1. 지역 최적값 문제
Local optima in neural networks
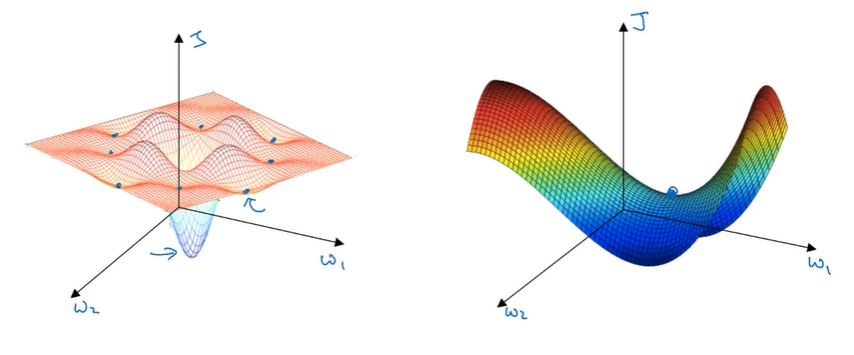
- 고차원 비용함수에서 경사가 0인 경우는 대부분 지역 최적값이 아니라 대개 안장점
- 말 안장과 비슷해서 안장점
- 왼쪽 그림처럼 낮은 차원의 공간에서 얻었던 직관이 학습 알고리즘이 높은 차원에서 돌아갈 때 적용되지 않을 수 있음
Problem of plateaus
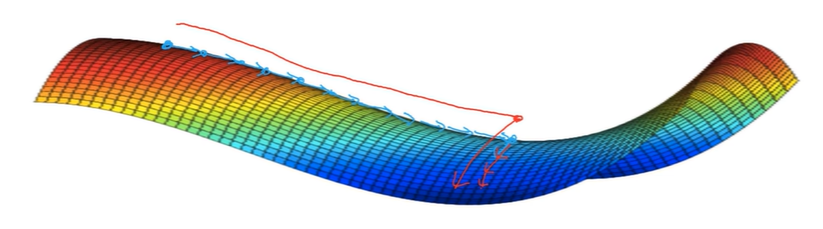
- 문제점: 안정 지대가 학습을 아주 지연시킬 수 있음
- 안정 지대: 미분값이 아주 오랫동안 0에 가깝게 유지되는 지역
- 왼쪽이나 오른쪽에 무작위로 작은 변화가 주어지면 알고리즘이 안정 지대를 벗어날 수 있음
- 모멘텀, RMSprop, Adam 등의 알고리즘의 도움을 받을 수 있음
- 충분히 큰 신경망을 학습시킨다면 지역 최적값에 갇힐 일이 잘 없음
- 하지만 안정지대는 문제
2. Tensorflow
Motivating problem
J(w)=w^2-10w+25=(w-5)^2
TensorFlow 1.0
import numpy as np
import tensorflow as tf
coefficients=np.array([[1.],[-20.],[100.]])
w=tf.Variable(0,dtype=tf.float32)
x=tf.placeholder(tf.float32,[3,1])
#비용함수 정의
#cost=tf.add(tf.add(w**2,tf.multiply(-10.,w)),25)
#cost=w**2-10*w+25
cost=x[0][0]*w**2+x[1][0]*w+x[2][0]
train=tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init=tf.global_variables_initializer()
session=tf.Session()
session.run(init)
print(session.run(w))
session.run(train)
print(session.run(w))
for i in range(1000):
session.run(train)
print(session.run(w))TensorFlow 2.0
import numpy as np
import tensorflow as tf
coefficients=np.array([[1.],[-20],[100]])
w=tf.Variable(0,dtype=tf.float32)
x=tf.Variable(coefficients, dtype=tf.float32)
def cost_function():
return x[0][0]*w**2+x[1][0]*w+x[2][0]
optimizer=tf.optimizers.SGD(0.01)
optimizer.minimize(cost_function,var_list=[w])
print(w.numpy())해당글은 부스트코스의 [딥러닝 2단계] 8. 프로그래밍 프레임워크 소개 강의를 듣고 작성한 글입니다.
