
최근 업데이트일 2024-11-26
쿠버네티스: Operator Pattern
Controller의 확장 버전인 Operator에 대해서 알아보고, Prometheus Operator를 실제로 사용해보자.
Operator
선언형 구성 → 자동화 → 도메인 지식까지 담은 클러스터 운영자로, CR을 사용하여 애플리케이션 및 해당 컴포넌트를 관리하는 쿠버네티스의 소프트웨어 익스텐션
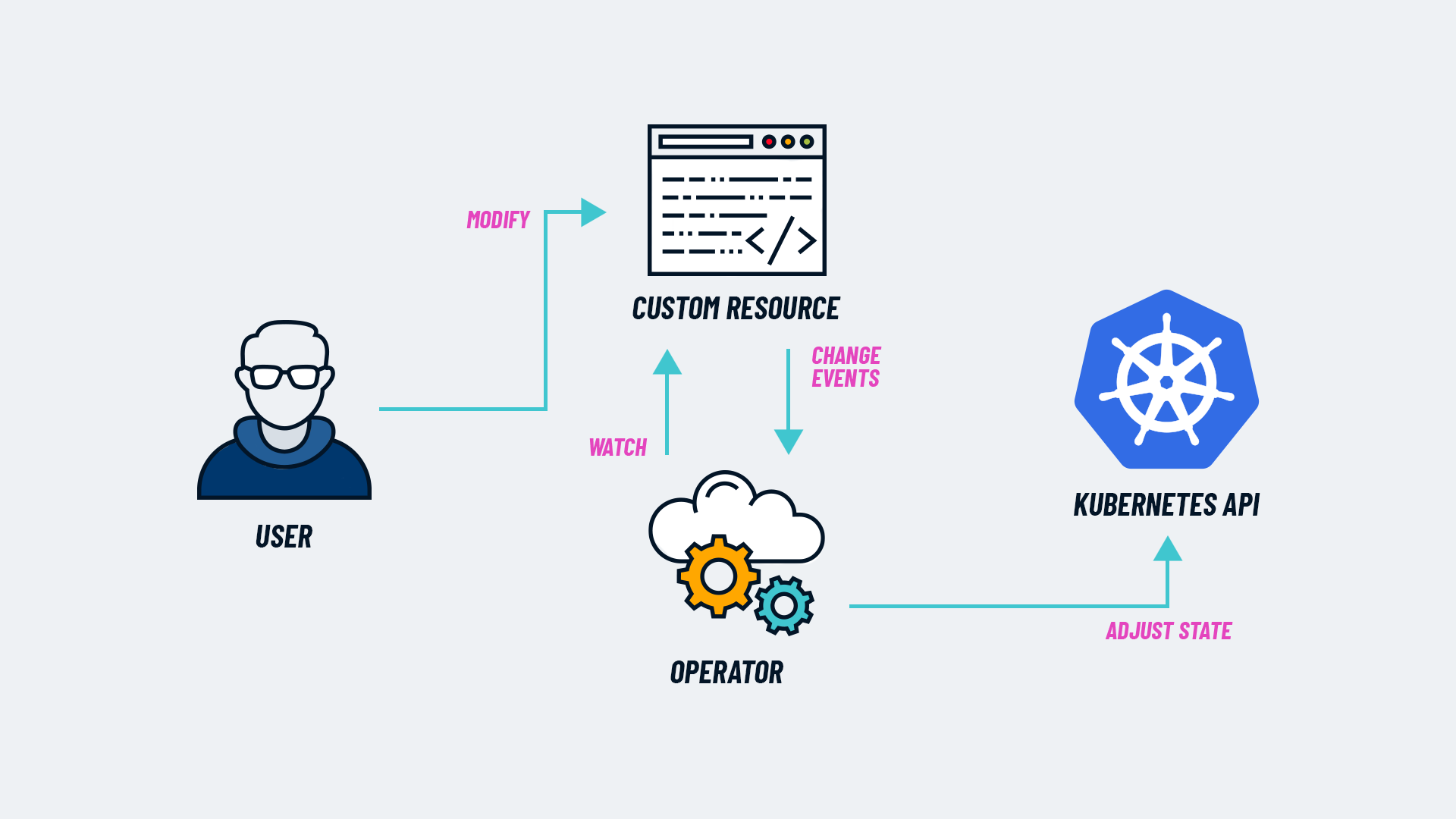
- 단순히 리소스를 만드는 것을 넘어 복잡한 시나리오를 자동화하고 운영하기 위해서 Operator를 사용한다.
- 즉, Custom Resource를 감시하는 Control Loop인 것은 Controller와의 공통점이지만, 자동화와 도메인 지식이 반영된 것이 Operator이다.
- 애플리케이션을 어떻게 조정하고 유지할지에 대한 지식을 코드로 담고 있는 오퍼레이터를 사용하면, 사용자는 리소스에 대해 원하는 상태를 선언하기만 하면 된다.
- Operator 동작 순서
- Operator도 Controller와 마찬가지로 Reconcile Loop를 기반으로 동작한다.
- 사용자가 Custom Resource를 생성
- Operator가 해당 리소스를 감시 (Controller 동작)
- Spec과 현재 Status를 비교
- 필요 시 다른 리소스를 생성/수정/삭제
- 도메인 로직 수행 (백업, 스케일링, 구성 반영 등)
- Operator를 직접 개발할 수 있도록 지원하는 툴이 존재한다.
- Operator SDK: Go/Helm/Ansible 기반 Operator 생성 지원
- Kubebuilder: Go 기반 Controller/CRD 개발 프레임워크
- OperatorHub.io: 다양한 오픈소스 Operator를 검색/설치 가능
- Prometheus Operator
- 사용자가 ServiceMonitor라는 CR을 정의하면, 해당 서비스를 Prometheus가 자동 감시하도록 설정을 추가
- PrometheusRule CR을 통해 알림 룰을 선언하면, Alertmanager와 연동되어 자동 반영
- Prometheus의 설정 파일을 직접 수정하지 않고도, 쿠버네티스 API 기반으로 모든 모니터링을 선언형으로 관리 가능
Operator 내부 구성 요소
Operator는 단일 컨트롤러가 아니라, 쿠버네티스 리소스를 감시하고 제어할 수 있도록 다양한 구성 요소로 이루어져 있다.
- Custom Resource Definition (CRD)
- Custom Controller (Reconciler)
- RBAC 구성
- Operator는 내부적으로 Deployment, Service, Secret 등을 제어하기 때문에 적절한 권한이 필요하다.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: operator-role
rules:
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["get", "list", "create", "update", "delete"]- Role에 대한 권한을 컨트롤러에 연결하기 위해 ServiceAccount와 RoleBinding을 함께 정의한다.
- Controller Pod는 이 ServiceAccount를 통해 동작하며, 해당 권한으로 리소스를 제어한다.
예시: Prometheus Operator
이전 포스팅 때 다뤘던 Prometheus Operator를 사용해서 Service를 감시하고 문제가 발생했을 때 Alert를 Slack으로 보내보자.
- Operator가 없던 때는 Pod/Service 변경 시마다 설정 파일을 수정하고 재시작해야 하고, 각 Service를 Prometheus 설정에 수작업으로 추가해야 하며, Alertmanager 설정도 별도로 유지해야 하며, 일관된 방식이 없었다.
- 이를 해결하기 위해 Prometheus Operator가 등장했다. AlertManager가 Slack으로 알림을 보내기까지의 예제를 살펴보자.
1. Helm으로 kube-prometheus-stack을 설치하면, 아래 CRD들이 함께 설치되어 해당 리소스들을 사용할 수 있게 된다.
| Custom Resource | 역할 |
|---|---|
Prometheus | Prometheus 인스턴스 정의 (배포 + 설정 포함) |
ServiceMonitor | 감시할 대상 서비스 정의 (서비스 선택자 + 메트릭 경로 등) |
PrometheusRule | 경고 룰 정의 (Alertmanager와 연동) |
Alertmanager | 알림 시스템 정의 및 관리 |
2. 감시할 Service 예시 생성
apiVersion: v1
kind: Service
metadata:
name: my-app
labels:
app: my-app
spec:
selector:
app: my-app
ports:
- name: metrics
port: 80803. ServiceMonitor 선언
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: my-app-monitor
labels:
release: prometheus
spec:
namespaceSelector: # 다른 네임스페이스의 ServiceMonitor도 감시 가능
matchNames:
- default
selector:
matchLabels:
app: my-app
endpoints:
- port: metrics4. Operator의 동작
- Prometheus Operator는 ServiceMonitor를 감지하고, 내부적으로 Prometheus 설정을 자동 생성하여 대상을 등록한다.
- 설정이 반영되면 Prometheus가
my-app의/metrics를 수집하기 시작한다. - 이 때 Prometheus Pod를 재시작하지 않아도 된다.
5. 경고 Rule 정의
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule # 경고 rule을 정의하는 리소스 타입
metadata:
name: high-latency
namespace: monitoring
spec:
groups: # 여러 규칙을 묶는 단위
- name: example-rules
rules:
- alert: HighRequestLatency # 경고 이름
# 알림 조건 (PromQL 표현식), 요청에 대한 응답이 0.5초를 초과했는지 확인
expr: job:request_latency_seconds:mean5m{job="my-app"} > 0.5
for: 2m # 조건이 충족된 뒤 경고가 발생하기까지 기다리는 시간
labels:
severity: warning # 경고의 심각도
annotations: # 경고 제목과 경고 설명
summary: "High request latency on my-app"
description: "my-app 평균 응답 지연 시간이 0.5초를 초과했습니다."- 이때 Alertmanager 리소스가 함께 정의되어 있고, Prometheus 설정에서 Alertmanager를 참조하고 있다면, 위에서 정의한 경고가 발생했을 때 알림이 전송된다.
6. Alertmanager 설정
apiVersion: v1
kind: Secret # 설정을 보안 리소스로 감추기 위해 Secret으로 생성
metadata:
name: alertmanager-prometheus-alertmanager
namespace: monitoring
labels: # Prometheus Operator가 Alertmanager 인스턴스를 찾을 때 사용
alertmanager: prometheus-alertmanager
type: Opaque # 일반 문자열 타입의 Secret
stringData:
alertmanager.yaml: | # Alertmanager의 핵심 구성 파일
global:
resolve_timeout: 5m # 경고 해제 후 알림 전송 지연 시간
route:
receiver: slack-notifications # 기본 경고 수신자 아래 목록 중 하나 선택
receivers:
- name: slack-notifications
slack_configs:
- send_resolved: true # 경고 해제 시에도 Slack 알림 전송 여부
channel: '#alerts' # 메시지가 전송될 Slack 채널
# Slack에서 발급받은 Webhook URL
api_url: 'https://hooks.slack.com/services/xxxx/yyyy/zzzzzz'
# 메시지 제목과 내용 (PrometheusRule의 annotations 참조)
title: '{{ .CommonAnnotations.summary }}'
text: '{{ range .Alerts }}{{ .Annotations.description }}\n{{ end }}'- Prometheus Operator는 Alertmanager 설정을 보통 Secret 리소스로 관리하며, 사용자는
alertmanager.yaml설정 파일을 Secret에 담아 생성하면, Operator가 이를 감지하여 Alertmanager 인스턴스에 자동 반영한다.
7. Alertmanager와 Prometheus 연결 확인
apiVersion: monitoring.coreos.com/v1
kind: Prometheus # Prometheus 인스턴스를 정의하는 CR
metadata:
name: prometheus
namespace: monitoring
spec:
alerting:
alertmanagers:
- namespace: monitoring # Alertmanager 리소스가 위치한 네임스페이스
name: prometheus-alertmanager # Service 이름 (보통 Alertmanager가 자동으로 이 이름을 가짐)
port: web # Alertmanager 서비스 포트 (보통 9093 포트)- prometheus CR의
.spec.alerting.alertmanagers필드를 통해 Alertmanager를 연결한다.

It’s always white night here.