Chapter 05. Pretraining on Unlabeled Data

훈련 루프와 코드를 구현하여 LLM을 사전 훈련해보고, 실제 GPT의 가중치를 모델에 load해보자.
https://github.com/rasbt/LLMs-from-scratch/tree/main/ch05
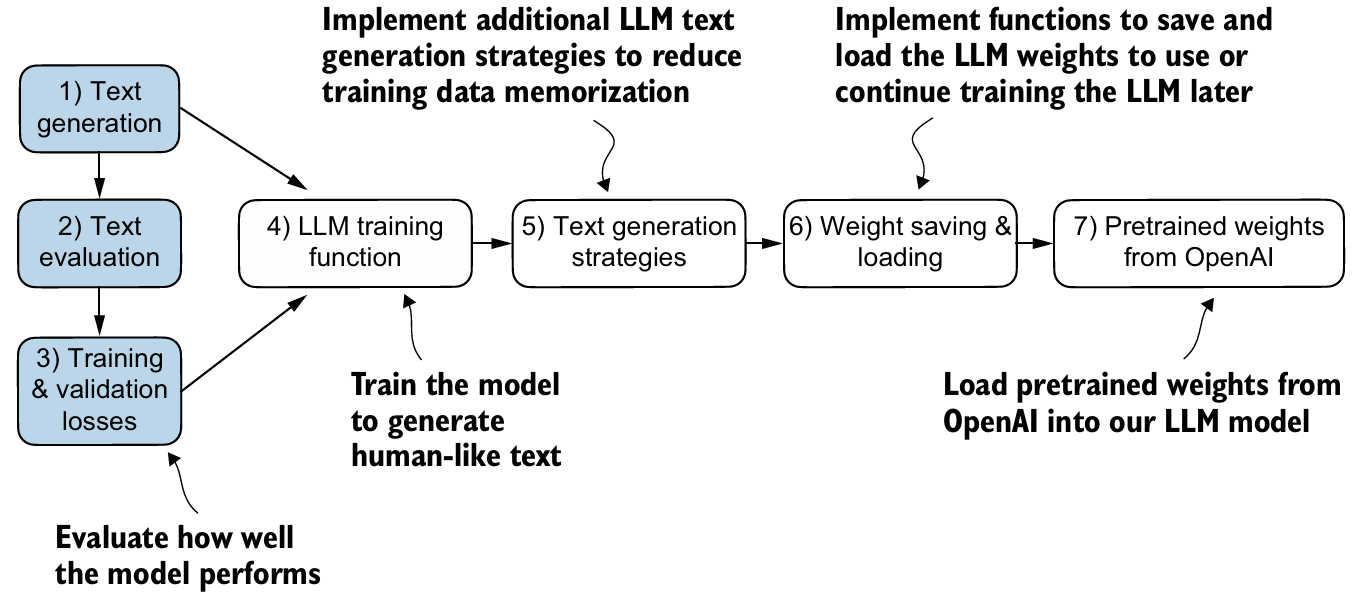
1. 텍스트 모델 평가하기
LLM이 만든 text가 'good text'인지를 측정하는 metric이 필요하다.
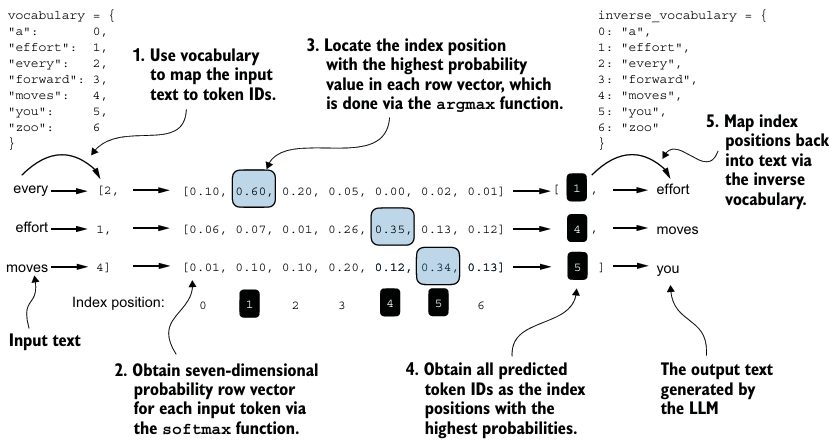
- 현대 LLMs은 bias vector를 사용하지 않는다.
"qkv_bias": False - 크게 보면, input을 넣으면 그에 맞는 logits을
vocab_size만큼 얻고, 이에 softmax를 적용하면 확률을 포함하는 동일한 차원의 텐서로 변환할 수 있다. 여기에argmax를 적용해서 가장 확률이 높은 token을 예측값으로 채택한다. - 훈련을 하기 위해서는 이 값이 실제 target과 얼마나 멀리 떨어져 있는지를 알아야 한다.
- 즉, sequence에 대해서 예측한
vocab_size만큼의 확률 텐서에서 실제 target이 가지는 확률을 극대화시켜야 한다는 것이다. - 수학적 최적화에서 이 확률 점수를 극대화하는 것보다 확률의 로그값을 극대화하는 것이 더 쉽다.
- batch와 sequence를 이어붙인 후(
seq_len * batch_size, vocab_size), 평균 로그값을 계산해서 이를 극대화하는 방식으로 진행한다.
- 즉, sequence에 대해서 예측한
※ 배치 차원 이해
- PyTorch나 다른 딥러닝 프레임워크는 배치 차원을 입력 텐서의 형태에 포함하는 것을 기대한다.
torch.tensor(text).unsqueeze(dim)을 사용하면 dim(축) 위치에 새로운 차원을 하나 추가해준다.token_ids.squeeze(dim)을 사용하면 배치 차원을 제거해 원래의 (단일 시퀀스) 형태로 복원한다.- 추가적으로,
dim=-1은 텐서의 마지막 차원을 의미하므로 tensor의 형태를 잘 유의해야 한다.
cross-entropy와 perplexity

- 딥러닝에서는 평균 로그 확률을 최대화하는 대신 음의 평균 로그 확률 값을 최소화하는 것이 관례이다.
- 확률의 로그값을 양수로 만든 후 이를 최소화하고 이 값을 cross-entropy loss라 부른다.
- PyTorch에서는
.flatten()을 이용해 sequence끼리 붙이고,torch.nn.functional.cross_entropy(logits_flat, targets_flat)을 통해 값을 얻는다.- 자동으로 target이 극대화되도록 계산된다.
- LLM에서는 cross-entropy loss의 지수 함수인 perplexity를 사용하기도 한다.
- 예측한 확률 분포가 데이터셋 내 단어의 실제 분포와 얼마나 잘 일치하는지를 측정하는 척도를 제공한다.
- 값이 낮을수록 실제 분포와 가까운 걸 의미한다.
학습과 검증 세트 손실 계산
def calc_loss_batch(input_batch, target_batch, model, device):
input_batch, target_batch = input_batch.to(device), target_batch.to(device)
logits = model(input_batch)
loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())
return loss
def calc_loss_loader(data_loader, model, device, num_batches=None):
total_loss = 0.
if len(data_loader) == 0:
return float("nan")
elif num_batches is None:
num_batches = len(data_loader)
else:
# num_batches가 DataLoader의 총 배치 수보다 크면, 이에 맞게 num_batches를 줄인다.
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
loss = calc_loss_batch(input_batch, target_batch, model, device)
total_loss += loss.item()
else:
break
return total_loss / num_batches
# 아직 훈련 중이 아니므로 효율성을 위해 gradient 추적 비활성화
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device)
val_loss = calc_loss_loader(val_loader, model, device)2. LLM 학습
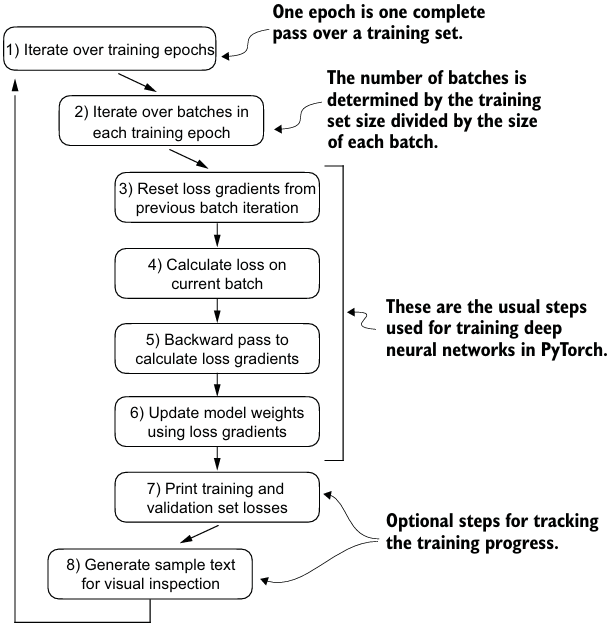
learning rate warmup, cosine annealing, gradient clipping에 대해서 더 알아보기 위해서는 Appendix D를 참고하자.
ORIG_BOOK_VERSION = False
def train_model(model, train_loader, val_loader, optimizer, device,
n_epochs, eval_freq, eval_iter, start_context, tokenizer,
warmup_steps, initial_lr=3e-05, min_lr=1e-6):
train_losses, val_losses, track_tokens_seen, track_lrs = [], [], [], []
tokens_seen, global_step = 0, -1
# optimizer에서 peak learning rate을 가져옴
peak_lr = optimizer.param_groups[0]["lr"]
# 전체 학습 과정의 총 iteration 수 계산
total_training_steps = len(train_loader) * n_epochs
# warm-up 구간 동안 learning rate이 증가하는 크기 계산
lr_increment = (peak_lr - initial_lr) / warmup_steps
for epoch in range(n_epochs):
model.train()
for input_batch, target_batch in train_loader:
optimizer.zero_grad()
global_step += 1
# 현재 단계에 따라 learning rate 조정 (warm-up 또는 cosine annealing)
if global_step < warmup_steps:
# 선형으로 warm-up
lr = initial_lr + global_step * lr_increment
else:
# warm-up 이후에는 cosine 함수 기반 annealing
progress = ((global_step - warmup_steps) /
(total_training_steps - warmup_steps))
lr = min_lr + (peak_lr - min_lr) * 0.5 * (1 + math.cos(math.pi * progress))
# 계산된 learning rate을 optimizer에 적용
for param_group in optimizer.param_groups:
param_group["lr"] = lr
track_lrs.append(lr) # 현재 learning rate 저장
# 손실 계산 및 역전파 수행
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward()
# warm-up 이후에 gradient clipping 수행 (gradient exploding 방지)
if ORIG_BOOK_VERSION:
if global_step > warmup_steps:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
else:
if global_step >= warmup_steps: # warm-up 직후 clipping이 누락되는 문제를 방지
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
tokens_seen += input_batch.numel()
# 일정 간격으로 train/validation 성능 평가
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader,
device, eval_iter
)
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
# 현재 손실 출력
print(f"Ep {epoch+1} (Iter {global_step:06d}): "
f"Train loss {train_loss:.3f}, "
f"Val loss {val_loss:.3f}"
)
# 에폭이 끝날 때 샘플 문장을 생성해서 출력 (경과 확인)
generate_and_print_sample(
model, tokenizer, device, start_context
)
return train_losses, val_losses, track_tokens_seen, track_lrs훈련 세트를 단순히 암기하기 시작하는 overfitting을 어느 정도 완화하기 위한 디코딩 전략을 다뤄보자.
3. 랜덤성을 통제하기 위한 디코딩 전략
temperature scaling
torch.argmax를 사용하여 항상 가장 높은 확률의 토큰을 샘플링하는게 아닌 입력 텐서의 확률에 맞게 샘플링하는torch.multinomial(probs, num_samples=1)을 이용한다.- logit을 0보다 큰 숫자로 나누는 Temperature scaling 방식으로 확률 분포에서 토큰을 선택하는 것을 제어할 수 있다.
- temperature가 1보다 높으면 softmax를 적용한 후 토큰 확률이 더 균일하게 분포되고, 작으면 더 비균등하게 분포된다.
top-k sampling
- 더 높은 temperature를 사용하면서도 무의미한 문장의 확률은 줄이기 위해 샘플링된 토큰을 가장 가능성이 높은 상위 k개로 제한하는 top-k sampling을 사용한다.
코드에 위 두 방식을 적용하면 아래와 같다.
def generate(model, idx, max_new_tokens, context_size, temperature=0.0, top_k=None, eos_id=None):
# 반복문은 이전과 동일: logits을 얻고 last step에만 집중
for _ in range(max_new_tokens):
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :]
# New: top-k sampling으로 logit 필터링
if top_k is not None:
# 상위 top_k 값만 유지
top_logits, _ = torch.topk(logits, top_k)
min_val = top_logits[:, -1]
logits = torch.where(logits < min_val, torch.tensor(float("-inf")).to(logits.device), logits)
# New: temperature scaling 적용
if temperature > 0.0:
logits = logits / temperature
# softmax를 적용하여 확률 분포 계산
probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)
# 확률 분포로부터 샘플링
idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)
# Same as before: logits 값이 가장 높은 토큰 인덱스를 선택
else:
idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)
if idx_next == eos_id: # eos_id가 지정되어 있고, 해당 토큰이 생성되면 조기 종료
break
# Same as before: 새로 생성한 토큰 인덱스를 sequence 뒤에 추가
idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)
return idx4. PyTorch로 모델 저장 후 로드
torch.save({
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),},
"model_and_optimizer.pth"
)
checkpoint = torch.load("model_and_optimizer.pth", weights_only=True)
model = GPTModel(GPT_CONFIG_124M)
model.load_state_dict(checkpoint["model_state_dict"])
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0005, weight_decay=0.1)
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])- Adam이나 AdamW 같은 adaptive optimizer도 각 모델 가중치에 대해 추가적인 매개변수를 저장하므로 같이 저장하는 것이 좋다.
5. OpenAI에서 사전훈련된 가중치 로드
Hugging Face Hub나 OpenAI에서 pretrained weights를 load할 수 있다.
- GPT instance를 만들고 config를 조정한 후 위 코드를 통해 가중치를 가져와서 파라미터를 옮기면 사용할 수 있다.
01_main-chapter-code/gpt_generate.py에서 확인할 수 있으며,gpt_train.py이 이번 chapter의 main 코드이다.transformers라이브러리로도 모델 load가 가능하다.- 추가적으로, tensor data만을 저장하고 잠재적으로 악성 코드 실행을 피하는
.safetensors로 안정적인 모델 load가 가능하다.
※ chainlit
- chainlit 라이브러리를 통해 서버에서 UI로 구현한 모델과 Chat-GPT 처럼 대화가 가능하다.
@chainlit.on_message
async def main(message: chainlit.Message): # main 함수
token_ids = generate( # 이 함수는 내부에서 이미 `with torch.no_grad()` 사용
model=model, # 사용자 입력 텍스트는 `message.content`로 제공됨
idx=text_to_token_ids(message.content, tokenizer).to(device),
max_new_tokens=50,
context_size=model_config["context_length"],
top_k=1,
temperature=0.0
)
text = token_ids_to_text(token_ids, tokenizer)
await chainlit.Message(
content=f"{text}", # 이 응답이 인터페이스에 모델의 출력으로 표시됨
).send()※ GPT to Llama
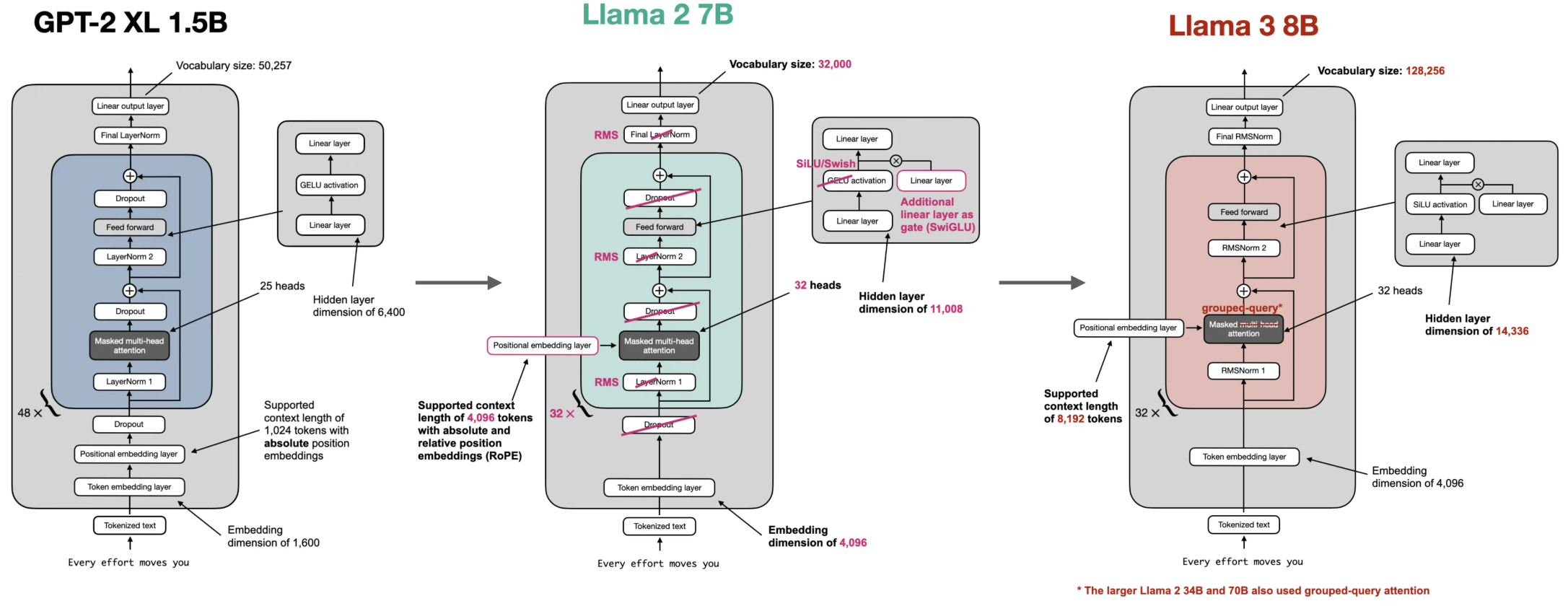
GPT 아키텍처를 Llama 2로 변환하기
1. Replace LayerNorm with RMSNorm layer
- 평균과 분산을 사용하여 normalize하는 LayerNorm 대신 계산 효율성이 좋은 root mean square를 사용하는 RMSNorm을 사용한다.
- : 입력
- : 학습가능한 파라미터 벡터
- : zero-division을 피하기 위한 작은 상수
example_batch = torch.randn(2, 3, 4)
rms_norm = RMSNorm(emb_dim=example_batch.shape[-1])
rmsnorm_pytorch = torch.nn.RMSNorm(example_batch.shape[-1], eps=1e-5)2. Replace GELU with SiLU activation
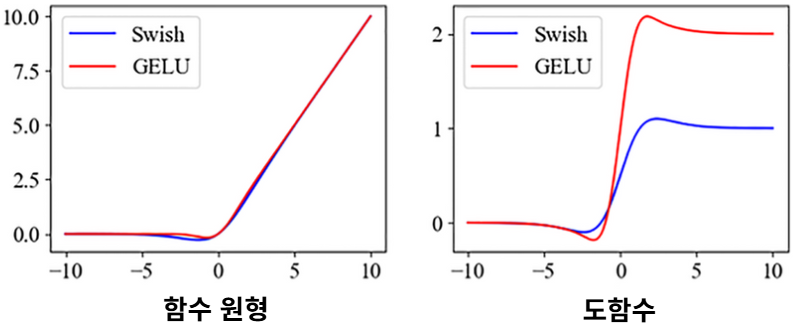
- GELU 대신 Swish function으로도 알려진 SiLU를 사용한다.
- , sigmoid
- GELU와 유사한 성질을 가지며 부드러운 곡선 형태를 갖고 있다.
- ReLU보다 더 부드럽고, 미분 가능하며, 실제 성능에서 향상을 보이는 경우도 있다.
- 자연스러운 gating 역할(어떤 값을 조절하거나 통제)을 하여 정보 흐름을 조절한다.
3. Update the FeedForward module
- Feed Forward 모듈에 SwiGLU라는 Gates Linear Unit(GLU) 기반 비선형 활성화 기법에 SiLU를 결합한 방식을 사용한다.
- 는 입력
- 는 학습 가능한 선형 변환
- 는 시그모이드 함수
- 는 element-wise muliplication (Hadamard product)
- 즉, 한 쪽 선형 변환 결과에 시그모이드로 gating을 곱한다.
- In FeedForward,
- gating을 시그모이드 대신 SiLU 함수로 조절하여 더 부드러운 비선형성과 정보 흐름이 가능해진다.
4. Add RoPE to MultiHeadAttention module
- GPT-2처럼 전통적인 Absolute Positional Embedding 방식으로 위치 정보를 고정된 벡터에 더하는 대신 상대적인 위치 정보까지 포함하는 Rotary Position Embeddings (RoPE)을 사용한다.
- key와 query 벡터에 직접 rotation 형태로 위치 정보를 내재화한다.
- 즉, 각 위치마다 특정한 회전 행렬을 적용해서 self-attention의 query/key를 위치에 따라 다르게 변형한다.
- 입력 , 위치 일 때 벡터 를 2차원 쌍들로 나눈다.
- 각 쌍에 대해 2D 회전 적용한다.
- 각 에 대해, 위치 에 따라 각도를 정의,
- 설정은 초기 Transformer에서 사용된 Positional Encoding의 주파수 스케일링 방식과 동일하다.
- 기존 :
- 위치별로 다양한 주파수의 sin/cos 함수를 적용하여, 에 따라 얼마나 빠르게 사인/코사인이 바뀌는지를 조절한다.
- 즉, 특정 차원 에 주파수를 부여하여 모델은 다양한 시간/위치 패턴에 민감하게 반응한다.
- GPT-2도 Transformer(attention 기반 시퀀스 처리 모델)의 변형 중 하나지만 위와 같은 sinusoidal PE 방식을 사용하지 않는다.
- 회전 행렬 이고 이를 각 쌍에 곱하면,
- 가 되어 위치 p에 따라 각 쌍의 벡터가 다른 각도로 회전한다.
- 각 에 대해, 위치 에 따라 각도를 정의,
- 회전된 벡터들을 다시 합쳐 원래 차원의 벡터로 되돌린다.
- 벡터 쌍을 나눠서 2D 회전을 하지만 실제 차원은 로 유지된다.
- 위치가 멀어질수록 벡터가 더 많이 회전하며, self-attention 내에서 두 벡터 q, k의 내적은 회전된 벡터들 간의 내적으로 바뀐다.
def precompute_rope_params(head_dim, theta_base=10_000, context_length=4096):
'''사전 계산된 RoPE 회전 각도 테이블을 생성'''
assert head_dim % 2 == 0, "임베딩 차원은 짝수여야 합니다."
# inverse frequency 계산
inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2)[: (head_dim // 2)].float() / head_dim))
# 위치 인덱스 생성 (0부터 context_length-1까지)
positions = torch.arange(context_length)
# 각도(θ) 계산 → 위치 × 주파수
angles = positions[:, None] * inv_freq[None, :] # Shape: (context_length, head_dim // 2)
# 각도를 head_dim 크기에 맞춰 확장 (angles는 2차원 회전은 짝을 이룬 차원마다 적용되기 때문에)
angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)
# 사인과 코사인 값 미리 계산해둬서
cos = torch.cos(angles)
sin = torch.sin(angles)
return cos, sin
def compute_rope(x, cos, sin):
# x: (batch_size, num_heads, seq_len, head_dim)
batch_size, num_heads, seq_len, head_dim = x.shape
assert head_dim % 2 == 0, "Head 차원은 짝수여야 합니다."
# x를 절반으로 나누기 (짝수 인덱스와 홀수 인덱스 역할)
x1 = x[..., : head_dim // 2] # First half
x2 = x[..., head_dim // 2 :] # Second half
# sin, cos 텐서의 shape을 x에 맞게 조정
# RoPE 적용 전,각 key, query의 shape은 (batch_size, num_heads, seq_len, head_dim)
# cos와 x(q와 k)의 shape이 다르면 element-wise 연산이 불가능하므로 차원을 맞춰줌
cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)
sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)
# Rotation 행렬을 적용한 변환 계산
rotated = torch.cat((-x2, x1), dim=-1)
x_rotated = (x * cos) + (rotated * sin)
return x_rotated.to(dtype=x.dtype)class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, num_heads, dtype=None):
super().__init__() # ,dropout, num_heads, qkv_bias=False): # Previous GPT-2
assert d_out % num_heads == 0, "d_out은 num_heads로 나누어떨어져야 합니다."
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads # 원하는 출력 차원에 맞게 각 head의 차원 축소
################################### NEW ###################################
# 아래의 모든 선형 계층에 대해 bias=False, dtype=dtype으로 설정
###########################################################################
self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)
self.W_key = nn.Linear(d_in, d_out, bias=False, dtype=dtype)
self.W_value = nn.Linear(d_in, d_out, bias=False, dtype=dtype)
self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype) # 여러 head의 출력을 결합하는 linear layer
# self.dropout = nn.Dropout(dropout)
self.register_buffer("mask", torch.triu(torch.ones(context_length, context_length), diagonal=1))
################################### NEW ###################################
cos, sin = precompute_rope_params(head_dim=self.head_dim, context_length=context_length)
self.register_buffer("cos", cos)
self.register_buffer("sin", sin)
###########################################################################
def forward(self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# 마지막 차원을 쪼개서 num_heads 차원을 추가함
# (b, num_tokens, d_out) → (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
# 전치: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
################################### NEW ###################################
keys = compute_rope(keys, self.cos, self.sin)
queries = compute_rope(queries, self.cos, self.sin)
###########################################################################
# 스케일 조정된 dot-product self-attention 계산 (causal mask 포함)
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# 원래의 마스크를 현재 토큰 수만큼 잘라서 boolean 타입으로 변환
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# 마스크가 적용된 위치의 attention score를 -inf로 설정 (softmax에서 무시되도록)
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
# attn_weights = self.dropout(attn_weights)
# context vector 계산 후 차원 transpose
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# head 결합, where self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.reshape(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # 최종 차원 투영
return context_vec5. Update the TransformerBlock module
이제
dropout과qkv_bias를 제거하고dtype세팅을 추가하며, RMSNorm을 사용하는 방식으로TransformerBlock을 수정한다.
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dtype=cfg["dtype"] # NEW
# dropout=cfg["drop_rate"],
# qkv_bias=cfg["qkv_bias"]
)
self.ff = FeedForward(cfg)
############################### NEW ###############################
# 기존 LayerNorm 대신 RMSNorm을 사용
# self.norm1 = LayerNorm(cfg["emb_dim"])
# self.norm2 = LayerNorm(cfg["emb_dim"])
self.norm1 = RMSNorm(cfg["emb_dim"])
self.norm2 = RMSNorm(cfg["emb_dim"])
###################################################################
# self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
# 첫 번째 블록: Self-Attention + Residual 연결
shortcut = x
x = self.norm1(x)
x = self.att(x) # Shape [batch_size, num_tokens, emb_size]
# x = self.drop_shortcut(x)
x = x + shortcut # 입력과 Attention 출력을 더함 (Residual 연결)
# 두 번째 블록: FeedForward + Residual 연결
shortcut = x
x = self.norm2(x)
x = self.ff(x)
# x = self.drop_shortcut(x)
x = x + shortcut # 입력과 FF 출력을 더함 (Residual 연결)
return x6. Update the model class
Llama2Modelclass에 dropout을 제거하고 RoPE 임베딩과 RMSNorm을 사용하며 dtype 세팅을 추가한다.
class Llama2Model(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"], dtype=cfg["dtype"])
# self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
# self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
################################### NEW ###################################
# self.final_norm = LayerNorm(cfg["emb_dim"])
self.final_norm = RMSNorm(cfg["emb_dim"])
###########################################################################
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False, dtype=cfg["dtype"])
def forward(self, in_idx):
# batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
# pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
x = tok_embeds # + pos_embeds # Shape [batch_size, num_tokens, emb_size]
# x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits※ Model 초기화 & Load tokenizer & Load pretrained weights
- Llama2는 Google's SentencePiece tokenizer를 사용한다.
- Llama3는 Tiktoken의 tokenizer를 사용한다.
- tokenizer를 사용하기 위해서는 추가적인 라이센스 동의 및 코드 수정이 필요하다.
- huggingface에서 사전 훈련된 가중치나 instruction-finetuned 모델을 load할 수 있다.
Llama 2 아키텍처를 Llama 3.2로 변환하기
Llama 2를 Llama 3.2로 바꾸려면 rotary 임베딩을 수정하고, Grouped-Query attention을 구현하고 GPT-4 토크나이저를 커스터마이징 해야한다.
1. Modified RoPE
- Rotation 행렬에서 Rotation 각도를 결정하는 데 사용되는 매개변수인 RoPE 가 10,000에서 500,000으로 증가하여, 회전 각도가 느리게 감소한다. (주파수 압축 해제)
- RoPE의 동작을 푸리에 해석 관점에서 보면, 각 차원마다 다른 주파수의 sin/cos파로 임베딩을 회전시키는 것이다.
- 높은 차원일수록 빠르게 진동하는 성분이 많아지고 이는 멀리 떨어진 위치에서 정보를 표현하기 어렵다.
- 따라서 를 증가시키면 진동 주기가 길어지게 하면 더 넓은 문맥 길이에서도 정보가 구분 가능해진다.
- 이로 인해 더 높은 임베딩 차원은 이전보다 더 큰 각도와 연관되게 된다.
2. Grouped-Query attention
- 고유한 query를 가지지만 Llama 2와 달리 key와 value projection을 여러 attention head 간에 공유한다.
- 즉, query는 여전히 head 수만큼 다르게 계산하지만, key와 value는 적은 수의 head(=group 수)만큼만 생성하고, 이걸 여러 query head가 공유해서 사용한다.
- 이로 인해 계산과 매개변수 측면에서 효율적이다.
- key/value가 적기 때문에, 각 query head가 사용할 수 있도록 key/value를 반복해서 복제/확장해줘야 한다.
- 즉, 각 key/value를 해당 그룹에 속한 여러 query head가 사용할 수 있도록,
dim차원에 따라 복제해줘야 한다.
- 즉, 각 key/value를 해당 그룹에 속한 여러 query head가 사용할 수 있도록,
SharedBuffersclass도 도입한다.- key/value가 공유되면 mask (causal mask), RoPE에서 사용하는 cos/sin 텐서도 head 수나 token 수에 따라 재사용/공유 가능해진다.
- 해당 class로 한 번만 계산하고, 여러 head에 재사용한다.
############################# NEW #############################
class SharedBuffers:
_buffers = {}
@staticmethod
def get_buffers(context_length, head_dim, rope_base, freq_config, dtype=torch.float32):
# 버퍼의 고유 키를 구성
key = (context_length, head_dim, rope_base, tuple(freq_config.values()) if freq_config else freq_config, dtype)
if key not in SharedBuffers._buffers:
# 아직 저장되지 않았다면 버퍼 생성
mask = torch.triu(torch.ones(context_length, context_length), diagonal=1)
cos, sin = precompute_rope_params(head_dim, rope_base, context_length, freq_config)
if dtype is not None:
cos = cos.to(dtype)
sin = sin.to(dtype)
SharedBuffers._buffers[key] = (mask, cos, sin)
return SharedBuffers._buffers[key]
############################# NEW #############################
class GroupedQueryAttention(nn.Module):
def __init__(
self, d_in, d_out, context_length, num_heads,
num_kv_groups, # NEW: key/value 그룹 수
rope_base=10_000, # NEW: RoPE의 기본 스케일 (theta 값)
rope_config=None, # NEW: RoPE 관련 추가 설정
dtype=None
):
super().__init__()
assert d_out % num_heads == 0, "d_out은 num_heads로 나누어떨어져야 합니다."
assert num_heads % num_kv_groups == 0, "num_heads는 num_kv_groups로 나누어떨어져야 합니다" # NEW
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads
############################# NEW #############################
# self.W_key = nn.Linear(d_in, d_out, bias=False, dtype=dtype)
# self.W_value = nn.Linear(d_in, d_out, bias=False, dtype=dtype)
# key와 value는 num_heads가 아닌 num_kv_groups만큼만 생성
self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)
self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)
self.num_kv_groups = num_kv_groups
self.group_size = num_heads // num_kv_groups # 각 kv 그룹당 몇 개의 query head가 붙는지 계산
################################################################
self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)
self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)
############################# NEW #############################
# SharedBuffers를 사용해 마스크, cos, sin을 가져옴 (RoPE 용)
mask, cos, sin = SharedBuffers.get_buffers(context_length, self.head_dim, rope_base, rope_config, dtype)
############################# NEW #############################
self.register_buffer("mask", mask)
self.register_buffer("cos", cos)
self.register_buffer("sin", sin)
def forward(self, x):
b, num_tokens, d_in = x.shape
queries = self.W_query(x) # Shape: (b, num_tokens, d_out)
keys = self.W_key(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)
values = self.W_value(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)
# 쿼리는 모든 헤드로 분할
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
##################### NEW #####################
# keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
# values = values.view(b, num_tokens, self.num_heads, self.head_dim)
# key와 value는 적은 수의 kv 그룹 수만큼만 분할
keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim)
values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim)
################################################
# 차원 transpose: (b, num_heads/group, num_tokens, head_dim)
keys = keys.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)
values = values.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)
queries = queries.transpose(1, 2) # Shape: (b, num_query_groups, num_tokens, head_dim)
# RoPE 위치 임베딩 적용
keys = compute_rope(keys, self.cos, self.sin)
queries = compute_rope(queries, self.cos, self.sin)
##################### NEW #####################
# head 수에 맞게 key와 value 확장 (복제)
# e.g. kv 그룹이 [K1, K2]이고 group_size=2일 때
# repeat_interleave → [K1, K1, K2, K2] (query 그룹과 정렬됨)
# repeat_interleave 대신 repeat을 쓸 경우 → [K1, K2, K1, K2]로 잘못 정렬됨
# Shape: (b, num_heads, num_tokens, head_dim)
keys = keys.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)
values = values.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)
# 스케일 조정된 dot-product attention (causal 마스크 적용)
# Shape: (b, num_heads, num_tokens, num_tokens)
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# 마스크 적용 (bool 타입으로 변환 후 현재 토큰 길이에 맞게 자름)
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
attn_scores.masked_fill_(mask_bool, -torch.inf)
# softmax를 통해 attention weight 계산
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
assert keys.shape[-1] == self.head_dim
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# 헤드 결합: (b, num_tokens, d_out(self.num_heads * self.head_dim))
context_vec = context_vec.reshape(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec- e.g. Llama 3 8B는 8 kv-groups이므로 32개의 attention heads를 8로 나누어 key와 value 행렬의 행 수가 4배 감소하게 된다.
3. Update the TransformerBlock module & Defining the model class
- RoPE 임베딩 모델과 GHA 매개변수로 업데이트한다.
- model class는 Llama2Model과 동일하게 한다.
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = GroupedQueryAttention( # MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
num_heads=cfg["n_heads"],
num_kv_groups=cfg["n_kv_groups"], # NEW
dtype=cfg["dtype"]
)
self.ff = FeedForward(cfg)
self.norm1 = RMSNorm(cfg["emb_dim"], eps=1e-5)
self.norm2 = RMSNorm(cfg["emb_dim"], eps=1e-5)
def forward(self, x, mask=None, cos=None, sin=None):
##################### NEW #####################
# forward 메서드는 이제 self.mask를 직접 참조하는 대신 `mask`를 인자로 받음
# 또한 RoPE 계산을 위한 cos, sin 값도 인자로 전달
################################################
# Shortcut connection for attention block
shortcut = x
x = self.norm1(x)
x = self.att(x.to(torch.bfloat16), mask, cos, sin) # Shape [batch_size, num_tokens, emb_size]
x = x + shortcut # 기존 입력 residual
# Shortcut connection for feed-forward block
shortcut = x
x = self.norm2(x)
x = self.ff(x.to(torch.bfloat16))
x = x + shortcut # 기존 입력 residual
return xclass Llama3Model(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"], dtype=cfg["dtype"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
self.final_norm = RMSNorm(cfg["emb_dim"], eps=1e-5)
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False, dtype=cfg["dtype"])
#################### NEW #####################
cos, sin = precompute_rope_params(
head_dim=cfg["emb_dim"] // cfg["n_heads"],
theta_base=cfg["rope_base"],
context_length=cfg["context_length"],
freq_config=cfg["rope_freq"]
)
self.register_buffer("cos", cos, persistent=False)
self.register_buffer("sin", sin, persistent=False)
##############################################
self.cfg = cfg
def forward(self, in_idx):
tok_embeds = self.tok_emb(in_idx)
x = tok_embeds
#################### NEW #####################
num_tokens = x.shape[1]
mask = torch.triu(torch.ones(num_tokens, num_tokens, device=x.device, dtype=torch.bool), diagonal=1)
##############################################
for block in self.trf_blocks:
x = block(x, mask, self.cos, self.sin)
x = self.final_norm(x)
logits = self.out_head(x.to(self.cfg["dtype"]))
return logits※ Initialize model & Load tokenizer & Load pretrained weights
- Llama3 7B와 매개변수 딕셔너리를 선언한다.
- Llama3는 어휘가 확장된 Tiktoken의 GPT-4 토크나이저를 사용한다.
- 데이터셋이나 모델을 처리할 때 사용하는
Blobfile패키지가 필요할 수 있다.
- 데이터셋이나 모델을 처리할 때 사용하는
- 마찬가지로, pretrained weight를 load할 수 있다.
- huggingface에서 사전 훈련된 가중치나 instruction-finetuned 모델을 load할 수 있다.
- Llama 3는 prompt template을 모델이 요구하는 것과 같게 사용해야 한다.
- e.g. "Hello World!" =
'<|start_header_id|>user<|end_header_id|>\n\nHello World!<|eot_id|>'
- e.g. "Hello World!" =
from pathlib import Path
import tiktoken
from tiktoken.load import load_tiktoken_bpe
class Tokenizer:
"""Llama-3의 특수 토큰 ID를 추적하는 tiktoken wrapper class"""
def __init__(self, model_path):
if not os.path.isfile(model_path):
raise FileNotFoundError(model_path)
# BPE 병합 규칙을 불러옴
mergeable = load_tiktoken_bpe(model_path)
# Meta의 tokenizer.json에 정의된 특수 토큰을 하드코딩
self.special = {
"<|begin_of_text|>": 128000,
"<|end_of_text|>": 128001,
"<|start_header_id|>": 128006,
"<|end_header_id|>": 128007,
"<|eot_id|>": 128009,
}
# reserved ID (중복되지 않게 추가)
self.special.update({f"<|reserved_{i}|>": 128002 + i
for i in range(256)
if 128002 + i not in self.special.values()})
self.model = tiktoken.Encoding(
name=Path(model_path).name,
pat_str=r"(?i:'s|'t|'re|'ve|'m|'ll|'d)"
r"|[^\r\n\p{L}\p{N}]?\p{L}+"
r"|\p{N}{1,3}"
r"| ?[^\s\p{L}\p{N}]+[\r\n]*"
r"|\s*[\r\n]+"
r"|\s+(?!\S)"
r"|\s+",
mergeable_ranks=mergeable,
special_tokens=self.special,
)
def encode(self, text, bos=False, eos=False):
ids = ([self.special["<|begin_of_text|>"]] if bos else []) \
+ self.model.encode(text)
if eos:
ids.append(self.special["<|end_of_text|>"])
return ids
def decode(self, ids):
return self.model.decode(ids)Llama 3.1 8B & Llama 3.2 1B

- Llama 3.1에서는 추가 구성을 통해 inverse frequency 계산에 추가 조정을 도입한다.
- inverse frequency는 각 차원마다 정의되는 를 통해
position * inv_freq = 각도(angle)를 만들고, 거기서 을 구한다. - Llama 3.1에서는 이에 대해 custom scaling이나 비선형 변환을 적용해 RoPE의 각도 분포를 미세 조정하여 긴 문장에서 positional signal이 너무 빨리 사라지는 문제를 완화하도록 한다.
- inverse frequency는 각 차원마다 정의되는 를 통해
- Llama 3.2는 GPT-2에서 사용하던 back weight tying을 사용하며, 3.1에 비해 모델의 크기가 많이 줄어들었다.
- Embedding layer와 output projection layer의 가중치를 공유하는 것으로, 모델 파라미터 수를 줄이고, 학습 안정성과 일반화 성능을 향상시키는 데 도움을 준다.
output_proj.weight = embedding.weight
- 추가적으로, RoPE rescaling factor가 증가했다.
- 입력 시퀀스가 길어질수록 각도가 커져서 학습이 불안정하거나 정보가 깨질 수 있고, 이를 방지하기 위해 RoPE에 들어가는 각도를 scale down한다.
- 이 factor를 더 크게 하여 긴 시퀀스를 더 부드럽게, 더 천천히 회전하게 만들어 긴 context에서도 안정적으로 작동하게 한다.
※ 메모리 효율적인 모델 가중치 로드
모델을 setup하고 weight를 load하면 GPU memory(VRAM) 사용량이 2배가 된다. (setup + weight)
이를 해결하기 위한 메모리 효율적인 weight loading 방법을 살펴보자.
Loading weights sequentially
- 모델을 순차적으로 load해서 최대 메모리 사용량이 모델의 크기와 거의 같도록 하는 방법이다.
- 먼저 모델을 GPU에 load하고 모델 가중치를 CPU memory에 load한 후 각 매개변수를 GPU에 하나씩 복사한다.
- 모델에
.to를 사용할 수 있도록 하나의 매개변수 tensor를 일시적으로 GPU에 이동시키기 때문에, 모델보다 조금 더 GPU memory를 사용한다.
Loading the model with low CPU memory
- "meta" device approach를 통해 GPU memory는 더 크지만 CPU memory가 작은 기계에 모델을 load한다.
- meta device는 데이터에 실제 메모리를 할당하지 않고도 tensor를 생성할 수 있는 special device type이다.
- 앞서 설명했던 순차적 weight loading과 더불어 사용하면 순차적 weight loading을 사용하지 않았을 때보다 CPU를 더 많이 사용하지만, 순차적 weight loading만 사용했을 때보다는 CPU memory를 더 적게 사용한다.
Using mmap=True (recommmended)
- memory-mapped file I/O를 가능하게 하여 tensor가 디스크 저장소에서 직접 데이터에 접근할 수 있게된다.
- 이로 인해 사용자의 spec에 맞게 memory가 최적으로 사용된다.
model.load_state_dict(
torch.load("model.pth", map_location=device, weights_only=True, mmap=True),
assign=True
)
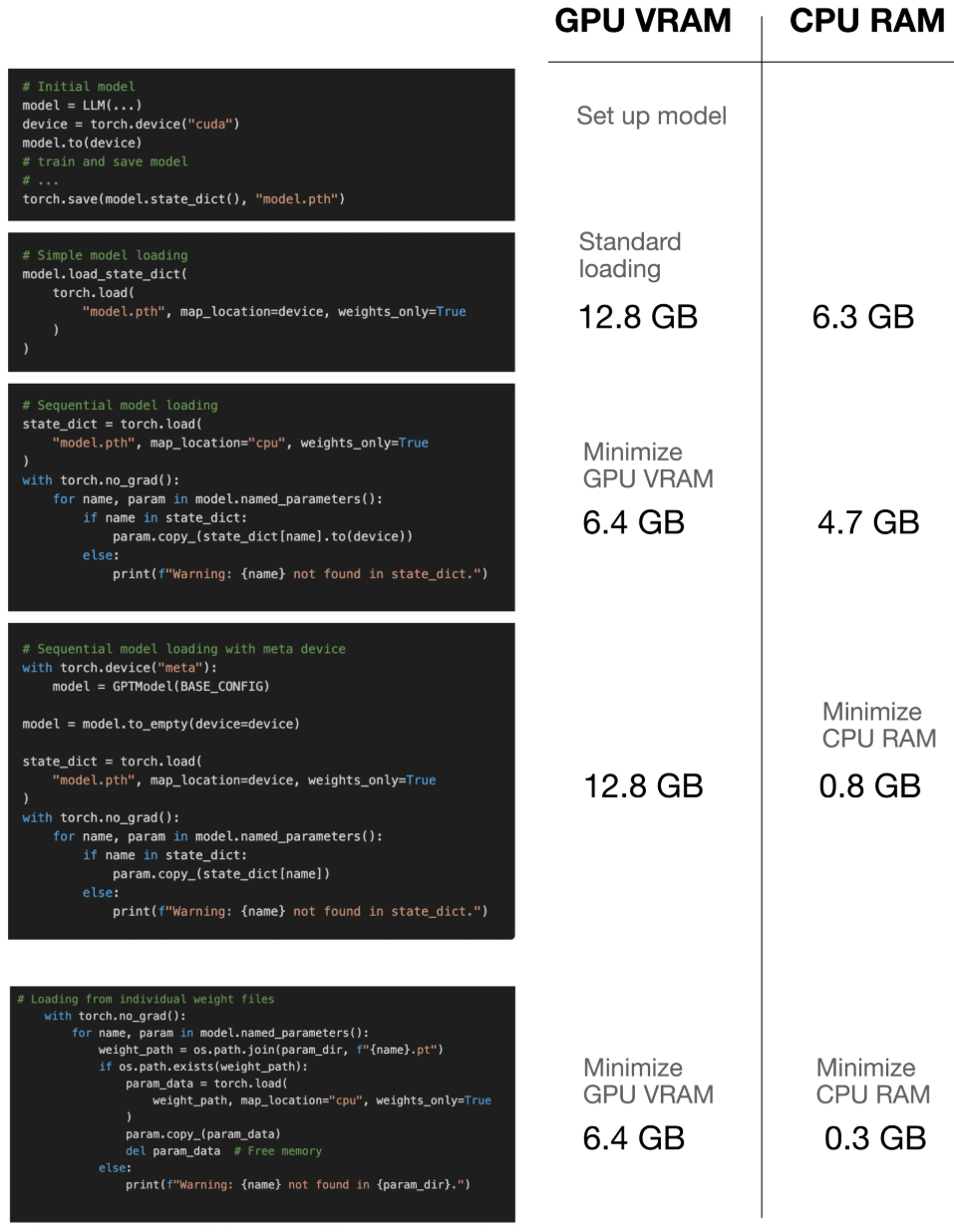
- 각 가중치 텐서를 따로 저장하고 로드하는 brute-force 방식도 사용될 수 있다.
※ Tiktoken BPE 토크나이저에 새로운 토큰 확장하기
BPE가 새로운 토큰을 분해하지 않고 단일 토큰으로 인코딩하려는 special token으로 인식하도록 확장해보자.
custom_tokens = ["MyNewToken_1", "MyNewToken_2"]
custom_token_ids = {
token: base_tokenizer.n_vocab + i for i, token in enumerate(custom_tokens)
}
extended_tokenizer = tiktoken.Encoding(
name="gpt2_custom",
pat_str=base_tokenizer._pat_str,
mergeable_ranks=base_tokenizer._mergeable_ranks,
special_tokens={**base_tokenizer._special_tokens, **custom_token_ids},
)- 먼저 토크나이저에 새 토큰을 merge를 하지 않는 토큰인 special tokens으로 추가한다.
- 이후, pretrained LLM에도 사용할 수 있도록 임베딩 및 output layer를 업데이트한다.
- 새로 추가하는 토큰 수만큼 확장한 새 레이어를 만들고 여기에 기존 임베딩 layer의 weight를 복사한 다음 교체한다.
- output layer도 Linear layer인 것만 차이가 있고 과정은 동일하다.
- weight tying인 모델은 하나의 layer만 바꾸고 복사해주면 된다.
original_out_features, original_in_features = gpt.out_head.weight.shape
new_out_features = original_out_features + 2
new_linear = torch.nn.Linear(original_in_features, new_out_features)
with torch.no_grad():
new_linear.weight[:original_out_features] = gpt.out_head.weight
if gpt.out_head.bias is not None:
new_linear.bias[:original_out_features] = gpt.out_head.bias
gpt.out_head = new_linear※ LLM 학습 속도
Training Speed를 향상시키기 위해 아래와 같은 작업을 해보자.
- Causal mask를 저장하지 않고 그때그때 즉시 생성한다.
- 일반적으로 shape이
(seq_len, seq_len)이고, 고정된 시퀀스 길이에서는 재사용할 수 있지만, 동적으로 생성하면 메모리 낭비를 줄이고 더 유연한 시퀀스 처리가 가능하다.
- 일반적으로 shape이
- 최신 GPU 내 행렬 곱셈 장치인 Tensor Cores를 사용한다.
- 해당 유닛은 형태의 GEMM(General Matrix Multiply and Accumulate) 연산을 단일 사이클로 처리하고, 행렬 블록 단위(e.g. 4x4x4)로 연산을 병렬 처리함으로써, 기존보다 훨씬 빠른 연산이 가능하다.
- Fused AdamW optimizer를 사용한다.
- 기본 AdamW 옵티마이저와 동일한 알고리즘이지만, GPU 연산을 더 효율적으로 처리하기 위해 여러 연산을 하나의 커널로 합쳐 overhead를 최소화한다.
- 기존 개별 CUDA 커널로 실행하던 방식을 단일 커널로 묶어 실행함으로써 커널 호출 횟수를 줄이고 GPU 메모리 접근 횟수를 최적화한다.
pin_memory=True를 통해 GPU memory를 미리 할당하고 재사용한다.- GPU로 데이터를 옮길 때 비동기적 데이터 전송이 가능해져 입출력 bottleneck을 줄인다.
- float32 대신 bfloat16 정확도를 사용한다.
- bfloat16은 float16보다 넓은 표현 범위를 가지며, float32의 절반의 메모리를 사용하기 때문에 연산 속도는 빨라지고, 정확도는 float16보다 안정적이다.
LayerNorm과 GeLU를 구현한 Scratch code를 PyTorch 기존 구현인 PyTorch class로 바꾼다.- PyTorch의 공식 구현은 C++/CUDA로 최적화되어 있어 더 빠르다.
- Flash Attention을 사용한다.
- FlashAttention은 스트리밍 방식으로 Softmax를 계산하여 메모리 사용을 줄이기 때문에 GPU 메모리 bottleneck을 완화한다.
torch.compile(model)을 사용하면 초반 Iteration 동안 모델 구조를 추적하고 최적화 코드를 생성하는 과정이 수행되어 느리기 때문에 이후 시점에서의 성능을 기록한다.- 즉, 초반 몇 iteration 동안 모델을 추적하고 그래프를 최적화하는 warm-up phase가 있어 느리기 때문에 학습 속도를 제대로 측정하려면 warm-up 이후 시점에서 측정한다.
vocal_size를 64의 배수인 50,304로 늘리면 batch size와 linear layer 차원이 일반적으로 특정 값의 배수로 선택되는 NVIDIA tensor 지침에 따라 성능이 향상된다.- GPU의 Tensor Cores는 특정 차원 정렬(e.g. 64, 128 단위)에 최적화되어 있기 때문에 64배수로 맞추면 성능이 향상된다
- Batch size를 늘린다.
- Multi-GPU인 경우, DDP를 사용하면 훈련이 bottle-neck 되지 않고 성능 향상이 가능하다.
- DistributedDataParallel를 사용하면 GPU 간 통신을 최적화하고, 각 GPU가 독립적으로 gradient를 계산한 후 all-reduce 방식으로 동기화할 수 있기 때문에 매우 빨라진다.
