Chapter 02. Working with text data

교재를 모두 읽는 것이 비효율적이라 여겨, github에 있는 코드 위주로 공부하고 부족한 부분은 교재를 찾아보는 방식으로 변경하였다.
https://github.com/rasbt/LLMs-from-scratch/tree/main/ch02
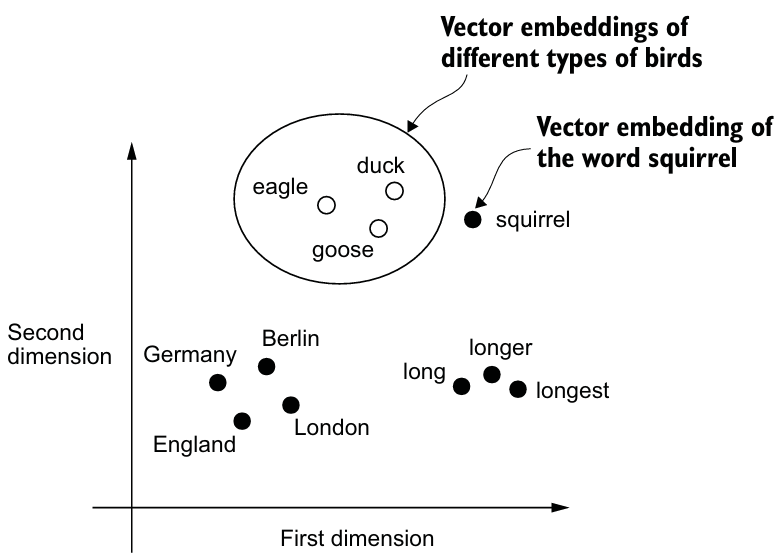
1. Understanding word embeddings
임베딩 중에서도 텍스트 임베딩에 대해서 알아보자.
2. Tokenizing text
텍스트를 구두점이나 단어같은 작은 unit으로 쪼개는 것을 tokenize라고 한다.
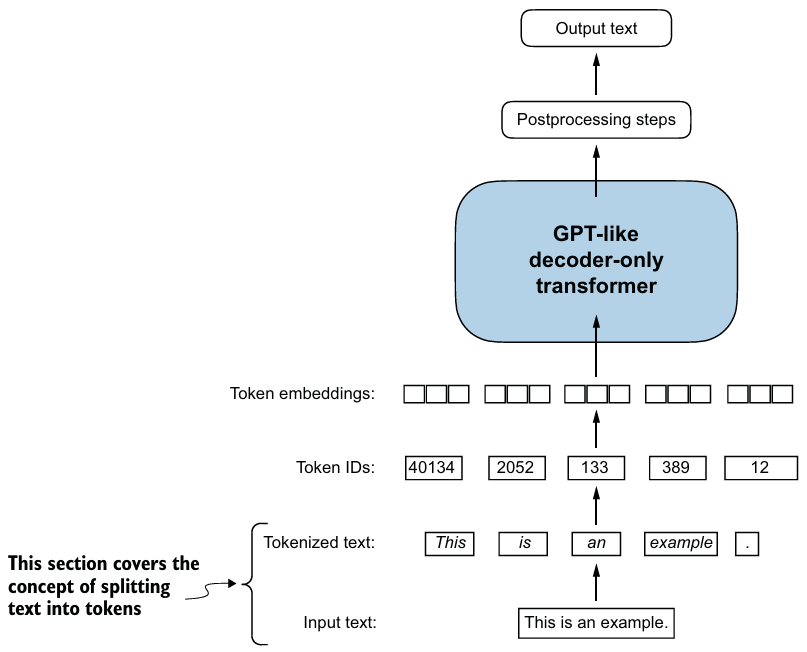
- 아래와 같은 방식으로 다양한 구두점에 대해 정규표현식을 사용하여 토큰화할 수 있다.
import re
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
result = [item.strip() for item in result if item.strip()]3. Converting tokens into token IDs
텍스트 토큰을 나중에 임베딩 레이어를 통해 처리할 수 있는 토큰 ID로 변환한다.
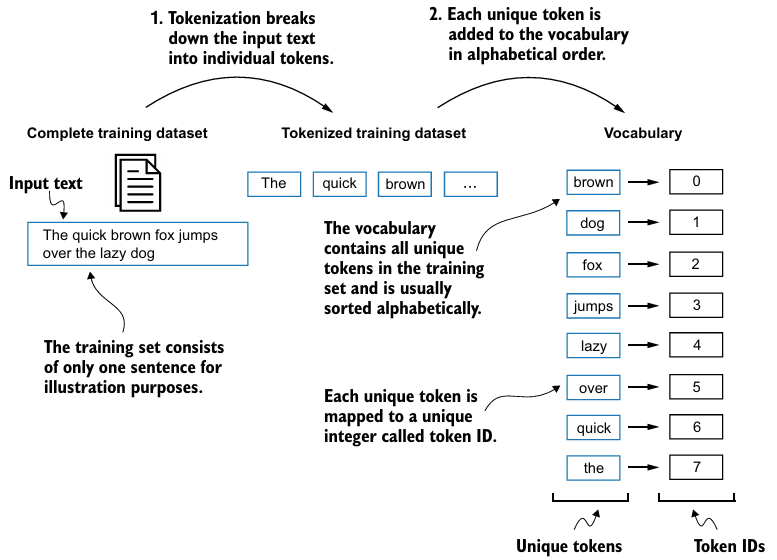
- 유니크한 토큰들(
set()사용)로 vocabulary을 만든다. - 만든 vocabulary로 sample text를 마찬가지로 토큰화하고 vocabulary에 mapping되는 token IDs로 변환한다.
encode()는 input 텍스트를 토큰 IDs 리스트로 변환하고,decode()는 반대 과정을 수행한다.- 인코딩된 정수 리스트는 이후 LLM의 input이 된다.
4. Adding special context tokens
몇몇 토크나이저는 추가적인 맥락을 LLM에 적용하기 위해 특별한 토큰을 사용한다.
- Special Tokens
- BOS(beginning of sequence): 텍스트의 시작
- EOS(end of sequence): 텍스트의 끝, 관련없는 여러 텍스트를 합칠 때 사용한다.
- GPT는 복잡성을 줄이기 위해 <|endoftext|> 외에 다른 특별한 토큰을 사용하지 않는다.
- 훈련 시 mask를 사용하기 때문에, 별 뜻 없이 padding 토큰으로도 사용한다.
- PAD(padding): 모든 텍스트가 같은 길이를 같도록, 짧은 텍스트에 나머지를 채우는 토큰
- UNK(unknown): vocabulary에 없는 단어
- GPT는 BPE(byte-pair encoding)를 사용하기 때문에 사용하지 않는다.
- 각 새로운 토큰을
encode()에 적용한다.
# 코드로 구현한 토크나이저
class SimpleTokenizerV2:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = { i:s for s,i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
preprocessed = [
item if item in self.str_to_int
else "<|unk|>" for item in preprocessed
]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
# Replace spaces before the specified punctuations
text = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text)
return text
tokenizer = SimpleTokenizerV2(vocab)
text = " <|endoftext|> ".join((text1, text2))
tokenizer.encode(text)
tokenizer.decode(tokenizer.encode(text))5. BytePair encoding
vocabulary에 포함되지 않은 단어를 subword 단위나 characters로 분해하여 out-of-vocabulary 단어를 처리할 수 있도록 한다.
- Rust로 짜여진 OpenAI의 오픈소스 tiktoken 라이브러리를 통해 BPE 토크나이저를 사용한다.
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})6. Data sampling with a sliding window
한 번에 하나의 단어를 만들어야 하므로, 시퀀스의 다음 단어가 예측할 대상을 나타낼 때 그에 따라 훈련 데이터를 준비해야 한다.

- target은 input에서 하나 옆으로 이동한 위치에 있다.
context_size를 지정하여 sliding window 방식을 사용할 수 있고, stride의 변화에 따라 overlap되는 word 개수를 지정할 수 있다.

7. Creating token embeddings
임베딩 레이어를 사용하여 토큰을 연속 벡터 표현으로 임베딩해보자.
- 임베딩 레이어는 대게 LLM 내부에 존재하며, 모델 훈련동안 업데이트된다.
- 원-핫 인코딩 이후 행렬 곱셈을 하는 방식보다 더 효율적인 방법이며, 역전파를 통해 최적화가 가능한 layer로 볼 수 있다.
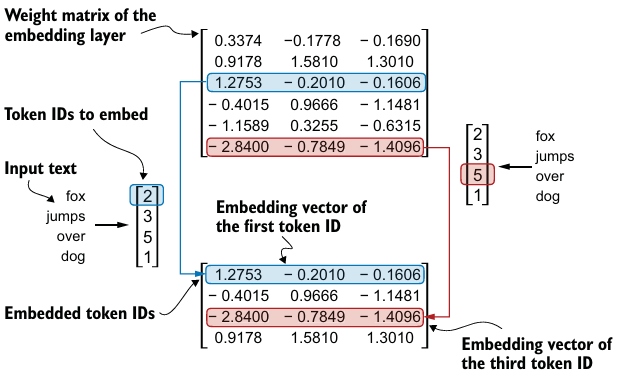
torch.nn.Linear와 행렬 곱셈을 통해서도 임베딩 레이어를 구현할 수 있다.
- 원-핫 인코딩 이후 행렬 곱셈을 하는 방식보다 더 효율적인 방법이며, 역전파를 통해 최적화가 가능한 layer로 볼 수 있다.
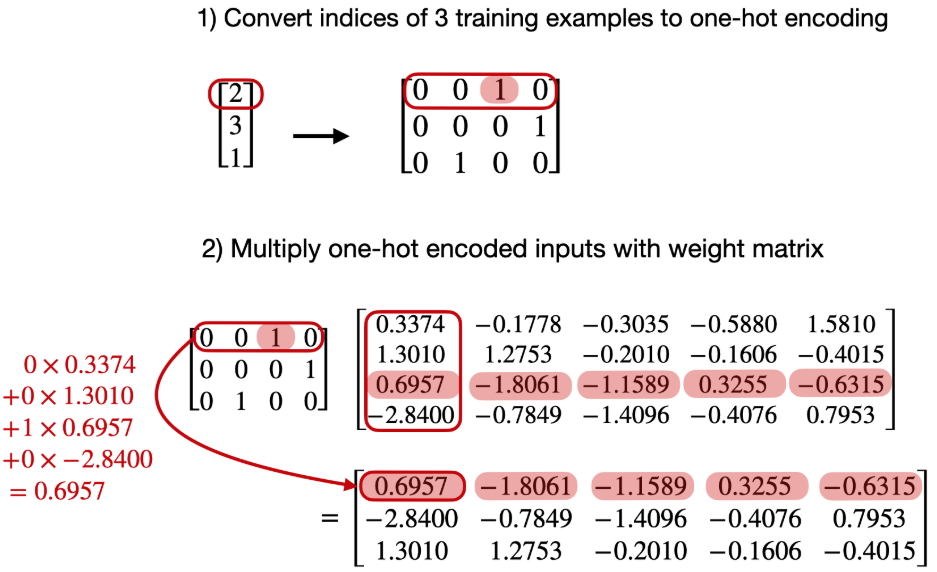
embedding_layer = torch.nn.Embedding(vocab_size, output_dim) # (6, 3)
print(embedding_layer(torch.tensor([2, 3, 5, 1]))
'''
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)
'''8. Encoding word positions
Sequence 내 토큰의 위치에 따라 다른 벡터 표현을 가져야 한다.
vocab_size = 50257
output_dim = 256
token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
max_length = 4
dataloader = create_dataloader_v1(
raw_text, batch_size=8, max_length=max_length,
stride=max_length, shuffle=False
)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
print("Inputs shape: ", inputs.shape)
# torch.Size([8, 4])
token_embeddings = token_embedding_layer(inputs)
print(token_embeddings.shape)
# torch.Size([torch.Size([8, 4, 256])- GPT-2는 absolute position 임베딩을 사용하므로 또다른 임베딩 레이어를 만들기만 하면 된다.
- 즉,
vocab_size를 활용하는 토큰 임베딩과 위치에 따른 가중치를 부여하는 위치 임베딩 layer를 따로 두는 것이다.
- 즉,
- input 임베딩을 만들기 위해 토큰 임베딩과 위치 임베딩을 더한다.
context_length = max_length # 4
pos_embedding_layer = torch.nn.Embedding(context_length, output_dim) # 256
pos_embeddings = pos_embedding_layer(torch.arange(max_length))
print(pos_embeddings.shape)
# torch.Size([4, 256])
※ BPE from scratch
1. The main idea behind BPE
bytearray(text, "utf-8")와ids = list(byte_ary)를 통해 text의 byte 값(character)에 따라 정수로 변환된다.- GPT의 BPE 토크나이저 또한 첫 256개의 토큰을 이 bytearray 값으로 사용한다.
- BPE 과정
- Identify frequent pairs: 가장 자주 등장하는 byte 쌍을 찾는다.
- Replace and record: 해당 쌍을 새 placeholder ID로 대체하고, 이 매핑을 lookup table에 기록한다.
- Repeat until no gains: 새 pair가 등장하지 않을 때까지 반복한다.
- Decompression: 반대로 복원하려면, lookup table의 ID를 해당 pair와 반전시킨다.
2. A simple BPE implementation
from collections import Counter, deque
from functools import lru_cache
import json
class BPETokenizerSimple:
def __init__(self):
# Maps token_id to token_str (e.g., {11246: "some"})
self.vocab = {}
# Maps token_str to token_id (e.g., {"some": 11246})
self.inverse_vocab = {}
# Dictionary of BPE merges: {(token_id1, token_id2): merged_token_id}
self.bpe_merges = {}
def train(self, text, vocab_size, allowed_special={"<|endoftext|>"}):
"""
Train the BPE tokenizer from scratch.
Args:
text (str): The training text.
vocab_size (int): The desired vocabulary size.
allowed_special (set): A set of special tokens to include.
"""
# Preprocess: Replace spaces with 'Ġ'
# Note that Ġ is a particularity of the GPT-2 BPE implementation
# E.g., "Hello world" might be tokenized as ["Hello", "Ġworld"]
# (GPT-4 BPE would tokenize it as ["Hello", " world"])
processed_text = []
for i, char in enumerate(text):
if char == " " and i != 0:
processed_text.append("Ġ")
if char != " ":
processed_text.append(char)
processed_text = "".join(processed_text)
# Initialize vocab with unique characters, including 'Ġ' if present
# Start with the first 256 ASCII characters
unique_chars = [chr(i) for i in range(256)]
# Extend unique_chars with characters from processed_text that are not already included
unique_chars.extend(char for char in sorted(set(processed_text)) if char not in unique_chars)
# Optionally, ensure 'Ġ' is included if it is relevant to your text processing
if "Ġ" not in unique_chars:
unique_chars.append("Ġ")
# Now create the vocab and inverse vocab dictionaries
self.vocab = {i: char for i, char in enumerate(unique_chars)}
self.inverse_vocab = {char: i for i, char in self.vocab.items()}
# Add allowed special tokens
if allowed_special:
for token in allowed_special:
if token not in self.inverse_vocab:
new_id = len(self.vocab)
self.vocab[new_id] = token
self.inverse_vocab[token] = new_id
# Tokenize the processed_text into token IDs
token_ids = [self.inverse_vocab[char] for char in processed_text]
# BPE steps 1-3: Repeatedly find and replace frequent pairs
for new_id in range(len(self.vocab), vocab_size):
pair_id = self.find_freq_pair(token_ids, mode="most")
if pair_id is None: # No more pairs to merge. Stopping training.
break
token_ids = self.replace_pair(token_ids, pair_id, new_id)
self.bpe_merges[pair_id] = new_id
# Build the vocabulary with merged tokens
for (p0, p1), new_id in self.bpe_merges.items():
merged_token = self.vocab[p0] + self.vocab[p1]
self.vocab[new_id] = merged_token
self.inverse_vocab[merged_token] = new_id
def load_vocab_and_merges_from_openai(self, vocab_path, bpe_merges_path):
"""
Load pre-trained vocabulary and BPE merges from OpenAI's GPT-2 files.
Args:
vocab_path (str): Path to the vocab file (GPT-2 calls it 'encoder.json').
bpe_merges_path (str): Path to the bpe_merges file (GPT-2 calls it 'vocab.bpe').
"""
# Load vocabulary
with open(vocab_path, "r", encoding="utf-8") as file:
loaded_vocab = json.load(file)
# Convert loaded vocabulary to correct format
self.vocab = {int(v): k for k, v in loaded_vocab.items()}
self.inverse_vocab = {k: int(v) for k, v in loaded_vocab.items()}
# Handle newline character without adding a new token
if "\n" not in self.inverse_vocab:
# Use an existing token ID as a placeholder for '\n'
# Preferentially use "<|endoftext|>" if available
fallback_token = next((token for token in ["<|endoftext|>", "Ġ", ""] if token in self.inverse_vocab), None)
if fallback_token is not None:
newline_token_id = self.inverse_vocab[fallback_token]
else:
# If no fallback token is available, raise an error
raise KeyError("No suitable token found in vocabulary to map '\\n'.")
self.inverse_vocab["\n"] = newline_token_id
self.vocab[newline_token_id] = "\n"
# Load BPE merges
with open(bpe_merges_path, "r", encoding="utf-8") as file:
lines = file.readlines()
# Skip header line if present
if lines and lines[0].startswith("#"):
lines = lines[1:]
for rank, line in enumerate(lines):
pair = tuple(line.strip().split())
if len(pair) == 2:
token1, token2 = pair
if token1 in self.inverse_vocab and token2 in self.inverse_vocab:
token_id1 = self.inverse_vocab[token1]
token_id2 = self.inverse_vocab[token2]
merged_token = token1 + token2
if merged_token in self.inverse_vocab:
merged_token_id = self.inverse_vocab[merged_token]
self.bpe_merges[(token_id1, token_id2)] = merged_token_id
# print(f"Loaded merge: '{token1}' + '{token2}' -> '{merged_token}' (ID: {merged_token_id})")
else:
print(f"Merged token '{merged_token}' not found in vocab. Skipping.")
else:
print(f"Skipping pair {pair} as one of the tokens is not in the vocabulary.")
def encode(self, text):
"""
Encode the input text into a list of token IDs.
Args:
text (str): The text to encode.
Returns:
List[int]: The list of token IDs.
"""
tokens = []
# First split on newlines to preserve them
lines = text.split("\n")
for i, line in enumerate(lines):
if i > 0:
tokens.append("\n") # Add newline token separately
words = line.split()
for j, word in enumerate(words):
if j == 0:
if i > 0: # Start of a new line but not the first line
tokens.append("Ġ" + word) # Ensure it's marked as a new segment
else:
tokens.append(word)
else:
# Prefix words in the middle of a line with 'Ġ'
tokens.append("Ġ" + word)
token_ids = []
for token in tokens:
if token in self.inverse_vocab:
# token is contained in the vocabulary as is
token_ids.append(self.inverse_vocab[token])
else:
# Attempt to handle subword tokenization via BPE
sub_token_ids = self.tokenize_with_bpe(token)
token_ids.extend(sub_token_ids)
return token_ids
def tokenize_with_bpe(self, token):
"""
Tokenize a single token using BPE merges.
Args:
token (str): The token to tokenize.
Returns:
List[int]: The list of token IDs after applying BPE.
"""
# Tokenize the token into individual characters (as initial token IDs)
token_ids = [self.inverse_vocab.get(char, None) for char in token]
if None in token_ids:
missing_chars = [char for char, tid in zip(token, token_ids) if tid is None]
raise ValueError(f"Characters not found in vocab: {missing_chars}")
can_merge = True
while can_merge and len(token_ids) > 1:
can_merge = False
new_tokens = []
i = 0
while i < len(token_ids) - 1:
pair = (token_ids[i], token_ids[i + 1])
if pair in self.bpe_merges:
merged_token_id = self.bpe_merges[pair]
new_tokens.append(merged_token_id)
# Uncomment for educational purposes:
# print(f"Merged pair {pair} -> {merged_token_id} ('{self.vocab[merged_token_id]}')")
i += 2 # Skip the next token as it's merged
can_merge = True
else:
new_tokens.append(token_ids[i])
i += 1
if i < len(token_ids):
new_tokens.append(token_ids[i])
token_ids = new_tokens
return token_ids
def decode(self, token_ids):
"""
Decode a list of token IDs back into a string.
Args:
token_ids (List[int]): The list of token IDs to decode.
Returns:
str: The decoded string.
"""
decoded_string = ""
for i, token_id in enumerate(token_ids):
if token_id not in self.vocab:
raise ValueError(f"Token ID {token_id} not found in vocab.")
token = self.vocab[token_id]
if token == "\n":
if decoded_string and not decoded_string.endswith(" "):
decoded_string += " " # Add space if not present before a newline
decoded_string += token
elif token.startswith("Ġ"):
decoded_string += " " + token[1:]
else:
decoded_string += token
return decoded_string
def save_vocab_and_merges(self, vocab_path, bpe_merges_path):
"""
Save the vocabulary and BPE merges to JSON files.
Args:
vocab_path (str): Path to save the vocabulary.
bpe_merges_path (str): Path to save the BPE merges.
"""
# Save vocabulary
with open(vocab_path, "w", encoding="utf-8") as file:
json.dump({k: v for k, v in self.vocab.items()}, file, ensure_ascii=False, indent=2)
# Save BPE merges as a list of dictionaries
with open(bpe_merges_path, "w", encoding="utf-8") as file:
merges_list = [{"pair": list(pair), "new_id": new_id}
for pair, new_id in self.bpe_merges.items()]
json.dump(merges_list, file, ensure_ascii=False, indent=2)
def load_vocab_and_merges(self, vocab_path, bpe_merges_path):
"""
Load the vocabulary and BPE merges from JSON files.
Args:
vocab_path (str): Path to the vocabulary file.
bpe_merges_path (str): Path to the BPE merges file.
"""
# Load vocabulary
with open(vocab_path, "r", encoding="utf-8") as file:
loaded_vocab = json.load(file)
self.vocab = {int(k): v for k, v in loaded_vocab.items()}
self.inverse_vocab = {v: int(k) for k, v in loaded_vocab.items()}
# Load BPE merges
with open(bpe_merges_path, "r", encoding="utf-8") as file:
merges_list = json.load(file)
for merge in merges_list:
pair = tuple(merge["pair"])
new_id = merge["new_id"]
self.bpe_merges[pair] = new_id
@lru_cache(maxsize=None)
def get_special_token_id(self, token):
return self.inverse_vocab.get(token, None)
@staticmethod
def find_freq_pair(token_ids, mode="most"):
pairs = Counter(zip(token_ids, token_ids[1:]))
if mode == "most":
return max(pairs.items(), key=lambda x: x[1])[0]
elif mode == "least":
return min(pairs.items(), key=lambda x: x[1])[0]
else:
raise ValueError("Invalid mode. Choose 'most' or 'least'.")
@staticmethod
def replace_pair(token_ids, pair_id, new_id):
dq = deque(token_ids)
replaced = []
while dq:
current = dq.popleft()
if dq and (current, dq[0]) == pair_id:
replaced.append(new_id)
# Remove the 2nd token of the pair, 1st was already removed
dq.popleft()
else:
replaced.append(current)
return replacedtrain- 새로운 텍스트 데이터를 바탕으로 BPE 토크나이저를 처음 학습시킬 때 사용한다.
- 입력 텍스트의 공백 문자를 GPT-2 스타일에 맞게
Ġ로 대체한다. - 256 ASCII 문자와, 전처리된 텍스트에서 등장하는 추가 문자와 special tokens을 추가한 후, BPE 과정을 거친다.
load_vocab_and_merges_from_openai- 이미 학습된 GPT-2 모델의 vocab과 BPE 병합 규칙을 사용하여 토크나이저를 초기화하고자 할 때 사용한다.
- vocab을 load하고
'\n'에 대해 추가한다. bpe_merges_path파일을 줄 단위로 읽어서, 두 개의 토큰(문자열)을 분리한 후, 두 토큰 문자열을 이어붙인 문자열의 토큰 ID를 찾아self.bpe_merges에 저장한다.
encode- 모델의 입력으로 사용할 텍스트를 전처리하여 토큰 ID 리스트로 변환할 때 사용한다.
- 텍스트를 라인별로 분리하고, 단어 단위 처리를 한 후, 만약 완성된 토큰이
self.inverse_vocab에 존재하지 않으면tokenize_with_bpemethod를 호출하여 서브워드 단위로 분할하고, 그에 따른 토큰 ID들을 반환받는다.
tokenize_with_bpe- 완전한 단어 토큰이 vocab에 없을 때, 해당 단어를 가능한 서브워드 단위로 분해해 인코딩할 때 사용
- 입력된 토큰을 개별 문자 단위로 분해한 후
self.inverse_vocab을 사용해 해당하는 토큰 ID로 변환한다. - 토큰 ID 리스트에서 인접한 토큰 쌍을 검사하고, 만약 그 쌍이
self.bpe_merges에 존재한다면 해당 쌍을 새로운 토큰 ID로 병합한다.
save_vocab_and_merges & load_vocab_and_merges- 현재까지 학습되거나 설정된 vocab과 BPE 병합 규칙을 JSON 파일로 저장하거나 불러와서 토크나이저를 복원한다.
get_special_token_id- 특별 토큰(예: <|endoftext|>)의 ID를 자주 조회해야 하는 경우, 빠른 액세스를 위해 사용한다.
@lru_cache데코레이터를 사용하여 같은 토큰에 대한 조회 결과를 캐시하므로, 반복 호출 시 성능을 개선한다.
find_freq_pair- 주어진 토큰 ID 리스트에서 인접한 토큰 쌍들의 등장 빈도를 계산하고, 자주 등장하는 쌍을 찾는다.
@staticmethod는 클래스 내부에서 정의되지만, 클래스나 인스턴스의 속성(self)을 사용하지 않는 메서드를 정의할 때 사용한다.
replace_pair- BPE 학습 과정에서
find_freq_pair로 선택된 토큰 쌍을 실제로 병합할 때 호출한다. - 주어진 토큰 ID 리스트에서 특정 인접 토큰 쌍(
pair_id)을 찾아, 이를 새 토큰 ID(new_id)로 병합한다.
- BPE 학습 과정에서
3. BPE implementation walkthrough
# 토크나이저 훈련 & 인코딩 & 디코딩
tokenizer.train(text, vocab_size=1000, allowed_special={"<|endoftext|>"})
token_ids = tokenizer.encode(input_text)
original_input_text = tokenizer.decode(token_ids)
# 토크나이저 저장 및 로드
tokenizer.save_vocab_and_merges(vocab_path="vocab.json", bpe_merges_path="bpe_merges.txt")
tokenizer.load_vocab_and_merges(vocab_path="vocab.json", bpe_merges_path="bpe_merges.txt")
It’s always white night here.