Java Stream - 순차 처리 Part1
이 포스팅은 Java 17, IntelliJ 기준으로 작성되었다.
Stream의 동작 과정
스트림 생성 -> 중간연산 체이닝 -> 중간연산 및 최종연산 수행
스트림의 동작 과정은 크게 3가지로 나누어 볼 수 있다. 한 단계씩 살펴보기 이전에 Stream의 핵심적인 클래스를 보고 넘어가자.
AbstractPipeline, ReferencePipeline 클래스
AbstractPipeline에는 스트림 연산과 체이닝을 위한 여러 인스턴스 변수가 있고, AbstractPipeline을 상속한 ReferencePipeline에는 연산 수행을 위한 메서드와 내부 클래스가 정의되어 있다.
// AbstractPipeline
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>> extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {\
private final AbstractPipeline sourceStage;
private final AbstractPipeline previousStage;
private AbstractPipeline nextStage;
private int depth;
private boolean linkedOrConsumed;
private boolean parallel;
...
}
// ReferencePipeline
abstract class ReferencePipeline<P_IN, P_OUT> extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>> implements Stream<P_OUT> {
// 1. Stateless한 중간연산
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) { ... }
@Override
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) { ... }
@Override
public final Stream<P_OUT> peek(Consumer<? super P_OUT> action) { ... }
// 2. Stateful한 중간연산
@Override
public final Stream<P_OUT> distinct() { ... }
@Override
public final Stream<P_OUT> sorted() { ... }
// 3. 종료연산
@Override
public void forEach(Consumer<? super P_OUT> action) { ... }
@Override
public List<P_OUT> toList() { ... }
@Override
public final Optional<P_OUT> findFirst() { ... }
@Override
public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) { ... }
// 4. Inner Class
// 초기 stream 생성을 위한 클래스
static class Head<E_IN, E_OUT> extends ReferencePipeline<E_IN, E_OUT> { ... }
// Stateless한 중간연산을 위한 클래스
abstract static class StatelessOp<E_IN, E_OUT> extends ReferencePipeline<E_IN, E_OUT> { ... }
// Stateful한 중간연산을 위한 클래스
abstract static class StatefulOp<E_IN, E_OUT> extends ReferencePipeline<E_IN, E_OUT> { ... }
...
}아래 두 가지는 기억하고 넘어가자.
Head,StatelessOp,StatefulOp,ReferencePipeline은AbstractPipeline의 자식 타입이다AbstractPipeline에는 previousStage, nextStage 등 중간연산 체이닝을 위한 인스턴스 변수가 존재한다는 것이다.
자 그럼 스트림을 이해하기 위한 사전 준비는 끝났다. 예제를 통해 어떻게 동작하는지 확인해보도록 하자.
Deep Dive
Sample Code
List <String> alphabetList = new ArrayList <>(Arrays.asList("X", "A", "F", "B", "C", "D"));
Stream <String> stream = alphabetList.stream(); // 여기!
stream.filter(s - > s.equals("X") || s.equals("D"))
.map(s - > s + "X")
.sorted()
.forEach(System.out::println); alphabetList에서 "X", "D"에 해당하는 문자열만 필터링하고, 필터링된 문자열 뒤에 "X"를 붙인 뒤 정렬, 콘솔에 출력하는 간단한 예제이다. 동작 과정을 살펴보는 과정에서 stream 변수가 계속 등장하니 기억해두자.
스트림 생성
Stream <String> stream = alphabetList.stream(); // 여기!
stream.filter(s - > s.equals("X") || s.equals("D"))
.map(s - > s + "X")
.sorted()
.forEach(System.out::println); 스트림을 생성하는 단계이다. 위 코드는 Collection 클래스의 stream() 메서드를 호출한다.
// Collection.java
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
// StreamSupport.java
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
return new ReferencePipeline.Head<>(spliterator, StreamOpFlag.fromCharacteristics(spliterator), parallel);
}
// ReferencePipeline.java
static class Head<E_IN, E_OUT> extends ReferencePipeline<E_IN, E_OUT> {
Head(Spliterator<?> source, int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
}
ReferencePipeline(Supplier<? extends Spliterator<?>> source, int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
// AbstractPipeline.java
AbstractPipeline(Supplier<? extends Spliterator<?>> source, int sourceFlags, boolean parallel) {
this.previousStage = null;
this.sourceSupplier = source;
this.sourceStage = this;
this.depth = 0;
this.parallel = parallel;
}stream() 메서드는 최종적으로 Head 객체를 생성해 리턴하는데, 그 과정에서 AbstractPipeline의 인스턴스 변수들을 초기화한다.
Head 클래스
앞서
ReferencePipeline에는 연산 수행을 위한 메서드와 내부 클래스가 정의되어 있다고 언급했었다.Head클래스는ReferencePipeline의 내부 클래스 중 하나로, 초기에 스트림 생성을 위해 사용된다.
AbstractPipeline 인스턴스 변수
- sourceStage - 초기 단계
- previousStage - 이전 단계
- nextStage - 다음 단계
- depth - 연결된 (현재) 단계 수
- parallel - 병렬처리 여부
- linkedOrConsumed - 다른 연산과 체이닝되었거나 최종연산이 완료되었는지 여부
스트림 생성 단계를 거친 후 stream 변수는 Head 타입의 인스턴스(Object-1)를 참조하게 된다.

이하 "stream 변수가 참조하는 인스턴스"를 "stream 인스턴스"로 짧게 작성하겠다.
중간연산 체이닝
예제에 적용된 중간연산은 filter(), map(), sorted()로 총 3가지이다. 하나씩 살펴보자.
filter()
Stream <String> stream = alphabetList.stream();
stream.filter(s - > s.equals("X") || s.equals("D")) // 여기!
.map(s - > s + "X")
.sorted()
.forEach(System.out::println); stream 인스턴스의 filter() 메서드가 호출되는데, Head에 filter() 메서드가 오버라이딩 되어 있지 않기 때문에 부모 클래스인 ReferencePipeline의 메서드가 호출된다. 해당 메서드는 StatelessOp 타입의 익명 객체를 생성해 리턴하는데 stream 인스턴스(Object-1)를 인자로 넘기는 것을 볼 수 있다.
// ReferencePipeline.java
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE, StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}StatelessOp 생성자는 super()를 통해 부모 생성자를 호출하고, AbstractPipeline의 인스턴스 변수들을 초기화한다. 앞의 스트림 생성 단계와 유사하지만 몇 가지 차이점이 있다.
- 스트림 생성 단계의 결과값인 Object-1 객체의 nextStage, linkedOrConsumed 값이 변경된다.
- 현재 생성되는 객체의 previousStage가 Object-1 객체를 참조하고, depth가 1로 초기화된다.
StatelessOp(AbstractPipeline<?, E_IN, ?> upstream, StreamShape inputShape, int opFlags) {
super(upstream, opFlags);
}
ReferencePipeline(AbstractPipeline<?, P_IN, ?> upstream, int opFlags) {
super(upstream, opFlags);
}
// AbstractPipeline.java
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this;
this.previousStage = previousStage;
this.sourceStage = previousStage.sourceStage;
this.depth = previousStage.depth + 1;
}filter() 메서드가 실행된 후 stream 인스턴스는 아래와 같다(Object-2). 이와 동일하게 다른 중간연산에서도 'AbstractPipeline'의 인스턴스 변수들을 초기화되고, 이전 단계에서 리턴된 객체의 인스턴스 변수들이 변경되기 때문에 이해하고 넘어가자.

StatelessOp 클래스
ReferencePipeline의 내부 클래스 중 하나로, Stateless한 중간 연산을 나타내기 위한 클래스이다.
map()
Stream <String> stream = alphabetList.stream();
stream.filter(s - > s.equals("X") || s.equals("D"))
.map(s - > s + "X") // 여기!
.sorted()
.forEach(System.out::println); 다음은 map() 연산이다. filter()와 마찬가지로 stream 인스턴스를 인자로 넘겨 StatelessOp 타입의 익명 객체를 생성해 리턴한다.
@Override
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE, StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}익명 객체를 생성하는 부분의 로직은 동일하므로 코드는 생략한다. filter() 메서드가 실행된 후 stream 인스턴스는 아래와 같다(Object-3).

sorted()
Stream <String> stream = alphabetList.stream();
stream.filter(s - > s.equals("X") || s.equals("D"))
.map(s - > s + "X")
.sorted() // 여기!
.forEach(System.out::println); 마지막으로 정렬 연산이다. 이전에는 StatelessOp 타입의 익명 객체가 리턴된 반면에, 해당 메서드에서는 StatelessOp 클래스를 상속한 OfRef 타입의 객체가 반환된다.
// ReferencePipeline.java
@Override
public final Stream<P_OUT> sorted() {
return SortedOps.makeRef(this);
}
// SortedOps.java
static <T> Stream<T> makeRef(AbstractPipeline<?, T, ?> upstream) {
return new OfRef<>(upstream);
}
private static final class OfRef<T> extends ReferencePipeline.StatefulOp<T, T> {
private final boolean isNaturalSort;
private final Comparator<? super T> comparator;
OfRef(AbstractPipeline<?, T, ?> upstream) {
super(upstream, StreamShape.REFERENCE, StreamOpFlag.IS_ORDERED | StreamOpFlag.IS_SORTED);
this.isNaturalSort = true;
Comparator<? super T> comp = (Comparator<? super T>) Comparator.naturalOrder();
this.comparator = comp;
}
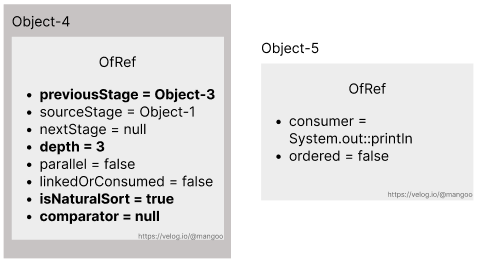
}sorted()에 인자를 따로 넘기지 않았기 때문에 comparator 인스턴스 변수에는 null이 할당된다. sorted() 메서드가 실행된 후 stream 인스턴스는 아래와 같다(Object-4).

요약하자면, 모든 중간연산은 ReferencePipeline으로 인스턴스화되어 이전 단계, 다음 단계에 대한 연결을 갖게 된다. 또한, 중간연산 단계에서는 연산이 이루어지지 않고 최종연산 메서드 호출 시 모든 중간연산과 최종연산이 수행된다.
중간연산 및 최종연산 수행
Stream <String> stream = alphabetList.stream();
stream.filter(s - > s.equals("X") || s.equals("D"))
.map(s - > s + "X")
.sorted()
.forEach(System.out::println); // 여기! stream 인스턴스의 forEach() 메서드가 호출되는데, OfRef에 forEach() 메서드가 오버라이딩 되어 있지 않기 때문에 부모 클래스인 ReferencePipeline 클래스의 메서드가 호출된다. 해당 메서드를 보면 인자로 받은 람다를 OfRef 타입의 인스턴스로 래핑한 뒤 evaluate() 메서드를 호출한다.
// ReferencePipeline.java
@Override
public void forEach(Consumer<? super P_OUT> action) {
evaluate(ForEachOps.makeRef(action, false));
}OfRef 타입의 인스턴스로 래핑되는 부분부터 살펴보자.
// ForEachOps.java
public static <T> TerminalOp<T, Void> makeRef(Consumer<? super T> action, boolean ordered) {
return new ForEachOp.OfRef<>(action, ordered);
}
static final class OfRef<T> extends ForEachOp<T> {
final Consumer<? super T> consumer;
OfRef(Consumer<? super T> consumer, boolean ordered) {
super(ordered);
this.consumer = consumer;
}
@Override
public void accept(T t) {
consumer.accept(t);
}
}makeRef()는 OfRef 생성자를 호출하고, 인스턴스 변수 consumer는 forEach() 메서드의 인자로 넣었던 System.out::prinln으로 초기화된다는 것을 알 수 있다. 따라서, 아래의 OfRef 타입의 인스턴스가 생성되어 evaluate() 메서드로 전달된다.

이제 evalute() 메서드를 살펴보자.
// AbstractPipeline.java
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
@Override
public final boolean isParallel() {
return sourceStage.parallel;
}evaluate()는 모든 중간연산과 최종연산이 수행되는 핵심적인 부분이다. linkedOrConsumed를 체크해 다른 연산과 연결되어 있는지, 이미 소비된 스트림인지 체크한다. 이후 parallel에 따라 분기 처리가 이루어진다. parallel가 true면 병렬 처리, false면 순차 처리이다. stream 인스턴스(Object-4)를 보면 linkedOrConsumed가 false리고, parallel이 false이기 때문에 evaluateSequential() 메서드가 호출된다.
한 번 더 정리해보면, this는 Object-4, terminalOp는 Object-5를 참조한다. 따라서 evaluateSequential() 메서드는 Object-5에 정의된 메서드가 실행되고, Object-4가 인자로 넘어간다.
순차 처리, 병렬 처리 방식은 굉장히 다르기 때문에 이번 포스팅에서는 순차 처리에 대해서만 다룬다.
Object-5는 OfRef 타입으로 evaluateSequential() 메서드가 정의되어 있지 않기 때문에 부모 클래스인 ForEachOps의 메서드가 호출된다. 여기서 helper는 Object-4, this는 Object-5를 참조한다. evaluateSequential() 메서드 내부에서는 helper 파라미터 변수의 wrapAndCopyInto() 메서드를 호출한다. 마찬가지로 OfRef에 wrapAndCopyInto() 메서드가 정의되어 있지 않기 때문에 부모 클래스인 AbstractPipeline의 메서드가 호출된다.
// ForEachOps.java
@Override
public <S> Void evaluateSequential(PipelineHelper<T> helper, Spliterator<S> spliterator) {
return helper.wrapAndCopyInto(this, spliterator).get();
}
// AbstractPipeline.java
@Override
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}AbstractPipeline의 wrapAndCopyInto() 메서드는 아래와 같이 두 가지 부분으로 나누어 볼 수 있다.
wrapSink()-ReferencePipeline타입의 stream 인스턴스와 이에 연결된 인스턴스를 Sink 타입으로 래핑한다.copyInto()- 래핑된Sink타입의 인스턴스를 받아 연산을 수행한다.
여기서 sink는 Object-5, this는 Object-4를 참조한다. 하나씩 살펴보자.
wrapSink()
// AbstractPipeline.java
@Override
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
for (AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}for문을 보면 this가 가리키는 Object-4부터 시작해 이전 단계의 중간연산을 순회한다. 즉, Object-4부터 Object-3, 2, 1까지 각 인스턴스에 대해 opWrapSink() 메서드의 결과값을 sink 지역 변수에 저장한다.
Iteration = 1, p = Object-4
Object-4는 OfRef 타입으로 opWrapSink() 메서드가 정의되어 있지 않기 때문에 부모 클래스인 SortedOps의 메서드가 호출된다. 해당 메서드는 RefSortingSink 인스턴스를 반환한다.
// SortedOps.java
@Override
public Sink<T> opWrapSink(int flags, Sink<T> sink) {
if (StreamOpFlag.SORTED.isKnown(flags) && isNaturalSort)
return sink;
else if (StreamOpFlag.SIZED.isKnown(flags))
return new SizedRefSortingSink<>(sink, comparator);
else
return new RefSortingSink<>(sink, comparator); // 여기!
}
private static final class RefSortingSink<T> extends AbstractRefSortingSink<T> {
private ArrayList<T> list;
RefSortingSink(Sink<? super T> sink, Comparator<? super T> comparator) {
super(sink, comparator);
}
}
// SortedOps.java
private abstract static class AbstractRefSortingSink<T> extends Sink.ChainedReference<T, T> {
protected final Comparator<? super T> comparator;
protected boolean cancellationRequestedCalled;
AbstractRefSortingSink(Sink<? super T> downstream, Comparator<? super T> comparator) {
super(downstream);
this.comparator = comparator;
}
// Sink
abstract static class ChainedReference<T, E_OUT> implements Sink<T> {
protected final Sink<? super E_OUT> downstream;
public ChainedReference(Sink<? super E_OUT> downstream) {
this.downstream = Objects.requireNonNull(downstream);
}
}생성자들을 쭉 따라가보면 RefSortingSink의 list, AbstractRefSortingSink의 comparator, Sink의 downstream 인스턴스 변수들이 초기화된다. 이 순회에서 opWrapSink()는 RefSortingSink 인스턴스를 반환하고, sink 지역 변수는 해당 인스턴스를 참조한다. 도식화해보면 아래와 같다(Object-6).

첫 번째 반복이 종료된 뒤 sink는 Object-6, p는 p.previousStage로 Object-3을 가리키게 된다.
Iteration = 2, p = Object-3
Object-3는 map() 메서드 호출로 생성된 객체였다. map() 호출 시 오버라이드된 onWrapSink() 메서드가 실행되고, ChainedReference 인스턴스를 반환한다.
// ReferencePipeline.java
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE, StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u)); // 여기!
}
};
}
};
}
// Sink.java
abstract static class ChainedReference<T, E_OUT> implements Sink<T> {
protected final Sink<? super E_OUT> downstream;
public ChainedReference(Sink<? super E_OUT> downstream) {
this.downstream = Objects.requireNonNull(downstream);
}
@Override
public void begin(long size) {
downstream.begin(size);
}
@Override
public void end() {
downstream.end();
}
@Override
public boolean cancellationRequested() {
return downstream.cancellationRequested();
}
}두 번째 반복이 종료된 뒤 sink는 Object-7, p는 Object-2를 가리키게 된다. 여기서 accept() 메서드가 오버라이드 되었다는 사실을 기억하자.

이렇게 Object-1까지 반복이 수행되며, 모든 반복문을 거쳐 나오는 sink는 아래와 같다.

요약하자면, 기존의 ReferencePipeline 타입이었던 객체가 반복을 거치며 다음 단계를 가리키는 downstream 변수를 갖고 Sink 타입으로 래핑되는 것이다.

글 덕분에 너무 잘 봤습니다. 혹시 해당 자료에 도달하기까지 어떤 과정으로 도달했는지 궁금합니다. 어떤 책에서 영감을 얻으신건가요?? 아니면 JDK에서 호출을 타고 들어가시면서 정리하신건가요?