네트워크 분석은 빅데이터 분석의 기본 테크닉 중 하나로, 연결망을 통해 데이터의 관계를 파악하고 중심이 되는 데이터를 찾아내는 기법입니다. 가장 기본적으로 사람들 간의 네트워크를 분석할 수도 있으나, 단어, 웹사이트, 국가 등 관계를 보려고 하는 분석이라면 무궁무진하게 활용할 수 있습니다.
그중에서도 오늘은 imdb 영화 관련 데이터를 통해 같은 작품에 출연한 배우들의 네트워크를 만들어보고, 서로 다 연결이 되어 있는지, 누가 가장 인싸일지 보도록 하겠습니다.

1. 패키지 설치
우선 필요한 패키지를 먼저 설치해주겠습니다. 기본적인 패키지는 있다고 가정하고, 새로 사용하는 패키지 두개를 설치하겠습니다.networkx는 네트워크 분석 패키지이고, pyvis는 동적 시각화 패키지입니다.
! pip install networkx
! pip install pyvis2. 데이터 준비
2.1. 데이터 다운로드
imdb에서는 데이터셋을 제공하고 있습니다. 압축파일을 다운로드 받을 수 있으며, 압축을 풀면 tsv 파일이 있습니다. imdb(https://www.imdb.com/interfaces/)에 있는 설명을 보고 필요한 데이터를 다운로드 받으면 되는데, 이번 분석에서는 "title.akas.tsv.gz"를 제외하고는 모두 다운로드 받습니다.
다운로드 받은 후에는 데이터프레임으로 로드해줍니다.
import pandas as pd
# 인물정보
name_info = pd.read_csv('/Users/imare-solis/Downloads/name.basics.tsv', sep='\t')
name_info.head()
# 작품 별 제작진/출연진
# 출연진은 상위 10명까지만 나옴
principal = pd.read_csv('/Users/imare-solis/Downloads/title.principals.tsv', sep='\t')
principal.head()
# 작품 기본 정보
title_info = pd.read_csv('/Users/imare-solis/Downloads/title.basics.tsv', sep='\t')
title_info.head()
# 별점
rating = pd.read_csv('/Users/imare-solis/Downloads/title.ratings.tsv', sep='\t')
rating.head()
2.2. 데이터 병합
데이터가 로드되었다면 필요한 데이터셋을 구성하기 위해 데이터를 병합합니다. 우리는 타이틀에 관한 정보와 별점, 그 타이틀에 등장한 주연 배우, 그 주연 배우에 관한 정보가 필요하므로, 네 개의 데이터셋으로 하나의 통합된 데이터셋을 만들겠습니다.
title_crew = principal.merge(name_info, how='inner', on='nconst')
actors = title_crew.loc[(title_crew['category'] == 'actor') | (title_crew['category'] == 'actress')]
actors = actors.merge(title_info, how='inner', on='tconst')
actors = actors.merge(rating, how='inner', on='tconst')
actors.head()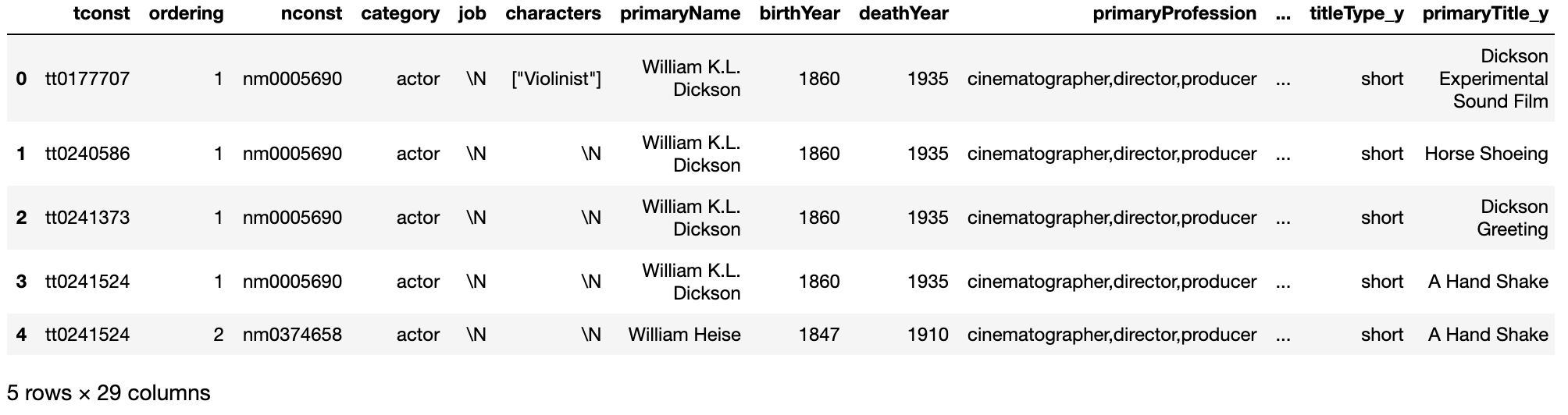
2.3. 데이터 확인
나중에 처음부터 돌릴 때 위의 과정을 생략할 수 있도록 데이터를 csv 파일로 따로 저장해주고 csv 파일로 다시 로드해줍니다. 데이터가 커서 저장하고 로드하는데 시간이 좀 걸리네요.
actors.to_csv('actors.csv')
actors = pd.read_csv('actors.csv')
actors.info()데이터 정보를 보니 몇가지 변환 사항이 보입니다. 필요없는 칼럼을 삭제하고, 데이터 타입을 변환해줍니다.
import numpy as np
actors = actors.drop(columns='Unnamed: 0')
actors['startYear_y'] = actors['startYear_y'].replace('\\N', np.nan)
actors['startYear_y'] = actors['startYear_y'].astype(float)
actors.info()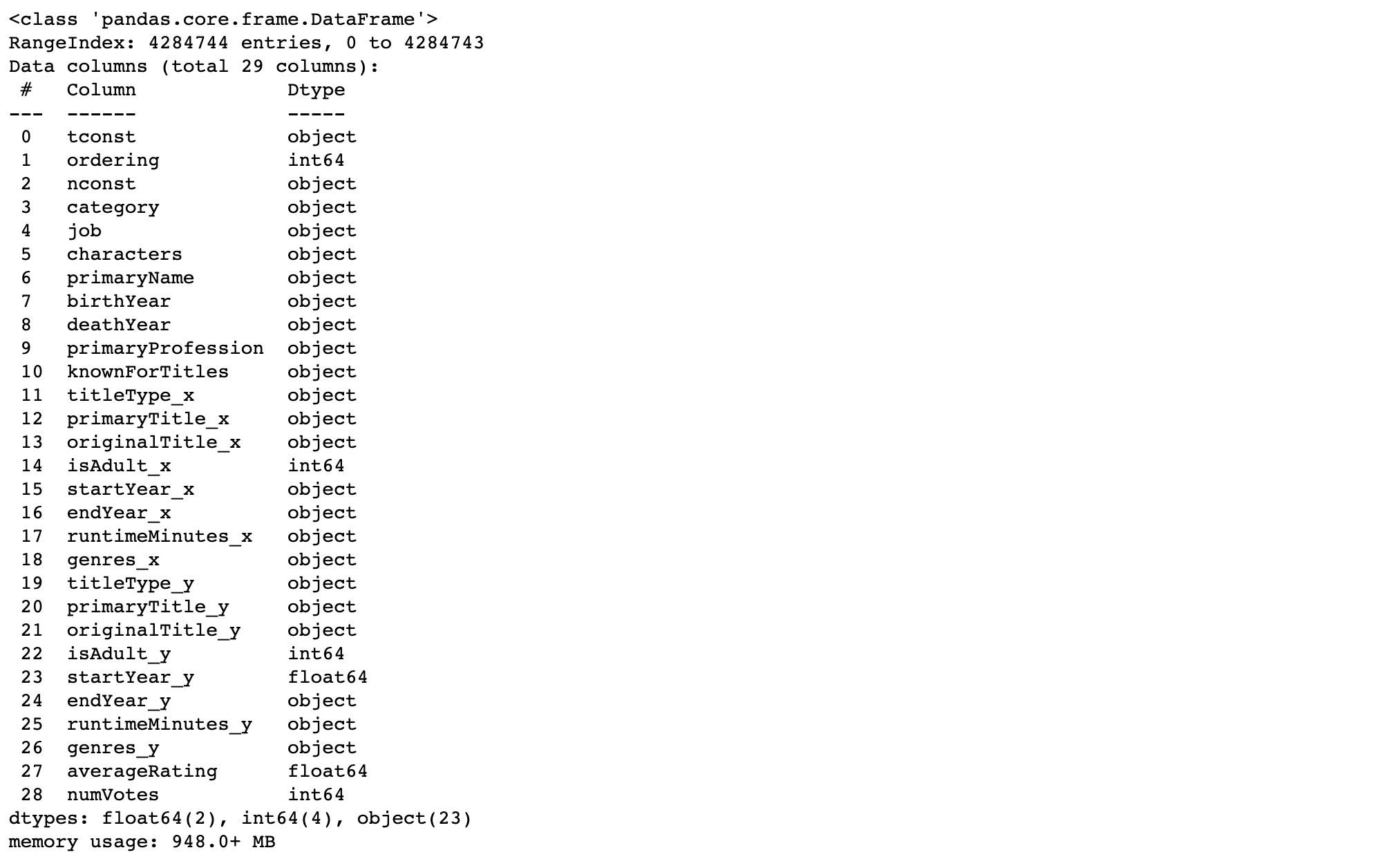
2.4. 데이터 전처리
네트워크 분석에 맞도록 데이터를 선정해야 합니다. 먼저 현재의 데이터는 너무 크니까 2021년 데이터만 사용하도록 하겠습니다. 콘텐츠의 형태는 영화와 tv 시리즈로만으로 제한하고, 별점 평가 수가 2000건이 넘는 콘텐츠만 보겠습니다.
actors_2021 = actors.loc[(actors['startYear_y'] == 2021)
& ((actors['titleType_y'] == 'movie')
| (actors['titleType_y'] == 'tvSeries'))
& (actors['numVotes'] > 2000)].dropna()이 과정이 끝나면 배우 이름을 제외하고 다른 데이터는 필요가 없으므로, 타이틀 아이디(tconst)와 배우 이름(primaryName)만 있는 데이터프레임을 사용하겠습니다. 그래도 데이터가 너무 많으므로 2021년에 출연작이 하나인 배우는 삭제하겠습니다.
actors_2021 = actors_2021.loc[:, actors_2021.columns.intersection(['tconst','primaryName'])]
actors_2021['primaryName'] = actors_2021['primaryName'].str.replace(',', '')
actors_2021['counts'] = actors_2021.groupby(['primaryName']).transform('count')3. 네트워크 분석
3.1. 네트워크 분석 데이터셋
다음에는 네트워크 분석을 위해 데이터 형태를 변행해줘야 합니다. 현재는 한 타이틀에 여러 출연자가 있을 경우 여러 개의 레코드가 만들어져 있습니다. 이것을 groupby로 타이틀 하나 당 출연진의 리스트가 만들어지도록 하겠습니다. 그러면 중복된 타이틀이 없겠죠!
actors_2021_join = actors_2021.groupby(['tconst'])['primaryName'].apply(list).reset_index()
actors_2021_join
다음에는 네트워크 분석에 사용될 수 있도록 변형해줘야 합니다. 네트워크 분석에 사용되는 데이터프레임에는 'source', 'target', 'weight'가 있어야 합니다. 'source'가 되는 배우, 'target'이 되는 배우, 그리고 그 조합이 얼마나 발생했는지에 따른 'weight'으로 구성됩니다. 원래 'source'와 'target'에는 방향성의 의미가 있지만 이번과 같은 분석에서는 방향성이 필요하지 않습니다. 'source'와 'target'은 하나씩밖에 지정되지 않으므로, 저희는 같은 작품에 출연한 배우들에서 2인으로 구성된 모든 조합을 구해야 합니다.
from itertools import combinations
actors_2021_join['primaryName'] = actors_2021_join['primaryName'].apply(lambda l: list(combinations(l, 2)))
actors_2021_join = actors_2021_join.explode('primaryName').dropna()
actors_2021_join.head()
nt = pd.DataFrame(actors_2021_join['primaryName'].to_list(), columns=['source','target'])
nt
3.2. 네트워크 분석 실행
데이터 준비가 모두 끝났으면 네트워크 분석을 실행해보겠습니다. 위에서 만든 데이터셋을 networkx에서 그래프로 바꿔줍니다.
import networkx as nx
nt['weight'] = nt.groupby(['source', 'target'])['source'].transform('size')
nt = nt.dropna()
G = nx.from_pandas_edgelist(nt, 'source', 'target',
create_using=nx.DiGraph(), edge_attr='weight')
nt
이제 최종! 네트워크 시각화를 해주고 파일로 저장합니다. 시각화 결과는 주피터 노트북 상에도 나오고 파일로도 저장됩니다.
from pyvis.network import Network
net = Network(notebook=True)
net.from_nx(G)
net.show_buttons(filter_=['nodes'])
net.show('example3.html')4. 결과 해석
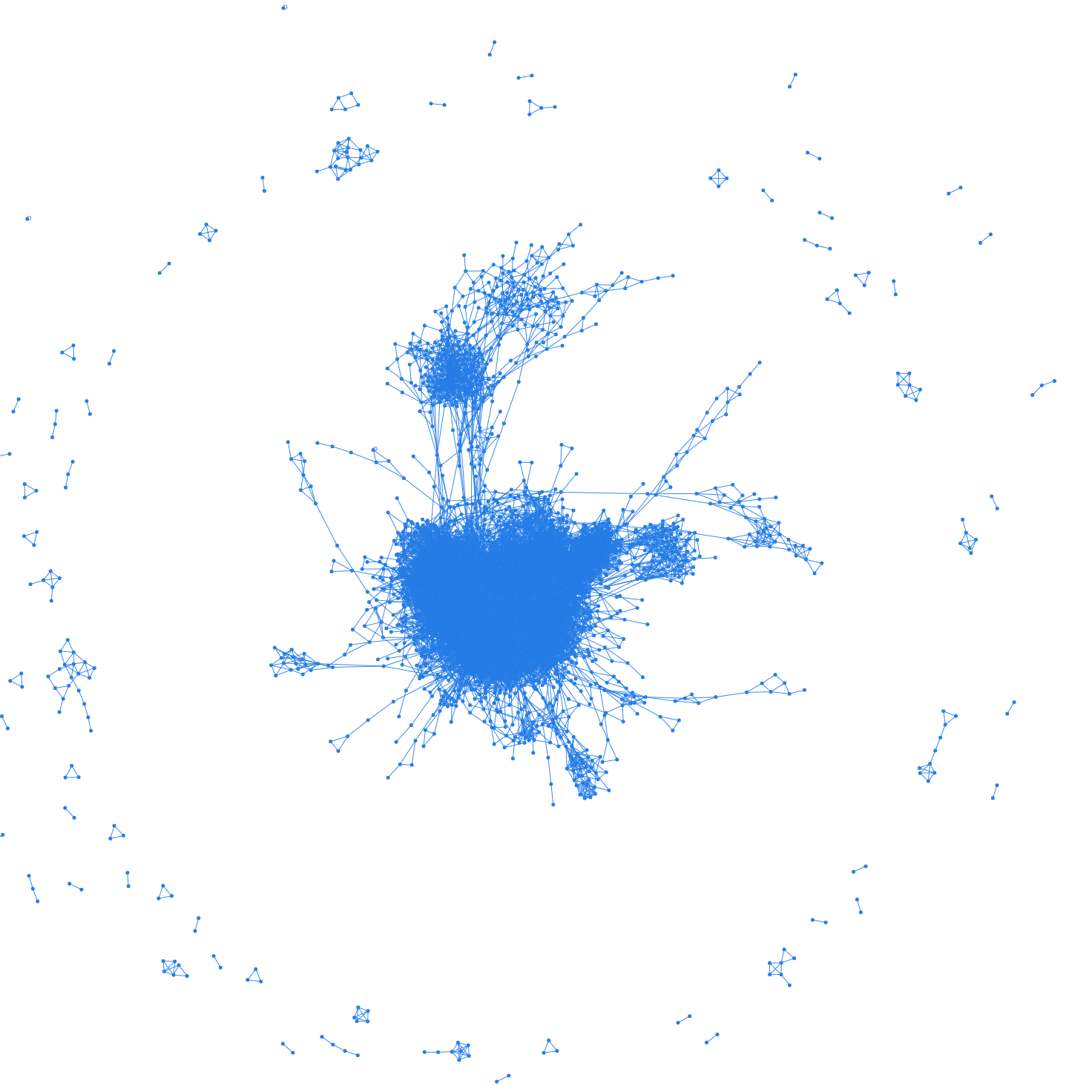
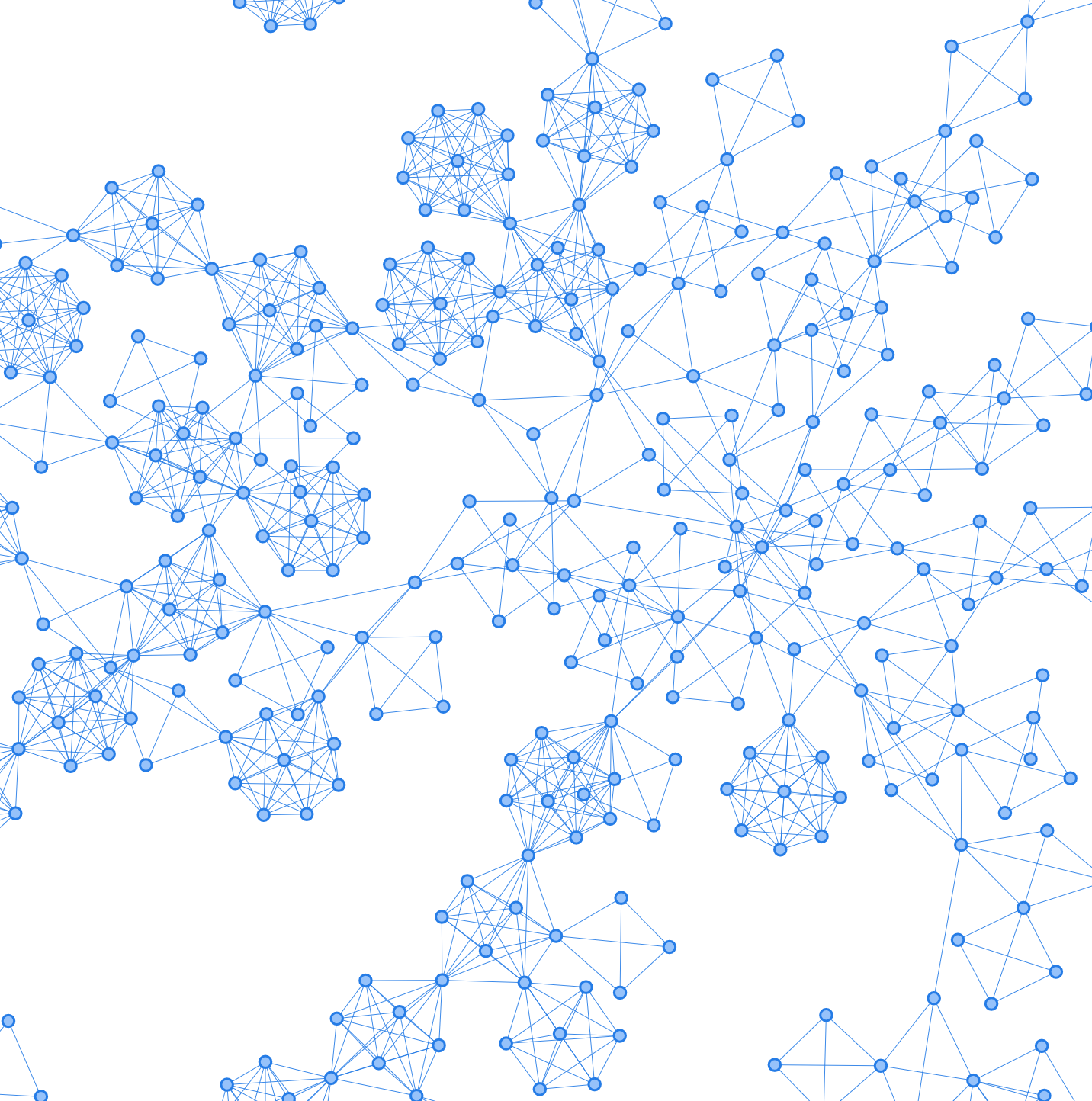
마치 밤하늘 같은 아름다운 모양이 나왔습니다 🤣

좀 더 자세히 들여다 보자면, 지엽적으로 별처럼 떠있는 모양들은 주로 같은 TV 드라마에 출연한 배우들입니다.
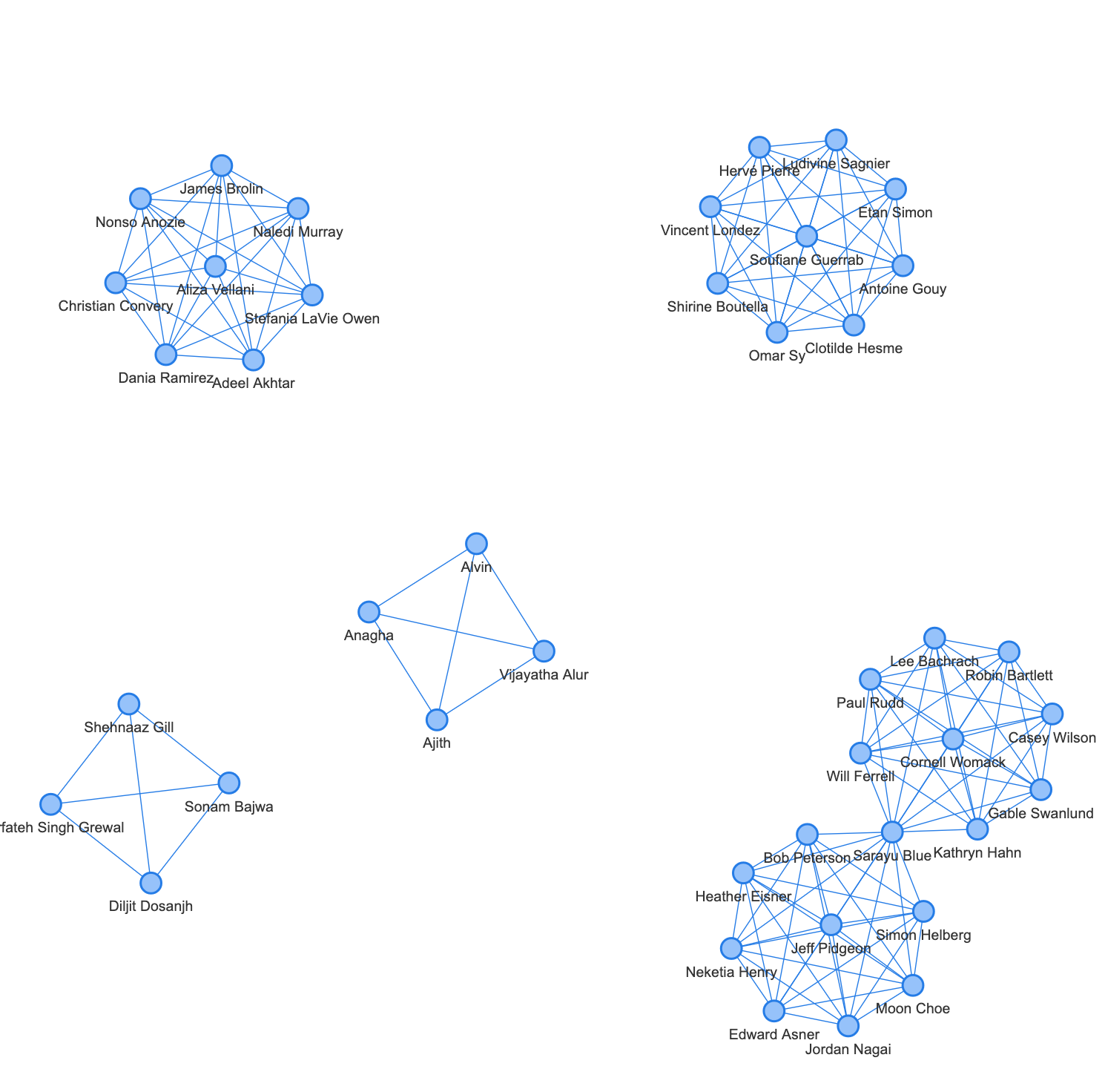
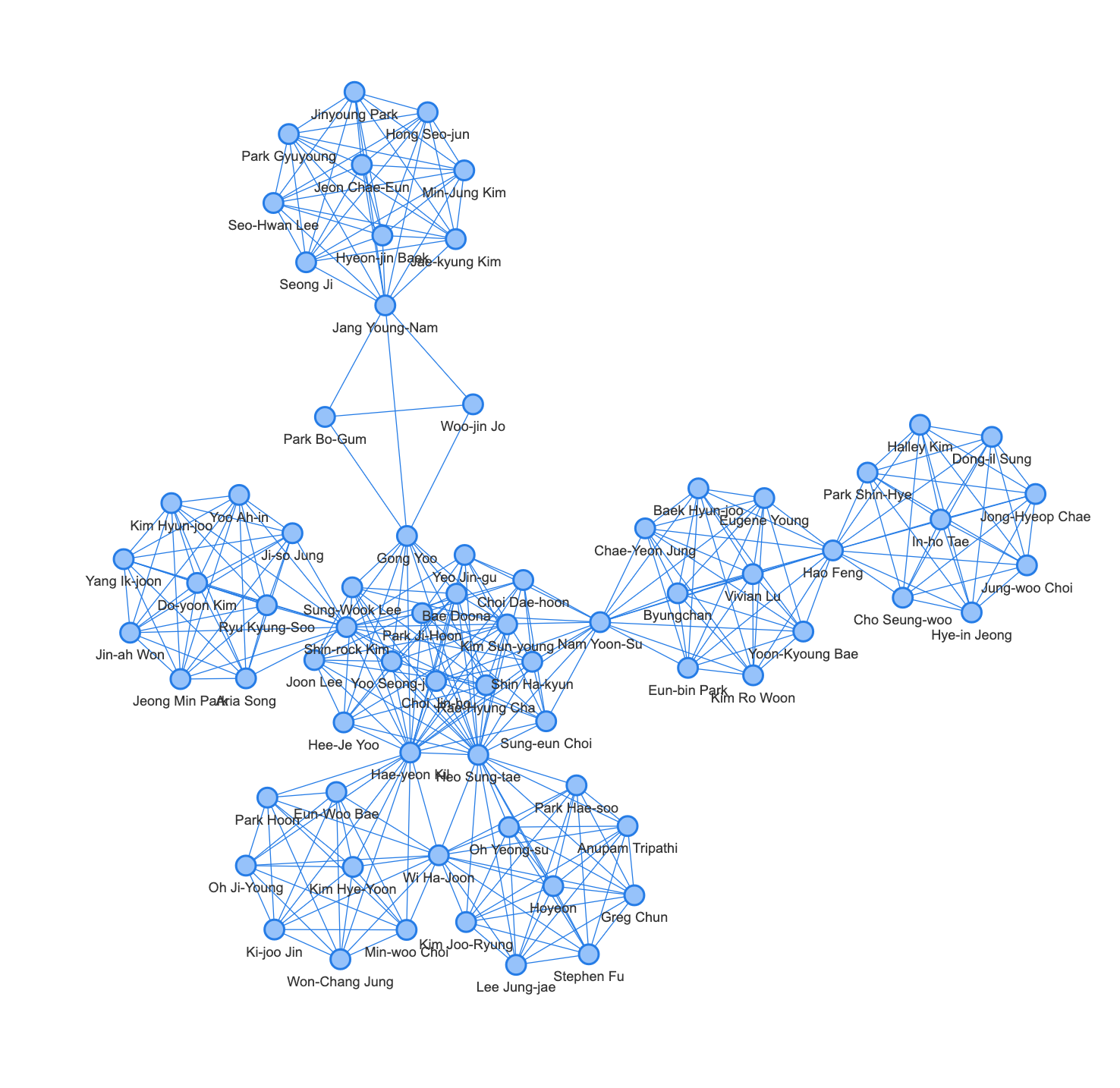
또 국가 별로 네트워크가 형성되는 것도 볼 수 있습니다. 아래는 한국 배우들의 네트워크네요. 따로 분리가 되어있는 것으로 보아, 2021년에 한국 작품을 했으면서 해외 배우와 같은 작품을 한 한국 배우는 없나 봅니다.
가장 중앙을 보면, 할리우드의 거대한 네트워크를 확인할 수 있습니다. 할리우드 배우들은 다른 영화 배우들과 활발히 연결되는 한편, 몇몇 인물을 중심으로 TV 배우들과도 연결이 되어 있는 것을 볼 수 있습니다.
관계망의 중심이 되는 영향력 있는 인물들을 파악해보도록 하겠습니다. 다작을 하는 조연배우들의 활약이 두드러지네요.
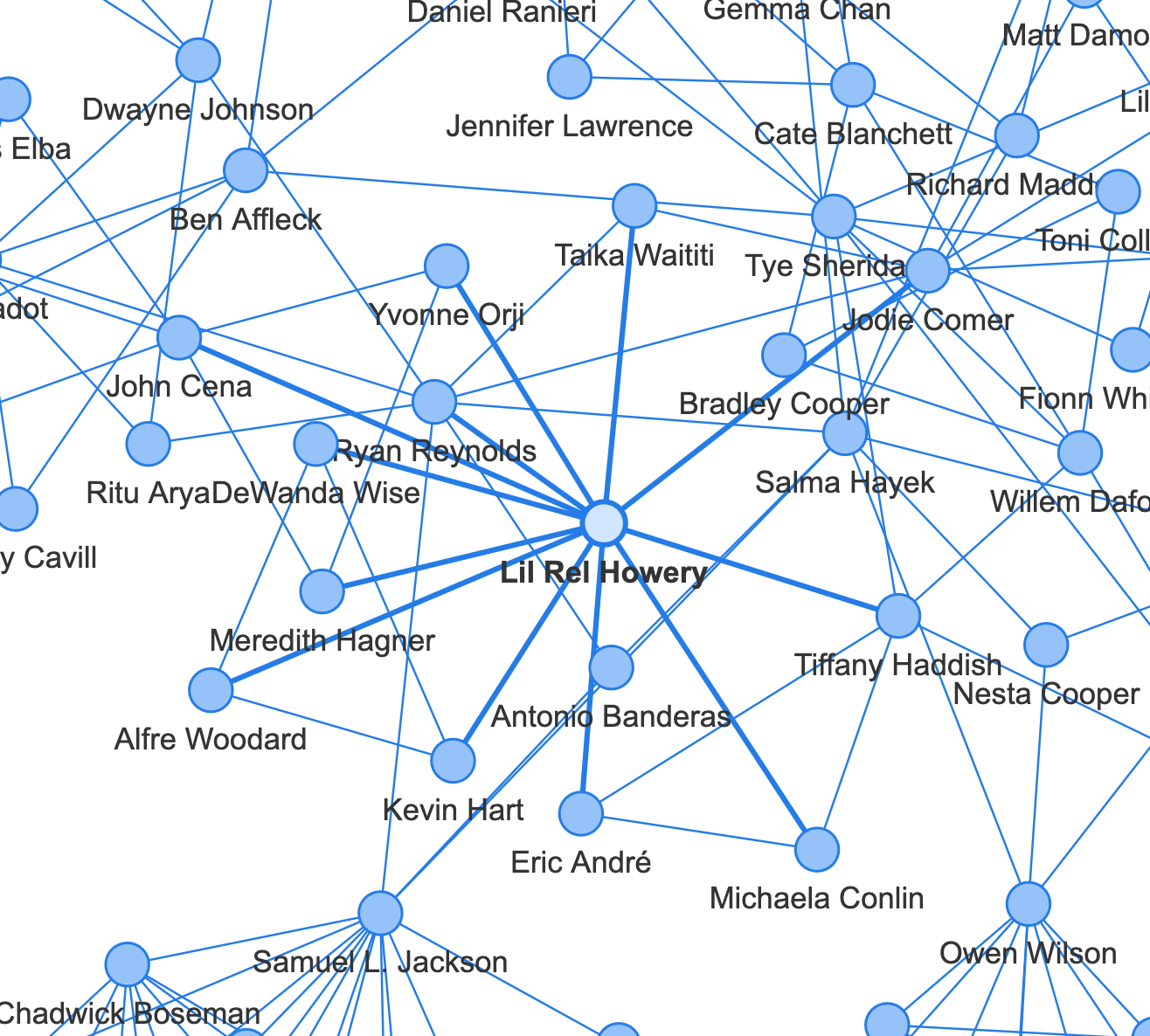
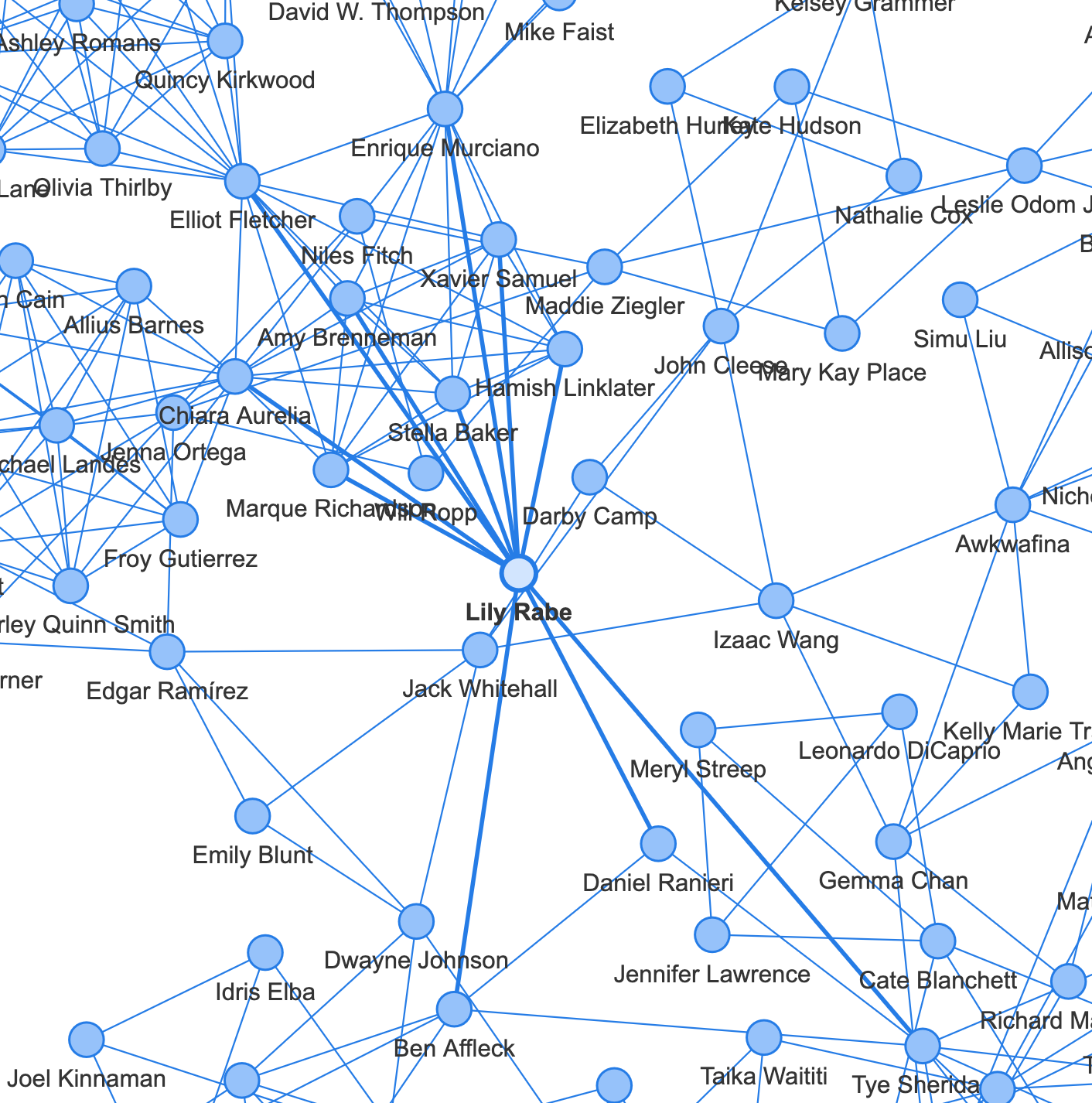
주연 배우들 중에서는 <듄>, <아담스 패일리> 등에 출연한 오스카 아이작, <이터널스>, <킬러의 보디가드>에 출연한 샐마 헤이약, <프리 가이>, <킬러의 보디가드>, <레드 노티스>에 출연한 라이언 레이놀즈가 네트워크 형성에 중요한 역할을 하고 있습니다.
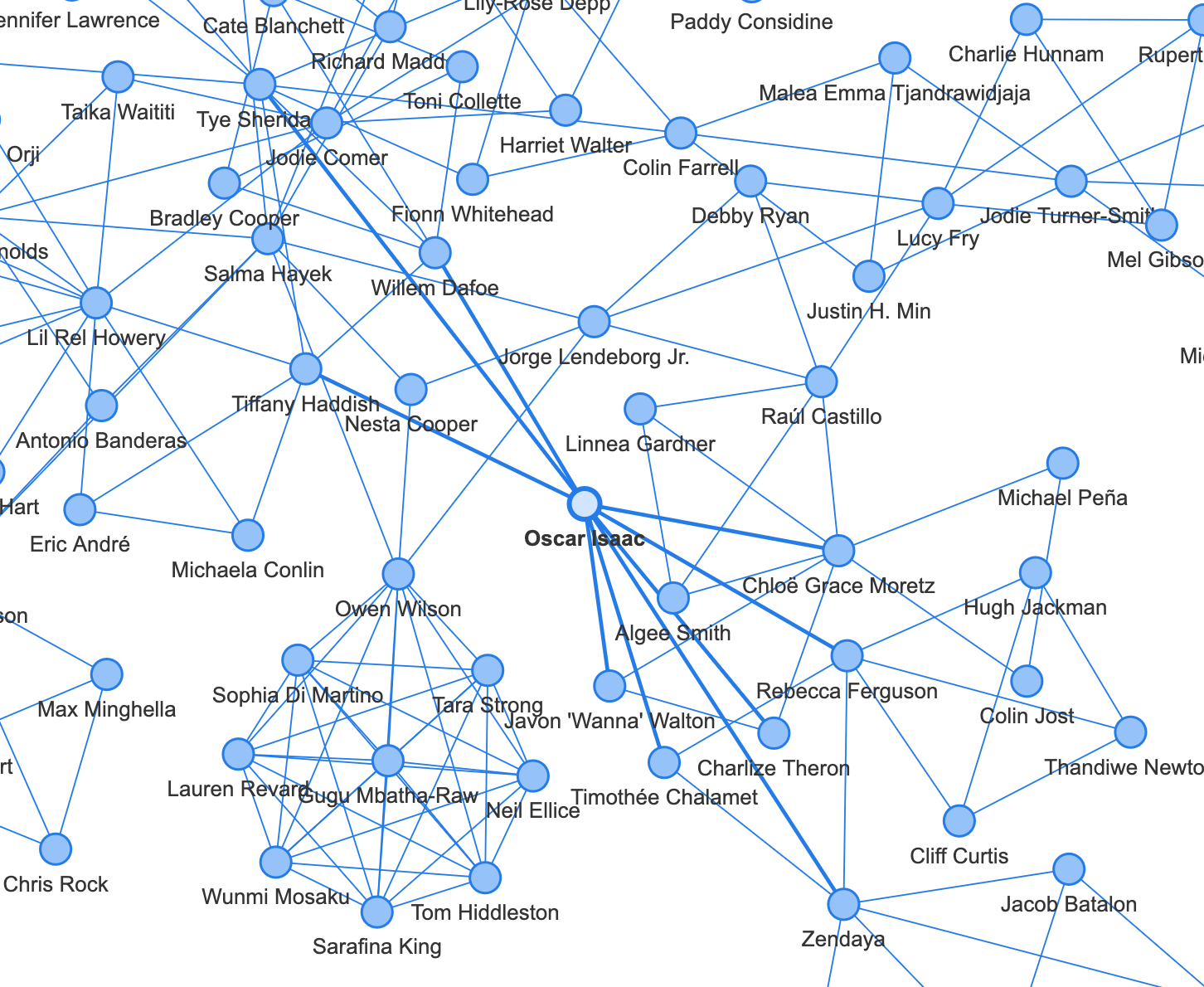
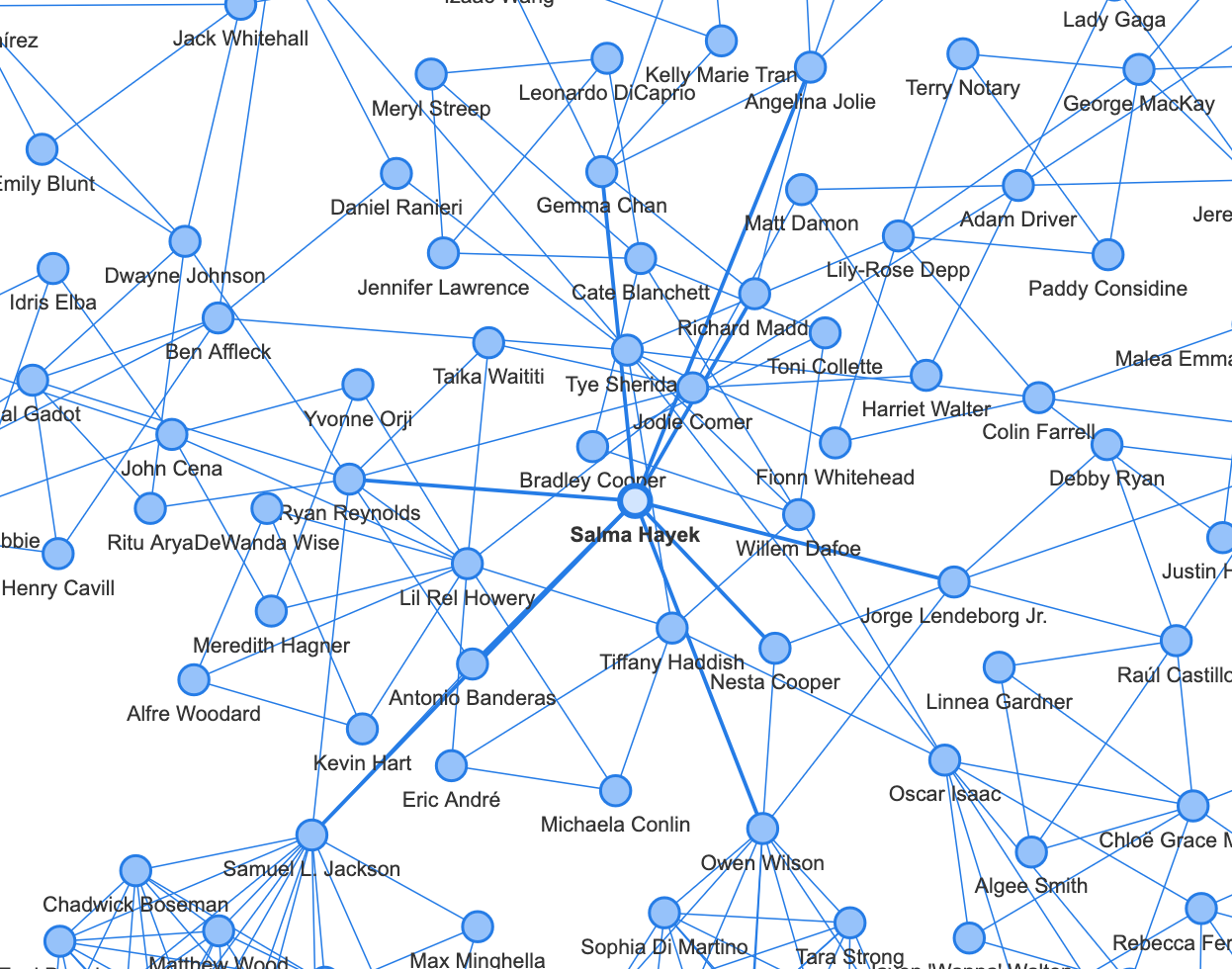

오늘 분석은 여기까지입니다. 특정 노드들의 색깔을 다르게 지정할 수 있으면 훨씬 이해하기 쉬운 시각화가 될 것 같은데 방법을 알 수 있으면 좋겠네요 😅 참고로 아래 시각화는 데이터 필터링을 거의 하지 않고 한번 해본 건데요. 데이터가 크면 클수록 오히려 더 직관적으로 이해하기 쉬울 수도 있다는 점 참고할 수 있을 것 같습니다.