Chapter 06. Finetuning for Text Classification

https://github.com/rasbt/LLMs-from-scratch/blob/main/ch06/
1. Different categories of finetuning
finetuning 방법에는 대게 instruction-finetuning과 classification finetuning이 있으며, 이번 챕터에서는 classification finetuning에 대해서 다룬다.
- CNN 분류 모델 훈련과 유사한 형태로, instruction-finetuning과는 달리 특수화된 model에 사용되며 특정 task만 수행한다.
2. Preparing the dataset
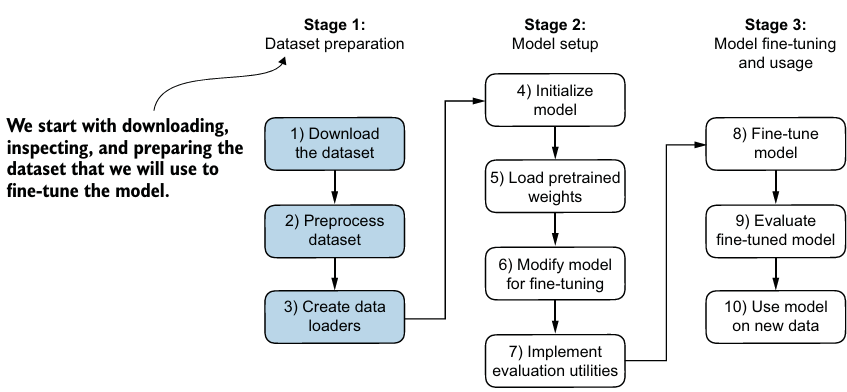
- 데이터셋을 다운받고 pandas DataFrame으로 변환 후, 원하는 크기만큼 데이터를 자르고, training set, test set, validation set으로 나눈다.
3. Creating data loaders
- 데이터셋 문장 별로 길이가 다를 경우, 가장 짧은 text의 길이로 나머지 데이터셋을 자르거나, 가장 긴 text의 길이로 나머지 데이터셋을 패딩 처리해야 한다.
<|endoftext|>토큰으로 패딩 처리를 한다.- test set과 validation set도 동일하게 처리해줘야 하며, training set보다 긴 sequence를 자를지 말지도 선택해줘야 한다.
- Dataloader는 우리가 해왔던 대로 만들어준다.
4. Initializing a model with pretrained weights
- 사전훈련된 GPT-2를 불러온다.
- 텍스트 생성은 잘 이루어지지만, 특히 instruction-finetuned되지 않았고 생성 모델이기 때문에 분류는 잘 이루어지지 않는다.
- 따라서 모델을 수정하고 classification finetuning을 해야 한다.
5. Adding a classification head
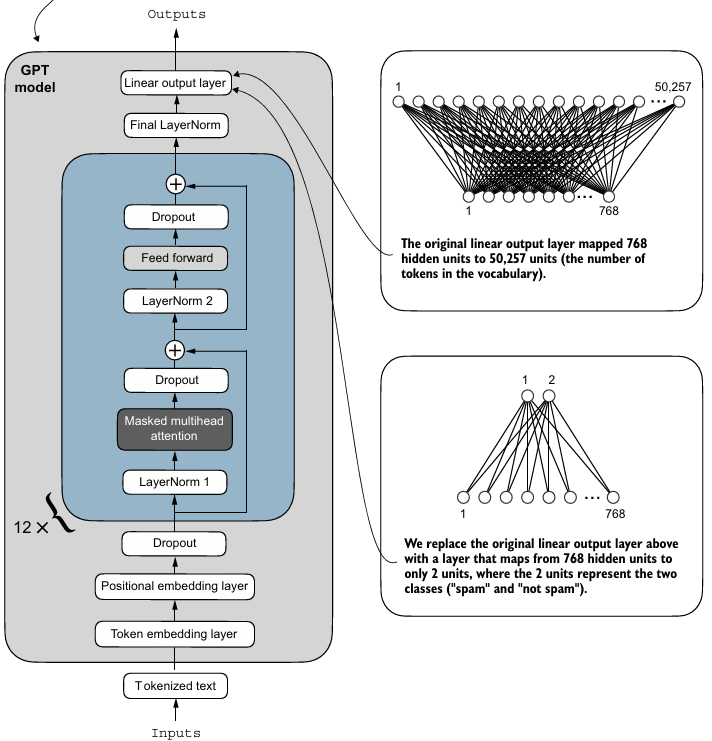
output layer를 교체하고 finetuning 해야한다.
# All layers are freezed to make non-trainable
for param in model.parameters():
param.requires_grad = False
# Change output layer
model.out_head = torch.nn.Linear(in_features=BASE_CONFIG["emb_dim"], out_features=num_classes)- 이로써, finetuning이 가능하게 되었지만 추가적으로 더 나은 성능을 내도록 last transformer block과 final LayerNorm을 trainable하게 만들어준다.
for param in model.trf_blocks[-1].parameters():
param.requires_grad = True
for param in model.final_norm.parameters():
param.requires_grad = True- 이제 output layer 차원은 input token 개수 * class 차원이며, causal attention mask에 의하면 마지막 차원이 이전 토큰들의 정보(attention score)까지 모두 담고 있으므로 이에 집중한다.
6. Calculating the classification loss and accuracy
- output에 softmax를 취하고, argmax로 예측값을 얻는다. softmax는 취하지 않아도 값은 동일하다.
- 아직 finetuning을 하지 않았기 때문에 성능이 좋지 않지만, cross-entropy loss를 손실 함수로 사용한다.
def calc_accuracy_loader(data_loader, model, device, num_batches=None):
model.eval()
correct_predictions, num_examples = 0, 0
if num_batches is None:
num_batches = len(data_loader)
else:
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
input_batch, target_batch = input_batch.to(device), target_batch.to(device)
with torch.no_grad():
logits = model(input_batch)[:, -1, :] # Logits of last output token
predicted_labels = torch.argmax(logits, dim=-1)
num_examples += predicted_labels.shape[0]
correct_predictions += (predicted_labels == target_batch).sum().item()
else:
break
return correct_predictions / num_examples7. Finetuning the model on supervised data
- 훈련 함수는 기존과 유사하지만, 토큰 수 대신 training example의 수를 추적하며, epoch마다 정확도를 계산한다.
- 검증 세트와 학습 세트를 비교하면 학습은 잘 이루어진다는 사실을 알게 된다.
- 하지만, 테스트 세트를 확인하면 검증 세트와 학습 세트에 대해 약간의 과적합이 일어났음을 알 수 있고, 이는 dropout rate나 weight decay를 통해 줄일 수 있다.
def train_classifier_simple(model, train_loader, val_loader, optimizer, device, num_epochs,
eval_freq, eval_iter):
# Initialize lists to track losses and examples seen
train_losses, val_losses, train_accs, val_accs = [], [], [], []
examples_seen, global_step = 0, -1
# Main training loop
for epoch in range(num_epochs):
model.train() # Set model to training mode
for input_batch, target_batch in train_loader:
optimizer.zero_grad() # Reset loss gradients from previous batch iteration
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward() # Calculate loss gradients
optimizer.step() # Update model weights using loss gradients
examples_seen += input_batch.shape[0] # New: track examples instead of tokens
global_step += 1
# Optional evaluation step
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter)
train_losses.append(train_loss)
val_losses.append(val_loss)
print(f"Ep {epoch+1} (Step {global_step:06d}): "
f"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}")
# Calculate accuracy after each epoch
train_accuracy = calc_accuracy_loader(train_loader, model, device, num_batches=eval_iter)
val_accuracy = calc_accuracy_loader(val_loader, model, device, num_batches=eval_iter)
print(f"Training accuracy: {train_accuracy*100:.2f}% | ", end="")
print(f"Validation accuracy: {val_accuracy*100:.2f}%")
train_accs.append(train_accuracy)
val_accs.append(val_accuracy)
return train_losses, val_losses, train_accs, val_accs, examples_seen8. Using the LLM as a spam classifier
- 만들었던 Dataset처럼 토크나이저로 인코딩 후 너무 길면 자르고 아니라면 padding을 한 후 batch 차원을 더하여 모델에 넣는다.
- 모델의 예측값 정수를 labeling한다.
- 이후 모델을 저장하고 load해서 다시 사용한다.
※ Additional Experiments Classifying the Sentiment of 50k IMDB Movie Reviews
Bert
- Bert는 트랜스포머 encoder 기반 양방향 모델이기 때문에 입력의 모든 토큰이 예측 대상이 될 수 있으므로 마지막 토큰만 보지 않고 전체 logit을 본다.
- 또한 패딩된 토큰을 무시하기 위해 Attention mask를 사용한다.
sklearn's LinearRegression
sklearn.feature_extraction.text의CountVectorizer를 통해 토큰화하고 vocabulary을 생성한다.- Bag-of-Words(BoW)를 사용하여 토큰별 등장 횟수를 기반으로 벡터화한다.
- 단어의 위치 정보가 반영되지 않는다.

It’s always white night here.