Appendix D. Adding bells and whistles to the training loop

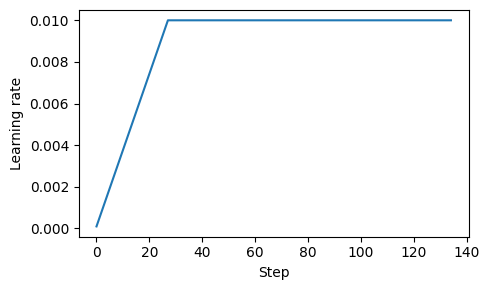
1. Learning rate warmup
- 복잡한 모델을 훈련할 때, learning rate warmup을 구현하면 안정화에 도움이 된다.
- 학습률을 매우 낮은 값에서 지정한 최대값까지 증가시켜서, 불안정한 업데이트 위험을 줄인다.
- 대게 warmup step의 수는 전체 step의 0.1% ~ 20%이다.
- 전체 step 수 = data_loader 길이 * 에포크 수
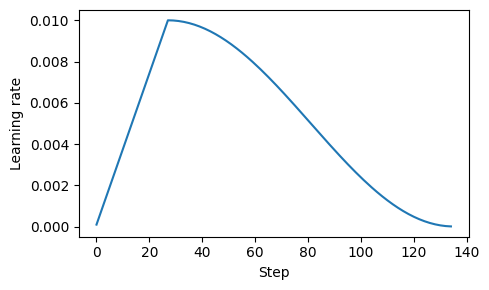
2. Cosine decay
- training 동안 learning rate가 cosion 곡선을 따르며, 초기 값에서 코사인의 절반 사이클 후 0에 가까이 감소한다.
- 이는 모델이 weight를 개선하는 동안 학습 속도를 늦추기 위해 설계되어, 안정화에 도움을 준다.
- linear한 형태로 감소하는 linear dacay가 사용되기도 한다.
3. Gredient clipping
- 임계값을 설정하여 이를 초과하는 기울기를 최대 크기로 축소하여 역전파 중 모델 매개변수에 대한 업데이트가 처리하기 쉬운 범위 내에 유지되도록 한다.
- PyTorch에서
clip_grad_norm_에서max_norm을 설정하면 norm이 1.0을 초과하지 않는다.- norm은 파라미터 공간의 gradient vector의 길이를 측정한 것으로, L2 norm이나 Euclidean norm으로도 불린다.
3가지 방법론을 training에 적용하면 아래와 같다.
ORIG_BOOK_VERSION = False
def train_model(model, train_loader, val_loader, optimizer, device,
n_epochs, eval_freq, eval_iter, start_context, tokenizer,
warmup_steps, initial_lr=3e-05, min_lr=1e-6):
train_losses, val_losses, track_tokens_seen, track_lrs = [], [], [], []
tokens_seen, global_step = 0, -1
# Retrieve the maximum learning rate from the optimizer
peak_lr = optimizer.param_groups[0]["lr"]
# Calculate the total number of iterations in the training process
total_training_steps = len(train_loader) * n_epochs
# Calculate the learning rate increment during the warmup phase
lr_increment = (peak_lr - initial_lr) / warmup_steps
for epoch in range(n_epochs):
model.train()
for input_batch, target_batch in train_loader:
optimizer.zero_grad()
global_step += 1
# Adjust the learning rate based on the current phase (warmup or cosine annealing)
if global_step < warmup_steps:
# Linear warmup
lr = initial_lr + global_step * lr_increment
else:
# Cosine annealing after warmup
progress = ((global_step - warmup_steps) /
(total_training_steps - warmup_steps))
lr = min_lr + (peak_lr - min_lr) * 0.5 * (1 + math.cos(math.pi * progress))
# Apply the calculated learning rate to the optimizer
for param_group in optimizer.param_groups:
param_group["lr"] = lr
track_lrs.append(lr) # Store the current learning rate
# Calculate and backpropagate the loss
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward()
# Apply gradient clipping after the warmup phase to avoid exploding gradients
if ORIG_BOOK_VERSION:
if global_step > warmup_steps:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
else:
if global_step >= warmup_steps: # the book originally used global_step > warmup_steps, which lead to a skipped clipping step after warmup
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
tokens_seen += input_batch.numel()
# Periodically evaluate the model on the training and validation sets
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader,
device, eval_iter
)
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
# Print the current losses
print(f"Ep {epoch+1} (Iter {global_step:06d}): "
f"Train loss {train_loss:.3f}, "
f"Val loss {val_loss:.3f}"
)
# Generate and print a sample from the model to monitor progress
generate_and_print_sample(
model, tokenizer, device, start_context
)
return train_losses, val_losses, track_tokens_seen, track_lrs
It’s always white night here.