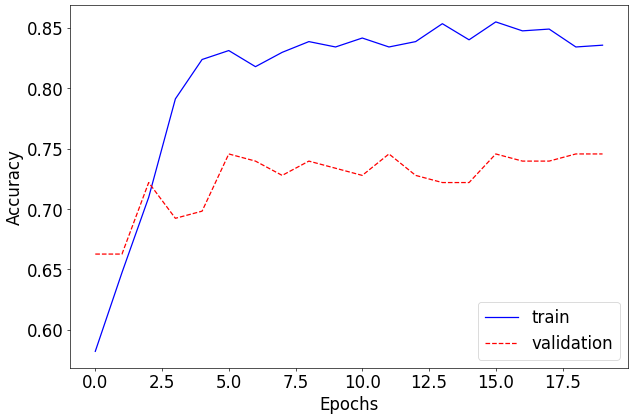
Model 2: 은닉층(hidden layer) 1개 추가된 모델
learning_rate = 0.01
log_step = 20
model = Model2()
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
num_epochs = 20
best_val_acc = 0
best_epoch = 0
history = []
accuracy = []
for epoch in range(num_epochs):
adjust_learning_rate(optimizer, epoch)
train_loss, train_acc = train()
val_loss, val_acc = validate()
history.append((train_loss, val_loss))
accuracy.append((train_acc, val_acc))
if val_acc > best_val_acc:
print("[Info] best validation accuracy!")
best_val_acc = val_acc
best_epoch = epoch
torch.save(model.state_dict(), f"best_checkpoint_epoch_{epoch + 1}.pth")
torch.save(model.state_dict(), f"last_checkpoint_epoch_{num_epochs}.pth")
plt.plot([x[0] for x in accuracy], 'b', label='train')
plt.plot([x[1] for x in accuracy], 'r--',label='validation')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
test_loss, test_accuracy = test()
print(f"Test loss: {test_loss:.8f}")
print(f"Test accuracy: {test_accuracy * 100.:.2f}%")Output
[Epoch: 1 - Training]
train loss: 0.062059673556575067, accuracy: 0.5688889026641846
elapsed time: 7.238025426864624
[Epoch: 1 - Validation]
[Batch: 1] running val loss: 0.10530433803796768, running val accuracy: 0.359375
val loss: 0.10420821263239934, accuracy: 0.4201183617115021
elapsed time: 1.2768044471740723
[Info] best validation accuracy!
...
[Epoch: 20 - Training]
train loss: 0.04108952063101309, accuracy: 0.7881481647491455
elapsed time: 7.323403835296631
[Epoch: 20 - Validation]
[Batch: 1] running val loss: 0.06464774161577225, running val accuracy: 0.609375
val loss: 0.0676442956077982, accuracy: 0.6568047404289246
elapsed time: 1.3936107158660889
[Test]
[Batch: 1] running test loss: 0.10629818588495255, running test accuracy: 0.484375
test loss: 0.07723092860492523, accuracy: 0.6832740306854248
elapsed time: 1.1223466396331787
Test loss: 0.07723093
Test accuracy: 68.33%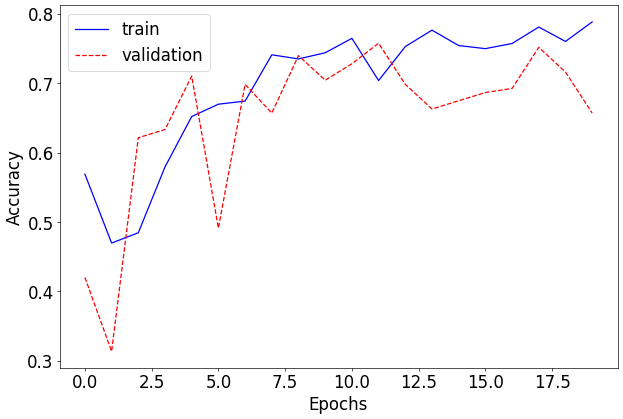
Model 3: 은닉층 + 드롭아웃이 포함된 심층 모델
learning_rate = 0.01
log_step = 20
model = Model3()
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
num_epochs = 20
best_val_acc = 0
best_epoch = 0
history = []
accuracy = []
for epoch in range(num_epochs):
adjust_learning_rate(optimizer, epoch)
train_loss, train_acc = train()
val_loss, val_acc = validate()
history.append((train_loss, val_loss))
accuracy.append((train_acc, val_acc))
if val_acc > best_val_acc:
print("[Info] best validation accuracy!")
best_val_acc = val_acc
best_epoch = epoch
torch.save(model.state_dict(), f"best_checkpoint_epoch_{epoch + 1}.pth")
torch.save(model.state_dict(), f"last_checkpoint_epoch_{num_epochs}.pth")
plt.plot([x[0] for x in accuracy], 'b', label='train')
plt.plot([x[1] for x in accuracy], 'r--',label='validation')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
test_loss, test_accuracy = test()
print(f"Test loss: {test_loss:.8f}")
print(f"Test accuracy: {test_accuracy * 100.:.2f}%")Output
[Epoch: 1 - Training]
train loss: 0.021055312863102665, accuracy: 0.3733333349227905
elapsed time: 7.819769620895386
[Epoch: 1 - Validation]
[Batch: 1] running val loss: 0.014086698181927204, running val accuracy: 0.671875
val loss: 0.014450000588005111, accuracy: 0.6449704170227051
elapsed time: 1.6248998641967773
[Info] best validation accuracy!
...
[Epoch: 20 - Training]
train loss: 0.013426496452755399, accuracy: 0.6651852130889893
elapsed time: 7.245265483856201
[Epoch: 20 - Validation]
[Batch: 1] running val loss: 0.010319100692868233, running val accuracy: 0.8125
val loss: 0.011233355166644034, accuracy: 0.7869822382926941
elapsed time: 1.279524326324463
[Test]
[Batch: 1] running test loss: 0.016797732561826706, running test accuracy: 0.78125
test loss: 0.011137271594932283, accuracy: 0.836298942565918
elapsed time: 1.0040242671966553
Test loss: 0.01113727
Test accuracy: 83.63%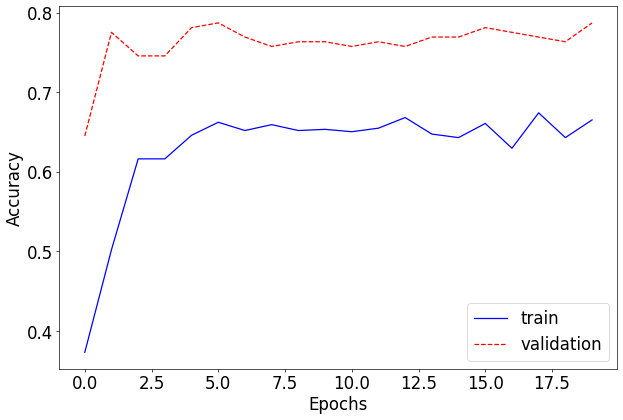
Model 4: resnet50 transfer learning
learning_rate = 0.01
log_step = 20
model = ModelTransfer()
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
num_epochs = 20
best_val_acc = 0
best_epoch = 0
history = []
accuracy = []
for epoch in range(num_epochs):
adjust_learning_rate(optimizer, epoch)
train_loss, train_acc = train()
val_loss, val_acc = validate()
history.append((train_loss, val_loss))
accuracy.append((train_acc, val_acc))
if val_acc > best_val_acc:
print("[Info] best validation accuracy!")
best_val_acc = val_acc
best_epoch = epoch
torch.save(model.state_dict(), f"best_checkpoint_epoch_{epoch + 1}.pth")
torch.save(model.state_dict(), f"last_checkpoint_epoch_{num_epochs}.pth")
plt.plot([x[0] for x in accuracy], 'b', label='train')
plt.plot([x[1] for x in accuracy], 'r--',label='validation')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
test_loss, test_accuracy = test()
print(f"Test loss: {test_loss:.8f}")
print(f"Test accuracy: {test_accuracy * 100.:.2f}%")Output
[Epoch: 1 - Training]
train loss: 0.011269845013265256, accuracy: 0.742222249507904
elapsed time: 13.960606813430786
[Epoch: 1 - Validation]
[Batch: 1] running val loss: 0.0027156963478773832, running val accuracy: 0.921875
val loss: 0.004075330301854738, accuracy: 0.9349112510681152
elapsed time: 1.6107542514801025
[Info] best validation accuracy!
...
[Epoch: 20 - Training]
train loss: 9.46323561516625e-05, accuracy: 1.0
elapsed time: 13.069997072219849
[Epoch: 20 - Validation]
[Batch: 1] running val loss: 0.00017253367695957422, running val accuracy: 1.0
val loss: 0.001278820651522755, accuracy: 0.9704142212867737
elapsed time: 1.609588861465454
[Test]
[Batch: 1] running test loss: 0.0005804044776596129, running test accuracy: 0.984375
test loss: 0.0012308261295104418, accuracy: 0.982206404209137
elapsed time: 1.8220326900482178
Test loss: 0.00123083
Test accuracy: 98.22%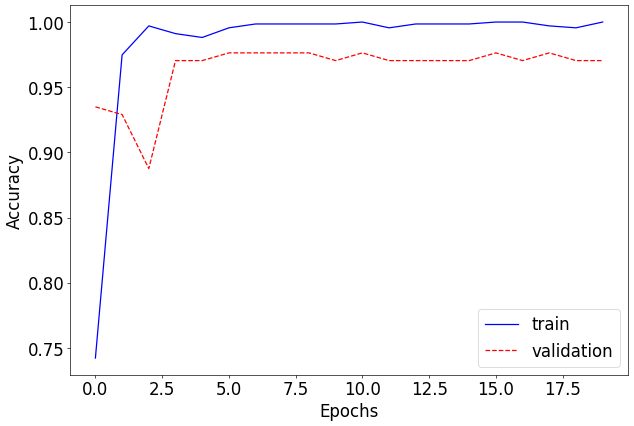

만두는 목말라