Abstract
denoising 과정에서 반복적으로 계산되는 결과들을 caching 하여 저장하고 재사용하는 것 => 연산 줄임
1. Introduction
- 최근 생성형 모델에서 diffusion model이 큰 주목을 받음
- 텍스트, 이미지, 오디오, 비디오등 다양한 분야에서 활용됨
기존 연구들의 문제점
- 느린 추론 속도
1) sampling 단계를 줄이는 것
2) pruning, distillation, quantization등으로 각 단계별 계산 비용을 줄이는 것
으로 해결하고자 함
기존의 해결방법들은 retraining process에 대한 비용과 대규모 데이터셋에 의존한다는 한계점이 아직 존재
본 논문에서의 목표 : diffusion model의 각 step마다 모델 크기를 줄여 효율성을 높이는 것
we focus on a challenging topic: How to significantly reduce the computational overhead at each denoising step without additional training, thereby achieving a cost-free compression of Diffusion Models?
-
high-level features 또한 캐싱이 가능하다는 것을 발견 ("cacheable"="한번만 계산하고 이후에는 저장된 값을 재사용하는 것이 가능하다")
-
U-Net 구조를 활용하여
- high-level features : 캐싱하여 유지
- low-level features : 각 denoising 단계에서 지속적으로 업데이트
=> 이를 통해 고수준 정보는 재사용하고, 필요한 부분만 동적으로 계산하게 됨. 따라서, 재훈련 없이 Diffusion Models의 효율성과 속도를 상당히 향상시킬 수 있음.
본 논문의 성과를 요약하면 :
- DeepCache : 동적 압축 알고리즘을 도입하여 runtime Diffusion Models를 압축하고 이미지 생성 속도를 향상 + 추가적인 재훈련이 필요하지 않음.
- 캐싱 가능한 특징을 이용해 중복 계산을 줄임, non-uniform 1:N strategy 제시
- pruning과 distillation 같은 기존 가속화 방법들보다 더 높은 효율성을 입증
2. Related Work
Diffusion Models의 추론 속도 문제를 해결하기 위한 기존 연구들
1. Optimized Sampling Efficiency
- 샘플링 단계의 수를 줄여 추론 속도를 개선하는 방식
1.DDIM
2.SDE or ODE
3.Consistency Model
4.Parallel sampling techniques (DSNO, ParaDiGMS)
2. Optimized Structural Efficiency
- 샘플링 각 단계의 추론 시간을 줄이는 방식
- Diff-pruning
- SnapFusion
- diffusion model zoo에서 단계별로 다른 모델을 선택
- 특정 조건에서 샘플링 과정을 조기 종료
- quantization techniques
3. Methodology
3.1 Preliminary
Forward and Reverse Process
- Diffusion Models는 데이터를 점진적으로 노이즈를 추가하여 변환하고, 이를 반대로 처리하여 데이터를 복원하는 과정으로 학습됨
Forward Process
- 실제 데이터 분포에서 샘플을 점진적으로 노이즈를 추가하여 점차적으로 랜덤한 노이즈로 변환
- T개의 단계에 걸쳐 가우시안 노이즈를 점진적으로 추가되는데, 그 과정은 다음과 같이 정의됨 :
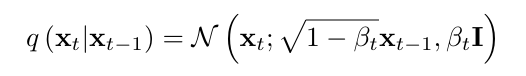
- 데이터 포인트 ∼ (실제 분포에서 샘플링)이고, 각 단계에서 데이터는 점점 더 노이즈가 섞어 는 무작위 노이즈로 변하게 됨. 는 각 타임스텝에서 추가되는 노이즈의 크기를 의미.
Reverse Process
- 랜덤 노이즈 에서 시작하여 점차적으로 이를 타겟 분포로 복원
- 과정 :
- 역방향에서, 네트워크 ϵθ(xt,t)를 사용하여 각 단계에서 노이즈를 제거
- 와 타임스텝 t를 입력으로 받아 을 추정
- 공식은 다음과 같다 :
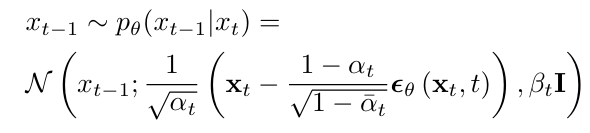
각 단계에서 노이즈를 점차 제거하여 를 점차적으로 실제 데이터에 가까워지도록 만드는 과정
High-level and Low-level Features in U-Net
U-Net은 원래 생물의학적 이미지 분할을 위해 소개되었으며, 고수준 특징과 저수준 특징을 결합하는 데 강력한 능력을 보여준다. 이 모델의 주요 특징은 skip connection을 통해 저수준 특징을 고수준 특징과 결합하는 구조이다.
U-Net의 구조
- U-Net은 downsampling과 upsampling 블록이 쌓인 구조로, 입력 이미지를 high-level representation으로 인코딩하고 이를 후속 작업을 위한 해석으로 디코딩
- 블록 쌍 : downsampling block인 {Di}와 upsampling block인 {Ui}로 나뉨. 이 블록들은 추가적인 skip paths로 연결됨
Skip Path와 Feature 전달
- Skip connection은 Di에서 처리된 저수준 특징을 Ui로 직접 전달한다. 이 연결을 통해 저수준 정보가 고수준 정보와 함께 결합된다.
- U-Net에서 데이터는 두 개의 경로를 통해 전달:
- Main Branch : 업샘플링 블록에서 처리된 고수준 특징을 제공
- Skip Branch : 대칭적인 다운샘플링 블록에서 나온 저수준 특징을 제공
- 이 두 경로의 정보들은 Concatenation Module에서 결합 :
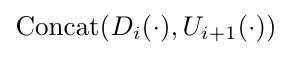
Di(·)는 다운샘플링 블록에서 얻은 특징이고, Ui+1(·)은 업샘플링 블록에서 얻은 특징이다. 저수준 특징과 고수준 특징을 연결하여 하나의 종합적인 표현을 만드는 것
3.2 Feature Redundancy in Sequential Denoising
Diffusion 모델의 denoising 과정은 순차적으로 진행되며, 이 순차성은 추론 속도에서 중요한 bottleneck이 됨. 즉, 각 단계가 차례대로 진행되기 때문에 속도가 늦어질 수 있음.
- denoising 과정에서 인접한 단계들 간에 high-level features이 시간적으로 유사하다는 사실을 발견
- 실험에 따르면 각 타임스텝에서, 적어도 10%의 인접 타임스텝은 현재 단계와 0.95 이상 유사하다는 결과가 나옴. 이 말은 고수준 특징이 서서히 변화한다는 것을 의미.

- 즉, 유사한 특징을 반복해서 계산하는 것이 비효율적이라는 것. 따라서 이 계산 부분을 최적화하여 속도를 향상시킬 수 있다
3.3 Deep Cache For Diffusion Models
DeepCache
- 변화가 느리게 일어나는 특징을 전략적으로 캐시함으로써, 반복적인 불필요한 계산을 방지
- U-Net의 Skip Connections을 활용
Cacheable Features in denosing
- 를 생성하는 과정에서 high-level features가 생성되고, 이는 U-Net의 main branch를 통해 계산된다. 이때 skip branch를 이용하여 skip connection을 고려한다.
- t 시점에서 업샘플링 블록에서 나온 특징을 캐시 :
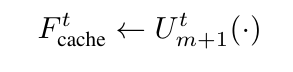
- t-1 시점에서는 전체 네트워크를 다시 계산하지 않고, 동적 부분 추론을 수행한다. 즉,
로부터 이미 계산된 특징을 바탕으로, 필요한 부분만 계산하고 나머지는 캐시에서 불러옴 :
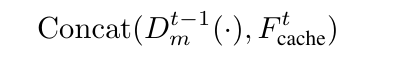
Dmt−1 : t-1 시점에서의 다운샘플링 블록의 출력. 이 출력은 계산해야 할 부분.
Ftcache: 이전 시점 t에서 계산한 고수준 특징을 캐시에서 불러온 값. 계산 X 재사용.
이 과정을 아래의 그림과 같이 정리할 수 있다 :
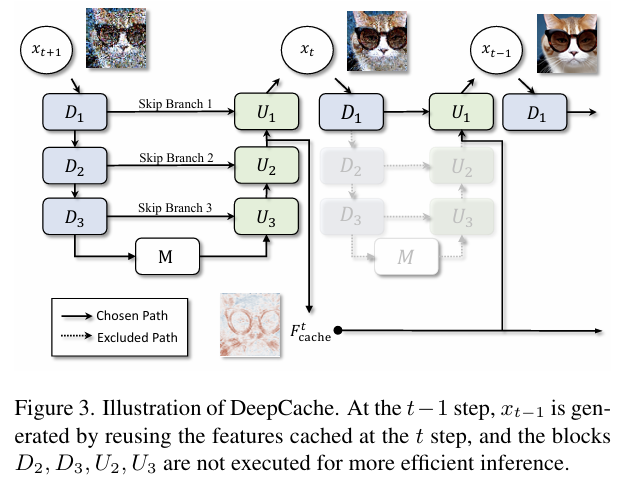
Non-uniform 1:N Inference
1:N strategy
- high-level features가 연속된 N 단계에서 불변한다고 가정하고, 이를 기반으로 추론을 가속화함.
- 그러나 이 가정은 모든 경우에 적용되지 않음. 특히 N이 커질수록, 두 단계 간의 특징 유사성이 일정하지 않다는 것이 드러남. 확산 모델에서 특징의 유사성이 시간이 지나면서 점차적으로 감소
Non-uniform 1:N Inference
- 특징 유사성이 낮은 단계들에 대해서는 더 많은 계산을 수행하도록 설정
- 유사성이 큰 단계에서는 캐시된 결과를 재사용하고, 유사성이 작은 단계들에 대해서는 전체 추론을 수행
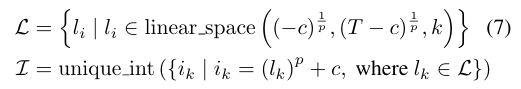
- linear space(s,e,n) : s에서 e까지의 구간을 n개의 숫자로 균등하게 나눈 값
- unique int(·) : 이 숫자들을 정수로 변환하여 중복되지 않도록 보장
- c는 선택된 중심 시점을 나타내는 하이퍼파라미터
- 이 식에서 인덱스의 빈도는 중심 시점에서 멀어질수록 2차 함수적인 방식으로 변화함
=>특징 유사성의 변화를 고려하여, 유사성이 큰 단계에서는 계산을 줄이고, 작은 단계에서는 더 많은 계산을 수행하는 방식으로 추론속도를 효율적으로 가속화함과 동시에 이미지 품질도 개선.
4. Experiment
4.1 Experimental Settings
- 데이터셋: LSUN-Churches, LSUN-Bedroom, CIFAR-10, CelebA 등의 다양한 공개 데이터셋
- 모델: DDPM, LDM, Stable Diffusion 등의 다양한 확산 모델에 대해 진행
- 평가 지표: 실험은 계산 속도와 생성 품질을 평가 지표로 사용. 속도 향상과 이미지 품질을 모두 고려하여 결과를 비교.
4.2 Complexity Analysis
- 기존 방법들보다 빠른 계산 속도를 제공
- 계산에 있어 불필요한 중복 작업을 줄이고, 캐시된 고수준 특징을 재사용함으로써 실험에서 가장 큰 속도 향상을 보임
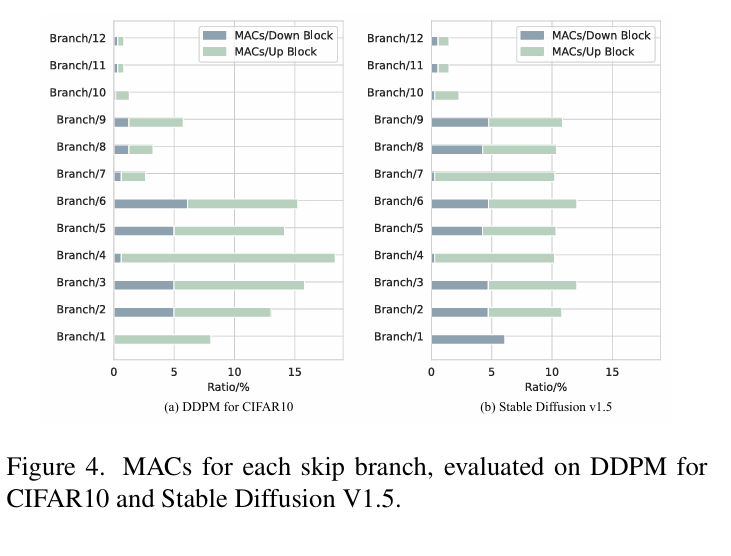
=> 실험 결과, DeepCache는 기존의 파라미터 크기 축소 방법이나 계산 최적화 방법들보다 더 뛰어난 성능을 보였으며, 많은 계산을 줄이면서도 고품질의 결과를 유지할 수 있음
4.3 Comparison with Compression Methods
- DeepCache는 기존의 DDIM과 PLMS와 비교해 비슷하거나 더 우수한 생성 품질을 보여줌.
- DeepCache가 제공하는 속도 향상은 이미지 품질에 큰 영향을 미치지 않았으며, 속도와 품질 모두에서 좋은 균형을 보였다는 점에서 의미가 있다.
LDM-4-Gfor ImageNet
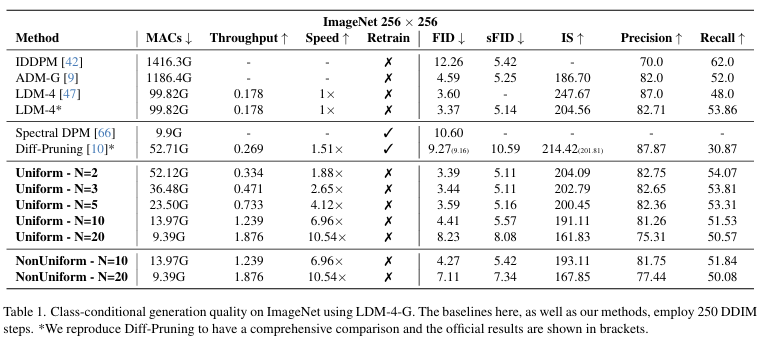
- LDM-4-G 모델을 사용하여 실험한 결과, 속도 4.1배 향상을 달성했을 때 약간의 성능 저하가 있었음
- 하지만 DeepCache 방법은 다른 방법들과 비교했을 때 FID와 FID 점수에서 현저한 개선을 보였고, 속도 향상이 상당히 큼
DDPMs forCIFAR-10andLSUN
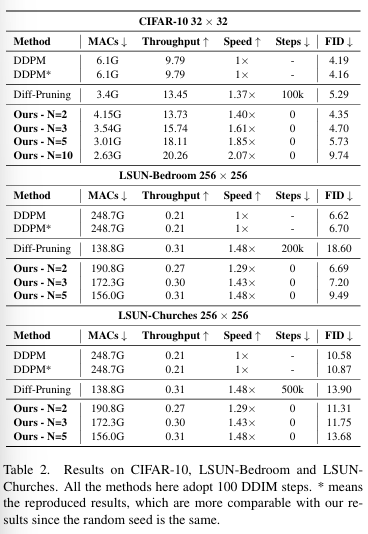
-CIFAR-10, LSUN-Bedroom, LSUN-Churches 데이터셋에서의 실험 결과, DeepCache 방법은 ㅁretraining이 필요 없으면서도 기존 방법을 초과하는 성능 - 레이어 프루닝 방식을 채택하여, 하드웨어 친화적이며, 기존 방법들과 비교해 더 큰 속도 향상을 달성
Stable Diffusion
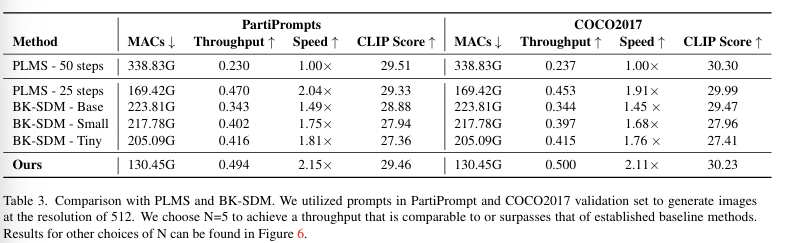
- BK-SDM의 세 가지 변형과 비교했을 때 모두 더 빠른 속도를 보이며 성능을 초과
- 이미지 품질에서도 DeepCache는 생성된 이미지가 원래 확산 모델의 이미지와 더 일관성이 있었으며 텍스트 프롬프트와 정렬이 더 잘 됨.
아래의 figure5를 통해 시각적으로 확인이 가능하다:

4.4 Comparison with Fast Sampler
- 속도 향상과 품질 간에는 트레이드오프가 존재하지만, DeepCache는 효율적인 계산을 통해 이러한 트레이드오프를 최소화
4.5 Analysis
- DeepCache는 기존의 다른 최적화 기법들과 비교하여 실험을 진행하였으며, 속도 향상과 생성 품질 모두에서 상위 성능을 기록
- 특히 DDIM과 PLMS 모델들에 비해 DeepCache는 비교적 적은 계산 비용으로 더 우수한 성능을 보임
5. Limitations
- pre-trained diffusion model의 구조에 의존
모델의 구조가 미리 정해져 있기 때문에, 모델의 구조가 깊은 경우나 특정 부분의 계산량이 많은 경우(예: 모델의 얕은 skip branch가 전체 모델의 50%를 차지하는 경우), 속도 향상을 그만큼 많이 달성하기 어려움. - large Cache step(N=20)을 사용할 경우 성능저하 발생 -> 속도 향상에 제한
6. Conclusion
- DeepCache는 확산 모델의 인접 단계 간 high-level features의 유사성을 활용하여 계산 속도를 가속화하는 방법이다.
- U-Net의 skip connection을 활용함으로써, 고수준 특징 계산을 줄이는 대신 저수준 특징을 빠르게 업데이트하였다.
- DeepCache는 파라미터 크기 감소에 집중하는 기존 압축 방법들보다 우수한 성능을 보였다. 또한, DDIM이나 PLMS와 같은 기존 방법들과 비교했을 때 생성 품질이 비슷하거나 약간 더 우수한 결과를 보였다.
